

flink iceberg kafka架构 catalog hive hdfs 笔记

flink就类似Java里的stream,并行流。。。跟hive相比就是,flink是实时流,hive是离线流。
同一个字符串,前面输出的编号是一样的,因为key => hashcode,同一个key的hash值固定,分配给相对应的线程处理。
每一个数据都对key进行hash计算,进行类似分区的操作,来一个数据就处理一次,所有中间过程都有输出!
这里因为是流处理,所以所有中间过程都会被输出,前面的序号就是并行执行任务的线程编号。
nc
-l 开启 监听模式,用于指定nc将处于监听模式。通常 这样代表着为一个 服务等待客户端来链接指定的端口
-k<通信端口>强制 nc 待命链接.当客户端从服务端断开连接后,过一段时间服务端也会停止监听。 但通过选项 -k 我们可以强制服务器保持连接并继续监听端口。
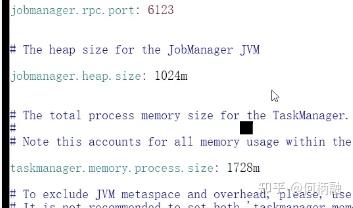
状态就是存储在堆外内存当中。现在理解的模型就是,一个jobmanager就是一个任务调度的。然后task包含了堆外和堆内的内存。
taskmanager就是干活的人,slot就是分配资源的,一个slot对应一个线程,slot对应的是最大的执行线程数。slot一般设置为当前CPU的核心线程数。 paramllelism则是真正并行的线程数。但是一个集群里可以有多个taskmanager,一个taskmanager又可以有多个slot,paramllelism只要不超过总的slot就可以了。


master就是提交任务的入口,对应的是jobmanager,启动的时候会对应一个进程用于提交任务。 taskmanager就是对应slaves,可以配置多个域名,用于计算。
jobmanager就是作业的管理者。


standalone就是接受任务的进程,task executor就是干活的那个人。




不同块的代码是可以在不同的分区执行的,没有说这一大块的代码都必须在同一节点执行。这样即使某些步骤特别耗时,也不一定阻塞后面的任务执行。
数据其实就是在不同的任务直接传输的。
并行度的优先级
优先以子任务的并行度为准,然后是env,接着是提交任务界面的,最后是集群环境默认的。




执行计划,看并行度
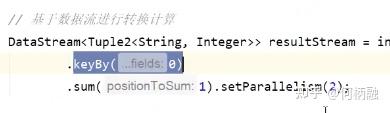
keyby只是分发了任务,不在计算操作内。 后面是聚合操作,这里子任务设置了。后面的print也是设置了
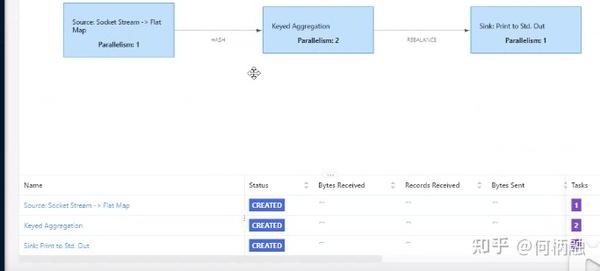
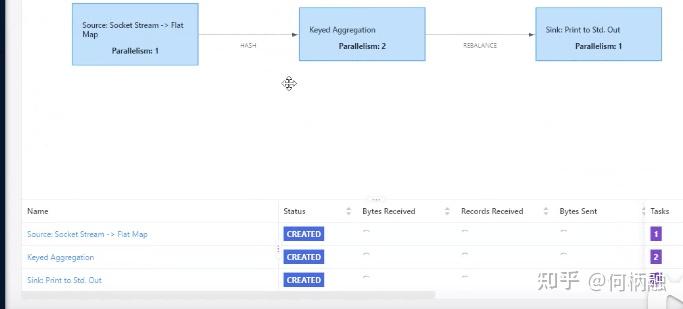
有四个任务,然后 只设置了一个slot,所以任务没有提交成功。
即并行度和资源分配单位的匹配。
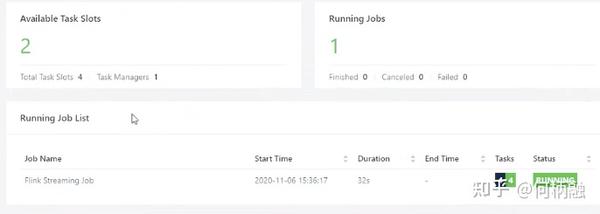
四个任务其实只占用了两个slot
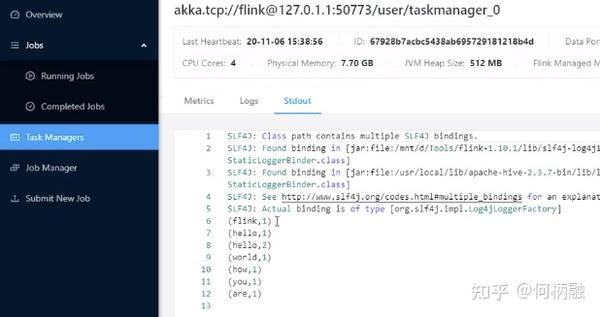
在task manager这里才能看到标准输出。
iceberg 介绍 Apache iceberg:Netflix 数据仓库的基石
可伸缩的 格式
Iceberg 的目标包括:1、成为静态数据交换的开放规范,维护一个清晰的格式规范,支持多语言,支持跨项目的需求等
2、提升扩展性和可靠性。能够在一个节点上运行,也能在集群上运行。所有的修改都是原子性的,串行化隔离。原生支持云对象存储,支持多并发写。
3、修复持续的可用性问题,比如模式演进,分区隐藏,支持时间旅行、回滚等
ceberg 主要设计思想:记录表在所有时间的所有文件,和 Delta Lake 或 Apache Hudi 一样,支持 snapshot,其是表在某个时刻的完整文件列表。每一次写操作都会生成一个新的快照。(空间占用不会很大吗?)
读取数据的时候使用当前的快照,Iceberg 使用乐观锁机制来创建新的快照,然后提交
Iceberg 这么设计的好处是:
- 所有的修改都是原子性的;
- 没有耗时的文件系统操作;
- 快照是索引好的,以便加速读取;
- CBO metrics 信息是可靠的;
- 更新支持版本,支持物化视图。
Iceberg 在 Netflix 生产环境维护着数十 TB 的数据,数百万个分区。对大表进行查询能够提供低延迟的响应


