


深度理解梯度在神经网络中的应用

本篇文章主要就最近温习的梯度下降法以及反向传播算法进行总结和梳理,并谈谈自己的理解。
梯度下降法是一种非常重要且核心的算法,许多基于目标函数的优化算法都是从梯度下降算法演变而来,反向传播算法也是一种常见算法。在神经网络优化的过程中,使用的梯度下降算法,具体实现的方式是采用反向传播算法。介绍的内容主要有:
- 梯度
- 梯度下降算法
- 反向传播算法
- 整体的理解和感悟
1.梯度
引用别人的一句话:训 练模型就像人生旅途,损失函数就是人生理想,而梯度就是朝着这个理性每一步前进的方向,所以梯度就是当下最佳的选择 。
在数据的定义中,梯度是一个矢量,既有大小也有方向,在算法优化的过程中更多用的是梯度的方向,大小更多取决于学习率。梯度的定义如下
T = f(w_{1},w_{2},w_{3}) ,其中T为目标函数,w为自变量(优化参数),目标函数对w1/w2/w3的梯度为:
∇f(w_1,w_2,w_3 )= (∂f/(∂w_1 ),∂f/(∂w_2 ),∂f/(∂w_3 ))
从梯度的形式看我可以看出,是将目标函数分别为每个自变量(优化参数)求偏导数,组成的向量称为梯度 。
2.梯度下降算法
梯度下降算法的核心就是计算梯度, 每迭代一步整个网络计算一次梯度 , 根据梯度中的对应的各个分量来更新参数 。在逻辑回归中,由于网络结构比较简单,可以认为就是一层神经网络,不需要通过反向传播通过链路的方式来计算每个参数的梯度(梯度中的分量)。当神经网络层数较多时,就要使用反向传播链式方式计算每个参数的梯度。下面重点介绍一下反向传播的具体过程。
3.反向传播算法
通过反向传播的方式来计算梯度,实现的形式就是通过链路的方法,计算某个具体参数的梯度(梯度分量)时,同一条链路上的偏导数相乘,最后将不同链路上的偏导数的积相加得到最终的梯度分量。
下面以一个三层的神经结构为例来说明:
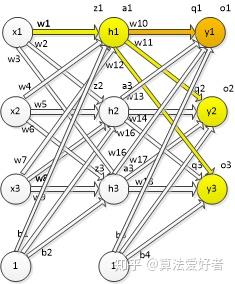
网络结果为三层,每层分别为三个神经元,是一个多分类模型(三类),w1-w18为各个神经元的权重,b1-b4为隐含层和输出层神经元的阈值,z1-z3为隐含层神经元的输入,q1-q3为输出神经元的输入,a1-a3为隐含层神经元的输出,o1-o3为输出层神经元的输出。
假设损失函数为 J(w,b) ,该损失函数即可以是一个样本产生的损失,也可以是一批样本产生的损失,还可以所有样本产生的损失,第一种是真正的SGD,第二种是广义上的SGD(实际并不是,不过现在都这么叫),第三种就是梯度下降法。
损失函数为输出神经元o1/o2/o3输出误差之和,橙色为对w10更新所用的链路,黄色+橙色为更新w1所使用的链路,下面分别写出两个链路的梯度更新式子。
对w10更新,对w1计算梯度只有橙色一个链路,所以计算公式为:
∂f/(∂w_{10} )= (J(w,b)/∂o_1 )∙(∂o_1/∂q_1 )∙(∂q_1/∂x_{10} )
对w10更新,对w10计算梯度只有橙色一个链路,所以计算公式为:赋予了一个初始值(或者w10是前一步迭代更新的值),将w10值带入就可以计算就可以计算出损失函数对w10的梯度分量。
对w1更新,由于w1是输入到隐含层之间的权重,所以反向传播的链路更加复杂,从图中可以看出损失函数J反向到达参数w1有三条支路,法则为链路内部偏导数相乘,然后链路之间相加,对于w10-w1链路:
(∂(w,b)/∂o_1 )∙(∂o_1/∂q_1 )∙(∂q_1/∂a_1 )∙(∂a_1/∂z_1 )∙(∂z_1/∂w_1 )
对w11-w1链路:
(∂(w,b)/∂o_2 )∙(∂o_2/∂q_2 )∙(∂q_2/∂a_1 )∙(∂a_1/∂z_1 )∙(∂z_1/∂w_1 )
对w12-w1链路:
(∂(w,b)/∂o_3 )∙(∂o_3/∂q_3 )∙(∂q_3/∂a_1 )∙(∂a_1/∂z_1 )∙(∂z_1/∂w_1 )
然后将三条链路的偏导数乘积相加:
∂f/∂w_1 = (∂(w,b)/∂o_1 )∙(∂o_1/∂q_1 )∙(∂q_1/∂a_1 )∙(∂a_1/∂z_1 )∙(∂z_1/∂w_1 )
+ (∂(w,b)/∂o_2 )∙(∂o_2/∂q_2 )∙(∂q_2/∂a_1 )∙(∂a_1/∂z_1 )∙(∂z_1/∂w_1 )
+ (∂(w,b)/∂o_3 )∙(∂o_3/∂q_3 )∙(∂q_3/∂a_1 )∙(∂a_1/∂z_1 )∙(∂z_1/∂w_1 )
同样由于之前的前向计算,w1的梯度分量可以直接计算出来( 注意这里计算并没有用本轮迭代更新的w10,还是用上一轮迭代更新的w10 ),根据以上反向传播链式法则,可以计算损失函数为 w2/w3/w4/w5/w6/w7/w8/w9/w11/w12/b1/b2/b3/b4的梯度分量
即可算出梯度为 (\frac{\partial f}{\partial w_{1}},\frac{\partial f}{\partial w_{2}},\frac{\partial f}{\partial w_{3}},\frac{\partial f}{\partial w_{4}},\frac{\partial f}{\partial w_{5}},\frac{\partial f}{\partial w_{6}},\frac{\partial f}{\partial w_{7}},\frac{\partial f}{\partial w_{8}},\frac{\partial f}{\partial w_{9}},\frac{\partial f}{\partial w_{10}},\frac{\partial f}{\partial w_{11}},\frac{\partial f}{\partial w_{12}},\frac{\partial f}{\partial b_{1}},\frac{\partial f}{\partial b_{2}},\frac{\partial f}{\partial b_{3}},\frac{\partial f}{\partial b_{4}})
然后各分量对对应的参数更新一次,完成模型的一次迭代更新 。
4.整体的理解和感悟
① 默认情况下是所有样本前向计算之后进行一次迭代更新,目标函数是所有前向计算样本的平均误差值;
② 参数w/b的更新是链路的更新,对隐含层-输出层以及输入层到隐含层的更新,都是看目标函数到所更新的参数之间有多少条链路,一条链路之间是相乘,多条链路之间是相加。链路中间的节点: 目标函数,输出层神经元的输出,输出层神经元的输入,隐含层神经元的输出,隐含层神经原的输入,最后更新的参数w/b ;
③ 参数w/b是一轮一轮的更新,在每一轮迭代更新所有参数的过程中,并不是先更新隐含层-输出层之间的参数,然后在更新输入层-隐含层的参数时,使用先更新隐含层-输出层之间的参数。这时更新输入层-隐含层的参数时使用的还是上一轮更新隐含层-输出层之间的参数的参数;
④ 通过上面3的分析, 可以认为神经网络在更新权重以及阈值时进行并行计算 ;
⑤ 梯度下降算法是一种通用的优化方法,反向传播算法是其在神经网络上的具体体现, 可以理解为梯度下降算法是一种优化思想,而反向传播算法是依据这个思想具体的实现方式 ;
⑥ 梯度下降算法的中心思想是沿着目标函数(基于参数)梯度的方向更新参数(权重)以让目标函数值最小(loss函数)或最大(准确率等),梯度下降算法是深度学习模型中常见的优化方法,其它模型也有在用梯度下降算法;
⑦ 反向传播算法是梯度下降算法在神经网络中的实现方式,由于深度学习网络是按层深入,层层嵌套,对深度学习网络目标函数计算梯度的时候,需要使用反向传播的方式由深到浅倒着计算以及更新参数。