


SQL高级功能窗口函数的应用

特别强调:
窗口函数目前MySQL 8.0版以上才支持该功能。
一 窗口函数
1 什么叫窗口函数?
窗口函数通常用于求组内排名, topN 问题。窗口函数是SQL的一个高级功能,也称为OLAP函数(Online Anallytical Processing,联机分析处理),意思是对数据库数据进行实时分析处理。
窗口函数就是为了实现OLAP而添加的标准SQL 功能 ,是类似于可以返回聚合值的函数(例如SUM(),COUNT(),MAX() ),但是窗口函数又与普通的聚合函数不同:
功能如下:
窗口函数同时具有分组和排序的功能;
且不减少原表的行数。
它可以进行排序,生成序列号等一般的聚合函数无法实现的高级操作。
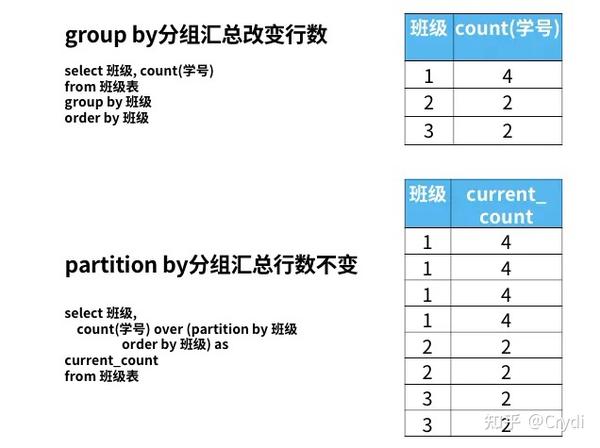
2 窗口函数具备了我们之前学过的group by子句分组的功能和order by子句排序的功能,那为什么还要用窗口函数呢?
这是因为,group by分组汇总后改变了表的行数,一行只有一个类别,而partiition by和rank函数不会减少原表中的行数。

3 窗口函数的基本语法:
-- 窗口函数的基本语法
SELECT
<窗口函数> OVER ([PARTITION BY <用于分组的列名>]
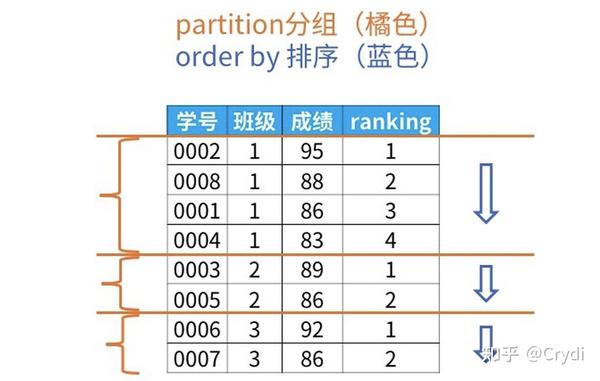
ORDER BY <用于排序的列名>)partition by:可将它看成group by子句,通过partition by分组后的记录集合成为“窗口”,表示“范围”的意思。
partition子句可省略,省略就是不指定分组。
order by:与普通查询语句中的order by没什么不同。
ORDER BY问题:将聚合函数作为窗口函数使用时,会议当前记录为基准来决定汇总对象的记录,因为OVER 子句中的 ORDER BY 只是用来决定窗口函数按照什么样的顺序进行计算的,对结果的排列顺序并没有影响。如果要使结果按照ranking升序排列,要在最后再加一个相同的ORDER BY语句。

