

通用编程语言Perl

Perl - Introduction
Perl是一种通用编程语言,最初是为文本操作而开发的,现在用于各种任务,包括系统管理,Web开发,网络编程,GUI开发等。
什么是Perl?
- Perl是一种稳定的跨平台编程语言。
- 虽然Perl不是官方缩写词,但很少有人将它用作 Practical Extraction and Report Language 。
- 它用于公共和私营部门的关键任务项目。
- Perl是一种 Open Source 软件,根据其 Artistic License 或 GNU General Public License (GPL) 。
- Perl由Larry Wall创建。
- Perl 1.0于1987年发布到usenet的alt.comp.sources。
- 在编写本教程时,最新版本的perl是5.16.2。
- Perl列于 Oxford English Dictionary 。
PC Magazine宣布Perl为其1998年开发工具类技术卓越奖的最终入围者。
Perl功能
- Perl采用其他语言的最佳功能,例如C,awk,sed,sh和BASIC等。
- Perls数据库集成接口DBI支持第三方数据库,包括Oracle,Sybase,Postgres,MySQL等。
- Perl使用HTML,XML和其他标记语言。
- Perl支持Unicode。
- Perl符合Y2K标准。
- Perl支持过程编程和面向对象编程。
- Perl通过XS或SWIG与外部C/C ++库连接。
- Perl是可扩展的。 Comprehensive Perl Archive Network( CPAN )提供了超过20,000个第三方模块。
- Perl解释器可以嵌入到其他系统中。
Perl和Web
- Perl曾经是最流行的Web编程语言,因为它具有文本操作功能和快速的开发周期。
- Perl被广泛称为“ 互联网的胶带 ”。
- Perl可以处理加密的Web数据,包括电子商务交易。
- Perl可以嵌入到Web服务器中,以便将处理速度提高2000%。
- Perl的 mod_perl 允许Apache Web服务器嵌入Perl解释器。
- Perl的 DBI 包使Web数据库集成变得容易。
Perl是解释
Perl是一种解释型语言,这意味着您的代码可以按原样运行,而无需创建非可移植可执行程序的编译阶段。
传统编译器将程序转换为机器语言。 当你运行Perl程序时,它首先被编译成一个字节代码,然后将其转换(当程序运行时)到机器指令中。 所以它与shell或Tcl不完全相同,它们在没有中间表示的情况下被 strictly 解释。
它也不像大多数C或C ++版本,它们直接编译成依赖于机器的格式。 介于两者之间,还有 Python 和 awk 以及Emacs .elc文件。
Perl - Environment
在我们开始编写Perl程序之前,让我们了解如何设置Perl环境。 Perl可在各种平台上使用 -
- Unix(Solaris,Linux,FreeBSD,AIX,HP/UX,SunOS,IRIX等)
- 赢9x/NT/2000/
- WinCE
- Macintosh(PPC,68K)
- Solaris(x86,SPARC)
- OpenVMS
- Alpha(7.2及更高版本)
- Symbian
- Debian GNU/kFreeBSD
- MirOS BSD
- And many more...
您的系统更有可能在其上安装了perl。 只需尝试在$提示符下给出以下命令 -
$perl -v
12如果您的计算机上安装了perl,那么您将收到如下消息:
This is perl 5, version 16, subversion 2 (v5.16.2) built for i686-linux
Perl may be copied only under the terms of either the Artistic License or the
GNU General Public License, which may be found in the Perl 5 source kit.
Complete documentation for Perl, including FAQ lists, should be found on
this system using "man perl" or "perldoc perl". If you have access to the
Internet, point your browser at http://www.perl.org/, the Perl Home Page.
12345678如果您尚未安装perl,请继续下一部分。
获得Perl安装
最新和最新的源代码,二进制文件,文档,新闻等可以在Perl的官方网站上找到。
Perl Official Website - https://www. perl.org/
您可以从以下站点下载Perl文档。
Perl Documentation Website - https://perldoc.perl.org
安装Perl
Perl分发适用于各种平台。 您只需下载适用于您的平台的二进制代码并安装Perl。
如果您的平台的二进制代码不可用,则需要C编译器手动编译源代码。 编译源代码在选择安装所需的功能方面提供了更大的灵活性。
以下是在各种平台上安装Perl的快速概述。
Unix和Linux安装
以下是在Unix/Linux机器上安装Perl的简单步骤。
- 打开Web浏览器并转到 https://www.perl.org/get.html.
- 点击链接下载适用于Unix/Linux的压缩源代码。
- 下载 perl-5.xytar.gz 文件并在$ prompt下发出以下命令。
$make install
1234567
NOTE - 这里是一个Unix提示符,你输入命令,所以确保你没有键入是一个Unix提示符,你输入命令,所以确保你没有键入键入上述命令。
这将在标准位置 /usr/local/bin 安装Perl,其库安装在 /usr/local/lib/perlXX ,其中XX是您正在使用的Perl版本。
发出 make 命令后编译源代码需要一段时间。 安装完成后,您可以在$ prompt处发出 perl -v 命令来检查perl安装。 如果一切正常,那么它将显示我们上面显示的消息。
Windows安装
以下是在Windows机器上安装Perl的步骤。
- 请访问Windows http://strawberryperl.com 上的Strawberry Perl安装链接
- 下载32位或64位版本的安装。
- 在Windows资源管理器中双击运行下载的文件。 这将打开Perl安装向导,它非常易于使用。 只需接受默认设置,等到安装完成,然后您就可以开始滚动!
Macintosh安装
为了构建您自己的Perl版本,您将需要'make',它是通常随Mac OS安装DVD提供的Apples开发人员工具的一部分。 您不需要最新版本的Xcode(现在需要付费)才能安装make。
以下是在Mac OS X计算机上安装Perl的简单步骤。
- 打开Web浏览器并转到 https://www. perl.org/get.html 。
- 点击链接下载适用于Mac OS X的压缩源代码。
- 下载 perl-5.xytar.gz 文件并在$ prompt下发出以下命令。
$make install
1234567
这将在标准位置 /usr/local/bin 安装Perl,其库安装在 /usr/local/lib/perlXX ,其中XX是您正在使用的Perl版本。
运行Perl
以下是启动Perl的不同方法。
交互式解释器 (Interactive Interpreter)
您可以通过从命令行启动它来输入 perl 并立即在交互式解释器中开始编码。 您可以从Unix,DOS或任何其他系统执行此操作,该系统为您提供命令行解释程序或shell窗口。
$perl -e <perl code> # Unix/Linux
C:>perl -e <perl code> # Windows/DOS
1234以下是所有可用命令行选项的列表 -
| Sr.No. | 选项和说明 |
|---|
命令行脚本 (Script from the Command-line)
Perl脚本是一个文本文件,它将perl代码保存在其中,并且可以通过调用应用程序上的解释器在命令行执行,如下所示 -
$perl script.pl # Unix/Linux
C:>perl script.pl # Windows/DOS
1234集成开发环境 (Integrated Development Environment)
您也可以从图形用户界面(GUI)环境运行Perl。 您所需要的只是系统上支持Perl的GUI应用程序。 您可以下载 Padre,Perl IDE 。 如果您熟悉Eclipse,还可以使用Eclipse插件 EPIC - Perl编辑器和IDE for Eclipse。
在继续下一章之前,请确保您的环境设置正确并且工作正常。 如果您无法正确设置环境,则可以从系统管理员处获取帮助。
后续章节中给出的所有示例都是在Linux的CentOS版本上使用v5.16.2版本执行的。
Perl - Syntax Overview
Perl借用了许多语言的语法和概念:awk,sed,C,Bourne Shell,Smalltalk,Lisp甚至英语。 但是,语言之间存在一些明显的差异。 本章旨在让您快速了解Perl中预期的语法。
Perl程序由一系列声明和语句组成,它们从顶部到底部运行。 循环,子例程和其他控制结构允许您在代码中跳转。 每个简单的语句都必须以分号(;)结尾。
Perl是一种自由格式语言:您可以根据自己的喜好对其进行格式化和缩进。 空格主要用于分隔标记,不像Python这样的语言,它是语法的重要组成部分,或者Fortran,它是无关紧要的。
第一个Perl计划
交互模式编程 (Interactive Mode Programming)
您可以在命令行中使用带 -e 选项的Perl解释器,这样您就可以从命令行执行Perl语句。 让我们在$ prompt尝试一下如下 -
$perl -e 'print "Hello World\n"'
12此执行将产生以下结果 -
Hello, world
12脚本模式编程
假设您已经处于$ prompt状态,让我们使用vi或vim编辑器打开一个文本文件hello.pl,并将以下行放在您的文件中。
#!/usr/bin/perl
# This will print "Hello, World"
print "Hello, world\n";
1234这里 /usr/bin/perl 实际上是perl解释器二进制文件。 在执行脚本之前,请务必更改脚本文件的模式并赋予执行权限,通常设置为0755可以正常工作,最后执行上述脚本,如下所示 -
$chmod 0755 hello.pl
$./hello.pl
123此执行将产生以下结果 -
Hello, world
12您可以将括号用于函数参数,或根据您的个人喜好省略它们。 他们只是偶尔需要澄清优先权问题。 以下两个陈述产生相同的结果。
print("Hello, world\n");
print "Hello, world\n";
123Perl文件扩展名
可以在任何普通的简单文本编辑器程序中创建Perl脚本。 每种类型的平台都有几种程序可用。 有许多程序员可以在网上下载程序。
作为Perl约定,必须使用.pl或.PL文件扩展名保存Perl文件,以便将其识别为正常运行的Perl脚本。 文件名可以包含数字,符号和字母,但不能包含空格。 在空格的位置使用下划线(_)。
Perl中的评论
任何编程语言的评论都是开发人员的朋友。 注释可用于使程序用户友好,并且它们只是被解释器跳过而不会影响代码功能。 例如,在上面的程序中,以hash # 开头的行是注释。
简单地说Perl中的注释以哈希符号开头并运行到行尾 -
# This is a comment in perl
12以=开头的行被解释为嵌入式文档(pod)的一部分的开头,编译器忽略所有后续行直到next = cut。 以下是示例 -
#!/usr/bin/perl
# This is a single line comment
print "Hello, world\n";
=begin comment
This is all part of multiline comment.
You can use as many lines as you like
These comments will be ignored by the
compiler until the next =cut is encountered.
12345678910这将产生以下结果 -
Hello, world
12Perl中的空格
Perl程序不关心空格。 以下程序完美无缺 -
#!/usr/bin/perl
print "Hello, world\n";
123但是如果空格在引用的字符串中,那么它们将按原样打印。 例如 -
#!/usr/bin/perl
# This would print with a line break in the middle
print "Hello
world\n";
12345这将产生以下结果 -
Hello
world
123当在引号之外使用时,所有类型的空格(如空格,制表符,换行符等)对于解释器都是等效的。 只包含空格(可能带有注释)的行称为空行,Perl完全忽略它。
Perl中的单引号和双引号
您可以在文字字符串周围使用双引号或单引号,如下所示 -
#!/usr/bin/perl
print "Hello, world\n";
print 'Hello, world\n';
1234这将产生以下结果 -
Hello, world
Hello, world\n$
123单引号和双引号存在重要差异。 只有双引号 interpolate 变量和特殊字符(如换行符\ n),而单引号不插入任何变量或特殊字符。 检查下面的示例我们使用$ a作为变量来存储值并稍后打印该值 -
#!/usr/bin/perl
$a = 10;
print "Value of a = $a\n";
print 'Value of a = $a\n';
12345这将产生以下结果 -
Value of a = 10
Value of a = $a\n$
123“这里”文件
您可以非常舒适地存储或打印多行文字。 即使您可以使用“here”文档中的变量。 下面是一个简单的语法,仔细检查<
标识符可以是一个单词或一些引用的文本,就像我们在下面使用EOF一样。 如果引用了标识符,则您使用的引用类型决定了对此docoment内部文本的处理方式,就像在常规引用中一样。 不带引号的标识符就像双引号一样。
#!/usr/bin/perl
$a = 10;
$var = <<"EOF";
This is the syntax for here document and it will continue
until it encounters a EOF in the first line.
This is case of double quote so variable value will be
interpolated. For example value of a = $a
print "$var\n";
$var = <<'EOF';
This is case of single quote so variable value will be
interpolated. For example value of a = $a
print "$var\n";
123456789101112131415这将产生以下结果 -
This is the syntax for here document and it will continue
until it encounters a EOF in the first line.
This is case of double quote so variable value will be
interpolated. For example value of a = 10
This is case of single quote so variable value will be
interpolated. For example value of a = $a
1234567逃脱角色
Perl使用反斜杠(\)字符来转义可能干扰我们代码的任何类型的字符。 让我们举一个例子,我们想要打印双引号和$ sign -
#!/usr/bin/perl
$result = "This is \"number\"";
print "$result\n";
print "\$result\n";
12345这将产生以下结果 -
This is "number"
$result
123Perl标识符
Perl标识符是用于标识变量,函数,类,模块或其他对象的名称。 Perl变量名称以$,@或%开头,后跟零个或多个字母,下划线和数字(0到9)。
Perl不允许标识符中的标点符号,如@,$和%。 Perl是一种 case sensitive 编程语言。 因此, $Manpower 和 $manpower 是Perl中的两个不同的标识符。
Perl - Data Types
Perl是一种松散类型的语言,在程序中使用时无需为数据指定类型。 Perl解释器将根据数据本身的上下文选择类型。
Perl有三种基本数据类型:标量,标量数组和标量散列,也称为关联数组。 以下是有关这些数据类型的一些细节。
| Sr.No. | 类型和描述 |
|---|
数字文字
Perl在内部将所有数字存储为有符号整数或双精度浮点值。 数字文字以下列任何浮点或整数格式指定 -
| 类型 | 值 |
|---|
字符串常量 (String Literals)
字符串是字符序列。 它们通常是由单引号(')或双引号引号组成的字母数字值。它们的工作方式与UNIX shell引号非常相似,您可以使用单引号字符串和双引号字符串。
双引号字符串文字允许变量插值,而单引号字符串则不允许。 当它们以反斜杠进行时有某些字符,具有特殊含义,它们用于表示换行符(\ n)或制表符(\ t)。
您可以直接在双引号字符串中嵌入换行符或任何以下转义序列 -
| 逃脱序列 | 含义 |
|---|
例子 (Example)
让我们再看一下字符串在单引号和双引号中的行为方式。 这里我们将使用上表中提到的字符串转义,并将使用标量变量来分配字符串值。
#!/usr/bin/perl
# This is case of interpolation.
$str = "Welcome to \niowiki.com!";
print "$str\n";
# This is case of non-interpolation.
$str = 'Welcome to \niowiki.com!';
print "$str\n";
# Only W will become upper case.
$str = "\uwelcome to iowiki.com!";
print "$str\n";
# Whole line will become capital.
$str = "\UWelcome to iowiki.com!";
print "$str\n";
# A portion of line will become capital.
$str = "Welcome to \Uiowiki\E.com!";
print "$str\n";
# Backsalash non alpha-numeric including spaces.
$str = "\QWelcome to iowiki's family";
print "$str\n";
1234567891011121314151617181920这将产生以下结果 -
Welcome to
iowiki.com!
Welcome to \niowiki.com!
Welcome to iowiki.com!
WELCOME TO iowiki.com!
Welcome to iowiki.com!
Welcome\ to\ iowiki\'s\ family
12345678Perl - Variables
变量是用于存储值的保留存储器位置。 这意味着当您创建变量时,您在内存中保留了一些空间。
根据变量的数据类型,解释器分配内存并决定可以存储在保留内存中的内容。 因此,通过为变量分配不同的数据类型,可以在这些变量中存储整数,小数或字符串。
我们了解到Perl具有以下三种基本数据类型 -
- Scalars
- Arrays
- Hashes
因此,我们将在Perl中使用三种类型的变量。 scalar 变量将以美元符号($)开头,它可以存储数字,字符串或引用。 array 变量将以符号@开头,它将存储有序的标量列表。 最后, Hash 变量将以符号%开头,并将用于存储键/值对的集合。
Perl将每个变量类型保存在单独的命名空间中。 因此,您可以在不担心冲突的情况下,为标量变量,数组或散列使用相同的名称。 这意味着$ foo和@foo是两个不同的变量。
创建变量
不必显式声明Perl变量来保留内存空间。 为变量赋值时,声明会自动发生。 等号(=)用于为变量赋值。
请注意,如果我们在程序中使用 use strict 语句,则必须在使用之前声明变量。
=运算符左边的操作数是变量的名称,=运算符右边的操作数是存储在变量中的值。 例如 -
$age = 25; # An integer assignment
$name = "John Paul"; # A string
$salary = 1445.50; # A floating point
1234这里25,“John Paul”和1445.50分别是分配给 $age , $name 和 $salary 变量的值。 不久我们将看到如何为数组和散列分配值。
标量变量
标量是单个数据单位。 该数据可以是整数,浮点数,字符,字符串,段落或整个网页。 简单地说它可以是任何东西,但只是一件事。
这是一个使用标量变量的简单示例 -
#!/usr/bin/perl
$age = 25; # An integer assignment
$name = "John Paul"; # A string
$salary = 1445.50; # A floating point
print "Age = $age\n";
print "Name = $name\n";
print "Salary = $salary\n";
12345678这将产生以下结果 -
Age = 25
Name = John Paul
Salary = 1445.5
1234数组变量
数组是存储标量值的有序列表的变量。 数组变量前面有“at”(@)符号。 要引用数组的单个元素,您将使用带有变量名的美元符号($),后跟方括号中元素的索引。
这是一个使用数组变量的简单示例 -
#!/usr/bin/perl
@ages = (25, 30, 40);
@names = ("John Paul", "Lisa", "Kumar");
print "\$ages[0] = $ages[0]\n";
print "\$ages[1] = $ages[1]\n";
print "\$ages[2] = $ages[2]\n";
print "\$names[0] = $names[0]\n";
print "\$names[1] = $names[1]\n";
print "\$names[2] = $names[2]\n";
12345678910这里我们在$ sign之前使用了escape符号(\)来打印它。 其他Perl会将其理解为变量并将其打印出来。 执行时,这将产生以下结果 -
$ages[0] = 25
$ages[1] = 30
$ages[2] = 40
$names[0] = John Paul
$names[1] = Lisa
$names[2] = Kumar
1234567哈希变量
散列是一组 key/value 对。 哈希变量前面有百分号(%)符号。 要引用哈希的单个元素,您将使用哈希变量名称,后跟与大括号中的值关联的“键”。
这是一个使用哈希变量的简单示例 -
#!/usr/bin/perl
%data = ('John Paul', 45, 'Lisa', 30, 'Kumar', 40);
print "\$data{'John Paul'} = $data{'John Paul'}\n";
print "\$data{'Lisa'} = $data{'Lisa'}\n";
print "\$data{'Kumar'} = $data{'Kumar'}\n";
123456这将产生以下结果 -
$data{'John Paul'} = 45
$data{'Lisa'} = 30
$data{'Kumar'} = 40
1234变量上下文
Perl基于Context不同地处理相同的变量,即使用变量的情况。 我们来看看下面的例子 -
#!/usr/bin/perl
@names = ('John Paul', 'Lisa', 'Kumar');
@copy = @names;
$size = @names;
print "Given names are : @copy\n";
print "Number of names are : $size\n";
1234567这将产生以下结果 -
Given names are : John Paul Lisa Kumar
Number of names are : 3
123这里@names是一个数组,已在两个不同的上下文中使用。 首先我们将它复制到任何其他数组,即list,所以它返回所有元素,假设上下文是列表上下文。 接下来我们使用相同的数组并尝试将此数组存储在标量中,因此在这种情况下,它返回此数组中的元素数量,假设上下文是标量上下文。 下表列出了各种情况 -
| Sr.No. | 上下文和描述 |
|---|
Perl - Scalars
标量是单个数据单位。 该数据可以是整数,浮点数,字符,字符串,段落或整个网页。
这是一个使用标量变量的简单示例 -
#!/usr/bin/perl
$age = 25; # An integer assignment
$name = "John Paul"; # A string
$salary = 1445.50; # A floating point
print "Age = $age\n";
print "Name = $name\n";
print "Salary = $salary\n";
12345678这将产生以下结果 -
Age = 25
Name = John Paul
Salary = 1445.5
1234数字标量
标量通常是数字或字符串。 以下示例演示了各种类型的数字标量的使用 -
#!/usr/bin/perl
$integer = 200;
$negative = -300;
$floating = 200.340;
$bigfloat = -1.2E-23;
# 377 octal, same as 255 decimal
$octal = 0377;
# FF hex, also 255 decimal
$hexa = 0xff;
print "integer = $integer\n";
print "negative = $negative\n";
print "floating = $floating\n";
print "bigfloat = $bigfloat\n";
print "octal = $octal\n";
print "hexa = $hexa\n";
12345678910111213141516这将产生以下结果 -
integer = 200
negative = -300
floating = 200.34
bigfloat = -1.2e-23
octal = 255
hexa = 255
1234567字符串标量
以下示例演示了各种类型的字符串标量的用法。 注意单引号字符串和双引号字符串之间的区别 -
#!/usr/bin/perl
$var = "This is string scalar!";
$quote = 'I m inside single quote - $var';
$double = "This is inside single quote - $var";
$escape = "This example of escape -\tHello, World!";
print "var = $var\n";
print "quote = $quote\n";
print "double = $double\n";
print "escape = $escape\n";
12345678910这将产生以下结果 -
var = This is string scalar!