flink命令 手动提交任务
flink list 列出当前正在工作的任务
flink cancel jobid
占据的slot等于最大的那个并行度。 也就是同一时间最多只能占用这么多个slot。
- 所有的Flink程序都是由三部分组成的: Source 、Transformation 和 Sink。
- Source 负责读取数据源,Transformation 利用各种算子进行处理加工,Sink 负责输出
小姐姐味道:到处是map、flatMap,啥意思? map和flatmap的使用区别
flat是扁平的意思
sink就是控制数据输出的方向的,可以输出到Kafka,redis,hive这类。
// 1.3 基于Blink的流处理 EnvironmentSettings blinkStreamSettings = EnvironmentSettings.newInstance() .useBlinkPlanner() .inStreamingMode() .build(); StreamTableEnvironment blinkStreamTableEnv = StreamTableEnvironment.create(env,blinkStreamSettings);
Kafka架构:一个partition有leader和flower,平常使用都是使用leader,leader挂了才使用flower,然后flower就变成了leader。一个topic有多个分区partition。也就是主从备份高可用那套。
消费组的概念:一个分区只能被一个消费组里面的一个消费者消费,也就是控制topic被消费者的消费的,最小粒度是分区。即一个分区的数据不能被同一个消费组的多个消费者消费,但是可以被不同消费者组里面的多个消费者消费。 作用: 提高消费能力 ,可以在一个消费组里面多加几个人,来一起消费同一个topic里面的东西。 所以一个消费组里的消费者个数要小于等于主题里的分区数,不然就浪费了消费者,分区数都别使用完了,你多出来的消费者啥都干不了。
一个主题被消费的数据,offset保存在zk里面。平常就使用本地内存的,挂了之后从zk里面取出来,然后继续消费。0.9之前存在zk,之后存储在Kafka系统的topic当中。 消费者是以拉取的模式获取消息的,即主动轮询,可能一秒好几次那种。 消费者本来就要连接Kafka集群了,又要连zk,就显得有些累赘,高并发连接zk也不好。
Kafka存数据在磁盘当中,默认保留七天。
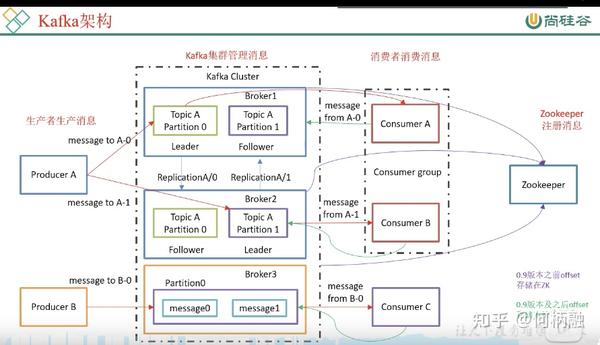
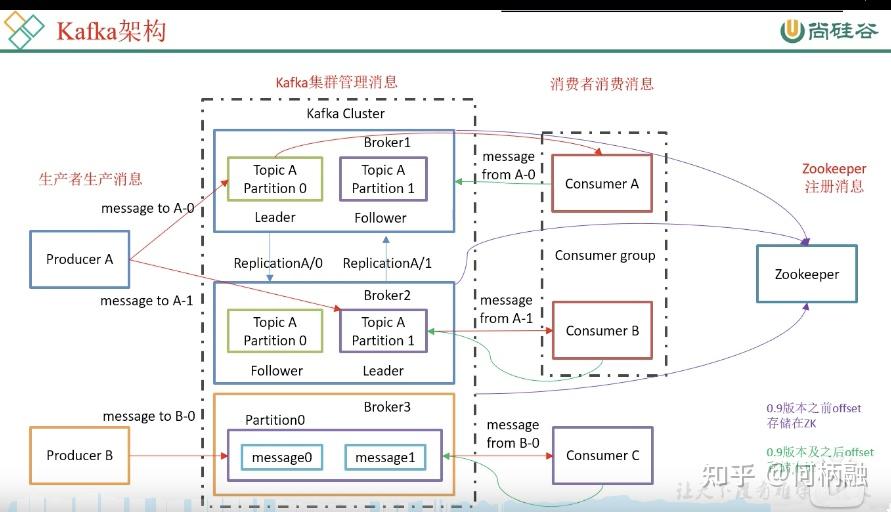
broker topic partition. consumer group
Hadoop "Permission denied (publickey,password,keyboard-interactive)" warning Mac上启动hdfs的时候一直报没有权限。也就是自己登录自己没有权限。 .
将id_rsa.pub中的内容拷贝到 authorized_keys中
cat id_rsa.pub >> authorized_keysssh hebingrong@localhost 这个的意思是使用hebingrong这个账户去ssh登录localhost这个地址。 authorized_keys是ssh服务端保存登录的客户端公钥的地方,然后是客户端的东西:id_rsa存储的是私钥,pub后缀存储的是公钥,然后这里的操作就是把客户端的公钥拷贝到服务端的authorized_keys当中。然后就可以免密ssh登录了。 Mac配合上公司的防护,这类东西比较难搞。
jps的时候