窗口函数的位置,可以放以下两种函数:
1) 专用窗口函数,包括后面要讲到的rank, dense_rank, row_number等专用窗口函数;
2) 聚合函数,如sum. avg, count, max, min等。
注:因为窗口函数是对where或者group by子句处理后的结果进行操作,所以窗口函数原则上只能写在select子句中。
二 专用窗口函数
1 专用窗口函数rank
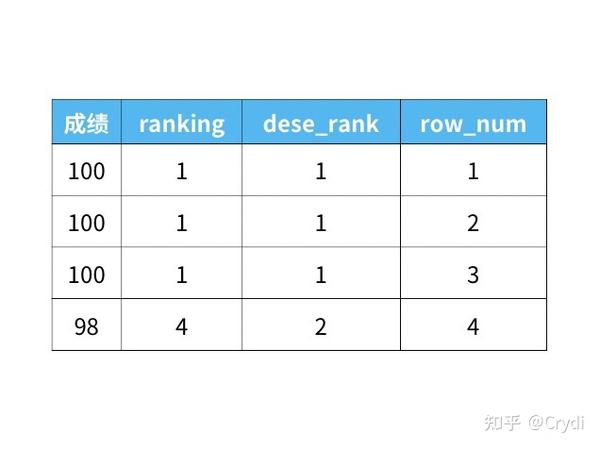
1)rank()
rank函数是跳跃排名,考虑到了over子句中排序字段值相同的情况,字段值相同的序号是一样的,会占用下一名次的位置,而后面字段值不相同的序号将跳过相同的排名号排下一个。
比如有 3 条记录排在第 1 位时:1 位、1 位、1 位、4 位……
2)dense_rank()
dense_rank函数同rank类似,相同字段排名序号相同,不占用下一名次的位置,后续字段值不同的序号承接上一个的序号,它是连续排名。
比如有 3 条记录排在第 1 位时:1 位、1 位、1 位、2 位……
3)row_number()
row_number函数作用就是将查询到的数据进行排序,不考虑并列名次的情况,每一条数据加一个序号。
比如有 3 条记录排在第 1 位时:1 位、2 位、3 位、4 位……

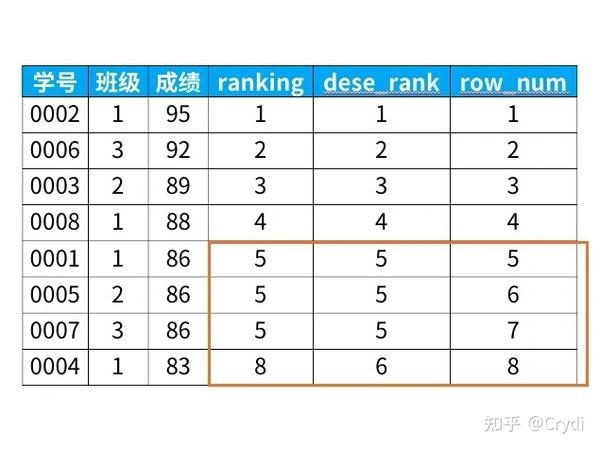
具体语法结果对比:
select *,
rank() over (order by 成绩 desc) as ranking,
dense_rank() over (order by 成绩 desc) as dese_rank,
row_number() over (order by 成绩 desc) as row_numfrom 班级表;注:由于专用窗口函数无需参数,因此通常括号中都是空的。

实战案例:
a 按课程号分组取成绩 最大值 所在行的数据
分析过程
1)利用group by和max函数求每个课程的最大值,但是无法获得最大成绩所在行的数据;
2) 用关联子查询查找每科的最大值。sql语句如下:
select *
from score as a
where 成绩 = (
select max(成绩)
from score as b
where b.课程号 = a.课程号);现有表格,记录了每个学生各科的成绩,内容如下:
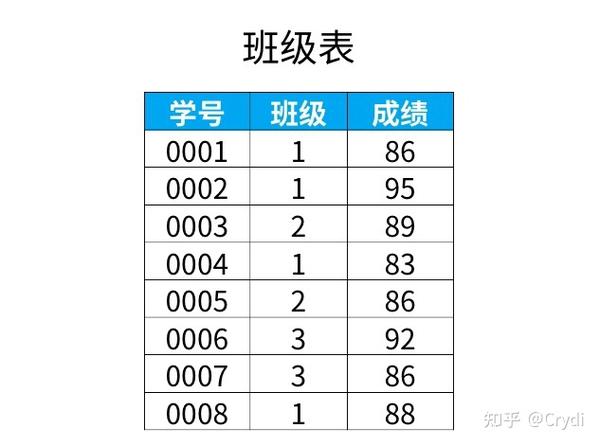

b 查找每个学生成绩最高的2个科目。
分析过程
第一步:“每个”同学需要分组,score中对学号分组,
如若需要学生姓名需要与student通过学号来连接(score中只有学号,课程号,成绩三个字段);
第二步:还需要对成绩进行降序排列,取前两位;
第三步:如果要分组和排序的功能,不减少原表的行数,要用窗口函数;
第四步:不受成绩并列影响,因此使用row_number专用窗口函数。此时可用子查询,把第一步得到查询结果作为一个新的表,sql语句如下:
select *
from (select *,
row_number() over (partition by 姓名 order by 成绩 desc) as ranking from 各科成绩表) as a
where ranking <= 2;运行如下:
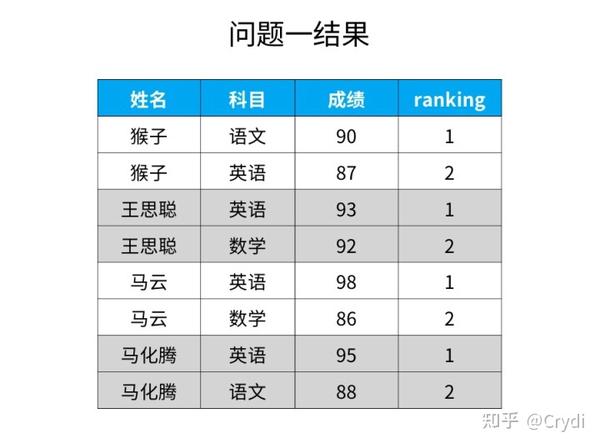

【举一反三】
经典topN问题:每组最大的N条记录。这类问题涉及到“既要分组,又要排序”的情况,要能想到用窗口函数来实现。
本题的sql语句修改下(将where字句里的条件修改成N),就可以成为这类问题的一个万能模板,遇到这类问题往里面套就可以了:
# topN问题 sql模板
select * from (select *,
row_number() over (partition by 要分组的列名 order by 要排序的列名 desc)
as ranking from 表名) as a where ranking ‹= N;三 聚合函数作为窗口函数
聚合函数作为窗口函数,用法和上面提到的专用窗口函数完全相同,只需要把聚合函数写在窗口函数的位置即可,但是函数后面括号里面不能为空,需要指定聚合的列名。例如:
SELECT*,
sum(成绩) over (ORDER BY 学号) AS current_sum,
avg(成绩) over (ORDER BY 学号) AS current_avg,
count(成绩) over (ORDER BY 学号) AS current_count,
max(成绩) over (ORDER BY 学号) AS current_max,
min(成绩) over (ORDER BY 学号) AS current_min
FROM 成绩表;运行如下:
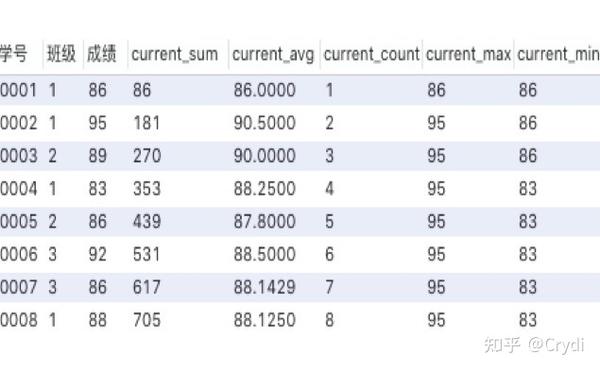

由上表可以看出,聚合函数作为窗口函数,其作用范围是从第一行到当前记录进行运算。
聚合函数作为窗口函数,可以在每一行的数据里直观的看到,截止到本行数据,统计数据是多少(最大值、最小值等)。同时可以看出每一行数据,对整体统计数据的影响。
下面我们来具体分析一下:
1 聚合函数sum作为窗口函数——窗口函数的累计求和。
例如:
select *,
sum(成绩) over
(order by 学号)
as current_sum
from 成绩表;聚合函数sum在窗口函数中,是对自身记录、及位于自身记录以上的数据进行求和的结果。比如0004号,在使用sum窗口函数后的结果,是对0001,0002,0003,0004号的成绩求和,若是0005号,则结果是0001号~0005号成绩的求和,以此类推。
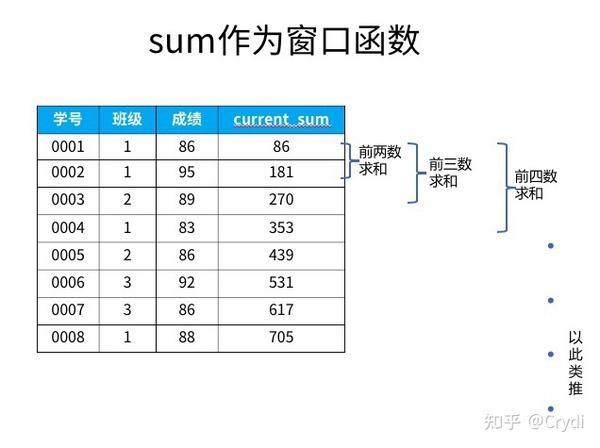

比如0005号后面的聚合窗口函数结果是:学号0001~0005五人成绩的总和、平均、计数及最大最小值。如果想要知道所有人成绩的总和、平均等聚合结果,看最后一行即可。
2 聚合函数avg作为窗口函数——窗口函数的移动平均。
例如:
select *,
avg(成绩) over
(order by 学号 rows 2 preceding) as current_avg
from 成绩表;
仔细看上面的窗口函数中,用了rows和preceding这两个关键字,是“之前~行”的意思,上面的句子中,是之前2行,也就是得到的结果是自身记录及前2行的平均。
例如:学号0004学生的current_avg,是自己和前2位同学的平均,即0002,0003,0004三位同学成绩的平均,其他数据的情况也一样,下图非常直观的可以看到计算过程:
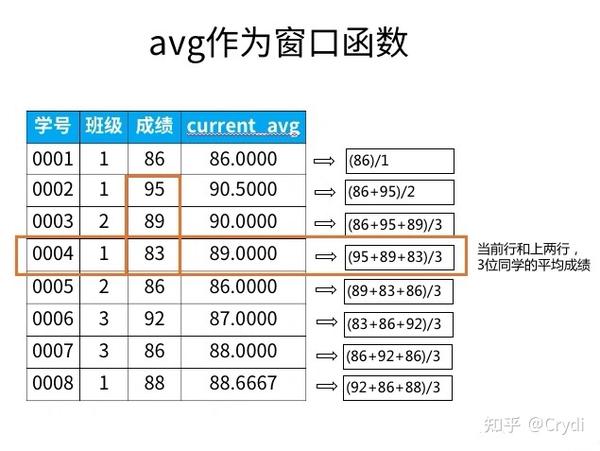

每一行得到的结果,都是当前行和前面2行的平均(共3行)。想要计算当前行与前n行(共n+1行)的平均时,只要调整rows…preceding中间的数字即可。
这里需要注意:在移动平均中,被选出的数据构成一个“框架”,例如,刚才例子中的0002、0003、0004行数据,就是一个“框架”。
由于这里可以通过preceding关键字调整作用范围,在以下场景中非常适用:
在公司业绩名单排名中,可以通过移动平均,直观地查看到与相邻名次业绩的平均、求和等统计数据。
注:
每一行得到的结果,都是当前行和前面2行的平均(共3行),想要计算当前行与前n行(共n+1行)的平均时,只要调整rows…preceding中间的数字即可。
使用关键字following替换preceding,就可以指定“截止到之后~行”作为框架了。
select *,
avg(成绩) over
(order by 学号 rows 2 following) as current_avg
from 成绩表;如果希望将当前记录的前后行作为汇总对象时,可以同时使用 PRECEDING(“之前”)和 FOLLOWING(“之后”)关键字来实现。
select *,
avg(成绩) over
(order by 学号 rows between 1 preceding and 1 following) as current_avg
from 成绩表;实战案例:
a 按照日期进行升序排列,查找日期、确诊人数以及对应的累计确诊人数。
select 日期,确诊人数,
sum(确诊人数) over (order by 日期) as 累计确诊人数
from 确诊人数表;

b 按照雇员编号升序排列,查找薪水的累计和(累计薪水)。
select 雇员编号,薪水,
sum(薪水) over (order by 雇员编号) as 累计薪水
from 薪水表
where 结束日期 = '9999-01-01';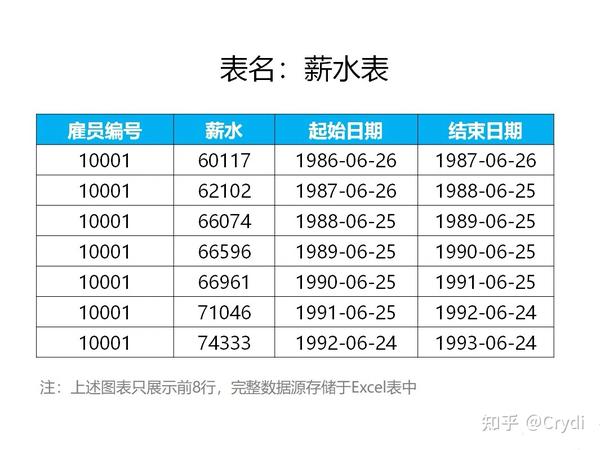

对于“累计”问题,要想到用聚合函数作为窗口函数
c 如何在每个组里比较?
即查找单科成绩高于该科目平均成绩的学生名单。
分析思路:
查找单科成绩高于该科目平均成绩,要在“每个”科目里比较,就要用到分组了。
能实现“分组”功能的sql有两种,一是group by字句,另一个是窗口函数的partition by
使用聚合窗口函数(求平均值avg),前求出每门课的平均成绩,然后找出大于比平均成绩的数据。
要求分组后不能减少表的行数。
select *
from (
select *,
avg(成绩) over (partition by 科目) as avg_score
from 各科成绩表
) as b
where 成绩 > avg_score;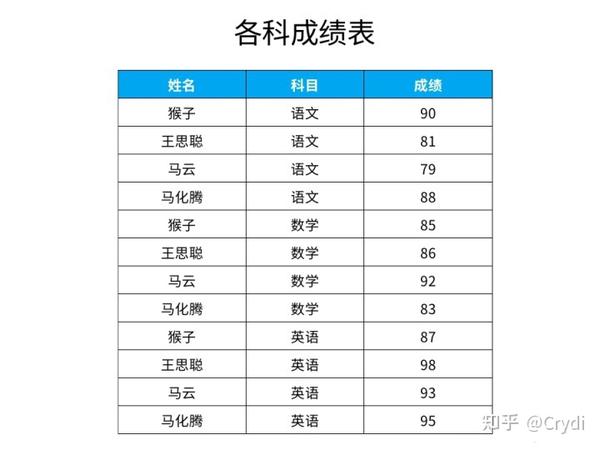