quote = I m inside single quote - $var
double = This is inside single quote - This is string scalar!
escape = This example of escape - Hello, World
12345标量运算
您将在单独的章节中看到Perl中可用的各种运算符的详细信息,但在这里我们将列出一些数字和字符串运算。
#!/usr/bin/perl
$str = "hello" . "world"; # Concatenates strings.
$num = 5 + 10; # adds two numbers.
$mul = 4 * 5; # multiplies two numbers.
$mix = $str . $num; # concatenates string and number.
print "str = $str\n";
print "num = $num\n";
print "mix = $mix\n";
123456789这将产生以下结果 -
str = helloworld
num = 15
mul = 20
mix = helloworld15
12345多线串
如果要在程序中引入多行字符串,可以使用下面的标准单引号 -
#!/usr/bin/perl
$string = 'This is
a multiline
string';
print "$string\n";
123456这将产生以下结果 -
This is
a multiline
string
1234您也可以使用“here”文档语法来存储或打印多行,如下所示 -
#!/usr/bin/perl
print <<EOF;
This is
a multiline
string
1234567这也会产生相同的结果 -
This is
a multiline
string
1234V-Strings
v1.20.300.4000形式的文字被解析为由具有指定序数的字符组成的字符串。 此表单称为v-strings。
v-string提供了一种替代且更易读的方式来构造字符串,而不是使用稍微不那么易读的插值形式“\ x {1}\x {14}\x {12c}\x {fa}}”。
它们是以av开头的任何文字,后跟一个或多个点分隔元素。 例如 -
#!/usr/bin/perl
$smile = v9786;
$foo = v102.111.111;
$martin = v77.97.114.116.105.110;
print "smile = $smile\n";
print "foo = $foo\n";
print "martin = $martin\n";
12345678这也会产生相同的结果 -
smile = ☺
foo = foo
martin = Martin
Wide character in print at main.pl line 7.
12345特殊文字
到目前为止,你必须对字符串标量及其连接和插值操作有一种感觉。 所以,让我告诉你三个特殊的文字 FILE ,_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
它们可能仅用作单独的标记,不会插入字符串中。 检查以下示例 -
#!/usr/bin/perl
print "File name ". __FILE__ . "\n";
print "Line Number " . __LINE__ ."\n";
print "Package " . __PACKAGE__ ."\n";
# they can not be interpolated
print "__FILE__ __LINE__ __PACKAGE__\n";
1234567这将产生以下结果 -
File name hello.pl
Line Number 4
Package main
__FILE__ __LINE__ __PACKAGE__
12345Perl - Arrays
数组是存储标量值的有序列表的变量。 数组变量前面有“at”(@)符号。 要引用数组的单个元素,您将使用带有变量名的美元符号($),后跟方括号中元素的索引。
这是一个使用数组变量的简单示例 -
#!/usr/bin/perl
@ages = (25, 30, 40);
@names = ("John Paul", "Lisa", "Kumar");
print "\$ages[0] = $ages[0]\n";
print "\$ages[1] = $ages[1]\n";
print "\$ages[2] = $ages[2]\n";
print "\$names[0] = $names[0]\n";
print "\$names[1] = $names[1]\n";
print "\$names[2] = $names[2]\n";
12345678910这里我们在$ sign之前使用了转义符号(\)来打印它。 其他Perl会将其理解为变量并将其打印出来。 执行时,这将产生以下结果 -
$ages[0] = 25
$ages[1] = 30
$ages[2] = 40
$names[0] = John Paul
$names[1] = Lisa
$names[2] = Kumar
1234567在Perl中,列表和数组术语通常被用作可互换的术语。 但列表是数据,数组是变量。
数组创建
数组变量以@符号为前缀,并使用括号或qw运算符填充。 例如 -
@array = (1, 2, 'Hello');
@array = qw/This is an array/;
123第二行使用qw //运算符,它返回一个字符串列表,用空格分隔分隔的字符串。 在这个例子中,这导致了一个四元素阵列; 第一个元素是'this',last(第四个)是'array'。 这意味着您可以使用以下不同的行 -
@days = qw/Monday
Tuesday
Sunday/;
12345您还可以通过单独分配每个值来填充数组,如下所示 -
$array[0] = 'Monday';
$array[6] = 'Sunday';
1234访问数组元素 (Accessing Array Elements)
从数组访问单个元素时,必须在变量前面加上美元符号($),然后在变量名称后面的方括号中附加元素索引。 例如 -
#!/usr/bin/perl
@days = qw/Mon Tue Wed Thu Fri Sat Sun/;
print "$days[0]\n";
print "$days[1]\n";
print "$days[2]\n";
print "$days[6]\n";
print "$days[-1]\n";
print "$days[-7]\n";
123456789这将产生以下结果 -
Mon
1234567数组索引从零开始,因此要访问第一个元素,您需要将0作为索引。 您还可以给出负索引,在这种情况下,您可以从数组的末尾而不是从头开始选择元素。 这意味着以下 -
print $days[-1]; # outputs Sun
print $days[-7]; # outputs Mon
123顺序数组
Perl提供了序列号和字母的快捷方式。 例如,在计算到100时,不是键入每个元素,而是可以执行如下操作 -
#!/usr/bin/perl
@var_10 = (1..10);
@var_20 = (10..20);
@var_abc = (a..z);
print "@var_10\n"; # Prints number from 1 to 10
print "@var_20\n"; # Prints number from 10 to 20
print "@var_abc\n"; # Prints number from a to z
12345678这里双点(..)称为 range operator 。 这将产生以下结果 -
1 2 3 4 5 6 7 8 9 10
10 11 12 13 14 15 16 17 18 19 20
a b c d e f g h i j k l m n o p q r s t u v w x y z
1234数组大小
可以使用数组上的标量上下文确定数组的大小 - 返回的值将是数组中元素的数量 -
@array = (1,2,3);
print "Size: ",scalar @array,"\n";
123返回的值将始终是数组的物理大小,而不是有效元素的数量。 您可以使用此片段演示这一点,以及标量@array和$#数组之间的区别如下 -
#!/usr/bin/perl
@array = (1,2,3);
$array[50] = 4;
$size = @array;
$max_index = $#array;
print "Size: $size\n";
print "Max Index: $max_index\n";
12345678这将产生以下结果 -
Size: 51
Max Index: 50
123数组中只有四个元素包含信息,但数组长度为51个元素,最高索引为50。
在数组中添加和删除元素
Perl提供了许多有用的函数来添加和删除数组中的元素。 您可能有一个问题是什么功能? 到目前为止,您已使用 print 功能打印各种值。 类似地,存在各种其他功能或有时称为子例程,其可用于各种其他功能。
| Sr.No. | 类型和描述 |
|---|
#!/usr/bin/perl
# create a simple array
@coins = ("Quarter","Dime","Nickel");
print "1. \@coins = @coins\n";
# add one element at the end of the array
push(@coins, "Penny");
print "2. \@coins = @coins\n";
# add one element at the beginning of the array
unshift(@coins, "Dollar");
print "3. \@coins = @coins\n";
# remove one element from the last of the array.
pop(@coins);
print "4. \@coins = @coins\n";
# remove one element from the beginning of the array.
shift(@coins);
print "5. \@coins = @coins\n";
1234567891011121314151617这将产生以下结果 -
1. @coins = Quarter Dime Nickel
2. @coins = Quarter Dime Nickel Penny
3. @coins = Dollar Quarter Dime Nickel Penny
4. @coins = Dollar Quarter Dime Nickel
5. @coins = Quarter Dime Nickel
123456切片阵元素
您还可以从数组中提取“切片” - 也就是说,您可以从数组中选择多个项目以生成另一个数组。
#!/usr/bin/perl
@days = qw/Mon Tue Wed Thu Fri Sat Sun/;
@weekdays = @days[3,4,5];
print "@weekdays\n";
12345这将产生以下结果 -
Thu Fri Sat
12切片的规范必须包含有效索引的列表,无论是正数还是负数,每个都用逗号分隔。 对于速度,您还可以使用 .. 范围运算符 -
#!/usr/bin/perl
@days = qw/Mon Tue Wed Thu Fri Sat Sun/;
@weekdays = @days[3..5];
print "@weekdays\n";
12345这将产生以下结果 -
Thu Fri Sat
12替换数组元素
现在我们将介绍另一个名为 splice() 函数,它具有以下语法 -
splice @ARRAY, OFFSET [ , LENGTH [ , LIST ] ]
12此函数将删除由OFFSET和LENGTH指定的@ARRAY元素,并将其替换为LIST(如果已指定)。 最后,它返回从数组中删除的元素。 以下是示例 -
#!/usr/bin/perl
@nums = (1..20);
print "Before - @nums\n";
splice(@nums, 5, 5, 21..25);
print "After - @nums\n";
123456这将产生以下结果 -
Before - 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
After - 1 2 3 4 5 21 22 23 24 25 11 12 13 14 15 16 17 18 19 20
123这里,实际的替换从第6个数字开始,然后用数字21,22,23,24和25将5个元素从6替换为10。
将字符串转换为数组
让我们再看一个名为 split() 函数,它具有以下语法 -
split [ PATTERN [ , EXPR [ , LIMIT ] ] ]
12此函数将字符串拆分为字符串数组,并将其返回。 如果指定了LIMIT,则最多分割为该字段数。 如果省略PATTERN,则拆分空格。 以下是示例 -
#!/usr/bin/perl
# define Strings
$var_string = "Rain-Drops-On-Roses-And-Whiskers-On-Kittens";
$var_names = "Larry,David,Roger,Ken,Michael,Tom";
# transform above strings into arrays.
@string = split('-', $var_string);
@names = split(',', $var_names);
print "$string[3]\n"; # This will print Roses
print "$names[4]\n"; # This will print Michael
12345678910这将产生以下结果 -
Roses
Michael
123将数组转换为字符串
我们可以使用 join() 函数重新加入数组元素并形成一个长标量字符串。 此函数具有以下语法 -
join EXPR, LIST
12此函数将单独的LIST字符串连接成一个字符串,其字段由EXPR的值分隔,并返回字符串。 以下是示例 -
#!/usr/bin/perl
# define Strings
$var_string = "Rain-Drops-On-Roses-And-Whiskers-On-Kittens";
$var_names = "Larry,David,Roger,Ken,Michael,Tom";
# transform above strings into arrays.
@string = split('-', $var_string);
@names = split(',', $var_names);
$string1 = join( '-', @string );
$string2 = join( ',', @names );
print "$string1\n";
print "$string2\n";
123456789101112这将产生以下结果 -
Rain-Drops-On-Roses-And-Whiskers-On-Kittens
Larry,David,Roger,Ken,Michael,Tom
123排序数组
sort() 函数根据ASCII数字标准对数组的每个元素进行排序。 此函数具有以下语法 -
sort [ SUBROUTINE ] LIST
12此函数对LIST进行排序并返回已排序的数组值。 如果指定了SUBROUTINE,则在对元素进行排序时应用SUBTROUTINE中的指定逻辑。
#!/usr/bin/perl
# define an array
@foods = qw(pizza steak chicken burgers);
print "Before: @foods\n";
# sort this array
@foods = sort(@foods);
print "After: @foods\n";
12345678这将产生以下结果 -
Before: pizza steak chicken burgers
After: burgers chicken pizza steak
123请注意,排序是根据单词的ASCII数值执行的。 因此,最好的选择是首先将数组的每个元素转换为小写字母,然后执行sort函数。
$ [特殊变量
到目前为止,您已经看到我们在程序中定义的简单变量,并使用它们来存储和打印标量和数组值。 Perl提供了许多特殊变量,这些变量具有预定义。
我们有一个特殊的变量,写成 $[ 。 此特殊变量是包含所有数组的第一个索引的标量。 因为Perl数组具有从零开始的索引,所以[几乎总是为0.但是如果将[几乎总是为0.但是如果将 [设置为1,那么所有数组都将使用基于索引的索引。 建议不要使用除零之外的任何其他索引。 但是,让我们举一个例子来说明$ [变量 - 的用法 -
#!/usr/bin/perl
# define an array
@foods = qw(pizza steak chicken burgers);
print "Foods: @foods\n";
