pandas 从 0.15 版本开始引入了 Category类型,Category 类型在底层使用整数值来表示该列的值,而不是使用原始值。Pandas 用一个字典来维护这些整型数值到原数据的映射关系。当一列中只包含有限种值时,这种方式是非常有效的。当把一列转换成category 类型时,pandas 会用一种最省空间的 int 子类型来表示这一列中所有的唯一值。

当前 DataFrame 共有 3 个 object 列,其中 E 这一列有 50 个 unique 值,F 这列无重复值,G 这列值全都相同。
df_obj = df.select_dtypes(include=['object']).copy()
df_obj.describe()
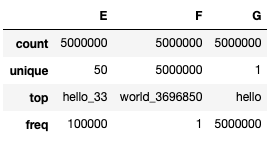
先来把 E 这列转成 Category 类型,看看是什么样
dow = df_obj['E']
print(dow.head())
dow_cat = dow.astype('category')
print(dow_cat.head())
0 hello_0
1 hello_1
2 hello_2
3 hello_3
4 hello_4
Name: E, dtype: object
0 hello_0
1 hello_1
2 hello_2
3 hello_3
4 hello_4
Name: E, dtype: category
Categories (50, object): [hello_0, hello_1, hello_10, hello_11, ..., hello_6, hello_7, hello_8, hello_9]
可以看到列的类型发生了转化,但数据看上去好像没什么变化。下面是用 Series.cat.codes 来返回 category 类型用以表示每个值的 int 数值。
print(dow_cat.head().cat.codes)
0 0
1 1
2 12
3 23
4 34
dtype: int8
可以看到,每一个值都被赋值为一个整数,而且这一列在底层是 int8 类型。这一列没有任何缺失数据,但是如果有,category 子类型会将缺失数据设为 -1。
最后,我们来看看这一列在转换为 category 类型前后的内存使用量。
print(mem_usage(dow))
print(mem_usage(dow_cat))
308.99 MB
4.77 MB
unbelievable,近这一列内存占用从 308.99M 降到了 4.77M,超过 98% 的降幅!这一列中有 50 个 unique 值,实际中的数据会有很多情况,unique 后小于 50。
转换后的 value 并没有变,可用 dow_cat.values == dow.values 进行检验。
那么这样的话, 所有的 object 列都用 category 转一下不就好了,内存就会刷刷的降?too young too naive, 古话说得好 “有得必有失”。首要问题就是转变为类别类型后会丧失数值计算能力,我们不能对category 列做任何算术运算,像 Series.min() 和Series.max() 等方法,不信你可以试一下;第二个问题就是,刚才提到 pandas 自己用一个字典来存储整形编码和原始数据的映射,这也算是额外的存储开销,所以当列中重复值较少时,此种方法并不适用,没准还会增大内存开销。下面是将 F 这列转化为 Category 类型后的内存对比,F 列无重复值出现
df_f = df_obj['F']
df_f_cat = df_f.astype('category')
print(mem_usage(df_f))
print(mem_usage(df_f_cat))
332.73 MB
511.80 MB
可见内存占用不仅没有降下来,反而还增大了,就是因为额外的映射关系表。一般情况下,对于唯一值数量少于 50% 的 object 列,我们应该坚持首先使用category 类型。更多说明可以参考 pandas 文档。
下面用一个循环,对每一个 object 列进行迭代,检查其唯一值是否少于 50%,如果是,则转换成类别类型。
converted_obj = pd.DataFrame()
for col in df_obj.columns:
num_unique_values = len(df_obj[col].unique())
num_total_values = len(df_obj[col])
if num_unique_values / num_total_values < 0.5:
converted_obj.loc[:,col] = df_obj[col].astype('category')
else:
converted_obj.loc[:,col] = df_obj[col]
print(mem_usage(df_obj))
print(mem_usage(converted_obj))
compare_obj = pd.concat([df_obj.dtypes,converted_obj.dtypes],axis=1)
compare_obj.columns = ['before','after']
compare_obj.apply(pd.Series.value_counts)
937.36 MB
342.27 MB
object 类型的内存使用量从 937.36M 降为 342.27M ,减少了 63% ,因为这里的 F 列没有做转换,刚才也看到 F 列自己就占用 332.73M,也就是说另外两列转换后只占用了 10M 不到的空间,这个降幅还是很大的。
现在把 object 类型的优化和之前的数值型列的优化合并起来,看看整体 DataFrame 的优化情况:
optimized_df[converted_obj.columns] = converted_obj
print(mem_usage(df))
print(mem_usage(optimized_df))
1089.94 MB
423.33 MB
整体 DataFrame 的内存量从 1089.94M 降到 423.33M,减少 62% 左右。
上面的例子中,我们是先读入 dataframe 然后再一步步的进行内存优化,以便清晰的看到节省了多少内存。那么能不能在开始读入数据的时候就指定每列的最优 类型呢?答案是可以的,而且这也是 pandas 比较推崇的做法。下面我们先保存原始的 dataframe,然后记下优化过的 optimized_df 每列的类型,然后在读入数据的时候指定每列类型,来对比下这种情况下的 dataframe 和不指定列类型时的内存对比。
dtypes = optimized_df.dtypes
dtypes_col = dtypes.index
dtypes_type = [i.name for i in dtypes.values]
column_types = dict(zip(dtypes_col, dtypes_type))
path = "./tmp.csv"
df.to_csv(path, index=False)
df2 = pd.read_csv(path,dtype=column_types)
print(mem_usage(df))
print(mem_usage(df2))
print(mem_usage(optimized_df))
1089.94 MB
423.33 MB
423.33 MB
可以看到,指定列名后,新读进来的 dataframe 和优化过的 dataframe 内存使用量是一样的。
在这个例子中,通过对 DataFrame 中不同列的优化,将内存使用量从 1089.94M 降到了 423M ,有效降低 62% 左右,用到的两个技巧:
- 将数值型列向下降级到更高效的类型
- 将字符串列转换为类别类型
腾讯校招官网显示,2022届腾讯校招开放技术、产品、设计等岗位共计 78 个,且以IT岗为主。
另据各大招聘平台统计数据,腾讯2022届研发岗应届生基础月薪在1.7万-2.3万之间,签字费(针对优秀人才的额外奖励)3万,股票依据不同等级从6万到20万不等,就算是最低等级的“白菜包”,年薪总包也远超40万元。
作为一个代码打工仔,对于绝大部分程序员来说,想要成为牛
点击上方“数据不吹牛”,选择“置顶星标”公众号干货福利,第一时间送达选自DATAQUEST作者:Josh Devlin机器之心编译参与:Pandapandas 是一个 Python 软件...
data = pd.read_csv('total_data.csv', index_col=0)
data.info(memory_usage='deep')
首先,我们读取total_data.csv这个数据,并制定第一列是index,然后,我们获取一下这个dataframe这个对象在内...
Table of Contents
Pandas 那些年踩过的坑——by 江凯1. Pandas IO中的坑1.1 解决读的坑,让pandas读文件内存占用减小 80%1.2 解决写的坑,让磁盘空间节约60%1.3 解决写的坑,避免挖个坑1.4 python2:加上encoding, 读写好习惯2. DataFrame 链式索引的坑2.1 解决:SettingWithCopyWarning:2.2...
在处理大型数据集的时候,经常碰见python把内存吃满的情况,影响性能,此时就可以对数据集在内存中的存储方式进行优化。所用函数如下:
pandas.DataFrame.memory_usage(index=True, deep=False)
返回该数据框所用的字节数(bytes)
index参数控制索引占用字节是否出现在结果中。
deep参数返回object对象在系统层面(不是很懂)的存储消耗。
pandas.to_numeric(arg, errors=‘raise’, downcast=None)
pandas读取文件占用内存多主要是没有准确识别每一列的数据类型,采用了object进行存储,所有的优化办法都是围绕数据类型转换进行的:一是在读取时指定最佳的数据类型,二是在读取后进行数据转换;更进一步的的优化操作有:(1)将数值向下转换为更高效的类型;(2)将字符串列转换为categorical类型。
把多个Pandas对象(DataFrame/Series)合并成一个。
concat语法:pandas.concat(objs, axis=0, join=‘outer’, ignore_i...
pandas.concat()通常用来连接DataFrame对象。默认情况下是对两个DataFrame对象进行纵向连接, 当然通过设置参数,也可以通过它实现DataFrame对象的横向连接。
1. 纵向连接DataFrame对象
(1)两个DataFrame对象的列完全相同
# 初始化两个DataFrame对象
df1 = pd.DataFrame([['a', 1], ['b', 2]],
columns=['letter', 'number'])
df2 = p
以下是我工作中使用pandas时的一些常用操作python pandas常用操作1. df.isna().sum() # 统计所有列的缺失值 df.iana().sum()/df.shape[0] # 计算所有列缺失率 df['feature'].isna().sum() # 统计单列的缺失值 df['feature'].isna().sum()/df.shape[0] # 计...
确认内存占用:
我这边有一个20M的文件,然后使用:
df = pandas.read_csv(r"F:\mail_log\idc\mail_file\1624-信息.csv", encoding="utf-8")
df.info(memory_usage="deep")
然后返回值:
# Column Non-Null Count Dtype
--- ------ ------------
详情可点击datatable_library[1]。
除此之外,还有一些其他技巧可以在一定程度上帮助我们解决pandas的内存问题。它们可能不是最佳的解决方案,但这些技巧有时很方便。而且,了解一下它们对你也没有坏处,对吧?在我之前的一篇文章中,我谈到了两种在pandas中加载大型数据集[2]的方法。
这两个技巧分别是:
分块:将数据集细
1.python pandas最多处理100M数据,再大就会OOM
2.spark中collect(),也要注意数据量太大时会OOM(我今天用2.3G数据collect就出现了OOM)
如果数据量比较大的时候,尽量不要使用collect函数,因为这可能导致Driver端内存溢出问题。
pandas 是一个 Python 软件库,可用于数据操作和分析。数据科学博客 Dataquest.io 发布了一篇关于如何优化 pandas 内存占用的教程:仅需进行简单的数据类型转换,就能够将一个棒球比赛数据集的内存占用减少了近 90%,机器之心对本教程进行了编译介绍。当使用 pandas 操作小规模数据(低于 100 MB)时,性能一般不是问题。而当面对更大规模的数据(100 MB 到数 G...




