|
|
|


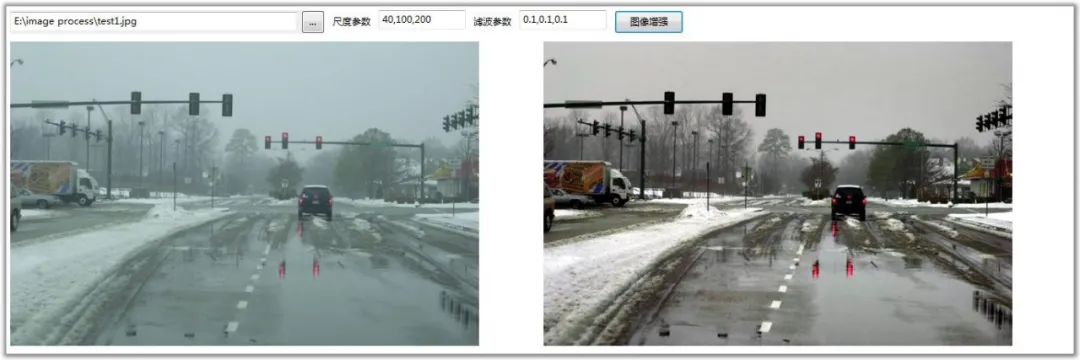
var layout = d3.layout.cloud() .size([500, 300]) .words(theme) // wordList.map(function(d) { // return {text: d, size: 10 + Math.random() * 50}; // }) .padding(5) .rotate(function() { return ~~(Math.random() * 1) * 90; }) .font("STXinwei") .fontSize(function(d) { return d.size; }) .on("end", draw); layout.start(); function draw(words) { d3.select(".wordcloud").html(""); //enter var mywords=d3.select(".wordcloud") .append("svg") .attr("width", layout.size()[0]) .attr("height", layout.size()[1]) .append("g") .attr("transform", "translate(" + layout.size()[0] / 2 + "," + layout.size()[1] / 2 + ")") .selectAll("text") .data(words) .enter() .append("text") .attr("class","word") .style("font-size", function(d) { return d.size + "px"; }) .style("font-family", "STXinwei") .style("fill", function(d, i) { fill(i); }) .attr("text-anchor", "middle") .attr("transform", function(d) { return "translate(" + [d.x, d.y] + ")rotate(" + d.rotate + ")"; }) .text(function(d) { // console.log(d.word); return d.word; })//这里要用d,而不是用i .on("mouseover",function(d,i){ d3.select(this) .transition() .duration(500) .attr("fill","gray"); d3.select(this) .select("text") .text(d.size) .attr("class",".poems"); // return d.size; }) .on("mouseout",function(d,i){ d3.select(this) .transition() .duration(1000) .attr("fill","black"); }) .on("click", function(d,i) { // console.log(i); // console.log(i.word); // console.log(d); showPoems(i.word); })//这里要用i,而不是用d .append("title") .text(function(d){ return "使用次数:"+d.size+"次"; }); 修改上述代码使得词云的显示集中在某个固定的多边形内,词与词之间越紧密越好
时间: 2024-03-07 16:47:31
浏览: 81
要实现词云的[显示](https://geek.csdn.net/educolumn/103ca72607c717122e068b9f06a24df6?spm=1055.2569.3001.10083)集中在某个固定的多边形内,可以通过以下[步骤](https://geek.csdn.net/educolumn/41e918968ef7840279c31b7f6a0950e3?spm=1055.2569.3001.10083)进行修改:
1.定义一个多边形的路径,并将其作为 [clip](https://geek.csdn.net/educolumn/0830e95abf03b0b8727f8e6fb0b6ac18?spm=1055.2569.3001.10083)Path 元素加入到 SVG 中。
2.在绘制词云之前,将 layout.words() 的值限制在多边形内部。可以通过以下方法实现:
- 遍历所有的词,将其位置限制在多边形内部。
- 在 layout.on("end", draw) 方法中,遍历所有的词,如果其位置在多边形外部,则将其移动到多边形内部。
3.在绘制词云时,将其位置限制在多边形内部。
下面是修改后的[代码](https://geek.csdn.net/educolumn/1572ef9b473b4e00f6b2bf6d428b7c27?spm=1055.2569.3001.10083):
// 定义多边形的路径
var polygon = [[100, 100], [400, 100], [400, 300], [100, 300]];
var polygonPath = "M" + polygon.join("L") + "Z";
// 将多边形加入到 SVG 中
d3.select("svg").append("[clip](https://geek.csdn.net/educolumn/0830e95abf03b0b8727f8e6fb0b6ac18?spm=1055.2569.3001.10083)Path")
.attr("id", "polygon")
.append("path")
.attr("d", polygonPath);
// 将 layout.words() 的值限制在多边形内部
layout.words(layout.words().filter(function(d) {
var x = d.x + layout.size()[0] / 2;
var y = d.y + layout.size()[1] / 2;
return d3.polygonContai
```
相关推荐
最新推荐
3-D声阵列测向:进化TDOA方法研究
"基于进化TDOA的3-D声阵列测向方法是研究论文,探讨了使用时间差-of-到达(TDOA)测量在三维声学传感器阵列中定位信号源的技术。文章提出两种进化计算方法,即遗传算法和粒子群优化算法,来解决方向查找问题,并考虑了声速的影响,该声速是根据观测到的天气参数和最小二乘(LS)估计算法提供的初步方向估计结果来估算的。"
本文主要关注的是利用TDOA在三维声学阵列中的信号源定向技术。在传统的TDOA测向中,信号到达不同传感器的时间差被用来确定信号源的位置。然而,这篇论文提出了一种创新的方法,通过结合进化计算技术,如遗传算法和粒子群优化算法,来更准确地解决这一问题。
首先,文章指出声音速度在定位过程中起着关键作用。考虑到环境因素,如温度、湿度和压力,这些都会影响声波在空气中的传播速度,论文中提出根据观察到的天气参数来估计声速。此外,初步的方向估计是通过最小二乘估计算法完成的,这是目前TDOA测向中的主流方法。LS估计算法能够提供初始的方向信息,帮助后续的进化算法更快地收敛。
其次,为了提高性能,文章采用了无参考的TDOA测量来定义成本函数。这种方法可以减少误差并提高定位精度。同时,为了确保算法的快速收敛,LS估计算法也被用作两种智能群算法(遗传算法和粒子群优化算法)的初始化方向估计。
仿真结果表明,采用完整TDOA集的提议方法在性能上优于传统的TDOA方法,特别是在处理复杂环境下的信号源定位问题时。这表明进化算法的引入可以显著提高三维声学阵列的定向能力,为实际应用提供了新的可能性,例如在海洋监测、环境噪声控制、无线通信等领域。
这篇研究论文为TDOA基的三维声学阵列测向提供了一种新的优化解决方案,结合了环境因素和智能优化算法,有望提升信号源定位的精度和效率。这对于进一步改进现有技术,尤其是在动态和多变环境中的应用具有重要意义。
管理建模和仿真的文件
管理Boualem Benatallah引用此版本:布阿利姆·贝纳塔拉。管理建模和仿真。约瑟夫-傅立叶大学-格勒诺布尔第一大学,1996年。法语。NNT:电话:00345357HAL ID:电话:00345357https://theses.hal.science/tel-003453572008年12月9日提交HAL是一个多学科的开放存取档案馆,用于存放和传播科学研究论文,无论它们是否被公开。论文可以来自法国或国外的教学和研究机构,也可以来自公共或私人研究中心。L’archive ouverte pluridisciplinaire
计算机视觉在工业领域的应用:缺陷检测与质量控制,提升生产效率
# 1. 计算机视觉技术概述**
计算机视觉是人工智能的一个分支,它赋予计算机“看”和“理解”图像和视频的能力。它涉及从图像和视频中提取、分析和解释有意义的信息。
计算机视觉技术广泛应用于各种领域,包括工业缺陷检测、质量控制、医疗诊断和自动驾驶。它使计算机能够执行诸如物体检测、图像分类、面部识别和运动跟踪等任务。
计算机视觉算法通常涉及以下步骤:图像采集、预处理、特征提取、分类和解释。图像采集涉及
postgresql性能为什么比mysql快
PostgreSQL 和 MySQL 都是非常流行的开源数据库系统,它们各有优缺点,性能差异取决于多种因素:
1. **存储引擎**: PostgreSQL 的默认存储引擎是归档日志模式,提供ACID(原子性、一致性、隔离性和持久性)事务处理能力,这使得它对复杂查询的支持更好,但可能会牺牲一些实时读写速度。而MySQL有不同的存储引擎,如InnoDB和MyISAM,InnoDB支持事务,但相比PostgreSQL,在简单插入和查询上可能更快。
2. **SQL语法和优化**: Postgres 的SQL语法更为严谨,支持更多的数据类型和更复杂的查询功能,但它也意味着更高的解析和执行开销。而
认知无线电MIMO广播信道的能效优化策略
“这篇研究论文探讨了认知无线电MIMO广播信道的能效优化问题,重点关注在单位能量消耗下的系统吞吐量提升。作者是Junling Mao、Gang Xie、Jinchun Gao和Yuanan Liu,他们都是IEEE的会员。”
在无线通信领域,认知无线电(CR)技术因其对频谱资源的有效利用而受到广泛关注。传统的认知无线电MIMO(Multiple-Input Multiple-Output)系统设计主要侧重于提高系统吞吐量,但随着环保意识的增强和能源效率(EE)成为关键考量因素,本研究论文旨在认知无线电MIMO广播信道(BC)中优化能源效率,同时确保单位能量消耗下的系统性能。
论文研究的问题是在总功率约束、干扰功率约束以及最小系统吞吐量约束下,如何优化认知无线电MIMO BC的能源效率。由于这是一个非凸优化问题,解决起来颇具挑战性。为了找到最优解,作者将原问题转换为一个等价的一维问题,其目标函数近似为凹函数,并采用黄金分割法进行求解。这种方法有助于在满足约束条件的同时,有效地平衡系统性能与能耗之间的关系。
黄金分割法是一种数值优化方法,它通过在区间内不断分割并比较函数值来逼近最优解,具有较高的精度和收敛性。在仿真结果中,论文展示了所提出的算法在实现能效优化方面的有效性。
关键词包括:能源效率、认知无线电、MIMO广播信道和功率分配。这篇论文的贡献在于为认知无线电系统提供了一种新的优化策略,即在保证服务质量的前提下,更有效地利用能源,这对未来绿色通信和可持续发展的无线网络设计具有重要意义。
"互动学习:行动中的多样性与论文攻读经历"
多样性她- 事实上SCI NCES你的时间表ECOLEDO C Tora SC和NCESPOUR l’Ingén学习互动,互动学习以行动为中心的强化学习学会互动,互动学习,以行动为中心的强化学习计算机科学博士论文于2021年9月28日在Villeneuve d'Asq公开支持马修·瑟林评审团主席法布里斯·勒菲弗尔阿维尼翁大学教授论文指导奥利维尔·皮耶昆谷歌研究教授:智囊团论文联合主任菲利普·普雷教授,大学。里尔/CRISTAL/因里亚报告员奥利维耶·西格德索邦大学报告员卢多维奇·德诺耶教授,Facebook /索邦大学审查员越南圣迈IMT Atlantic高级讲师邀请弗洛里安·斯特鲁布博士,Deepmind对于那些及时看到自己错误的人...3谢谢你首先,我要感谢我的两位博士生导师Olivier和Philippe。奥利维尔,"站在巨人的肩膀上"这句话对你来说完全有意义了。从科学上讲,你知道在这篇论文的(许多)错误中,你是我可以依
计算机视觉在医疗领域的应用:疾病诊断与影像分析,赋能精准医疗
# 1. 计算机视觉在医疗领域的概述**
计算机视觉是一种人工智能技术,它使计算机能够从图像和视频中“理解”世界。在医疗领域,计算机视觉正在为疾病诊断和影像分析带来革命性的变革,赋能精准医疗。
计算机视觉在医疗领域的应用主要集中在两大方面:疾病诊断和影像分析。在疾病诊断方面,计算机视觉算法可以分析医学图像,如X射线、
Playwright/test
Playwright/test是由GitHub上著名的开源库Playwright驱动的一个测试框架,它专为Web应用程序的端到端(e2e)测试设计。Playwright本身是一个跨平台的自动化浏览器控制库,支持Chrome、Firefox和WebKit,而Playwright/test则是将Playwright与JavaScript测试框架如Jest、Mocha或Cypress等集成,用于编写高性能的、可靠的自动化测试用例。
Playwright/test提供了一种直观的方式来编写测试,允许开发者模拟用户交互,比如填写表单、点击链接、滚动页面等,并且由于其底层是基于真实的浏览器环境,所以能得
高隐蔽性JPEG隐写分析:基于KFD指标的聚类方法
"基于KFD指标聚类的高隐蔽性JPEG隐写分析"
本文主要探讨了在隐写术分析领域中,如何针对非公开图像源或算法的隐写行为进行更有效的聚类分析,以提高隐写检测的准确性。在隐写者先验信息不足的情况下,聚类分析成为一种实用的策略。Ker等人曾提出使用最大平均距离(MMD)指标进行聚类的隐写者识别方法,但这种方法仅考虑样本中心之间的距离,忽视了样本相对于中心的聚合程度对分类性能的影响。
为了提升聚类分析的准确性,文章提出了基于核Fisher鉴别(KFD)指标的聚类方法。KFD指标是一种结合了类间方差和类内方差的差异度量工具,它能够同时考虑类间的分离度和类内的紧密度,从而提供更精确的样本间差异估计。具体实现步骤包括:首先,从JPEG图像中提取PEV274校准特征,并对其进行归一化处理;接着,利用KFD指标计算样本间的距离矩阵;最后,通过样本间差异度量矩阵,采用重心法自底向上进行层次聚类分析。
实验结果显示,采用KFD指标的聚类方法对于低嵌入率的隐写分析,准确率最高可以提升约30%,而对于高嵌入率的情况,准确率下降不超过5%。相较于现有方法,KFD指标的聚类方法在平均准确率上有显著提升。