# Let's reset first index of all the arrays.
$[ = 1;
print "Food at \@foods[1]: $foods[1]\n";
print "Food at \@foods[2]: $foods[2]\n";
123456789这将产生以下结果 -
Foods: pizza steak chicken burgers
Food at @foods[1]: pizza
Food at @foods[2]: steak
1234合并数组
因为数组只是逗号分隔的值序列,所以您可以将它们组合在一起,如下所示 -
#!/usr/bin/perl
@numbers = (1,3,(4,5,6));
print "numbers = @numbers\n";
1234这将产生以下结果 -
numbers = 1 3 4 5 6
12嵌入式阵列只是成为主阵列的一部分,如下所示 -
#!/usr/bin/perl
@odd = (1,3,5);
@even = (2, 4, 6);
@numbers = (@odd, @even);
print "numbers = @numbers\n";
123456这将产生以下结果 -
numbers = 1 3 5 2 4 6
12从列表中选择元素
列表表示法与数组表示法相同。 您可以通过在列表中附加方括号并提供一个或多个索引来从数组中提取元素 -
#!/usr/bin/perl
$var = (5,4,3,2,1)[4];
print "value of var = $var\n"
1234这将产生以下结果 -
value of var = 1
12同样,我们可以提取切片,但不需要前导@字符 -
#!/usr/bin/perl
@list = (5,4,3,2,1)[1..3];
print "Value of list = @list\n";
1234这将产生以下结果 -
Value of list = 4 3 2
12Perl - Hashes
散列是一组 key/value 对。 哈希变量前面有百分号(%)符号。 要引用散列的单个元素,您将使用前面带有“$”符号的哈希变量名称,后跟与大括号中的值相关联的“键”。
这是一个使用哈希变量的简单示例 -
#!/usr/bin/perl
%data = ('John Paul', 45, 'Lisa', 30, 'Kumar', 40);
print "\$data{'John Paul'} = $data{'John Paul'}\n";
print "\$data{'Lisa'} = $data{'Lisa'}\n";
print "\$data{'Kumar'} = $data{'Kumar'}\n";
123456这将产生以下结果 -
$data{'John Paul'} = 45
$data{'Lisa'} = 30
$data{'Kumar'} = 40
1234创建哈希
哈希是以下列两种方式之一创建的。 在第一种方法中,您可以逐个为命名键分配值 -
$data{'John Paul'} = 45;
$data{'Lisa'} = 30;
$data{'Kumar'} = 40;
1234在第二种情况下,您使用一个列表,该列表通过从列表中获取单个对来转换:该对的第一个元素用作键,第二个元素用作值。 例如 -
%data = ('John Paul', 45, 'Lisa', 30, 'Kumar', 40);
12为清楚起见,您可以使用=>作为别名,以指示键/值对,如下所示 -
%data = ('John Paul' => 45, 'Lisa' => 30, 'Kumar' => 40);
12这是上述形式的另一个变体,看看它,这里所有的键都以连字符( - )开头,并且它们周围不需要引号 -
%data = (-JohnPaul => 45, -Lisa => 30, -Kumar => 40);
12但重要的是要注意有一个单词,即没有空格键已经在这种形式的哈希形式中使用,如果你以这种方式构建你的哈希,那么只能使用连字符访问键,如下所示。
$val = %data{-JohnPaul}
$val = %data{-Lisa}
123访问哈希元素
从散列访问单个元素时,必须在变量前面加上美元符号($),然后在变量名称后面的大括号中附加元素键。 例如 -
#!/usr/bin/perl
%data = ('John Paul' => 45, 'Lisa' => 30, 'Kumar' => 40);
print "$data{'John Paul'}\n";
print "$data{'Lisa'}\n";
print "$data{'Kumar'}\n";
123456这将产生以下结果 -
45
1234提取切片
您可以提取哈希切片,就像从数组中提取切片一样。 您需要为变量使用@前缀来存储返回的值,因为它们将是值列表 -
#!/uer/bin/perl
%data = (-JohnPaul => 45, -Lisa => 30, -Kumar => 40);
@array = @data{-JohnPaul, -Lisa};
print "Array : @array\n";
12345这将产生以下结果 -
Array : 45 30
12提取键和值
您可以使用 keys 函数从散列中获取所有键的列表,该函数具有以下语法 -
keys %HASH
12此函数返回指定散列的所有键的数组。 以下是示例 -
#!/usr/bin/perl
%data = ('John Paul' => 45, 'Lisa' => 30, 'Kumar' => 40);
@names = keys %data;
print "$names[0]\n";
print "$names[1]\n";
print "$names[2]\n";
1234567这将产生以下结果 -
Lisa
John Paul
Kumar
1234同样,您可以使用 values 函数来获取所有值的列表。 此函数具有以下语法 -
values %HASH
12此函数返回由指定哈希的所有值组成的普通数组。 以下是示例 -
#!/usr/bin/perl
%data = ('John Paul' => 45, 'Lisa' => 30, 'Kumar' => 40);
@ages = values %data;
print "$ages[0]\n";
print "$ages[1]\n";
print "$ages[2]\n";
1234567这将产生以下结果 -
30
1234检查是否存在
如果您尝试从不存在的哈希中访问键/值对,则通常会获得 undefined 值,如果您已打开警告,则会在运行时生成警告。 你可以通过使用 exists 函数解决这个问题,如果命名密钥存在,则返回true,而不管它的值是什么 -
#!/usr/bin/perl
%data = ('John Paul' => 45, 'Lisa' => 30, 'Kumar' => 40);
if( exists($data{'Lisa'} ) ) {
print "Lisa is $data{'Lisa'} years old\n";
} else {
print "I don't know age of Lisa\n";
12345678这里我们介绍了IF ... ELSE语句,我们将在另一章中进行研究。 现在你只假设 if( condition ) 部分只在给定条件为真时执行,否则将执行part。 因此,当我们执行上述程序时,它会产生以下结果,因为这里给定的条件 exists($data{'Lisa'} 返回true -
Lisa is 30 years old
12获得哈希大小
您可以通过使用键或值上的标量上下文来获取大小(即散列中的元素数)。 简单地说首先你必须得到一个键或值的数组,然后你可以得到如下数组的大小 -
#!/usr/bin/perl
%data = ('John Paul' => 45, 'Lisa' => 30, 'Kumar' => 40);
@keys = keys %data;
$size = @keys;
print "1 - Hash size: is $size\n";
@values = values %data;
$size = @values;
print "2 - Hash size: is $size\n";
123456789这将产生以下结果 -
1 - Hash size: is 3
2 - Hash size: is 3
123在哈希中添加和删除元素
使用简单赋值运算符可以使用一行代码添加新的键/值对。 但是要从哈希中删除元素,您需要使用 delete 函数,如下例所示 -
#!/usr/bin/perl
%data = ('John Paul' => 45, 'Lisa' => 30, 'Kumar' => 40);
@keys = keys %data;
$size = @keys;
print "1 - Hash size: is $size\n";
# adding an element to the hash;
$data{'Ali'} = 55;
@keys = keys %data;
$size = @keys;
print "2 - Hash size: is $size\n";
# delete the same element from the hash;
delete $data{'Ali'};
@keys = keys %data;
$size = @keys;
print "3 - Hash size: is $size\n";
12345678910111213141516这将产生以下结果 -
1 - Hash size: is 3
2 - Hash size: is 4
3 - Hash size: is 3
1234Perl Conditional Statements - IF...ELSE
Perl条件语句有助于决策,这需要程序员指定一个或多个要由程序评估或测试的条件,以及在条件被确定为真时要执行的一个或多个语句,以及可选的其他条件如果确定条件为假,则执行语句。
以下是大多数编程语言中的典型决策结构的一般性 -

数字0,字符串'0'和“”,空列表()和undef在布尔上下文中都是 false ,所有其他值都为 true 。 否定真正的价值 ! 或 not 返回特殊的假值。
Perl编程语言提供以下类型的条件语句。
| Sr.No. | 声明和说明 |
|---|
(The ? : Operator)
我们检查 conditional operator ? : conditional operator ? : 可用于替换 if...else 语句。 它有以下一般形式 -
Exp1 ? Exp2 : Exp3;
12Exp1,Exp2和Exp3是表达式。 注意结肠的使用和放置。
一个值? 表达式的确定方式如下:评估Exp1。 如果是,那么Exp2会被评估并成为整个值吗? 表达。 如果Exp1为false,则计算Exp3,其值将成为表达式的值。 下面是一个使用此运算符的简单示例 -
#!/usr/local/bin/perl
$name = "Ali";
$age = 10;
$status = ($age > 60 )? "A senior citizen" : "Not a senior citizen";
print "$name is - $status\n";
123456这将产生以下结果 -
Ali is - Not a senior citizen
12Perl - Loops
可能存在需要多次执行代码块的情况。 通常,语句按顺序执行:首先执行函数中的第一个语句,然后执行第二个语句,依此类推。
编程语言提供各种控制结构,允许更复杂的执行路径。
循环语句允许我们多次执行语句或语句组,以下是大多数编程语言中循环语句的一般形式 -
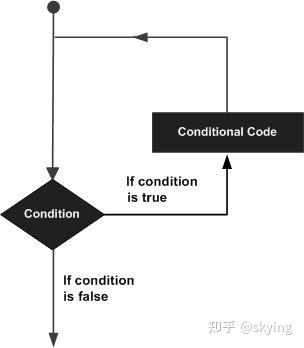
Perl编程语言提供以下类型的循环来处理循环要求。
| Sr.No. | 循环类型和描述 |
|---|
循环控制语句 (Loop Control Statements)
循环控制语句将执行从其正常顺序更改。 当执行离开作用域时,将销毁在该作用域中创建的所有自动对象。
Perl支持以下控制语句。 单击以下链接以检查其详细信息。
| Sr.No. | 控制声明和描述 |
|---|
无限循环 (The Infinite Loop)
如果条件永远不会变为假,则循环变为无限循环。 for 循环传统上用于此目的。 由于不需要构成 for 循环的三个表达式,因此可以通过将条件表达式留空来创建无限循环。
#!/usr/local/bin/perl
for( ; ; ) {
printf "This loop will run forever.\n";
12345您可以按Ctrl + C键终止上述无限循环。
当条件表达式不存在时,假定为真。 您可能有一个初始化和增量表达式,但作为程序员,更常见的是使用for(;;)构造来表示无限循环。
Perl - Operators
什么是运算符?
使用表达式 4 + 5 is equal to 9 可以给出简单的答案。 这里4和5被称为操作数,+被称为操作符。 Perl语言支持许多运算符类型,但以下是重要且最常用的运算符列表 -
- 算术运算符
- 平等运算符
- 逻辑运算符
- 分配运算符
- 按位运算符
- 逻辑运算符
- 报价运算符
- 其它运算符
让我们逐一了解所有运算符。
Perl算术运算符
假设变量a保持10,变量a保持10,变量 b保持20,然后是Perl算术运算符 -
| Sr.No. | 操作符和说明 |
|---|
Perl Equality Operators
这些也称为关系运算符。 假设变量a保持10,变量a保持10,变量 b保持20,那么让我们检查以下数字相等运算符 -
| Sr.No. | 操作符和说明 |
|---|
以下是股权经营者名单。 假设变量a持有“abc”而变量a持有“abc”而变量 b持有“xyz”然后,让我们检查以下字符串相等运算符 -
| Sr.No. | 操作符和说明 |
|---|
Perl分配运算符
假设变量a保持10,变量a保持10,变量 b保持20,然后下面是Perl中可用的赋值运算符及其用法 -
| Sr.No. | 操作符和说明 |
|---|
Perl按位运算符
按位运算符处理位并执行逐位运算。 假设a=60;和a=60;和 b = 13; 现在采用二进制格式,它们如下 -
$ a = 0011 1100
$ b = 0000 1101
-----------------
a&a& b = 0000 1100
a|a| b = 0011 1101
a ^a ^ b = 0011 0001
〜$ a = 1100 0011
Perl语言支持以下Bitwise运算符,假设a=60;而a=60;而 b = 13
| Sr.No. | 操作符和说明 |
|---|
Perl逻辑运算符
Perl语言支持以下逻辑运算符。 假设变量a成立,变量a成立,变量 b成立为假 -
| Sr.No. | 操作符和说明 |
|---|
Quote-like Operators
Perl语言支持以下类似Quote的运算符。 在下表中,{}表示您选择的任何分隔符对。
| Sr.No. | 操作符和说明 |
|---|
混合操作符 (Miscellaneous Operators)
Perl语言支持以下其他运算符。 假设变量a保持10,变量b保持20然后 -
| Sr.No. | 操作符和说明 |
|---|
Perl运算符优先级
下表列出了从最高优先级到最低优先级的所有运算符。
left terms and list operators (leftward)
left ->
nonassoc ++ --
right **
right ! ~\and unary + and -
left =~ !~
left */% x
left + - .
nonassoc named unary operators
nonassoc < > <= >= lt gt le ge
nonassoc == != <=> eq ne cmp ~~
left | ^
left || //
nonassoc .. ...
right ?:
right = += -= *= etc.
left , =>
nonassoc list operators (rightward)
right not
left and
left or xor
12345678910111213141516171819202122232425Perl - Date and Time
本章将为您提供有关如何在Perl中处理和操作日期和时间的基本知识。
当前日期和时间
让我们从 localtime() 函数开始,如果没有参数,则返回当前日期和时间的值。 以下是在列表上下文中使用时由 localtime 函数返回的9元素列表 -
sec, # seconds of minutes from 0 to 61
min, # minutes of hour from 0 to 59
hour, # hours of day from 0 to 24
mday, # day of month from 1 to 31
mon, # month of year from 0 to 11
year, # year since 1900
wday, # days since sunday
yday, # days since January 1st
isdst # hours of daylight savings time
12345678910尝试以下示例来打印localtime()函数返回的不同元素 -
#!/usr/local/bin/perl
@months = qw( Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec );
@days = qw(Sun Mon Tue Wed Thu Fri Sat Sun);
($sec,$min,$hour,$mday,$mon,$year,$wday,$yday,$isdst) = localtime();
print "$mday $months[$mon] $days[$wday]\n";
123456执行上述代码时,会产生以下结果 -
16 Feb Sat
12如果您将在标量上下文中使用localtime()函数,那么它将从系统中设置的当前时区返回日期和时间。 请尝试以下示例以完整格式打印当前日期和时间 -
#!/usr/local/bin/perl
$datestring = localtime();
print "Local date and time $datestring\n";
1234执行上述代码时,会产生以下结果 -
Local date and time Sat Feb 16 06:50:45 2013
12GMT时间
函数 gmtime() 工作方式与localtime()函数类似,但返回的值已针对标准格林威治时区进行了本地化。 在列表上下文中调用$ isdst时,gmtime返回的最后一个值始终为0.GWT中没有夏令时。
您应该记录localtime()将在运行脚本的机器上返回当前本地时间,gmtime()将返回通用格林威治标准时间或GMT(或UTC)。
尝试以下示例打印当前日期和时间,但按GMT比例 -
#!/usr/local/bin/perl
$datestring = gmtime();
print "GMT date and time $datestring\n";
1234执行上述代码时,会产生以下结果 -
GMT date and time Sat Feb 16 13:50:45 2013
12格式化日期和时间
您可以使用localtime()函数获取9个元素的列表,稍后您可以使用 printf() 函数根据您的要求格式化日期和时间,如下所示 -
#!/usr/local/bin/perl
($sec,$min,$hour,$mday,$mon,$year,$wday,$yday,$isdst) = localtime();
printf("Time Format - HH:MM:SS\n");
printf("%02d:%02d:%02d", $hour, $min, $sec);
12345执行上述代码时,会产生以下结果 -
Time Format - HH:MM:SS
06:58:52
123大纪元时间
您可以使用time()函数来获取纪元时间,即自给定日期以来经过的秒数,在Unix中是1970年1月1日。
#!/usr/local/bin/perl
$epoc = time();
print "Number of seconds since Jan 1, 1970 - $epoc\n";
1234执行上述代码时,会产生以下结果 -
Number of seconds since Jan 1, 1970 - 1361022130
12您可以将给定的秒数转换为日期和时间字符串,如下所示 -
#!/usr/local/bin/perl
$datestring = localtime();
print "Current date and time $datestring\n";
$epoc = time();
$epoc = $epoc - 24 * 60 * 60; # one day before of current date.
$datestring = localtime($epoc);
print "Yesterday's date and time $datestring\n";
12345678执行上述代码时,会产生以下结果 -
Current date and time Tue Jun 5 05:54:43 2018
Yesterday's date and time Mon Jun 4 05:54:43 2018
123POSIX Function strftime()
您可以使用POSIX函数 strftime() 在下表的帮助下格式化日期和时间。 请注意,标有星号(*)的说明符与语言环境有关。
| 符 | 取而代之 | 例 |
|---|
让我们检查以下示例以了解其用法 -
#!/usr/local/bin/perl
use POSIX qw(strftime);
$datestring = strftime "%a %b %e %H:%M:%S %Y", localtime;
printf("date and time - $datestring\n");
# or for GMT formatted appropriately for your locale:
$datestring = strftime "%a %b %e %H:%M:%S %Y", gmtime;
printf("date and time - $datestring\n");
12345678执行上述代码时,会产生以下结果 -
date and time - Sat Feb 16 07:10:23 2013
date and time - Sat Feb 16 14:10:23 2013
123Perl - Subroutines
Perl子例程或函数是一组一起执行任务的语句。 您可以将代码分成单独的子例程。 如何在不同的子程序之间划分代码取决于你,但从逻辑上讲,除法通常是每个函数执行特定的任务。
Perl可互换地使用术语子例程,方法和函数。
定义并调用子程序
Perl编程语言中子例程定义的一般形式如下 -
sub subroutine_name {
body of the subroutine
1234调用Perl子例程的典型方法如下 -
subroutine_name( list of arguments );
12在5.0之前的Perl版本中,调用子例程的语法略有不同,如下所示。 这仍然适用于最新版本的Perl,但不推荐使用它,因为它绕过了子程序原型。
&subroutine_name( list of arguments );
12让我们看看下面的例子,它定义了一个简单的函数,然后调用它。 因为Perl在执行程序之前编译程序,所以在哪里声明子程序并不重要。
#!/usr/bin/perl
# Function definition
sub Hello {
print "Hello, World!\n";
# Function call
Hello();
12345678执行上述程序时,会产生以下结果 -
Hello, World!
12将参数传递给子例程
您可以像使用任何其他编程语言一样将各种参数传递给子例程,并且可以使用特殊数组@_在函数内部访问它们。 因此函数的第一个参数是[0],第二个参数是[0],第二个参数是 _ [1],依此类推。
您可以将数组和散列作为参数传递,就像任何标量一样,但是传递多个数组或散列通常会导致它们失去单独的标识。 因此,我们将使用引用(在下一章中解释)来传递任何数组或哈希。
让我们尝试以下示例,该示例获取数字列表然后打印其平均值 -
#!/usr/bin/perl
# Function definition
sub Average {
# get total number of arguments passed.
$n = scalar(@_);
$sum = 0;
foreach $item (@_) {
$sum += $item;
$average = $sum/$n;
print "Average for the given numbers : $average\n";
# Function call
Average(10, 20, 30);
123456789101112131415执行上述程序时,会产生以下结果 -
Average for the given numbers : 20
12将列表传递给子例程
因为@ 变量是一个数组,所以它可以用来为子程序提供列表。 但是,由于Perl接受并解析列表和数组的方式,从@ 中提取单个元素可能很困难。 如果你必须传递一个列表和其他标量参数,那么将list作为最后一个参数,如下所示 -
#!/usr/bin/perl
# Function definition
sub PrintList {
my @list = @_;
print "Given list is @list\n";
$a = 10;
@b = (1, 2, 3, 4);
# Function call with list parameter
PrintList($a, @b);
1234567891011执行上述程序时,会产生以下结果 -
Given list is 10 1 2 3 4
12将哈希传递给子例程
当您向接受列表的子例程或运算符提供哈希时,哈希会自动转换为键/值对列表。 例如 -
#!/usr/bin/perl
# Function definition
sub PrintHash {
my (%hash) = @_;
foreach my $key ( keys %hash ) {
my $value = $hash{$key};
print "$key : $value\n";
%hash = ('name' => 'Tom', 'age' => 19);
# Function call with hash parameter
PrintHash(%hash);
12345678910111213执行上述程序时,会产生以下结果 -
name : Tom
age : 19
123从子程序返回值
您可以像使用任何其他编程语言一样从子例程返回值。 如果未从子例程返回值,则在子例程中最后执行的任何计算自动也是返回值。
您可以像任何标量一样从子例程返回数组和哈希值,但返回多个数组或哈希值通常会导致它们失去单独的标识。 因此,我们将使用引用(在下一章中解释)从函数返回任何数组或散列。
让我们尝试以下示例,该示例获取数字列表然后返回其平均值 -
#!/usr/bin/perl
# Function definition
sub Average {
# get total number of arguments passed.
$n = scalar(@_);
$sum = 0;
foreach $item (@_) {
$sum += $item;
$average = $sum/$n;
return $average;
# Function call
$num = Average(10, 20, 30);
print "Average for the given numbers : $num\n";
12345678910111213141516执行上述程序时,会产生以下结果 -
Average for the given numbers : 20
12子程序中的私有变量
默认情况下,Perl中的所有变量都是全局变量,这意味着可以从程序中的任何位置访问它们。 但您可以随时使用 my 运算符创建称为 lexical variables private 变量。
my 运算符将变量限制在可以使用和访问它的特定代码区域。 在该区域之外,不能使用或访问此变量。 该区域称为其范围。 词法范围通常是一个带有一组括号的代码块,例如定义子例程主体的那些或标记 if, while, for, foreach, 和 eval 语句的代码块的代码块。
以下是一个示例,说明如何使用 my 运算符定义单个或多个私有变量 -
sub somefunc {
my $variable; # $variable is invisible outside somefunc()
my ($another, @an_array, %a_hash); # declaring many variables at once
12345让我们检查以下示例以区分全局变量和私有变量 -
#!/usr/bin/perl
# Global variable
$string = "Hello, World!";
# Function definition
sub PrintHello {
# Private variable for PrintHello function
my $string;
$string = "Hello, Perl!";
print "Inside the function $string\n";
# Function call
PrintHello();
print "Outside the function $string\n";
1234567891011121314执行上述程序时,会产生以下结果 -
Inside the function Hello, Perl!
Outside the function Hello, World!
123Temporary Values via local()
当变量的当前值必须对被调用的子例程可见时,主要使用 local 。 本地只为全局(含义包)变量提供临时值。 这称为 dynamic scoping 。 词法范围是用我的,它更像C的自动声明。
如果为local提供了多个变量或表达式,则必须将它们放在括号中。 此运算符的作用是将这些变量的当前值保存在隐藏堆栈的参数列表中,并在退出块,子例程或eval时恢复它们。
让我们检查以下示例以区分全局变量和局部变量 -
#!/usr/bin/perl
# Global variable
$string = "Hello, World!";
sub PrintHello {
# Private variable for PrintHello function
local $string;
$string = "Hello, Perl!";
PrintMe();
print "Inside the function PrintHello $string\n";
sub PrintMe {
print "Inside the function PrintMe $string\n";
# Function call
PrintHello();
print "Outside the function $string\n";
1234567891011121314151617执行上述程序时,会产生以下结果 -
Inside the function PrintMe Hello, Perl!
Inside the function PrintHello Hello, Perl!
Outside the function Hello, World!
1234State Variables via state()
还有另一种类型的词法变量,它们类似于私有变量,但它们保持状态,并且在多次调用子例程时不会重新初始化。 这些变量使用 state 运算符定义,可从Perl 5.9.4开始提供。
让我们检查以下示例来演示 state 变量的使用 -
#!/usr/bin/perl
use feature 'state';
sub PrintCount {
state $count = 0; # initial value
print "Value of counter is $count\n";
$count++;
for (1..5) {
PrintCount();
1234567891011执行上述程序时,会产生以下结果 -
Value of counter is 0
Value of counter is 1
Value of counter is 2
Value of counter is 3
Value of counter is 4
123456在Perl 5.10之前,你必须像这样写 -
#!/usr/bin/perl
my $count = 0; # initial value
sub PrintCount {
print "Value of counter is $count\n";
$count++;
for (1..5) {
PrintCount();
123456789101112子程序调用上下文
子例程或语句的上下文被定义为期望的返回值的类型。 这允许您使用单个函数,该函数根据用户期望接收的内容返回不同的值。 例如,以下localtime()在标量上下文中调用时返回一个字符串,但在列表上下文中调用它时返回一个列表。
my $datestring = localtime( time );
12在此示例中,$ timestr的值现在是由当前日期和时间组成的字符串,例如,Thu Nov 30 15:21:33 2000.相反 -
($sec,$min,$hour,$mday,$mon, $year,$wday,$yday,$isdst) = localtime(time);
12现在,各个变量包含localtime()子例程返回的相应值。
Perl - References
Perl引用是一种标量数据类型,它保存另一个值的位置,该值可以是标量,数组或散列。 由于它的标量性质,可以在任何地方使用引用,可以使用标量。
您可以构造包含对其他列表的引用的列表,其中可以包含对哈希的引用,依此类推。 这就是嵌套数据结构在Perl中的构建方式。
创建参考
通过在前面加上反斜杠,可以很容易地为任何变量,子例程或值创建引用,如下所示 -
$scalarref = \$foo;
$arrayref = \@ARGV;
$hashref = \%ENV;
$coderef = \&handler;
$globref = \*foo;
123456您不能使用反斜杠运算符在I/O句柄(文件句柄或dirhandle)上创建引用,但可以使用方括号创建对匿名数组的引用,如下所示 -
$arrayref = [1, 2, ['a', 'b', 'c']];
12类似地,您可以使用大括号创建对匿名哈希的引用,如下所示 -
$hashref = {
'Adam' => 'Eve',
'Clyde' => 'Bonnie',
12345可以使用不带子名称的sub创建对匿名子例程的引用,如下所示 -
$coderef = sub { print "Boink!\n" };
12Dereferencing
取消引用将参考点的值返回到该位置。 要取消引用引用,只需使用$,@或%作为引用变量的前缀,具体取决于引用是指向标量,数组还是哈希。 以下是解释这个概念的例子 -
#!/usr/bin/perl
$var = 10;
# Now $r has reference to $var scalar.
$r = \$var;
# Print value available at the location stored in $r.
print "Value of $var is : ", $$r, "\n";
@var = (1, 2, 3);
# Now $r has reference to @var array.
$r = \@var;
# Print values available at the location stored in $r.
print "Value of @var is : ", @$r, "\n";
%var = ('key1' => 10, 'key2' => 20);
# Now $r has reference to %var hash.
$r = \%var;
# Print values available at the location stored in $r.
print "Value of %var is : ", %$r, "\n";
1234567891011121314151617执行上述程序时,会产生以下结果 -
Value of 10 is : 10
Value of 1 2 3 is : 123
Value of %var is : key220key110
1234如果您不确定变量类型,那么使用 ref 很容易知道它的类型,如果它的参数是 ref ,它将返回以下字符串之一。 否则,它返回false -
SCALAR
ARRAY
1234567让我们试试下面的例子 -
#!/usr/bin/perl
$var = 10;
$r = \$var;
print "Reference type in r : ", ref($r), "\n";
@var = (1, 2, 3);
$r = \@var;
print "Reference type in r : ", ref($r), "\n";
%var = ('key1' => 10, 'key2' => 20);
$r = \%var;
print "Reference type in r : ", ref($r), "\n";
1234567891011执行上述程序时,会产生以下结果 -
Reference type in r : SCALAR
Reference type in r : ARRAY
Reference type in r : HASH
1234循环参考
当两个引用包含对彼此的引用时,将发生循环引用。 创建引用时必须小心,否则循环引用可能会导致内存泄漏。 以下是一个例子 -
#!/usr/bin/perl
my $foo = 100;
$foo = \$foo;
print "Value of foo is : ", $$foo, "\n";
12345执行上述程序时,会产生以下结果 -
Value of foo is : REF(0x9aae38)
12引用函数 (References to Functions)
如果您需要创建一个信号处理程序,以便通过在该函数名前加上\&而引用一个函数,并且引用该引用,您只需要使用&符号&前缀引用变量,就可能发生这种情况。 以下是一个例子 -
#!/usr/bin/perl
# Function definition
sub PrintHash {
my (%hash) = @_;
foreach $item (%hash) {
print "Item : $item\n";
%hash = ('name' => 'Tom', 'age' => 19);
# Create a reference to above function.
$cref = \&PrintHash;
# Function call using reference.
&$cref(%hash);
1234567891011121314执行上述程序时,会产生以下结果 -
Item : name
Item : Tom
Item : age
Item : 19
12345Perl - Formats
Perl使用称为“格式”的书写模板来输出报告。 要使用Perl的格式功能,您必须首先定义格式,然后您可以使用该格式来编写格式化数据。
定义格式
以下是定义Perl格式的语法 -
format FormatName =
fieldline
value_one, value_two, value_three
fieldline
value_one, value_two
1234567这里 FormatName 表示格式的名称。 fieldline 是具体的方式,数据应该格式化。 值行表示将输入到字段行中的值。 您可以使用单个句点结束格式。
下一个 fieldline 可以包含任何文本或字段持有者。 现场持有人为将在以后放置的数据保留空间。 一名持场人的格式为 -
@<<<<
12此字段持有者是左对齐的,字段空间为5.您必须计算@符号和 其他现场持有人包括 -
@>>>> right-justified
@|||| centered
@####.## numeric field holder
@* multiline field holder
12345一个示例格式是 -
format EMPLOYEE =
===================================
$name $age
@#####.##
$salary
===================================
123456789在此示例中,$ name将在22个字符空间内写为左对齐,并且在该年龄之后将写入两个空格。
使用格式
为了调用这种格式声明,我们将使用 write 关键字 -
write EMPLOYEE;
12问题是格式名称通常是打开文件句柄的名称,而write语句将输出发送到此文件句柄。 由于我们希望将数据发送到STDOUT,因此我们必须将EMPLOYEE与STDOUT文件句柄相关联。 首先,我们必须使用select()函数确保STDOUT是我们选择的文件句柄。
select(STDOUT);
12然后我们将EMPLOYEE与STDOUT联系起来,方法是使用特殊变量〜或〜或 FORMAT_NAME将新格式名称设置为STDOUT,如下所示 -
$~ = "EMPLOYEE";
12当我们现在执行write()时,数据将被发送到STDOUT。 请记住:如果要在任何其他文件句柄而不是STDOUT中编写报表,则可以使用select()函数选择该文件句柄,其余逻辑将保持不变。
我们来看下面的例子。 这里我们有硬编码值,仅用于显示用法。 在实际使用中,您将从文件或数据库中读取值以生成实际报告,您可能需要将最终报告再次写入文件。
#!/usr/bin/perl
format EMPLOYEE =
===================================
$name $age
@#####.##
$salary
===================================
select(STDOUT);
$~ = EMPLOYEE;
@n = ("Ali", "Raza", "Jaffer");
@a = (20,30, 40);
@s = (2000.00, 2500.00, 4000.000);
$i = 0;
foreach (@n) {
$name = $_;
$age = $a[$i];
$salary = $s[$i++];
write;
12345678910111213141516171819202122执行时,这将产生以下结果 -
===================================
Ali 20
2000.00
===================================
===================================
Raza 30
2500.00
===================================
===================================
Jaffer 40
4000.00
===================================
12345678910111213定义报告标题
一切都很好看。 但是您有兴趣在报告中添加标题。 此标题将打印在每页的顶部。 这样做非常简单。 除了定义模板之外,您还必须定义标头并将其分配给或或 FORMAT_TOP_NAME变量 -
#!/usr/bin/perl
format EMPLOYEE =
===================================
$name $age
@#####.##
$salary
===================================
format EMPLOYEE_TOP =
===================================
Name Age
===================================
select(STDOUT);
$~ = EMPLOYEE;
$^ = EMPLOYEE_TOP;
@n = ("Ali", "Raza", "Jaffer");
@a = (20,30, 40);
@s = (2000.00, 2500.00, 4000.000);
$i = 0;
foreach (@n) {
$name = $_;
$age = $a[$i];
$salary = $s[$i++];
write;
12345678910111213141516171819202122232425262728现在你的报告看起来像 -
===================================
Name Age
===================================
===================================
Ali 20
2000.00
===================================
===================================
Raza 30
2500.00
===================================
===================================
Jaffer 40
4000.00
===================================
12345678910111213141516定义分页
如果您的报告占用多个页面怎么办? 你有一个解决方案,只需使用 $% 或$ FORMAT_PAGE_NUMBER vairable以及标题如下 -
format EMPLOYEE_TOP =
===================================
Name Age Page @<
===================================
1234567现在您的输出将如下所示 -
===================================
Name Age Page 1
===================================
===================================
Ali 20
2000.00
===================================
===================================
Raza 30
2500.00
===================================
===================================
Jaffer 40
4000.00
===================================
12345678910111213141516页面上的行数
您可以使用特殊变量 $= (或FORMATLINESPERPAGE)设置每页的行数,默认情况下,FORMATLINESPERPAGE)设置每页的行数,默认情况下, =将为60。
定义报告页脚
虽然或或 FORMAT_TOP_NAME包含当前标题格式的名称,但没有相应的机制可以自动为页脚执行相同的操作。 如果你有一个固定大小的页脚,你可以通过在每次write()之前检查变量−或−或 FORMAT_LINES_LEFT来获取页脚,并在必要时使用另一种格式打印页脚,如下所示 -
format EMPLOYEE_BOTTOM =
End of Page @<
12345有关与格式化相关的一整套变量,请参阅 Perl特殊变量 部分。
Perl - File I/O
处理文件的基础很简单:将 filehandle 与外部实体(通常是文件)相关联,然后使用Perl中的各种运算符和函数来读取和更新与文件句柄关联的数据流中存储的数据。
文件句柄是一个命名的内部Perl结构,它将物理文件与名称相关联。 所有文件句柄都具有读/写访问权限,因此您可以读取和更新与文件句柄关联的任何文件或设备。 但是,关联文件句柄时,可以指定打开文件句柄的模式。
三个基本文件句柄是 - STDIN , STDOUT 和 STDERR, 分别代表标准输入,标准输出和标准错误设备。
打开和关闭文件 (Opening and Closing Files)
以下两个函数具有多个表单,可用于在Perl中打开任何新文件或现有文件。
open FILEHANDLE, EXPR
open FILEHANDLE
sysopen FILEHANDLE, FILENAME, MODE, PERMS
sysopen FILEHANDLE, FILENAME, MODE
12345这里FILEHANDLE是 open 函数返回的文件句柄,EXPR是具有文件名和打开文件模式的表达式。
打开功能
以下是以只读模式打开 file.txt 的语法。 这里小于“符号表示文件必须以只读模式打开。
open(DATA, "<file.txt");
12这里DATA是文件句柄,用于读取文件。 这是一个示例,它将打开一个文件并在屏幕上打印其内容。
#!/usr/bin/perl
open(DATA, "<file.txt") or die "Couldn't open file file.txt, $!";
while(<DATA>) {
print "$_";
123456以下是在写入模式下打开file.txt的语法。 这里小于>符号表示文件必须在写入模式下打开。
open(DATA, ">file.txt") or die "Couldn't open file file.txt, $!";
12此示例实际上在打开文件之前截断(清空)文件,这可能不是所需的效果。 如果要打开文件进行读写,可以在>或
例如,要打开文件进行更新而不截断它 -
open(DATA, "+<file.txt"); or die "Couldn't open file file.txt, $!";
12要先截断文件 -
open DATA, "+>file.txt" or die "Couldn't open file file.txt, $!";
12您可以在追加模式下打开文件。 在此模式下,写入点将设置为文件的结尾。
open(DATA,">>file.txt") || die "Couldn't open file file.txt, $!";
12双>>打开文件以进行追加,将文件指针放在末尾,以便您可以立即开始附加信息。 但是,除非你在它前面加上一个加号,否则你无法读取它 -
open(DATA,"+>>file.txt") || die "Couldn't open file file.txt, $!";
12以下是表格,其中给出了不同模式的可能值
| Sr.No. | 实体和定义 |
|---|
Sysopen功能
sysopen 函数类似于main open函数,除了它使用系统 open() 函数,使用提供给它的参数作为系统函数的参数 -
例如,要打开文件进行更新,请从打开模拟 +《filename 格式 -
sysopen(DATA, "file.txt", O_RDWR);
12或者在更新之前截断文件 -
sysopen(DATA, "file.txt", O_RDWR|O_TRUNC );
12您可以使用O_CREAT创建新文件,使用O_WRONLY-以只写模式打开文件,使用O_RDONLY - 以只读模式打开文件。
PERMS 参数指定指定文件的文件权限(如果必须创建)。 默认情况下,它需要 0x666 。
以下是表格,其中给出了MODE的可能值。
| Sr.No. | 实体和定义 |
|---|
关闭功能
要关闭文件句柄,从而取消文件句柄与相应文件的关联,可以使用 close 函数。 这会刷新文件句柄的缓冲区并关闭系统的文件描述符。
close FILEHANDLE
close
123如果未指定FILEHANDLE,则它将关闭当前选定的文件句柄。 仅当它可以成功刷新缓冲区并关闭文件时,它才返回true。
close(DATA) || die "Couldn't close file properly";
12读写文件 (Reading and Writing Files)
一旦打开文件句柄,您就需要能够读取和写入信息。 有许多不同的方法可以将数据读入和写入文件。
运算符
从打开的文件句柄读取信息的主要方法是运算符。 在标量上下文中,它从文件句柄返回一行。 例如 -
#!/usr/bin/perl
print "What is your name?\n";
$name = <STDIN>;
print "Hello $name\n";
12345在列表上下文中使用运算符时,它将返回指定文件句柄中的行列表。 例如,要将文件中的所有行导入数组 -
#!/usr/bin/perl
open(DATA,"<import.txt") or die "Can't open data";
@lines = <DATA>;
close(DATA);
12345getc功能
getc函数返回指定FILEHANDLE中的单个字符,如果没有指定则返回STDIN -
getc FILEHANDLE
123如果出现错误,或文件句柄位于文件末尾,则返回undef。
读功能
read函数从缓冲的文件句柄中读取一个信息块:该函数用于从文件中读取二进制数据。
read FILEHANDLE, SCALAR, LENGTH, OFFSET
read FILEHANDLE, SCALAR, LENGTH
123读取数据的长度由LENGTH定义,如果未指定OFFSET,则数据放在SCALAR的开头。 否则,数据将放在SCALAR中的OFFSET字节之后。 该函数返回成功时读取的字节数,文件末尾为零,如果有错误则返回undef。
打印功能
对于用于从文件句柄读取信息的所有不同方法,用于写回信息的主要功能是打印功能。
print FILEHANDLE LIST
print LIST
print
1234print函数将LIST的评估值打印到FILEHANDLE,或打印到当前输出文件句柄(默认情况下为STDOUT)。 例如 -
print "Hello World!\n";
12复制文件
下面是一个示例,它打开现有文件file1.txt并逐行读取并生成另一个复制文件file2.txt。
#!/usr/bin/perl
# Open file to read
open(DATA1, "<file1.txt");
# Open new file to write
open(DATA2, ">file2.txt");
# Copy data from one file to another.
while(<DATA1>) {
print DATA2 $_;
close( DATA1 );
close( DATA2 );
123456789101112重命名文件
这是一个示例,它显示了我们如何将文件file1.txt重命名为file2.txt。 假设文件在/ usr/test目录中可用。
#!/usr/bin/perl
rename ("/usr/test/file1.txt", "/usr/test/file2.txt" );
123此函数 renames 需要两个参数,它只是重命名现有文件。
删除现有文件
下面是一个示例,演示如何使用 unlink 函数删除文件file1.txt。
#!/usr/bin/perl
unlink ("/usr/test/file1.txt");
123在文件中定位
您可以使用 tell 函数来了解文件的当前位置,并使用函数来指向文件中的特定位置。
告诉功能
第一个要求是在文件中找到你的位置,你使用tell函数来做 -
tell FILEHANDLE
123如果指定,则返回文件指针的位置(以字节为单位)在FILEHANDLE中,如果未指定,则返回当前默认选择的文件句柄。
寻求功能
seek函数将文件指针定位到文件中指定的字节数 -
seek FILEHANDLE, POSITION, WHENCE
12该函数使用fseek系统函数,您可以相对于三个不同的点进行定位:开始,结束和当前位置。 您可以通过为WHENCE指定值来完成此操作。
零设置相对于文件开头的定位。 例如,该行将文件指针设置为文件中的第256个字节。
seek DATA, 256, 0;
12文件信息
您可以使用一系列统称为-X测试的测试运算符在Perl中快速测试某些功能。 例如,要快速测试文件的各种权限,可以使用这样的脚本 -
#/usr/bin/perl
my $file = "/usr/test/file1.txt";
my (@description, $size);
if (-e $file) {
push @description, 'binary' if (-B _);
push @description, 'a socket' if (-S _);
push @description, 'a text file' if (-T _);
push @description, 'a block special file' if (-b _);
push @description, 'a character special file' if (-c _);
push @description, 'a directory' if (-d _);
push @description, 'executable' if (-x _);
push @description, (($size = -s _)) ? "$size bytes" : 'empty';
print "$file is ", join(', ',@description),"\n";
123456789101112131415以下是功能列表,您可以检查文件或目录 -
| Sr.No. | 运算符和定义 |
|---|
Perl - Directories
以下是用于播放目录的标准函数。
opendir DIRHANDLE, EXPR # To open a directory
readdir DIRHANDLE # To read a directory
rewinddir DIRHANDLE # Positioning pointer to the begining
telldir DIRHANDLE # Returns current position of the dir
seekdir DIRHANDLE, POS # Pointing pointer to POS inside dir
closedir DIRHANDLE # Closing a directory.
1234567显示所有文件
列出特定目录中可用的所有文件的方法有很多种。 首先让我们使用简单的方法来获取并使用 glob 运算符列出所有文件 -
#!/usr/bin/perl
# Display all the files in /tmp directory.
$dir = "/tmp/*";
my @files = glob( $dir );
foreach (@files ) {
print $_ . "\n";
# Display all the C source files in /tmp directory.
$dir = "/tmp/*.c";
@files = glob( $dir );
foreach (@files ) {
print $_ . "\n";
# Display all the hidden files.
$dir = "/tmp/.*";
@files = glob( $dir );
foreach (@files ) {
print $_ . "\n";
# Display all the files from /tmp and /home directories.
$dir = "/tmp/* /home/*";
@files = glob( $dir );
foreach (@files ) {
print $_ . "\n";
1234567891011121314151617181920212223242526这是另一个示例,它打开一个目录并列出该目录中可用的所有文件。
#!/usr/bin/perl
opendir (DIR, '.') or die "Couldn't open directory, $!";
while ($file = readdir DIR) {
print "$file\n";
closedir DIR;
1234567打印可能使用的C源文件列表的另一个示例是 -
#!/usr/bin/perl
opendir(DIR, '.') or die "Couldn't open directory, $!";
foreach (sort grep(/^.*\.c$/,readdir(DIR))) {
print "$_\n";
closedir DIR;
1234567创建新目录
您可以使用 mkdir 函数创建新目录。 您需要具有创建目录所需的权限。
#!/usr/bin/perl
$dir = "/tmp/perl";
# This creates perl directory in /tmp directory.
mkdir( $dir ) or die "Couldn't create $dir directory, $!";
print "Directory created successfully\n";
123456删除目录
您可以使用 rmdir 函数删除目录。 您需要具有删除目录所需的权限。 此外,在尝试删除目录之前,此目录应为空。
#!/usr/bin/perl
$dir = "/tmp/perl";
# This removes perl directory from /tmp directory.
rmdir( $dir ) or die "Couldn't remove $dir directory, $!";
print "Directory removed successfully\n";
123456更改目录
您可以使用 chdir 函数更改目录并转到新位置。 您需要具有更改目录所需的权限并进入新目录。
#!/usr/bin/perl
$dir = "/home";
# This changes perl directory and moves you inside /home directory.
chdir( $dir ) or die "Couldn't go inside $dir directory, $!";
print "Your new location is $dir\n";
123456Perl - Error Handling
执行和错误总是在一起。 如果要打开不存在的文件。 然后,如果你没有正确处理这种情况,那么你的程序被认为质量很差。
如果发生错误,程序将停止。 因此,使用适当的错误处理来处理各种类型的错误,这些错误可能在程序执行期间发生并采取适当的操作而不是完全停止程序。
您可以通过多种不同方式识别和捕获错误。 很容易在Perl中捕获错误然后正确处理它们。 这里有几种可以使用的方法。
if 语句
当您需要检查语句的返回值时, if statement 是显而易见的选择; 例如 -
if(open(DATA, $file)) {
} else {
die "Error: Couldn't open the file - $!";
123456这里变量$! 返回实际的错误消息。 或者,我们可以在有意义的情况下将陈述减少到一行; 例如 -
open(DATA, $file) || die "Error: Couldn't open the file $!";
12除非功能
unless 函数与if:逻辑相反,语句可以完全绕过成功状态,只有在表达式返回false时才执行。 例如 -
unless(chdir("/etc")) {
die "Error: Can't change directory - $!";
1234当您只想在表达式失败时引发错误或替代时,最好使用 unless 语句。 在单行语句中使用时,该语句也很有意义 -
die "Error: Can't change directory!: $!" unless(chdir("/etc"));
12在这里,我们只有在chdir操作失败时才会死掉,并且读得很好。
三元运算符
对于非常短的测试,您可以使用条件运算符 ?:
print(exists($hash{value}) ? 'There' : 'Missing',"\n");
12这里不太清楚我们想要实现什么,但效果与使用 if 或 unless 语句相同。 当您想要快速返回表达式或语句中的两个值之一时,最好使用条件运算符。
警告功能
warn函数只会发出警告,会向STDERR打印一条消息,但不会采取进一步操作。 因此,如果您只想为用户打印警告并继续执行其余操作,则更有用 -
chdir('/etc') or warn "Can't change directory";
12模具功能
die函数就像warn一样工作,除了它还调用exit。 在普通脚本中,此函数具有立即终止执行的效果。 如果程序中存在错误,则应该使用此函数以防止继续操作 -
chdir('/etc') or die "Can't change directory";
12模块中的错误
我们应该能够处理两种不同的情况 -
- 报告引用模块文件名和行号的模块中的错误 - 这在调试模块时很有用,或者当您特别想要引发与模块相关但不与脚本相关的错误时。
- 在模块中报告引用调用方信息的错误,以便您可以在脚本中调试导致错误的行。 以这种方式引发的错误对最终用户很有用,因为它们突出显示与调用脚本的原始行相关的错误。
warn 和 die 函数的工作方式与 die 调用时的工作方式略有不同。 例如,简单的模块 -
package T;
require Exporter;
@ISA = qw/Exporter/;
@EXPORT = qw/function/;
use Carp;
sub function {
warn "Error in module!";
12345678910从下面的脚本调用时 -
use T;
function();
123它会产生以下结果 -
Error in module! at T.pm line 9.
12这或多或少是您所期望的,但不一定是您想要的。 从模块程序员的角度来看,信息很有用,因为它有助于指出模块本身的错误。 对于最终用户来说,所提供的信息是相当无用的,对于除了强化程序员之外的所有人来说,它完全没有意义。
这些问题的解决方案是Carp模块,它提供了一种简单的方法,用于报告模块中的错误,这些模块返回有关调用脚本的信息。 鲤鱼模块提供四种功能:鲤鱼,咯咯,croak和confess。 这些功能将在下面讨论。
鲤鱼功能
carp函数是warn的基本等价物,它将消息打印到STDERR而不实际退出脚本并打印脚本名称。
package T;
require Exporter;
@ISA = qw/Exporter/;
@EXPORT = qw/function/;
use Carp;
sub function {
carp "Error in module!";
12345678910从下面的脚本调用时 -
use T;
function();
123它会产生以下结果 -
Error in module! at test.pl line 4
12咯咯的功能
cluck函数是一种增压的鲤鱼,它遵循相同的基本原则,但也打印导致被调用函数的所有模块的堆栈跟踪,包括原始脚本的信息。
package T;
require Exporter;
@ISA = qw/Exporter/;
@EXPORT = qw/function/;
use Carp qw(cluck);
sub function {
cluck "Error in module!";
12345678910从下面的脚本调用时 -
use T;
function();
123它会产生以下结果 -
Error in module! at T.pm line 9
T::function() called at test.pl line 4
123croak作用
croak 函数等同于 die ,除了它将调用者报告一级。 与die一样,此函数在向STDERR报告错误后也会退出脚本 -
package T;
require Exporter;
@ISA = qw/Exporter/;
@EXPORT = qw/function/;
use Carp;
sub function {
croak "Error in module!";
12345678910从下面的脚本调用时 -
use T;
function();
123它会产生以下结果 -
Error in module! at test.pl line 4
12与carp一样,对于根据warn和die函数包含行和文件信息,也适用相同的基本规则。
confess功能
confess 功能就像 cluck ; 它调用die然后打印堆栈跟踪一直到原始脚本。
package T;
require Exporter;
@ISA = qw/Exporter/;
@EXPORT = qw/function/;
use Carp;
sub function {
confess "Error in module!";
12345678910从下面的脚本调用时 -
use T;
function();
123它会产生以下结果 -
Error in module! at T.pm line 9
T::function() called at test.pl line 4
123Perl - Special Variables
在Perl中有一些具有预定义和特殊含义的变量。 它们是在通常的变量指示符(,@或%)之后使用标点符号的变量,例如,@或%)之后使用标点符号的变量,例如 _(如下所述)。
大多数特殊变量都有类似英文的长名称,例如,操作系统错误变量!可以写成!可以写成 OS_ERROR。 但是如果你打算使用英文名字,那么你必须把一行 use English; 在程序文件的顶部。 这指导解释器拾取变量的确切含义。
最常用的特殊变量是$ _,它包含默认输入和模式搜索字符串。 例如,在以下行中 -
#!/usr/bin/perl
foreach ('hickory','dickory','doc') {
print $_;
print "\n";
123456执行时,这将产生以下结果 -
hickory
dickory
1234再次,让我们在不使用$ _变量的情况下检查相同的示例 -
#!/usr/bin/perl
foreach ('hickory','dickory','doc') {
print;
print "\n";
123456执行时,这也会产生以下结果 -
hickory
dickory
1234第一次执行循环时,会打印“hickory”。 第二次打印“dickory”,第三次打印“doc”。 这是因为在循环的每次迭代中,当前字符串都放在中,默认情况下由print使用。以下是Perl假设中,默认情况下由print使用。以下是Perl假设 _的地方,即使你没有指定它 -
- 各种一元函数,包括ord和int等函数,以及除-t之外的所有文件测试(-f,-d),默认为STDIN。
- 各种列表功能,如打印和取消链接。
- 模式匹配操作m //,s ///和tr ///在没有=〜运算符的情况下使用。
- 如果没有提供其他变量,则foreach循环中的默认迭代器变量。
- grep和map函数中的隐式迭代器变量。
- 当行输入操作的结果被自身测试为while测试的唯一标准时(即),输入记录的默认位置。 请注意,在一段时间的测试之外,这不会发生。
特殊变量类型
根据特殊变量的用法和性质,我们可以按以下类别对它们进行分类 -
- 全局标量特殊变量。
- 全局数组特殊变量。
- 全局哈希特殊变量。
- 全球特殊文件句柄。
- Global Special Constants.
- 正则表达式特殊变量。
- Filehandle特殊变量。
全局标量特殊变量
这是所有标量特殊变量的列表。 我们列出了相应的英文名称以及符号名称。
| $_ | 默认输入和模式搜索空间。 |
|---|
全局数组特殊变量
| @ARGV | 包含用于脚本的命令行参数的数组。 |
|---|
全局哈希特殊变量
| %INC | 包含通过do或require包含的每个文件的文件名的条目的哈希。 |
|---|
全球特殊文件句柄
| ARGV | 在@ARGV中迭代命令行文件名的特殊文件句柄。 通常在<>中写为空文件句柄。 |
|---|
全球特殊常数
| END | 表示程序的逻辑结束。 忽略任何后续文本,但可以通过DATA文件句柄读取。 |
|---|
正则表达式特殊变量
| $digit | 包含匹配的最后一个模式中相应的括号集匹配的文本。 例如,$ 1匹配前一个正则表达式中第一组括号中包含的内容。 |
|---|
Filehandle特殊变量
| $| | 如果设置为非零,则在每次写入或打印当前所选输出通道后强制执行fflush(3)。 |
|---|
Perl - Coding Standard
当然,每个程序员在格式化方面都有自己的偏好,但是有一些通用的指导方针可以使您的程序更易于阅读,理解和维护。
最重要的是始终在-w标志下运行程序。 如果必须,可以通过no warnings pragma或$ ^ W变量明确地为代码的特定部分关闭它。 您还应该始终使用use strict或知道原因。 使用sigtrap甚至使用诊断编译指示也可能有用。
关于代码的美学布局,关于Larry唯一关心的唯一事情是多行BLOCK的结束大括号应该与启动构造的关键字对齐。 除此之外,他还有其他不那么强烈的偏好 -
- 4-column indent.
- 如果可能,在与关键字相同的行上打开卷曲,否则排队。
- 在多行BLOCK开放卷曲之前的空间。
- 单行BLOCK可以放在一行,包括curlies。
- 分号前没有空格。
- “短”单行BLOCK中省略了分号。
- 大多数运算符的空间。
- “复杂”下标周围的空间(括号内)。
- 做不同事情的块之间的空白行。
- Uncuddled elses.
- 函数名称与其左括号之间没有空格。
- 每个逗号后的空格。
- 运算符后除去长行(和和之外)。
- 在当前行上的最后一个括号匹配后的空格。
- 垂直排列相应的项目。
- 只要清晰度不受影响,省略多余的标点符号。
以下是一些其他更具实质性的风格问题:只是因为你能做某事特定的方式并不意味着你应该这样做。 Perl旨在为您提供多种方法,因此请考虑选择最具可读性的方法。 例如 -
open(FOO,$foo) || die "Can't open $foo: $!";
12比 - 更好
die "Can't open $foo: $!" unless open(FOO,$foo);
12因为第二种方法在修饰符中隐藏了语句的主要部分。 另一方面,
print "Starting analysis\n" if $verbose;
12比 - 更好
$verbose && print "Starting analysis\n";
12因为要点不是用户是否键入-v。
当Perl提供最后一个操作符以便您可以在中间退出时,不要通过愚蠢的扭曲来退出顶部或底部的循环。 只是“突出”它有点让它更明显 -
LINE:
for (;;) {
statements;
last LINE if $foo;
next LINE if /^#/;
statements;
12345678让我们看一些更重要的观点 -
- 不要害怕使用循环标签 - 它们是为了增强可读性以及允许多级循环中断。 请参阅上一个示例。
- 避免在void上下文中使用grep()(或map())或backticksbackticks,也就是说,当你丢弃它们的返回值时。 这些函数都有返回值,因此请使用它们。 否则使用foreach()循环或system()函数。
- 为了便于移植,当使用可能未在每台机器上实现的功能时,请在eval中测试构造以查看它是否失败。 如果您知道实现了特定功能的版本或补丁级别,则可以测试](英语为](英语为 PERL_VERSION)以查看它是否存在。 当安装Perl时,Config模块还允许您查询由Configure程序确定的值。
- 选择助记符标识符。 如果你不记得什么是助记符,你就会遇到问题。
- 虽然像gotit这样的短标识符可能没问题,但使用下划线来分隔较长标识符中的单词。通常比gotit这样的短标识符可能没问题,但使用下划线来分隔较长标识符中的单词。通常比 VarNamesLikeThis更容易阅读$ var_names_like_this,特别是对于非母语的英语人士。 它也是一个与VAR_NAMES_LIKE_THIS一致的简单规则。
- 包名称有时是此规则的例外。 Perl非正式地保留了“pragma”模块的小写模块名称,如integer和strict。 其他模块应以大写字母开头并使用大小写,但可能没有下划线,原因是原始文件系统将模块名称表示为必须适合几个稀疏字节的文件。
- 如果你有一个非常多毛的正则表达式,使用/ x修饰符并放入一些空格,使它看起来不像线条噪音。 当regexp有斜杠或反斜杠时,不要使用斜杠作为分隔符。
- 始终检查系统调用的返回码。 好的错误消息应该转到STDERR,包括导致问题的程序,失败的系统调用和参数是什么,以及(非常重要)应包含出错的标准系统错误消息。 这是一个简单但足够的例子 -
opendir(D, $dir) or die "can't opendir $dir: $!";
12- 考虑可重用性。 为什么当你想要再做一次这样的事情时,为什么会浪费智力? 考虑概括您的代码。 考虑编写模块或对象类。 考虑使用use strict使代码运行干净,并使用有效的警告(或-w)。 考虑放弃你的代码。 考虑改变你的整个世界观。 考虑一下......哦,没关系。
- 始终如一。
- 对人好点。
Perl - Regular Expressions
正则表达式是一串字符,用于定义您正在查看的图案。 Perl中正则表达式的语法与您在其他正则表达式支持程序(如 sed , grep 和 awk 的语法非常相似。
应用正则表达式的基本方法是使用模式绑定运算符=〜和 ! 〜。 第一个运算符是测试和赋值运算符。
Perl中有三个正则表达式运算符。
- 匹配正则表达式 - m //
- 替代正则表达式 - s ///
- 音译正则表达式 - tr ///
每种情况下的正斜杠都充当您指定的正则表达式(正则表达式)的分隔符。 如果您对任何其他分隔符感到满意,则可以使用代替正斜杠。
匹配运算符
匹配运算符m //用于将字符串或语句与正则表达式进行匹配。 例如,要将字符序列“foo”与标量$ bar匹配,您可以使用如下语句 -
#!/usr/bin/perl
$bar = "This is foo and again foo";
if ($bar =~ /foo/) {
print "First time is matching\n";
} else {
print "First time is not matching\n";
$bar = "foo";
if ($bar =~ /foo/) {
print "Second time is matching\n";
} else {
print "Second time is not matching\n";
1234567891011121314执行上述程序时,会产生以下结果 -
First time is matching
Second time is matching
123m //实际上与q //运算符系列的工作方式相同。您可以使用自然匹配字符的任意组合作为表达式的分隔符。 例如,m {},m()和m> 所以上面的例子可以重写如下 -
#!/usr/bin/perl
$bar = "This is foo and again foo";
if ($bar =~ m[foo]) {
print "First time is matching\n";
} else {
print "First time is not matching\n";
$bar = "foo";
if ($bar =~ m{foo}) {
print "Second time is matching\n";
} else {
print "Second time is not matching\n";
1234567891011121314如果分隔符是正斜杠,则可以从m //中省略m,但对于所有其他分隔符,必须使用m前缀。
请注意,如果表达式匹配,整个匹配表达式(即=〜或!〜左侧的表达式和匹配运算符)将返回true(在标量上下文中)。 因此声明 -
$true = ($foo =~ m/foo/);
12如果foo与正则表达式匹配,则将foo与正则表达式匹配,则将 true设置为1;如果匹配失败,则将0设置为0。 在列表上下文中,匹配返回任何分组表达式的内容。 例如,从时间字符串中提取小时,分钟和秒时,我们可以使用 -
my ($hours, $minutes, $seconds) = ($time =~ m/(\d+):(\d+):(\d+)/);
12匹配运算符修饰符
匹配运算符支持自己的一组修饰符。 /g修饰符允许全局匹配。 /i修饰符将使匹配大小写不敏感。 这是修饰符的完整列表
| Sr.No. | 修饰符和描述 |
|---|
只匹配一次
还有一个更简单的匹配算子版本 - ?PATTERN? 运算符。 这与m //运算符基本相同,只是它在每次重置调用之间搜索的字符串中只匹配一次。
例如,您可以使用它来获取列表中的第一个和最后一个元素 -
#!/usr/bin/perl
@list = qw/food foosball subeo footnote terfoot canic footbrdige/;
foreach (@list) {
$first = $1 if /(foo.*?)/;
$last = $1 if /(foo.*)/;
print "First: $first, Last: $last\n";
12345678执行上述程序时,会产生以下结果 -
First: food, Last: footbrdige
12正则表达式变量
正则表达式变量包括 $ ,其中包含匹配的最后一个分组匹配; $& ,包含整个匹配的字符串; $` ,包含匹配字符串之前的所有内容; 和 $' ,包含匹配字符串后的所有内容。 以下代码演示了结果 -
#!/usr/bin/perl
$string = "The food is in the salad bar";
$string =~ m/foo/;
print "Before: $`\n";
print "Matched: $&\n";
print "After: $'\n";
1234567执行上述程序时,会产生以下结果 -
Before: The
Matched: foo
After: d is in the salad bar
1234替代运算符
替换运算符s ///实际上只是匹配运算符的扩展,它允许您替换与某些新文本匹配的文本。 运算符的基本形式是 -
s/PATTERN/REPLACEMENT/;
12PATTERN是我们正在寻找的文本的正则表达式。 REPLACEMENT是我们要用来替换找到的文本的文本或正则表达式的规范。 例如,我们可以使用以下正则表达式将所有出现的 dog 替换为 cat -
#/user/bin/perl
$string = "The cat sat on the mat";
$string =~ s/cat/dog/;
print "$string\n";
12345执行上述程序时,会产生以下结果 -
The dog sat on the mat
12替换运算符修饰符
以下是替换运算符使用的所有修饰符的列表。
| Sr.No. | 修饰符和描述 |
|---|
翻译运算符
翻译与替换原则类似,但不完全相同,但与替换不同,翻译(或音译)不使用正则表达式来搜索替换值。 翻译经营者是 -
tr/SEARCHLIST/REPLACEMENTLIST/cds
y/SEARCHLIST/REPLACEMENTLIST/cds
123该翻译将SEARCHLIST中出现的所有字符替换为REPLACEMENTLIST中的相应字符。 例如,使用“猫坐在垫子上”。 我们在本章中使用过的字符串 -
#/user/bin/perl
$string = 'The cat sat on the mat';
$string =~ tr/a/o/;
print "$string\n";
12345执行上述程序时,会产生以下结果 -
The cot sot on the mot.
12也可以使用标准Perl范围,允许您通过字母或数值指定字符范围。 要更改字符串的大小写,可以使用以下语法代替 uc 函数。
$string =~ tr/a-z/A-Z/;
12翻译运算符修饰符
以下是与翻译相关的运算符列表。
| Sr.No. | 修饰符和描述 |
|---|
/d修饰符删除与REPARACEMENT列表中没有相应条目的SEARCHLIST匹配的字符。 例如 -
#!/usr/bin/perl
$string = 'the cat sat on the mat.';
$string =~ tr/a-z/b/d;
print "$string\n";
12345执行上述程序时,会产生以下结果 -
b b b.
12最后一个修饰符/ s删除了被替换的重复字符序列,因此 -
#!/usr/bin/perl
$string = 'food';
$string = 'food';
$string =~ tr/a-z/a-z/s;
print "$string\n";
123456执行上述程序时,会产生以下结果 -
fod
12更复杂的正则表达式
您不必只需匹配固定字符串。 事实上,通过使用更复杂的正则表达式,您可以匹配任何您梦寐以求的东西。 这是一个快速的备忘单 -
下表列出了Python中可用的正则表达式语法。
| Sr.No. | 模式和描述 |
|---|
^元字符匹配字符串的开头,$ metasymbol匹配字符串的结尾。 以下是一些简短的例子。
# nothing in the string (start and end are adjacent)
# a three digits, each followed by a whitespace
# character (eg "3 4 5 ")
/(\d\s) {3}/
# matches a string in which every
# odd-numbered letter is a (eg "abacadaf")
/(a.)+/
# string starts with one or more digits
/^\d+/
# string that ends with one or more digits
/\d+$/
12345678910111213让我们看看另一个例子。
#!/usr/bin/perl
$string = "Cats go Catatonic\nWhen given Catnip";
($start) = ($string =~ /\A(.*?) /);
@lines = $string =~ /^(.*?) /gm;
print "First word: $start\n","Line starts: @lines\n";
123456执行上述程序时,会产生以下结果 -
First word: Cats
Line starts: Cats When
123匹配边界
\b 匹配任何单词边界,由\ w类和\ W类之间的差异定义。 因为\ w包含单词的字符,而\ W包含相反的字符,这通常意味着单词的终止。 \B 断言匹配任何不是单词边界的位置。 例如 -
/\bcat\b/ # Matches 'the cat sat' but not 'cat on the mat'
/\Bcat\B/ # Matches 'verification' but not 'the cat on the mat'
/\bcat\B/ # Matches 'catatonic' but not 'polecat'
/\Bcat\b/ # Matches 'polecat' but not 'catatonic'
12345选择替代品
| 字符就像Perl中的标准或按位OR。 它指定正则表达式或组中的备用匹配。 例如,要在表达式中匹配“cat”或“dog”,您可以使用此 -
if ($string =~ /cat|dog/)
12您可以将表达式的各个元素组合在一起,以支持复杂匹配。 搜索两个人的名字可以通过两个单独的测试来实现,像这样 -
if (($string =~ /Martin Brown/) || ($string =~ /Sharon Brown/))
This could be written as follows
if ($string =~ /(Martin|Sharon) Brown/)
1234分组匹配
从正则表达的角度来看,除了前者稍微更清楚之外没有区别。
$string =~ /(\S+)\s+(\S+)/;
$string =~ /\S+\s+\S+/;
1234但是,分组的好处是它允许我们从正则表达式中提取序列。 分组按照它们在原始文件中出现的顺序作为列表返回。 例如,在下面的片段中,我们从字符串中提取了小时,分钟和秒。
my ($hours, $minutes, $seconds) = ($time =~ m/(\d+):(\d+):(\d+)/);
12除了这个直接方法,匹配组也可以在特殊的$ x变量中使用,其中x是正则表达式中的组的编号。 因此,我们可以重写前面的例子如下 -
#!/usr/bin/perl
$time = "12:05:30";
$time =~ m/(\d+):(\d+):(\d+)/;
my ($hours, $minutes, $seconds) = ($1, $2, $3);
print "Hours : $hours, Minutes: $minutes, Second: $seconds\n";
123456执行上述程序时,会产生以下结果 -
Hours : 12, Minutes: 05, Second: 30
12在替换表达式中使用组时,可以在替换文本中使用$ x语法。 因此,我们可以使用这个重新格式化日期字符串 -
#!/usr/bin/perl
$date = '03/26/1999';
$date =~ s#(\d+)/(\d+)/(\d+)#$3/$1/$2#;
print "$date\n";
12345执行上述程序时,会产生以下结果 -
1999/03/26
12\G断言
\G断言允许您从最后一次匹配发生的位置继续搜索。 例如,在下面的代码中,我们使用了\ G,以便我们可以搜索到正确的位置然后提取一些信息,而无需创建更复杂的单个正则表达式 -
#!/usr/bin/perl
$string = "The time is: 12:31:02 on 4/12/00";
$string =~ /:\s+/g;
($time) = ($string =~ /\G(\d+:\d+:\d+)/);
$string =~ /.+\s+/g;
($date) = ($string =~ m{\G(\d+/\d+/\d+)});
print "Time: $time, Date: $date\n";
12345678执行上述程序时,会产生以下结果 -
Time: 12:31:02, Date: 4/12/00
12\G断言实际上只是pos函数的metasymbol等价物,因此在正则表达式调用之间你可以继续使用pos,甚至可以通过使用pos作为左值子程序来修改pos的值(因此也可以修改\ G)。
Regular-expression Examples
文字字符
| Sr.No. | 示例和说明 |
|---|
角色类
| Sr.No. | 示例和说明 |
|---|
特殊字符类
| Sr.No. | 示例和说明 |
|---|
重复案件
| Sr.No. | 示例和说明 |
|---|
Nongreedy Repetition
这匹配最小的重复次数 -
| Sr.No. | 示例和说明 |
|---|
用括号分组
| Sr.No. | 示例和说明 |
|---|
Backreferences
这与之前匹配的组再次匹配 -
| Sr.No. | 示例和说明 |
|---|
替代品(Alternatives)
| Sr.No. | 示例和说明 |
|---|
Anchors
这需要指定匹配位置。
| Sr.No. | 示例和说明 |
|---|
带括号的特殊语法
| Sr.No. | 示例和说明 |
|---|
Perl - Sending Email
使用sendmail实用程序
发送简单消息
如果您正在使用Linux/Unix机器,那么您只需在Perl程序中使用 sendmail 实用程序即可发送电子邮件。 这是一个示例脚本,可以将电子邮件发送到给定的电子邮件ID。 只需确保sendmail实用程序的给定路径是正确的。 对于Linux/Unix机器,这可能有所不同。
#!/usr/bin/perl
$to = 'abcd@gmail.com';
$from = 'webmaster@yourdomain.com';
$subject = 'Test Email';
$message = 'This is test email sent by Perl Script';
open(MAIL, "|/usr/sbin/sendmail -t");
# Email Header
print MAIL "To: $to\n";
print MAIL "From: $from\n";
print MAIL "Subject: $subject\n\n";
# Email Body
print MAIL $message;
close(MAIL);
print "Email Sent Successfully\n";
123456789101112131415实际上,上面的脚本是一个客户端电子邮件脚本,它将起草电子邮件并提交给在Linux/Unix机器上本地运行的服务器。 此脚本不负责将电子邮件发送到实际目的地。 因此,您必须确保在计算机上正确配置并运行电子邮件服务器,以便将电子邮件发送到给定的电子邮件ID。
发送HTML消息
如果您想使用sendmail发送HTML格式的电子邮件,那么您只需在电子邮件的标题部分添加 Content-type: text/html\n ,如下所示 -
#!/usr/bin/perl
$to = 'abcd@gmail.com';
$from = 'webmaster@yourdomain.com';
$subject = 'Test Email';
$message = '<h1>This is test email sent by Perl Script</h1>';
open(MAIL, "|/usr/sbin/sendmail -t");
# Email Header
print MAIL "To: $to\n";
print MAIL "From: $from\n";
print MAIL "Subject: $subject\n\n";
print MAIL "Content-type: text/html\n";
# Email Body
print MAIL $message;
close(MAIL);
print "Email Sent Successfully\n";
12345678910111213141516使用MIME :: Lite模块
如果您正在使用Windows机器,那么您将无法访问sendmail实用程序。 但您可以使用MIME:Lite perl模块编写自己的电子邮件客户端。 您可以从 MIME-Lite-3.01.tar.gz 下载此模块,并将其安装在Windows或Linux/Unix机器上。 要安装它,请按照简单的步骤 -
$tar xvfz MIME-Lite-3.01.tar.gz
$cd MIME-Lite-3.01
$perl Makefile.PL
$make
$make install
123456就是这样,您将在您的计算机上安装MIME :: Lite模块。 现在,您已准备好使用下面介绍的简单脚本发送电子邮件。
发送简单消息
现在,以下是一个脚本,它将负责发送电子邮件给定的电子邮件ID -
#!/usr/bin/perl
use MIME::Lite;
$to = 'abcd@gmail.com';
$cc = 'efgh@mail.com';
$from = 'webmaster@yourdomain.com';
$subject = 'Test Email';
$message = 'This is test email sent by Perl Script';
$msg = MIME::Lite->new(
From => $from,
To => $to,
Cc => $cc,
Subject => $subject,
Data => $message
$msg->send;
print "Email Sent Successfully\n";
1234567891011121314151617发送HTML消息
如果您想使用sendmail发送HTML格式的电子邮件,那么您只需在电子邮件的标题部分添加 Content-type: text/html\n 。 以下是脚本,它将负责发送HTML格式的电子邮件 -
#!/usr/bin/perl
use MIME::Lite;
$to = 'abcd@gmail.com';
$cc = 'efgh@mail.com';
$from = 'webmaster@yourdomain.com';
$subject = 'Test Email';
$message = '<h1>This is test email sent by Perl Script</h1>';
$msg = MIME::Lite->new(
From => $from,
To => $to,
Cc => $cc,
Subject => $subject,
Data => $message
$msg->attr("content-type" => "text/html");
$msg->send;
print "Email Sent Successfully\n";
123456789101112131415161718发送附件
如果您要发送附件,则以下脚本可用于此目的 -
#!/usr/bin/perl
use MIME::Lite;
$to = 'abcd@gmail.com';
$cc = 'efgh@mail.com';
$from = 'webmaster@yourdomain.com';
$subject = 'Test Email';
$message = 'This is test email sent by Perl Script';
$msg = MIME::Lite-=>new(
From => $from,
To => $to,
Cc => $cc,
Subject => $subject,
Type => 'multipart/mixed'
# Add your text message.
$msg->attach(Type => 'text',
Data => $message
# Specify your file as attachement.
$msg->attach(Type => 'image/gif',
Path => '/tmp/logo.gif',
Filename => 'logo.gif',
Disposition => 'attachment'
$msg->send;
print "Email Sent Successfully\n";
123456789101112131415161718192021222324252627您可以使用attach()方法在电子邮件中附加任意数量的文件。
使用SMTP服务器
如果您的计算机未运行电子邮件服务器,则可以使用远程位置提供的任何其他电子邮件服务器。 但是要使用任何其他电子邮件服务器,您需要拥有ID,密码,URL等。一旦获得了所有必需的信息,您只需要在 send() 方法中提供该信息,如下所示 -
$msg->send('smtp', "smtp.myisp.net", AuthUser=>"id", AuthPass=>"password" );
12您可以与您的电子邮件服务器管理员联系以获取上述信息,如果用户ID和密码尚未提供,则您的管理员可以在几分钟内创建它。
Perl - Socket Programming
什么是套接字?
Socket是一种Berkeley UNIX机制,用于在不同进程之间创建虚拟双工连接。 随后将其移植到每个已知的OS上,使得能够跨越在不同OS软件上运行的地理位置的系统之间进行通信。 如果不是套接字,系统之间的大多数网络通信永远不会发生。
仔细看看; 网络上的典型计算机系统根据其上运行的各种应用程序接收和发送信息。 此信息被路由到系统,因为为其指定了唯一的IP地址。 在系统上,此信息将提供给相关应用程序,这些应用程序可以侦听不同的端口。 例如,因特网浏览器在端口80上侦听从Web服务器接收的信息。 我们还可以编写可以监听和发送/接收特定端口号信息的自定义应用程序。
现在,让我们总结一下套接字是一个IP地址和一个端口,允许连接通过网络发送和接收数据。
为了解释上面提到的套接字概念,我们将以Perl为例进行客户端 - 服务器编程。 要完成客户端服务器架构,我们必须执行以下步骤 -
创建服务器
- 使用 socket 调用创建 socket 。
- 使用 bind 调用将套接字绑定到端口地址。
- 使用 listen 调用 listen 端口地址处的套接字。
- 使用 accept 调用接受客户端连接。
创建客户端
- 使用 socket 调用创建 socket 。
- 使用 connect 调用将(套接字) connect 到服务器。
下图显示了客户端和服务器用于彼此通信的完整调用序列 -
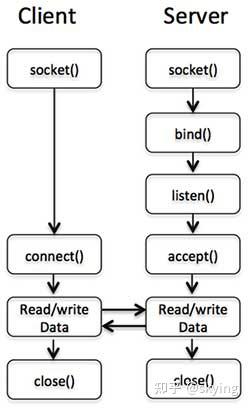
服务器端套接字调用
The socket() call
socket() 调用是建立网络连接的第一个调用是创建套接字。 此调用具有以下语法 -
socket( SOCKET, DOMAIN, TYPE, PROTOCOL );
12上面的调用创建一个SOCKET,其他三个参数是整数,它们应具有以下TCP/IP连接值。
- DOMAIN 应该是PF_INET。 你的电脑很可能是2。
- 对于TCP/IP连接, TYPE 应为SOCK_STREAM。
- PROTOCOL 应该是 (getprotobyname('tcp'))[2] 。 通过套接字说出TCP等特定协议。
所以服务器发出的socket函数调用将是这样的 -
use Socket # This defines PF_INET and SOCK_STREAM
socket(SOCKET,PF_INET,SOCK_STREAM,(getprotobyname('tcp'))[2]);
123The bind() call
socket()调用创建的套接字在绑定到主机名和端口号之前是无用的。 服务器使用以下 bind() 函数指定它们将从客户端接受连接的端口。
bind( SOCKET, ADDRESS );
12这里SOCKET是socket()调用返回的描述符,ADDRESS是包含三个元素的套接字地址(用于TCP/IP) -
- 地址族(对于TCP/IP,即AF_INET,可能是系统上的2)。
- 端口号(例如21)。
- 计算机的互联网地址(例如10.12.12.168)。
由于服务器使用bind(),因此不需要知道自己的地址,因此参数列表如下所示 -
use Socket # This defines PF_INET and SOCK_STREAM
$port = 12345; # The unique port used by the sever to listen requests
$server_ip_address = "10.12.12.168";
bind( SOCKET, pack_sockaddr_in($port, inet_aton($server_ip_address)))
or die "Can't bind to port $port! \n";
123456or die 子句非常重要,因为如果服务器在没有未完成连接的情况下死亡,除非使用 setsockopt() 函数使用选项SO_REUSEADDR,否则端口将不会立即重用。 这里使用 pack_sockaddr_in() 函数将端口和IP地址打包成二进制格式。
The listen() call
如果这是一个服务器程序,那么需要在指定的端口上发出 listen() 调用来监听,即等待传入的请求。 此调用具有以下语法 -
listen( SOCKET, QUEUESIZE );
12上面的调用使用socket()调用返回的SOCKET描述符,而QUEUESIZE是同时允许的未完成连接请求的最大数量。
The accept() call
如果这是服务器程序,则需要发出对 access() 函数的调用以接受传入连接。 此调用具有以下语法 -
accept( NEW_SOCKET, SOCKET );
12accept调用接收socket()函数返回的SOCKET描述符,并在成功完成后,为客户端和服务器之间的所有未来通信返回一个新的套接字描述符NEW_SOCKET。 如果access()调用失败,则返回FLASE,这是我们最初使用的Socket模块中定义的。
通常,accept()用于无限循环。 一旦一个连接到达,服务器就会创建一个子进程来处理它或自己提供服务,然后回去监听更多连接。
while(1) {
accept( NEW_SOCKET, SOCKT );
.......
12345现在,与服务器相关的所有呼叫都已结束,让我们看到客户端需要的呼叫。
客户端套接字调用
The connect() call
如果您要准备客户端程序,那么首先您将使用 socket() 调用来创建套接字,然后您必须使用 connect() 调用来连接到服务器。 您已经看过socket()调用语法,它将与服务器socket()调用类似,但这里是 connect() 调用的语法 -
connect( SOCKET, ADDRESS );
12这里SCOKET是客户端发出的socket()调用返回的套接字描述符,ADDRESS是类似于 bind 调用的套接字地址,除了它包含远程服务器的IP地址。
$port = 21; # For example, the ftp port
$server_ip_address = "10.12.12.168";
connect( SOCKET, pack_sockaddr_in($port, inet_aton($server_ip_address)))
or die "Can't connect to port $port! \n";
12345如果您成功连接到服务器,则可以使用SOCKET描述符开始将命令发送到服务器,否则您的客户端将通过给出错误消息来发出。
客户端 - 服务器示例
以下是使用Perl套接字实现简单客户端 - 服务器程序的Perl代码。 这里服务器侦听传入的请求,一旦建立连接,它只是 Smile from the server 回复 Smile from the server 。 客户端读取该消息并在屏幕上打印。 假设我们的服务器和客户端在同一台机器上,让我们看看它是如何完成的。
创建服务器的脚本
#!/usr/bin/perl -w
# Filename : server.pl
use strict;
use Socket;
# use port 7890 as default
my $port = shift || 7890;
my $proto = getprotobyname('tcp');
my $server = "localhost"; # Host IP running the server
# create a socket, make it reusable
socket(SOCKET, PF_INET, SOCK_STREAM, $proto)
or die "Can't open socket $!\n";
setsockopt(SOCKET, SOL_SOCKET, SO_REUSEADDR, 1)
or die "Can't set socket option to SO_REUSEADDR $!\n";
# bind to a port, then listen
bind( SOCKET, pack_sockaddr_in($port, inet_aton($server)))
or die "Can't bind to port $port! \n";
listen(SOCKET, 5) or die "listen: $!";
print "SERVER started on port $port\n";
# accepting a connection
my $client_addr;
while ($client_addr = accept(NEW_SOCKET, SOCKET)) {
# send them a message, close connection
my $name = gethostbyaddr($client_addr, AF_INET );
print NEW_SOCKET "Smile from the server";
print "Connection recieved from $name\n";
close NEW_SOCKET;
12345678910111213141516171819202122232425262728要以后台模式运行服务器,请在Unix提示符下发出以下命令 -
$perl sever.pl&
12创建客户端的脚本
!/usr/bin/perl -w
# Filename : client.pl
use strict;
use Socket;
# initialize host and port
my $host = shift || 'localhost';
my $port = shift || 7890;
my $server = "localhost"; # Host IP running the server
# create the socket, connect to the port
socket(SOCKET,PF_INET,SOCK_STREAM,(getprotobyname('tcp'))[2])
or die "Can't create a socket $!\n";
connect( SOCKET, pack_sockaddr_in($port, inet_aton($server)))
or die "Can't connect to port $port! \n";
my $line;
while ($line = <SOCKET>) {
print "$line\n";
close SOCKET or die "close: $!";
12345678910111213141516171819现在让我们在命令提示符下启动我们的客户端,它将连接到服务器并读取服务器发送的消息,并在屏幕上显示如下 -
$perl client.pl
Smile from the server
123NOTE - 如果您以点表示法提供实际IP地址,则建议在客户端和服务器中以相同格式提供IP地址,以避免混淆。
Object Oriented Programming in PERL
我们已经研究了Perl和Perl匿名数组和散列中的引用。 Perl中的面向对象概念非常基于引用和匿名数组和散列。 让我们开始学习面向对象Perl的基本概念。
对象基础知识
从Perl处理对象的角度来看,有三个主要术语。 术语是对象,类和方法。
- Perl中的 object 仅仅是对知道它属于哪个类的数据类型的引用。 该对象存储为标量变量中的引用。 因为标量只包含对象的引用,所以相同的标量可以在不同的类中保存不同的对象。
- Perl中的 class 是一个包,其中包含创建和操作对象所需的相应方法。
- Perl中的 method 是一个子程序,用包定义。 该方法的第一个参数是对象引用或包名称,具体取决于方法是否影响当前对象或类。
Perl提供了一个 bless() 函数,用于返回最终成为对象的引用。
定义一个类
在Perl中定义一个类非常简单。 类以最简单的形式对应于Perl包。 要在Perl中创建类,我们首先构建一个包。
包是一个由用户定义的变量和子程序组成的独立单元,可以一遍又一遍地重复使用。
Perl包在Perl程序中提供了一个单独的命名空间,它使子例程和变量独立于与其他包中的子例程冲突。
要在Perl中声明一个名为Person的类,我们可以 -
package Person;
12包定义的范围扩展到文件的末尾,或者直到遇到另一个包关键字。
创建和使用对象
要创建类(对象)的实例,我们需要一个对象构造函数。 此构造函数是包中定义的方法。 大多数程序员选择将此对象构造函数方法命名为new,但在Perl中,您可以使用任何名称。
您可以使用任何类型的Perl变量作为Perl中的对象。 大多数Perl程序员选择对数组或散列的引用。
让我们使用Perl哈希引用为Person类创建构造函数。 创建对象时,需要提供构造函数,该构造函数是包中返回对象引用的子例程。 通过祝福对包的类的引用来创建对象引用。 例如 -
package Person;
sub new {
my $class = shift;
my $self = {
_firstName => shift,
_lastName => shift,
_ssn => shift,
# Print all the values just for clarification.
print "First Name is $self->{_firstName}\n";
print "Last Name is $self->{_lastName}\n";
print "SSN is $self->{_ssn}\n";
bless $self, $class;
return $self;
12345678910111213141516现在让我们看看如何创建一个Object。
$object = new Person( "Mohammad", "Saleem", 23234345);
12如果您不想为任何类变量赋值,可以在consturctor中使用简单哈希。 例如 -
package Person;
sub new {
my $class = shift;
my $self = {};
bless $self, $class;
return $self;
12345678定义方法
其他面向对象的语言具有数据安全性的概念,以防止程序员直接更改对象数据,并且它们提供修改对象数据的访问器方法。 Perl没有私有变量,但我们仍然可以使用辅助方法的概念来操作对象数据。
让我们定义一个帮助方法来获得人的名字 -
sub getFirstName {
return $self->{_firstName};
1234设置人名的另一个辅助功能 -
sub setFirstName {
my ( $self, $firstName ) = @_;
$self->{_firstName} = $firstName if defined($firstName);
return $self->{_firstName};
123456现在让我们看看完整的示例:将Person包和帮助函数保存到Person.pm文件中。
#!/usr/bin/perl
package Person;
sub new {
my $class = shift;
my $self = {
_firstName => shift,
_lastName => shift,
_ssn => shift,
# Print all the values just for clarification.
print "First Name is $self->{_firstName}\n";
print "Last Name is $self->{_lastName}\n";
print "SSN is $self->{_ssn}\n";
bless $self, $class;
return $self;
sub setFirstName {
my ( $self, $firstName ) = @_;
$self->{_firstName} = $firstName if defined($firstName);
return $self->{_firstName};
sub getFirstName {
my( $self ) = @_;
return $self->{_firstName};
123456789101112131415161718192021222324252627现在让我们在employee.pl文件中使用Person对象,如下所示 -
#!/usr/bin/perl
use Person;
$object = new Person( "Mohammad", "Saleem", 23234345);
# Get first name which is set using constructor.
$firstName = $object->getFirstName();
print "Before Setting First Name is : $firstName\n";
# Now Set first name using helper function.
$object->setFirstName( "Mohd." );
# Now get first name set by helper function.
$firstName = $object->getFirstName();
print "Before Setting First Name is : $firstName\n";
123456789101112当我们执行上面的程序时,它会产生以下结果 -
First Name is Mohammad
Last Name is Saleem
SSN is 23234345
Before Setting First Name is : Mohammad
Before Setting First Name is : Mohd.
123456继承 (Inheritance)
面向对象编程具有非常好的和有用的概念,称为继承。 继承只是意味着父类的属性和方法可供子类使用。 因此,您不必一次又一次地编写相同的代码,您可以继承父类。
例如,我们可以有一个Employee类,它继承自Person。 这被称为“isa”关系,因为员工是一个人。 Perl有一个特殊变量@ISA来帮助解决这个问题。 @ISA管理(方法)继承。
以下是使用继承时要考虑的重点 -
- Perl在指定对象的类中搜索给定的方法或属性,即变量。
- Perl搜索对象类的@ISA数组中定义的类。
- 如果在步骤1或2中找不到任何方法,则Perl使用AUTOLOAD子例程(如果在@ISA树中找到一个子例程)。
- 如果仍然找不到匹配方法,则Perl将搜索作为标准Perl库的一部分的UNIVERSAL类(包)中的方法。
- 如果仍未找到该方法,则Perl放弃并引发运行时异常。
因此,要创建一个将从Person类继承方法和属性的新Employee类,我们只需编写如下代码:将此代码保存到Employee.pm中。
#!/usr/bin/perl
package Employee;
use Person;
use strict;
our @ISA = qw(Person); # inherits from Person
123456现在,Employee Class具有从Person类继承的所有方法和属性,您可以按如下方式使用它们:使用main.pl文件对其进行测试 -
#!/usr/bin/perl
use Employee;
$object = new Employee( "Mohammad", "Saleem", 23234345);
# Get first name which is set using constructor.
$firstName = $object->getFirstName();
print "Before Setting First Name is : $firstName\n";
# Now Set first name using helper function.
$object->setFirstName( "Mohd." );
# Now get first name set by helper function.
$firstName = $object->getFirstName();
print "After Setting First Name is : $firstName\n";
123456789101112当我们执行上面的程序时,它会产生以下结果 -
First Name is Mohammad
Last Name is Saleem
SSN is 23234345
Before Setting First Name is : Mohammad
Before Setting First Name is : Mohd.
123456方法覆盖
子类Employee从父类Person继承所有方法。 但是,如果您想在子类中覆盖这些方法,那么您可以通过提供自己的实现来实现。 您可以在子类中添加其他函数,也可以在其父类中添加或修改现有方法的功能。 它可以按如下方式完成:修改Employee.pm文件。
#!/usr/bin/perl
package Employee;
use Person;
use strict;
our @ISA = qw(Person); # inherits from Person
# Override constructor
sub new {
my ($class) = @_;
# Call the constructor of the parent class, Person.
my $self = $class->SUPER::new( $_[1], $_[2], $_[3] );
# Add few more attributes
$self->{_id} = undef;
$self->{_title} = undef;
bless $self, $class;
return $self;
# Override helper function
sub getFirstName {
my( $self ) = @_;
# This is child class function.
print "This is child class helper function\n";
return $self->{_firstName};
# Add more methods
sub setLastName{
my ( $self, $lastName ) = @_;
$self->{_lastName} = $lastName if defined($lastName);
return $self->{_lastName};
sub getLastName {
my( $self ) = @_;
return $self->{_lastName};
1234567891011121314151617181920212223242526272829303132333435现在让我们再次尝试在main.pl文件中使用Employee对象并执行它。
#!/usr/bin/perl
use Employee;
$object = new Employee( "Mohammad", "Saleem", 23234345);
# Get first name which is set using constructor.
$firstName = $object->getFirstName();
print "Before Setting First Name is : $firstName\n";
# Now Set first name using helper function.
$object->setFirstName( "Mohd." );
# Now get first name set by helper function.
$firstName = $object->getFirstName();
print "After Setting First Name is : $firstName\n";
123456789101112当我们执行上面的程序时,它会产生以下结果 -
First Name is Mohammad
Last Name is Saleem
SSN is 23234345
This is child class helper function
Before Setting First Name is : Mohammad
This is child class helper function
After Setting First Name is : Mohd.
12345678默认自动加载
Perl提供了一个在任何其他编程语言中都找不到的功能:默认子程序。 这意味着,如果定义一个名为 AUTOLOAD(), 的函数 AUTOLOAD(), 那么对未定义子程序的任何调用都将自动调用AUTOLOAD()函数。 可以在此子例程中以$ AUTOLOAD的形式访问缺少的子例程的名称。
默认自动加载功能对于错误处理非常有用。 以下是实现AUTOLOAD的示例,您可以用自己的方式实现此功能。
sub AUTOLOAD {
my $self = shift;
my $type = ref ($self) || croak "$self is not an object";
my $field = $AUTOLOAD;
$field =~ s/.*://;
unless (exists $self->{$field}) {
croak "$field does not exist in object/class $type";
if (@_) {
return $self->($name) = shift;
} else {
return $self->($name);
123456789101112131415析构函数和垃圾收集
如果您之前使用过面向对象编程进行了编程,那么您将意识到需要创建一个 destructor 来释放分配给该对象的内存。 只要对象超出范围,Perl就会自动为您执行此操作。
如果你想实现你的析构函数,它应该关闭文件或做一些额外的处理,那么你需要定义一个名为 DESTROY 的特殊方法。 在Perl释放分配给它的内存之前,将在对象上调用此方法。 在所有其他方面,DESTROY方法就像任何其他方法一样,您可以在此方法中实现所需的任何逻辑。
析构函数方法只是一个名为DESTROY的成员函数(子例程),在以下情况下将自动调用 -
- 当对象引用的变量超出范围时。
- 当对象引用的变量未被删除时。
- When the script terminates
- 当perl解释器终止时
例如,您可以在您的类中简单地放入以下方法DESTROY -
package MyClass;
sub DESTROY {
print "MyClass::DESTROY called\n";
123456面向对象的Perl示例
这是另一个很好的例子,它将帮助您理解Perl的面向对象概念。 将此源代码放入任何perl文件并执行它。
#!/usr/bin/perl
# Following is the implementation of simple Class.
package MyClass;
sub new {
print "MyClass::new called\n";
my $type = shift; # The package/type name
my $self = {}; # Reference to empty hash
return bless $self, $type;
sub DESTROY {
print "MyClass::DESTROY called\n";
sub MyMethod {
print "MyClass::MyMethod called!\n";
# Following is the implemnetation of Inheritance.
package MySubClass;
@ISA = qw( MyClass );
sub new {
print "MySubClass::new called\n";
my $type = shift; # The package/type name
my $self = MyClass->new; # Reference to empty hash
return bless $self, $type;
sub DESTROY {
print "MySubClass::DESTROY called\n";
sub MyMethod {
my $self = shift;
$self->SUPER::MyMethod();
print " MySubClass::MyMethod called!\n";
# Here is the main program using above classes.
package main;
print "Invoke MyClass method\n";
$myObject = MyClass->new();
$myObject->MyMethod();
print "Invoke MySubClass method\n";
$myObject2 = MySubClass->new();
$myObject2->MyMethod();
print "Create a scoped object\n";
my $myObject2 = MyClass->new();
# Destructor is called automatically here
print "Create and undef an object\n";
$myObject3 = MyClass->new();
undef $myObject3;
print "Fall off the end of the script...\n";
# Remaining destructors are called automatically here
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051当我们执行上面的程序时,它会产生以下结果 -
Invoke MyClass method
MyClass::new called
MyClass::MyMethod called!
Invoke MySubClass method
MySubClass::new called
MyClass::new called
MyClass::MyMethod called!
MySubClass::MyMethod called!
Create a scoped object
MyClass::new called
MyClass::DESTROY called
Create and undef an object
MyClass::new called
MyClass::DESTROY called
Fall off the end of the script...
MyClass::DESTROY called
MySubClass::DESTROY called
123456789101112131415161718Perl - Database Access
本章将教您如何访问Perl脚本中的数据库。 从Perl 5开始,使用 DBI 模块编写数据库应用程序变得非常容易。 DBI代表Perl的 Database Independent Interface ,这意味着DBI在Perl代码和底层数据库之间提供了一个抽象层,允许您非常轻松地切换数据库实现。
DBI是Perl编程语言的数据库访问模块。 它提供了一组方法,变量和约定,提供了一致的数据库接口,与所使用的实际数据库无关。
DBI应用程序的体系结构
DBI独立于后端中可用的任何数据库。 无论您是使用Oracle,MySQL还是Informix等,都可以使用DBI。从以下architure图中可以清楚地看到这一点。
这里DBI负责通过API(即应用程序编程接口)获取所有SQL命令,并将它们分派给适当的驱动程序以进行实际执行。 最后,DBI负责从驱动程序获取结果并将其返回给调用scritp。
符号和约定
在本章中,将使用以下符号,建议您也应遵循相同的约定。
$dsn Database source name
$dbh Database handle object
$sth Statement handle object
$h Any of the handle types above ($dbh, $sth, or $drh)
$rc General Return Code (boolean: true=ok, false=error)
$rv General Return Value (typically an integer)
@ary List of values returned from the database.
