


R语言基础—apply函数家族


apply函数在我们平常的数据分析中具有重要的作用,其家族函数有以下几种:

各函数的用途如下表所示:
| 函数 | 用途 |
| apply | 遍历数组中的所有维度 |
| lapply | 遍历列表或向量的元素 |
| sapply | 遍历列表或向量的元素,然后简化输出 |
| tapply | 将函数运用与一个或多个因子的每个水平 |
| mapply | sapply的多元版本 |
| rapply | lapply的递归版本 |
| eapply | 运用函数遍历“环境”的具名元素 |
| vapply | 类似sapply,但可以设定返回值的类型。 |
主要为大家介绍前四种。
一、apply函数
apply()函数用于遍历数据对象的维度。其函数表达式为:apply(X, MARGIN, FUN, ...)
| 参数 | 意义 |
| X | 有维度的数据对象 |
| MARGIN | 在维度为2时,MARGIN=1表示对行进行运算,MARGIN=2时表示对列进行运算;维度为3及以上时,会对相应的维度数据进行操作 |
| FUN | 待运用的函数 |
| … | 其他参数 |
以下为示例:
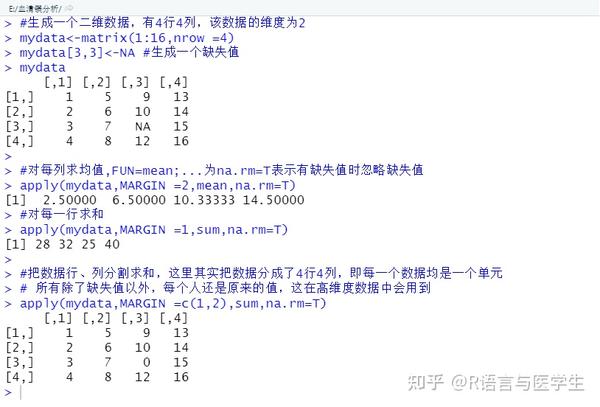
在平常我们一般处理的时二维数据,因此掌握这些足够,这样我们是不是能很快速的算出我们想要的值,如我们想知道列变量:年龄、身高、体重等的均值,我们直接对数据进行列运算即可。
二、lapply函数
lapply函数指把FUN指定的函数运用于列表的每一个元素,并返回列表结构输出。其函数为:lapply(X, FUN, ...),其参数意义和apply函数一样只是没有MARGIN参数。
> #创建有三个元素的列表
> Ryuyan<-list(p1=c(1,2,3),p2=c(4,5,6),p3=c(7,8,9))
> Ryuyan
$p1
[1] 1 2 3
$p2
[1] 4 5 6
$p3
[1] 7 8 9
> #对列表的每一个元素求均值
> lapply(Ryuyan,mean)
$p1
[1] 2
$p2
[1] 5
$p3
[1] 8
> #对向量进行运算
> #以下结果等价于log(1)、log(2)、log(3)
> lapply(1:3,log)
[[1]]
[1] 0
[[2]]
[1] 0.6931472
[[3]]
[1] 1.098612
> #数据框其实是向量的列表,因此我们也可以对数据框进行操作
> #可以发现以下结果和上面的是一样的
> Ryuyan<-data.frame(p1=c(1,2,3),p2=c(4,5,6),p3=c(7,8,9))
> Ryuyan
p1 p2 p3
1 1 4 7
2 2 5 8
3 3 6 9
> lapply(Ryuyan,mean)
$p1
[1] 2
$p2
[1] 5
$p3
[1] 8
lapply函数和apply函数的区别是一个返回的是列表,一个返回的是向量。
三、sapply函数
sapply函数是经过简单包装的lapply函数,sapply函数可以运用于列表或向量。
同样使用上面的数据示例。
#单个值会输出成向量
> sapply(Ryuyan,mean)
p1 p2 p3
2 5 8
#多个值会输出成矩阵
> sapply(Ryuyan,quantile)
p1 p2 p3
0% 1.0 4.0 7.0
25% 1.5 4.5 7.5
50% 2.0 5.0 8.0
75% 2.5 5.5 8.5
100% 3.0 6.0 9.0
四、tapply函数
tapply函数按一个或多个因子的水平分类,把FUN指定的函数运用于每一个向量。其函数为:
tapply(X, INDEX, FUN = NULL, ..., default = NA, simplify = TRUE)
| 参数 | 意义 |
| X | 待汇总的数据,通常为一个向量 |
| INDEX | 一个因子或因子列表,数据根据此变量分组 |
| FUN | 指定使用的函数 |
| … | 其他参数 |
#根据性别来计算男女的平均年龄
> tapply(myR$age,INDEX=myR$sex,mean)
male female
62.22583 64.22572
#根据是否为糖尿病及性别来分组计算平均年龄
> tapply(myR$age,INDEX=list(myR$sex,myR$DB),mean)
No diabetes diabetes
male 61.89896 63.85306
female 63.64329 67.09174
以上为大家简单的介绍了apply函数家族,大家可以适当的掌握,很多数据的运算等我们介绍到数据处理时,会有更简单的方式计算!但这些函数是最基本的,有助于我们编写函数时来执行特定的计算!
原文见:
