Ftr:常规卷积操作
Fsq:squeeze操作,使用H x W大小的卷积核进行average pooling(也叫global average pooling),生成1 x 1 x C的向量
Fex:excitation操作。
 公式表示的是两个FC构成的bottleneck结构,防止过拟合,提高泛化能力。如下图,detla表示relu函数,sigma是sigmoid。
公式表示的是两个FC构成的bottleneck结构,防止过拟合,提高泛化能力。如下图,detla表示relu函数,sigma是sigmoid。
补充说明:论文中z和s的维度是一样的。Bottleneck先降维再升维,假设降维的比例系数r,实验结果精度也与r的大小有关。相关内容在文末说明。
Fscale:
 下标c可理解为channel-wise,每张通道的特征图 uc与对应的标量sc相乘。
下标c可理解为channel-wise,每张通道的特征图 uc与对应的标量sc相乘。
Fex中得到的向量中元素相当于对应channel的权重。
SE模块嵌入网络实例:
SE模块可嵌入到其他各类型如AlexNet,ResNet,InceptionNet,MobileNet,ShuffleNet等网络结构中,下图是嵌入到Inception与ResNet网络中的图示。
SE模块复杂度与性能:
以ResNet-50和SE-ResNet-50为例进行比较
|
|
计算量/GFLOPS
|
训练时间/ms
|
GPU推理时间
|
参数/million
|
|
ResNet-50
|
3.86
|
190
|
164
|
25
|
|
SE-ResNet-50
|
3.87
|
209
|
167
|
27.5
|
|
增加百分比
|
0.26%
|
5.26%
|
1.83%
|
10%
|
|
备注
|
|
在8个NVIDIA Titan X GPUs上执行一个前馈和反向操作
|
|
可通过移除最后一层网络的SE模块进一步减少参数增量到4%
|
补充说明:SE模块中的FC操作带来了非常大的参数增量。参数增量我们可以通过公式
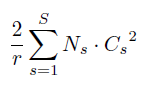 得到,其中r是降维比例,Cs是原某层网络的通道数,Ns指堆叠了多少层网络(论文描述为stage)。可结合bottleneck的说明图理解公式。我们也可以定量的想象到,随着网络层数加深,卷积特征图的通道数越来越大,W1,W2两个矩阵越来越大,bottleneck中FC的参数量也越来多。由此,为了减少参数量,网络最后一层不加入SE模块,虽然性能下降了0.1%,但参数增量下降至4%。
得到,其中r是降维比例,Cs是原某层网络的通道数,Ns指堆叠了多少层网络(论文描述为stage)。可结合bottleneck的说明图理解公式。我们也可以定量的想象到,随着网络层数加深,卷积特征图的通道数越来越大,W1,W2两个矩阵越来越大,bottleneck中FC的参数量也越来多。由此,为了减少参数量,网络最后一层不加入SE模块,虽然性能下降了0.1%,但参数增量下降至4%。
下图中为ImageNet数据集上分类任务(目标检测任务在论文中有涉及,此处不提)
上图中可看出,SE模块的引入对性能的提升是显著的,而且对现有的网络结构都有作用。图中画圈的地方可看到,SE-ResNet-50的top-5err几乎比得上ResNet-101,但参数量只有其一半。
降维系数r:
降维系数r作为网络的超参数,并不是越大越好。图中为r对精度的影响,虽然r增大带来了网络参数量的下降,但性能不是是单调变好。论文中解释为,这样的现象可能与过拟合有关。我存疑。
SE模块更多理解
在深度网络中,我们认为网络中低层layer学习到的是一些普遍的特征,深层次layer中学习到的特征更特殊化、更具有针对性。分类任务中,我们取四个不同的类,横坐标代表通道序号,纵坐标代表SE模块获得的权重,作图如下。a为低层layer,d为深层layer,可以看到低层layer中不同类SE在通道上分配的attention的分布是相似的,高层layer中出现差异。这佐证了低层次学普遍特征,深层学差异性特征的观点。
而且,在网络最后几层,观察到分配给不同通道的Attention都趋近于1如下图e,此时其实相当于不加SE模块;最后一层中如下图f,不同类的分布图又趋于一致,说明加入SE模块对分类任务的作用不大,佐证了前面提到的-网络最后不添加SE模块,性能下降非常小,但显著降低了参数量。
特别说明:禁止转载。欢迎交流学习。
Squeeze excitation network 以下简称SE-NetSE是一个在卷积特征图通道上分配Attention的模块,可嵌入到其他的的网络结构中。SE模块图示:下面说明如何计算attention,即分配给各通道权重值的计算方式。Ftr:常规卷积操作Fsq:squeeze操作,使用H x W大小的卷积核进行average pooling(也叫global average pooling),生成1 x 1 x C的向量Fex:excitation操作。 公式表示的是两个
注意力机制之SE
模块
Squeeze-and-Excitation Networks
注意力————一种将可用计算资源的
分配
偏向信号中信息量最大的分量的手段。注意力
模块
一般有两种:一种是空间注意力
模块
,一种是
通道
注意力
模块
,SE
模块
属于后者。
SE-block:通过该机制,网络可以学习使用全局信息来选择性地强调信息特征,并抑制不太有用的特征。
SE-block流程:
特征图U(H’W’C’)首先通过Squeeze操作传递,在空间维度上聚集特征图,产生11C的
通道
描述符。
之后是激励操作
SeNet学习笔记及仿真
SENet[1]是ImageNet 2017年的冠军模型,自SeNet提出后,ImageNet挑战赛就停止举办了。SENet同之前的ResNet一样,引入了一些技巧,可以在很大程度上降低模型的参数,并且提升模型的运算速度。
SENet全称Squeeze-and-Excitation Networks,中文名可以翻译为挤压和激励网络。SENet在ImageNet 2017取得了第一名的成绩,Top-5 error rate降低到了2.251%,官方的模型和代码在github仓库
注意力机制的文章之------
通道
注意力
SE-Net:Squeeze-and-Excitation Networks
论文
详解
论文
链接:https://arxiv.org/pdf/1709.01507.pdf
Github代码:https://github.com/hujie-frank/SENet
注意力机制最早用于自然语言处理(NLP),后来在计算机视觉(CV)也得到广泛的应用,之后注意力机制便被引入来进行视觉信息处理。注意力机制的核心思想就是能够从大量的信息中筛选出重要的信息。注意力机制可以分为
通道
1、简要介绍
这篇
论文
集中于
通道
间的关系,提出一种新颖的结构:SE block。它通过在特征
通道
之间建立相关性 ,可以自适应地校正
通道
间的特征。通过堆叠SE block构造了SENet结构,极大程度改善了
通道
的特征。
2、相关介绍
卷积神经网络是基于卷积的操作,它通过融合空间和
通道
上的信息到局部感受野上,以提取有用的信息。为了增强网络的表征能力,最近一些方法都是从空间上改善。
对于每个卷积层,我们学习了一组过滤器来表示输入
通道
上的局部空间连接。换句话说,卷积滤波器被用于:将空间信息和
通道
信息在局部感受野内结