聚合函数与order by联用 :查询出逐行累计数值
聚合函数与partition by 联用 :查询出组内相同累计数值
四 存储过程
在工作里会经常遇到重复性的工作,这时候就可以把常用的SQL写好存储起来,这就是存储过程。这样下次遇到同样的问题,直接使用存储过程就可以了,就不需要再重新写一遍SQL了,这就极大的提高了工作效率。
如何使用存储过程?
使用存储过程需要:1)先定义存储过程 2)使用已经定义好的存储过程。
(1)无参数的存储过程
定义存储过程的语法形式:
create procedure 存储过程名称() begin ‹sql语句› ; end;
语法里的begin...end用于表示sql语句的开始和结束。语法里面的‹sql语句›就是重复使用的sql语句。下面通过一个例子看下如何使用。例如查出“学生表”里的学生姓名。
sql语句是:
select 姓名 from 学生表;
把这个sql语句放入存储过程的语法里,并给这个存储过程起个名字叫做就a_stuent1:
-- 先将分隔符;设置为 //, 直到遇到下一个//, 才整体执行语句。
DELIMITER //
create procedure a_stuent1()
begin
select 姓名 from 学生表;
//上面就是,先将分隔符设置为 //, 即输入DELIMITER //
直到遇到下一个 //,才整体执行语句。
如果MySql版本同一会话可连续执行语句,
执行完本语句后,在本语句最后一行输入 delimiter ; 将mysql的分隔符重新设置为分号;
如果不修改的话,本次会话中的所有分隔符都以// 为准。
其中Begin和End之间的部分,称为存储过程的主体,
因个人使用版本问题,必须加 delimiter // ...... // 才能执行成功,
据了解,正常版本的,不需要输入这些,具体情况具体对待吧~
在navicat里运行以后,建立的存储过程就会出现在左边数据库表格中的f()函数里。
下次使用存储过程的用下面sql语句就可以,就不需要重新写一遍sql了。
call 存储过程名称();
call a_stuent1();
(2)有参数的存储过程
前面的存储过程名称后面是(),括号里面没有参数。当括号里面有参数时,就是下面的语法:
-- 先将分隔符;设置为 //, 直到遇到下一个//, 才整体执行语句。
DELIMITER //
create procedure 存储过程名称(参数1,参数2,...)
begin
‹sql语句›;
//
通过一个案例看下,现在要在“学生表”里查找出指定学号的学生姓名。如果指定学号是0001,那么sql语句是:
select 姓名 from 学生表 where 学号='0001';
现在问题来了,一开始不知道指定学号是哪一个,只有使用的时候才知道业务需求。比如今天要查找学号0001,明天要查找学号002。这时候就需要用到参数,来灵活应对这种情况。把sql语句放入存储过程语法里就是:
-- 先将分隔符;设置为 // ,直到遇到下一个// ,才整体执行语句。
DELIMITER //
create procedure getNum(num varchar(100))
begin
select 姓名 from 学生表 where 学号=num;
//
其中
getNum
是存储过程的名称,后面括号里面的
num varchar(100)
是参数,参数由2部分组成:参数名称是num;参数类型是是varchar(100),这里表示是字符串类型。
存储过程里面的sql语句(where 学号=num)使用了这个参数num。这样在使用存储过程的时候,给定参数的值就可以灵活的按业务需求来查询了。
比如现在要查询学号=0001的学生姓名,那么就在使用存储过程的参数中给出学号的值,也就是下面括号里的0001:
call getNum('0001');
(3)默认参数的存储过程
前面的存储过程名称后面是(参数1,参数2),括号里面只包含参数的类型和名字,方便调用。存储过程还一种情况是有默认参数,是下面的语法。
in 输入参数:
参数初始值在存储过程前被指定为
默认值
,在存储过程中修改该参数的值
不能被返回
。
-- 先将分隔符;设置为 // ,直到遇到下一个// ,才整体执行语句。
DELIMITER //
-- in输入参数
set @num=0; -- 初始化参数
-- 初始化存储过程
create procedure in1(in num int)
begin
select num; -- 0
set num = 1;
select num; -- 1
end;//
-- in参数调用
call in1(@num);
select num; -- 返回0

out输出参数: 参数初始值为 空 ,该值可在存储过程内部被改变,并 可返回 。
-- 先将分隔符;设置为 // ,直到遇到下一个// ,才整体执行语句。
DELIMITER //
-- out输出参数
set @num=0; -- 初始化参数
-- 初始化存储过程
create procedure out2(out num int)
begin
select num; -- null
set num =1;
select num; -- 1
end;//
-- out参数调用
call out2(@num);
select num; -- 返回1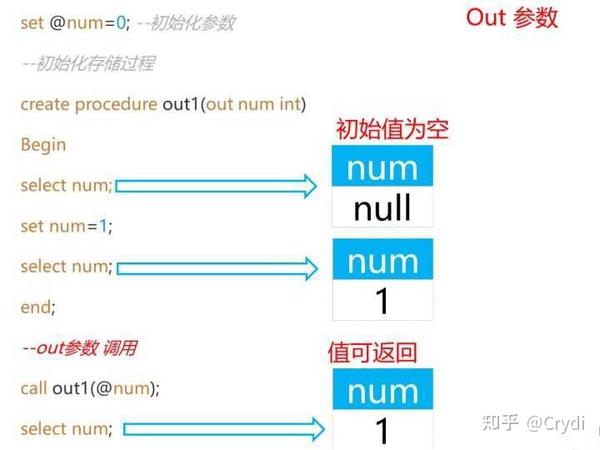

inout输入输出参数: 参数初始值在存储过程前被指定为 默认值 ,并且可在存储过程中被改变和在调用完毕后 可被返回。
-- 先将分隔符;设置为 // ,直到遇到下一个// ,才整体执行语句。
DELIMITER //
-- inout输入输出参数
set @num = 0;-- 初始化参数
-- 初始化存储过程
create procedure inout1(inout num int)
begin
select num;-- 0
set num = 1;