1681 RunJar 这个是hive启动的进程
下面三个是Hadoop的hdfs启动的进程。貌似不需要启动其它的东西就可以供hive使用了。
1523 SecondaryNameNode
1284 NameNode
1387 DataNode
如果hdfs没有启动的话,hive中show dabases也是可以的,但是create database就会有问题了。
./hdfs dfs -ls / 查看hdfs根目录下有哪些文件
CN0014002455M:bin hebingrong$ ./hdfs dfs -ls /user/hive/warehouse
2021-08-11 10:51:47,119 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 1 items
drwxr-xr-x - hebingrong supergroup 0 2021-08-10 18:36 /user/hive/warehouse/test.db之前我使用hive在hdfs这里创建了test的数据库,然后一步一步跟着就出现了这个文件。
catalog的概念是什么? iceberg怎么使用起来?
Hadoop catalog是使用Hadoop的hdfs,hive的catalog是使用hive的 metastore,catalog是iceberg对数据源的不同组织形式。
Hive catalog 是通过连接 Hive 的 MetaStore,把 Iceberg 的表存储到其中
catalog就是映射一个数据源 ,多操作两下就理解了。
./sql-client.sh embedded -j /Users/hebingrong/application/jarfile/iceberg-flink-runtime-0.11.0.jar -j /Users/hebingrong/application/jarfile/flink-sql-connector-hive-3.1.2_2.11-1.12.0.jar shell
这样就可以进入flink 的sql查询端了。
./bin/sql-client.sh embedded \
-j ./lib/iceberg-flink-runtime-0.10.0.jar \
-j ./lib/flink-sql-connector-hive-3.1.2_2.11-1.11.0.jar \
shellsql-client执行create catalog的时候,报错
[ERROR] Could not execute SQL statement. Reason:
java.lang.ClassNotFoundException: org.apache.hadoop.conf.Configuration
是因为开启flink即 ./start-cluster.sh之前 没有export HADOOP_CLASSPATH=`/Users/hebingrong/application/hadoop-3.1.0/bin/hadoop classpath` 可以使用echo $HADOOP_CLASSPATH 进行打印输出。 我就很好奇,为啥要使用特定的环境变量来联系到Hadoop啊,一般不都在配置文件里面配置Hadoop的路径的嘛。。。 这里主要就是要使用Hadoop的包。
export HADOOP_CLASSPATH=`/Users/hebingrong/application/hadoop-3.1.0/bin/hadoop classpath` 这个是要执行sql-client之前执行。。。
CREATE CATALOG hive_catalog WITH (
'type'='iceberg',