


Pandas 中的数据探索

整体探索:
data.columns.values # 查看有哪些列
data.keys() # 查看有哪些列
data.describe() # 描述性统计
data.head(2).T # 查看前2行
data.shape # 查看dataframe的形状,是几行几列的
type(data[item][2]) # 查看某一个变量的数据类型
data.preferred_genre.value_counts() # 查看一个feature的每一种取值有多少样本
data.info()查看DataFrame总共有多少行、多少列:
# 返回列数:
df.shape[1]
# 返回行数:
df.shape[0]
# 或者:
len(df)查看每一列的空值数:
df.isna().sum()判断一个对象是否为空值:
pd.isnull(na) # True
pd.isna(na) # True
np.isnan(na) # True
na is np.nan # True
na in [np.nan] # True
# 注意,不能用==np.nan来判断查看一个feature的不重复值有哪些、数据类型、空值个数:
def unique(data,i):
variables = data.keys().values
item = variables[i]
print(sorted(data[item].unique()))
except:
print(data[item].unique())
print('-'*5, item, '-'*5)
print(type(data[item][0]))
print('-'*5, data[item].isna().sum(), '-'*5)
提取值:
dataframe_name.iloc[1:3,2:]注意,通过冒号前后数字的不同组合,可以提取出来不同的样式。
例如,我们同样是从DataFrame中仅仅提取一个值出来,有可能提取出来字符串、pd.Series、pd.DataFrame三种格式的数据。
首先,我们创建一个用于示范的DataFrame:
data = {'水果':['苹果','梨','草莓'],
'数量':[3,2,5],
'价格':[10,9,8]}
data = pd.DataFrame(data)
然后,我们指定要提取的是第几行、第几列:
j = 2 # 行
i = 0 # 列下面我们开始提取处于该位置的数据。
第一种方法:直接指定坐标
output1 = data.iloc[j, i]
print(output1)
print(type(output1))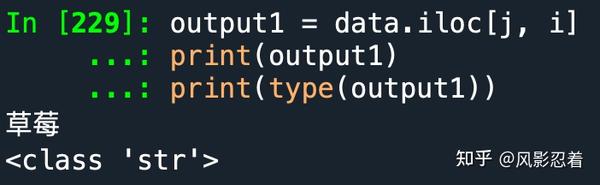

我们发现,仅仅是把处于这个位置的值提取出来了,且数据类型为字符串型。
第二种方法:行号指定成一个区间,列号指定成一个数字
output2 = data.iloc[j:j+1, i]
print(output2)
print(type(output2))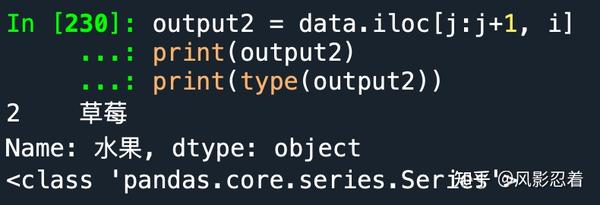

此时,由于行号是一个区间,我们的目光会在同一列中,从上到下由区间开头扫到区间结尾。因此提取出来的是一个pd.Series,且Series的name是该列的列名。
第三种方法:行号指定成一个数字,列号指定成一个区间
output3 = data.iloc[j, i:i+1]
print(output3)
print(type(output3))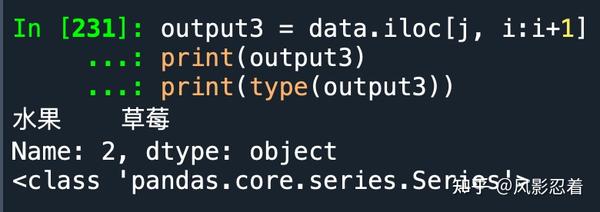

