在扩散模型上实现后门攻击以及防御(一)

简单介绍一下我看的几篇在扩散模型上做后门攻击和防御的文章。
第一篇是清华大学团队发表在CVPR2023上的文章: How to Backdoor Diffusion Models? ,这篇文章思想很简单,对数据集和模型训练过程进行改进,使得输入带有trigger的图像(带有眼镜的人脸,眼镜是trigger),能够生成target图像 (比如猫),没有trigger的输入则生成正常的人脸图像。这篇文章发出来也没多久,但是第一篇在diffusion模型上面做后门攻击的,所以虽然思路简单,却中了CVPR。
How to Backdoor Diffusion Models?
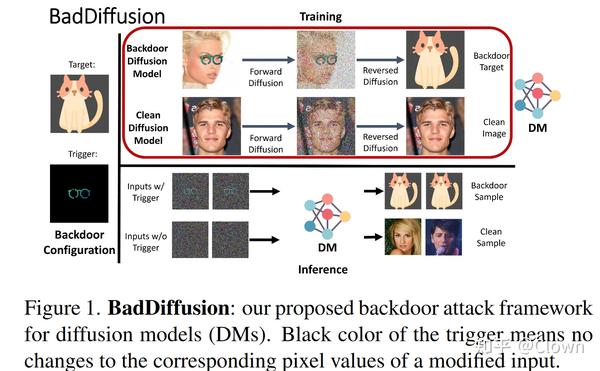

标准的分类器上的后门攻击只修改训练数据集和label 用于后门注入,本文提出的BadDiffusion 不仅修改了训练数据集,还对扩散模型的前向、后向过程进行篡改。BadDiffusion能够满足后门攻击的两个关键目标:(1)高可用性,后门不被触发时模型的性能和干净的模型相近;(2)高特异性,后门被触发时模型能产生特定的行为。
威胁模型 :User 希望能够离线使用一个第三方发布的扩散模型(可以从网上的资源下载),用于特定任务;Attacker 外包了训练模型的任务。Attacker 训练模型并发布,它可以篡改训练数据集和训练过程;User 检测模型的性能和可用性(比如FID、IS分数),模型符合要求才被 accept。
训练过程
干净的DDPM模型
前向过程:
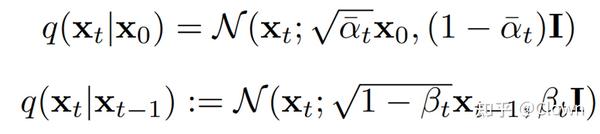

后向过程:
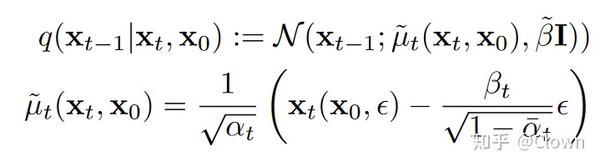

Backdoored 扩散模型 (加入trigger g)
前向过程:
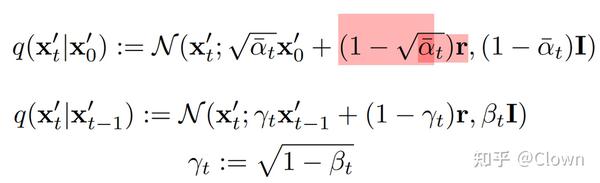

后向过程:
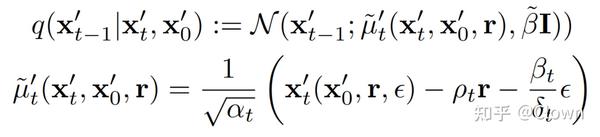

损失函数:
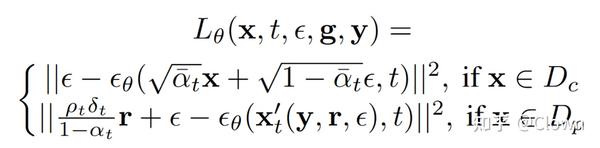

投毒的数据图像为:
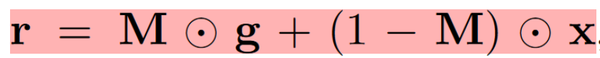

算法实现


BadDiffusion 算法实现和DDPM差别不大,训练阶段主要是对数据集和损失函数进行修改,采样阶段是对干净的目标和后门目标分别采样。
实验过程
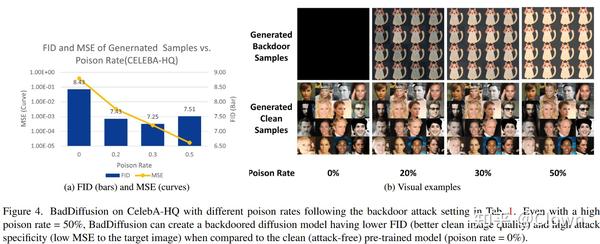
数据集是CIFAR10 (trigger包括 Grey Box , Stop Sign,taregets 包括 NoShift,Shift,Corner,Shoe,Hat) 和 CelebA-HQ (trigger 是 Eyeglasses, target 是cat)
实验结果