$rows Number of rows processed (if available, else -1)
$fh A filehandle
undef NULL values are represented by undefined values in Perl
\%attr Reference to a hash of attribute values passed to methods
123456789101112数据库连接 (Database Connection)
假设我们要使用MySQL数据库。 在连接到数据库之前,请确保以下内容。 如果您不了解如何在MySQL数据库中创建数据库和表,您可以参考我们的MySQL教程。
- 您已经创建了一个名为TESTDB的数据库。
- 您已在TESTDB中创建了一个名为TEST_TABLE的表。
- 此表包含FIRST_NAME,LAST_NAME,AGE,SEX和INCOME字段。
- 用户ID“testuser”和密码“test123”设置为访问TESTDB。
- Perl Module DBI已正确安装在您的计算机上。
- 您已经通过MySQL教程来了解MySQL基础知识。
以下是连接MySQL数据库“TESTDB”的示例 -
#!/usr/bin/perl
use DBI
use strict;
my $driver = "mysql";
my $database = "TESTDB";
my $dsn = "DBI:$driver:database=$database";
my $userid = "testuser";
my $password = "test123";
my $dbh = DBI->connect($dsn, $userid, $password ) or die $DBI::errstr;
12345678910如果与数据源建立连接,则返回数据库句柄并保存到dbh以供进一步使用,否则dbh以供进一步使用,否则 dbh设置为 undef 值,$ DBI :: errstr返回错误字符串。
插入操作
如果要在表中创建一些记录,则需要INSERT操作。 这里我们使用表TEST_TABLE来创建记录。 因此,一旦建立了数据库连接,我们就可以在TEST_TABLE中创建记录了。 以下是在TEST_TABLE中创建单个记录的过程。 您可以使用相同的概念创建任意数量的记录。
记录创建采取以下步骤 -
- 使用INSERT语句准备SQL语句。 这将使用 prepare() API完成。
- 执行SQL查询以从数据库中选择所有结果。 这将使用 execute() API完成。
- 释放Stattement句柄。 这将使用 finish() API finish() 。
- 如果一切正常,则 commit 此操作,否则您可以 rollback 完成事务。 提交和回滚将在下一节中介绍。
my $sth = $dbh->prepare("INSERT INTO TEST_TABLE
(FIRST_NAME, LAST_NAME, SEX, AGE, INCOME )
values
('john', 'poul', 'M', 30, 13000)");
$sth->execute() or die $DBI::errstr;
$sth->finish();
$dbh->commit or die $DBI::errstr;
12345678使用绑定值 (Using Bind Values)
可能存在未提前输入要输入的值的情况。 因此,您可以使用绑定变量,它将在运行时获取所需的值。 Perl DBI模块使用问号代替实际值,然后在运行时通过execute()API传递实际值。 以下是示例 -
my $first_name = "john";
my $last_name = "poul";
my $sex = "M";
my $income = 13000;
my $age = 30;
my $sth = $dbh->prepare("INSERT INTO TEST_TABLE
(FIRST_NAME, LAST_NAME, SEX, AGE, INCOME )
values
(?,?,?,?)");
$sth->execute($first_name,$last_name,$sex, $age, $income)
or die $DBI::errstr;
$sth->finish();
$dbh->commit or die $DBI::errstr;
1234567891011121314读操作 (READ Operation)
READ对任何数据库的操作意味着从数据库中获取一些有用的信息,即来自一个或多个表的一个或多个记录。 因此,一旦建立了数据库连接,我们就可以对此数据库进行查询。 以下是查询AGE大于20的所有记录的过程。这将需要四个步骤 -
- 根据所需条件准备SQL SELECT查询。 这将使用 prepare() API完成。
- 执行SQL查询以从数据库中选择所有结果。 这将使用 execute() API完成。
- 逐个获取所有结果并打印这些结果。这将使用 fetchrow_array() API完成。
- 释放Stattement句柄。 这将使用 finish() API finish() 。
my $sth = $dbh->prepare("SELECT FIRST_NAME, LAST_NAME
FROM TEST_TABLE
WHERE AGE > 20");
$sth->execute() or die $DBI::errstr;
print "Number of rows found :" + $sth->rows;
while (my @row = $sth->fetchrow_array()) {
my ($first_name, $last_name ) = @row;
print "First Name = $first_name, Last Name = $last_name\n";
$sth->finish();
1234567891011使用绑定值 (Using Bind Values)
可能存在事先未给出条件的情况。 因此,您可以使用绑定变量,它将在运行时获取所需的值。 Perl DBI模块使用问号代替实际值,然后在运行时通过execute()API传递实际值。 以下是示例 -
$age = 20;
my $sth = $dbh->prepare("SELECT FIRST_NAME, LAST_NAME
FROM TEST_TABLE
WHERE AGE > ?");
$sth->execute( $age ) or die $DBI::errstr;
print "Number of rows found :" + $sth->rows;
while (my @row = $sth->fetchrow_array()) {
my ($first_name, $last_name ) = @row;
print "First Name = $first_name, Last Name = $last_name\n";
$sth->finish();
123456789101112更新操作
UPDATE对任何数据库的操作意味着更新数据库表中已有的一个或多个记录。 以下是将SEX更新为“M”的所有记录的过程。 在这里,我们将所有男性的年龄增加一年。 这将需要三个步骤 -
- 根据所需条件准备SQL查询。 这将使用 prepare() API完成。
- 执行SQL查询以从数据库中选择所有结果。 这将使用 execute() API完成。
- 释放Stattement句柄。 这将使用 finish() API finish() 。
- 如果一切正常,则 commit 此操作,否则您可以 rollback 完成事务。 有关提交和回滚API,请参阅下一节。
my $sth = $dbh->prepare("UPDATE TEST_TABLE
SET AGE = AGE + 1
WHERE SEX = 'M'");
$sth->execute() or die $DBI::errstr;
print "Number of rows updated :" + $sth->rows;
$sth->finish();
$dbh->commit or die $DBI::errstr;
12345678使用绑定值 (Using Bind Values)
可能存在事先未给出条件的情况。 因此,您可以使用绑定变量,它将在运行时获取所需的值。 Perl DBI模块使用问号代替实际值,然后在运行时通过execute()API传递实际值。 以下是示例 -
$sex = 'M';
my $sth = $dbh->prepare("UPDATE TEST_TABLE
SET AGE = AGE + 1
WHERE SEX = ?");
$sth->execute('$sex') or die $DBI::errstr;
print "Number of rows updated :" + $sth->rows;
$sth->finish();
$dbh->commit or die $DBI::errstr;
123456789在某些情况下,您希望设置一个值,该值不会提前给出,因此您可以使用绑定值,如下所示。 在这个例子中,所有男性的收入将设置为10000。
$sex = 'M';
$income = 10000;
my $sth = $dbh->prepare("UPDATE TEST_TABLE
SET INCOME = ?
WHERE SEX = ?");
$sth->execute( $income, '$sex') or die $DBI::errstr;
print "Number of rows updated :" + $sth->rows;
$sth->finish();
123456789删除操作
如果要从数据库中删除某些记录,则需要DELETE操作。 以下是从TEST_TABLE中删除所有记录的过程,其中AGE等于30.此操作将采取以下步骤。
- 根据所需条件准备SQL查询。 这将使用 prepare() API完成。
- 执行SQL查询以从数据库中删除所需的记录。 这将使用 execute() API完成。
- 释放Stattement句柄。 这将使用 finish() API finish() 。
- 如果一切正常,则 commit 此操作,否则您可以 rollback 完成事务。
$age = 30;
my $sth = $dbh->prepare("DELETE FROM TEST_TABLE
WHERE AGE = ?");
$sth->execute( $age ) or die $DBI::errstr;
print "Number of rows deleted :" + $sth->rows;
$sth->finish();
$dbh->commit or die $DBI::errstr;
12345678Using do 语句
如果您正在执行UPDATE,INSERT或DELETE,则没有数据从数据库返回,因此执行此操作有一个快捷方式。 您可以使用 do 语句执行以下任何命令。
$dbh->do('DELETE FROM TEST_TABLE WHERE age =30');
12如果成功 do 返回true值,如果失败 do 返回false值。 实际上,如果成功,则返回受影响的行数。 在示例中,它将返回实际删除的行数。
COMMIT操作
提交是向数据库发出绿色信号以完成更改的操作,在此操作之后,任何更改都不能恢复到其原始位置。
这是一个调用 commit API的简单示例。
$dbh->commit or die $dbh->errstr;
12回滚操作
如果您对所有更改不满意,或者在任何操作之间遇到错误,则可以还原这些更改以使用 rollback API。
这是一个调用 rollback API的简单示例。
$dbh->rollback or die $dbh->errstr;
12开始交易
许多数据库支持事务。 这意味着您可以创建一大堆可以修改数据库的查询,但实际上并未进行任何更改。 然后在最后,您发出特殊的SQL查询 COMMIT ,并同时进行所有更改。 或者,您可以发出查询ROLLBACK,在这种情况下,所有更改都将被丢弃,数据库保持不变。
Perl DBI模块提供了 begin_work API,它启用事务(通过关闭AutoCommit)直到下一次调用commit或rollback。 在下一次提交或回滚后,AutoCommit将自动再次打开。
$rc = $dbh->begin_work or die $dbh->errstr;
12AutoCommit选项
如果您的交易很简单,您可以省去必须发出大量提交的麻烦。 进行连接调用时,可以指定 AutoCommit 选项,该选项将在每次成功查询后执行自动提交操作。 这是它的样子 -
my $dbh = DBI->connect($dsn, $userid, $password,
{AutoCommit => 1})
or die $DBI::errstr;
1234这里AutoCommit可以取值1或0,其中1表示AutoCommit打开,0表示AutoCommit关闭。
自动错误处理
进行连接调用时,可以指定一个RaiseErrors选项,自动为您处理错误。 发生错误时,DBI将中止您的程序而不是返回失败代码。 如果您只想在错误中中止程序,这可能很方便。 这是它的样子 -
my $dbh = DBI->connect($dsn, $userid, $password,
{RaiseError => 1})
or die $DBI::errstr;
1234这里RaiseError可以取值1或0。
断开数据库 (Disconnecting Database)
要断开数据库连接,请使用 disconnect API,如下所示 -
$rc = $dbh->disconnect or warn $dbh->errstr;
12遗憾的是,断开连接方法的事务行为是不确定的。 某些数据库系统(如Oracle和Ingres)将自动提交任何未完成的更改,但其他数据库系统(如Informix)将回滚任何未完成的更改。 不使用AutoCommit的应用程序应在调用disconnect之前显式调用commit或rollback。
使用NULL值
未定义的值或undef用于指示NULL值。 您可以像使用非NULL值一样插入和更新具有NULL值的列。 这些示例使用NULL值插入和更新列时代 -
$sth = $dbh->prepare(qq {
INSERT INTO TEST_TABLE (FIRST_NAME, AGE) VALUES (?, ?)
$sth->execute("Joe", undef);
12345这里 qq{} 用于返回带引号的字符串以 prepare API。 但是,在WHERE子句中尝试使用NULL值时必须小心。 考虑 -
SELECT FIRST_NAME FROM TEST_TABLE WHERE age = ?
12将undef(NULL)绑定到占位符将不会选择具有NULL年龄的行! 至少对于符合SQL标准的数据库引擎。 有关此原因,请参阅数据库引擎的SQL手册或任何SQL书籍。 要显式选择NULL,您必须说“WHERE age IS NULL”。
一个常见的问题是让代码片段在运行时处理可以定义或undef(非NULL或NULL)的值。 一种简单的技术是根据需要准备适当的语句,并将占位符替换为非NULL的情况 -
$sql_clause = defined $age? "age = ?" : "age IS NULL";
$sth = $dbh->prepare(qq {
SELECT FIRST_NAME FROM TEST_TABLE WHERE $sql_clause
$sth->execute(defined $age ? $age : ());
123456其他一些DBI函数 (Some Other DBI Functions)
available_drivers
@ary = DBI->available_drivers;
@ary = DBI->available_drivers($quiet);
123通过@INC中的目录搜索DBD :: *模块,返回所有可用驱动程序的列表。 默认情况下,如果某些驱动程序在早期目录中被其他同名的驱动程序隐藏,则会发出警告。 传递$ quiet的真值会抑制警告。
installed_drivers
%drivers = DBI->installed_drivers();
12返回已安装(加载)到当前进程中的所有驱动程序的驱动程序名称和驱动程序句柄对的列表。 驱动程序名称不包含'DBD ::'前缀。
data_sources
@ary = DBI->data_sources($driver);
12返回通过指定驱动程序可用的数据源(数据库)列表。 如果$ driver为空或undef,则使用DBI_DRIVER环境变量的值。
quote
$sql = $dbh->quote($value);
$sql = $dbh->quote($value, $data_type);
123通过转义字符串中包含的任何特殊字符(如引号)并添加所需类型的外引号,引用字符串文字以用作SQL语句中的文字值。
$sql = sprintf "SELECT foo FROM bar WHERE baz = %s",
$dbh->quote("Don't");
123对于大多数数据库类型,引用将返回'不'(包括外引号)。 quote()方法返回一个计算结果为所需字符串的SQL表达式是有效的。 例如 -
$quoted = $dbh->quote("one\ntwo\0three")
may produce results which will be equivalent to
CONCAT('one', CHAR(12), 'two', CHAR(0), 'three')
1234所有手柄共有的方法
err
$rv = $h->err;
$rv = $DBI::err
$rv = $h->err
123456从最后一个调用的驱动程序方法返回本机数据库引擎错误代码。 代码通常是一个整数但你不应该假设。 这相当于DBI::err或DBI::err或 h-> err。
errstr
$str = $h->errstr;
$str = $DBI::errstr
$str = $h->errstr
123456从最后一个调用的DBI方法返回本机数据库引擎错误消息。 这与上述“错误”方法具有相同的寿命问题。 这相当于DBI::errstr或DBI::errstr或 h-> errstr。
rows
$rv = $h->rows;
$rv = $DBI::rows
1234这将返回由先前SQL语句影响的行数,并等效于$ DBI :: rows。
trace
$h->trace($trace_settings);
12DBI具有非常有用的功能,可以生成正在执行的操作的运行时跟踪信息,在尝试跟踪DBI程序中的奇怪问题时可以节省大量时间。 您可以使用不同的值来设置跟踪级别。 这些值在0到4之间变化。值0表示禁用跟踪,4表示生成完整跟踪。
插值声明是禁止的
强烈建议不要使用插值语句,如下所示 -
while ($first_name = <>) {
my $sth = $dbh->prepare("SELECT *
FROM TEST_TABLE
WHERE FIRST_NAME = '$first_name'");
$sth->execute();
# and so on ...
12345678因此,不要使用插值语句而是使用 bind value 来准备动态SQL语句。
Perl - CGI Programming
什么是CGI?
- 通用网关接口(CGI)是一组标准,用于定义如何在Web服务器和自定义脚本之间交换信息。
- CGI规范目前由NCSA维护,NCSA定义CGI如下 -
- The Common Gateway Interface, or CGI, is a standard for external gateway programs to interface with information servers such as HTTP servers.
- 目前的版本是CGI/1.1,CGI/1.2正在进行中。
网页浏览 (Web Browsing)
为了理解CGI的概念,让我们看看当我们点击网页上可用的超链接来浏览特定网页或URL时会发生什么。
- 您的浏览器使用HTTP协议联系Web服务器并要求URL,即网页文件名。
- Web Server将检查URL并查找所请求的文件名。 如果Web服务器找到该文件,则它将文件发送回浏览器而不进一步执行,否则会发送一条错误消息,指示您已请求错误的文件。
- Web浏览器从Web服务器获取响应,并在未找到文件的情况下显示接收的文件内容或错误消息。
但是,可以以这样的方式设置HTTP服务器,以便每当请求某个目录中的文件时不发回该文件; 相反,它作为一个程序执行,无论该程序输出什么结果,都会被发回给您的浏览器进行显示。 这可以通过使用Web服务器中可用的特殊功能来完成,它被称为 Common Gateway Interface 或CGI,并且由服务器执行以产生最终结果的此类程序称为CGI脚本。 这些CGI程序可以是PERL脚本,Shell脚本,C或C ++程序等。
CGI架构图 (CGI Architecture Diagram)
Web服务器支持和配置
在继续进行CGI编程之前,请确保您的Web服务器支持CGI功能,并配置为处理CGI程序。 Web服务器要执行的所有CGI程序都保存在预先配置的目录中。 该目录称为CGI目录,按照惯例,它被命名为/ cgi-bin。 按照惯例,Perl CGI文件将扩展为 .cgi 。
第一个CGI程序 (First CGI Program)
这是一个链接到名为hello.cgi的CGI脚本的简单链接。 该文件保存在 /cgi-bin/ 目录中,它具有以下内容。 在运行CGI程序之前,请确保使用 chmod 755 hello.cgi UNIX命令更改文件模式。
#!/usr/bin/perl
print "Content-type:text/html\r\n\r\n";
print '<html>';
print '<head>';
print '<title>Hello Word - First CGI Program</title>';
print '</head>';
print '<body>';
print '<h2>Hello Word! This is my first CGI program</h2>';
print '</body>';
print '</html>';
123456789101112现在,如果单击 hello.cgi 链接,则请求转到在/ cgi-bin目录中搜索hello.cgi的Web服务器,执行它并生成任何结果,Web服务器将该结果发送回Web浏览器,如下所示 -
<h3>Hello Word! This is my first CGI program</h3>
12这个hello.cgi脚本是一个简单的Perl脚本,它将输出写在STDOUT文件即屏幕上。 有一个重要的额外功能,第一行打印 Content-type:text/html\r\n\r\n 。 该行被发送回浏览器并指定要在浏览器屏幕上显示的内容类型。 现在你必须掌握CGI的基本概念,你可以使用Perl编写许多复杂的CGI程序。 此脚本还可以与任何其他exertnal系统交互,以交换诸如数据库,Web服务或任何其他复杂接口之类的信息。
了解HTTP标头
第一行 Content-type:text/html\r\n\r\n 是HTTP标头的一部分,它被发送到浏览器,以便浏览器可以理解来自服务器端的传入内容。 所有HTTP标头将采用以下形式 -
HTTP Field Name: Field Content
12例如 -
<font color="Red">Content-type:</font><font color="blue">text/html\r\n\r\n</font>
12很少有其他重要的HTTP标头,您将在CGI编程中经常使用它们。
| Sr.No. | 标题和说明 |
|---|
CGI环境变量 (CGI Environment Variables)
所有CGI程序都可以访问以下环境变量。 在编写任何CGI程序时,这些变量都起着重要作用。
| Sr.No. | 变量名称和描述 |
|---|
这是一个小型CGI程序,用于列出Web服务器支持的所有CGI变量。 单击此链接可查看结果获取环境
#!/usr/bin/perl
print "Content-type: text/html\n\n";
print "<font size=+1>Environment</font>\n";
foreach (sort keys %ENV) {
print "<b>$_</b>: $ENV{$_}<br>\n";
12345678提出“文件下载”对话框?
有时,您希望在用户单击链接的位置提供选项,它会向用户弹出“文件下载”对话框,而不是显示实际内容。 这非常简单,将通过HTTP标头获得。
此HTTP标头将与上一节中提到的标头不同。 例如,如果您想从给定链接下载 FileName 文件,那么它的语法如下 -
#!/usr/bin/perl
# HTTP Header
print "Content-Type:application/octet-stream; name = \"FileName\"\r\n";
print "Content-Disposition: attachment; filename = \"FileName\"\r\n\n";