此时,由于列号是一个区间,我们的目光会在同一行中,从左到右由区间开头扫到区间结尾。因此提取出来的是一个pd.Series,且Series的name是该行的行名。
第四种方法:行号和列号均指定成一个区间。
output4 = data.iloc[j:j+1, i:i+1]
print(output4)
print(type(output4))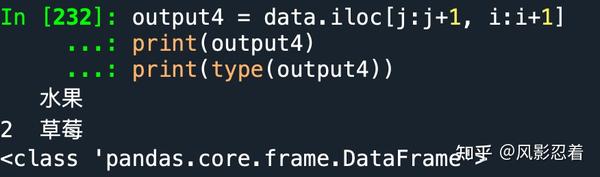

根据上面的两个关于提取成Series的例子,我们就可以类推出这种情况,提取出来的是一个DataFrame。即使我们只提取了一个数据出来。
这里有一个要注意的地方,对于切片的修改会应用到原DataFrame上。
例如,下面我们做一个切片,
data_v = data.iloc[:,:]然后对切片进行修改
data_v.iloc[2,2] = 2000我们会发现,原DataFrame的值也变了。


所以,不能用这种方法来备份一个DataFrame。
正确的方法是用DataFrame的copy方法。
根据索引值提取DataFrame的一列,或者根据索引值提取Series的一个值:
dateframe_name[column_name]
dateframe_name[column_name_list1+column_name_list2]
data.column_name
# 这两种提取列的方法返回的内容是一样的注意,在上面的方括号中,如果方括号内写的是一连串的字符串,name是只能按照column_name提取。如果写的一连串的True和False,那么是按照行提取的。
统计每一个组合有多少种情况:
data.value_counts()
# 注意,value_counts()不仅仅只能统计dataframe或者series里面的元素,对于列表里面的元素也是可以统计的。
# 例如,我们要统计sample=[1,2,3,2,1,4,1,1,2,5,3]中,每一个元素出现了几次,可以写:
pd.value_counts(sample)提取一个dataframe里面,某一列的值不为0的所有的行:
dataframe.loc[dataframe.column_name != '0']
# 这一行的效果是,如果这个dataframe的这一列里面的某一个值为0,那么这一整行都会被剔除
# 取非的另一种方法是用~符号,注意,~符号后面的内容要用括号括起来,原因是~号的运算优先级大于==号
df = df[~(df.rumormongerName=="")]查看index有没有重复值:
type1.index.is_unique判断一个值是否是NaN:
dataframe_name.iloc[i,j] is np.nan查看一个Series有哪些不重复的值:
dataframe.column_name.unique()
# 这一行,会把一个series里面所有可能出现的值列出来。用index或column来筛选:
df_Tableau.filter(like = "Total", axis = 0)
# axis=0表示对于index筛选,axis=1表示用column筛选
# 用来筛选的指标可以用item、like、regex来控制
# item表示必须完全匹配label
# like表示label中包含这个指标即可,不必完全相同
# regex表示用正则表达式匹配对于index或者column更加复杂的筛选,可以用一些自己定义的函数,对于column或者index name进行筛选,然后通过column names进行提取。
columns_needed = [item for item in data.columns.to_list() if 'Cusine' in item or 'SpendNew' in item or 'CityLevelNew_' in item or 'context_1119' in item]用某一列的值来筛选dataframe:
# 法一:
data[data['price'].values<=5000]
# 筛选data里面,price小于等于5000的所有observation。
# 这里面,<=符号也可以换成>=、==、!=等判断符号。
# 如果有多个条件,若多个条件时间是或的关系要用“|”而不能用or;
# 同理是和的关系要用“&”。且每一个条件用小括号括起来;
# 上面两句的原因是:对于逻辑运算符,比如 b1 and b2,python里等价于bool(b1) and bool(b2),但是对于bool Series,直接bool(bool Series)是不行的,就会出现上述错误,因为无法直接对一个Series使用bool函数。所以,我们要用位运算符来实现。pandas中,位运算符是类似于加减法这些运算的,因此直接对两个Series使用位运算符,就等价于对两个Series的相应位置的元素进行位运算
# 例如:data[(data['payment_period']==0) & (data['trial_completed']==False)]
# 法二:
data.query('courier_id==10007871')
# 用id来查询数据
# 法三: