


MyBatis 源码解析:映射文件的加载与解析(下)

- Jdbc3KeyGenerator
首先来看 Jdbc3KeyGenerator 实现类,这是一个用于获取数据库自增主键值的实现版本。Jdbc3KeyGenerator 的
Jdbc3KeyGenerator#processBefore
方法是一个空实现,主要实现逻辑位于
Jdbc3KeyGenerator#processAfter
方法中:
public void processAfter(Executor executor, MappedStatement ms, Statement stmt, Object parameter) {
this.processBatch(ms, stmt, parameter);
public void processBatch(MappedStatement ms, Statement stmt, Object parameter) {
// 获取 keyProperty 属性配置,用于指定生成结果所映射的目标属性,可能存在多个
final String[] keyProperties = ms.getKeyProperties();
if (keyProperties == null || keyProperties.length == 0) {
return;
// 调用 Statement#getGeneratedKeys 方法获取数据库自动生成的主键
try (ResultSet rs = stmt.getGeneratedKeys()) {
// 获取 ResultSet 元数据信息
final ResultSetMetaData rsmd = rs.getMetaData();
final Configuration configuration = ms.getConfiguration();
if (rsmd.getColumnCount() < keyProperties.length) {
// Error?
} else {
// 使用主键值填充 parameter 目标属性
this.assignKeys(configuration, rs, rsmd, keyProperties, parameter);
} catch (Exception e) {
throw new ExecutorException("Error getting generated key or setting result to parameter object. Cause: " + e, e);
private void assignKeys(Configuration configuration,
ResultSet rs,
ResultSetMetaData rsmd,
String[] keyProperties,
Object parameter) throws SQLException {
if (parameter instanceof ParamMap || parameter instanceof StrictMap) {
// Multi-param or single param with @Param
this.assignKeysToParamMap(configuration, rs, rsmd, keyProperties, (Map<String, ?>) parameter);
} else if (parameter instanceof ArrayList
&& !((ArrayList<?>) parameter).isEmpty()
&& ((ArrayList<?>) parameter).get(0) instanceof ParamMap) {
// Multi-param or single param with @Param in batch operation
this.assignKeysToParamMapList(configuration, rs, rsmd, keyProperties, (ArrayList<ParamMap<?>>) parameter);
} else {
// Single param without @Param
this.assignKeysToParam(configuration, rs, rsmd, keyProperties, parameter);
}上述实现的主要逻辑就是获取数据库自增的主键值,并设置到用户传递实参(parameter)的相应属性中。用户指定的实参可以是一个具体的实体类对象、Map 对象,以及集合类型,上述方法会依据入参类型分而治之。以 t_user 这张数据表为例,假设有如下插入语句:
<insert id="insert" parameterType="org.zhenchao.mybatis.entity.User" useGeneratedKeys="true" keyProperty="id">
insert into t_user (username, password, age, phone, email)
values (#{username,jdbcType=VARCHAR}, #{password,jdbcType=VARCHAR},
#{age,jdbcType=INTEGER}, #{phone,jdbcType=VARCHAR}, #{email,jdbcType=VARCHAR})
</insert>
那么 MyBatis 在执行插入时会先获取到数据库的自增 ID 值,并填充到 User 对象中。这里最终会调用
Jdbc3KeyGenerator#assignKeysToParam
方法填充目标属性值,实现如下:
private void assignKeysToParam(Configuration configuration,
ResultSet rs,
ResultSetMetaData rsmd,
String[] keyProperties,
Object parameter) throws SQLException {
// 将 Object 类型参数转换成相应的集合类型
Collection<?> params = collectionize(parameter);
if (params.isEmpty()) {
return;
// 遍历为每个目标属性配置创建对应的 KeyAssigner 分配器
List<KeyAssigner> assignerList = new ArrayList<>();
for (int i = 0; i < keyProperties.length; i++) {
assignerList.add(new KeyAssigner(configuration, rsmd, i + 1, null, keyProperties[i]));
// 遍历填充目标属性
Iterator<?> iterator = params.iterator();
while (rs.next()) {
if (!iterator.hasNext()) {
throw new ExecutorException(String.format(MSG_TOO_MANY_KEYS, params.size()));
Object param = iterator.next();
// 基于 KeyAssigner 使用自增 ID 填充目标属性
assignerList.forEach(x -> x.assign(rs, param));
// org.apache.ibatis.executor.keygen.Jdbc3KeyGenerator.KeyAssigner#assign
protected void assign(ResultSet rs, Object param) {
if (paramName != null) {
// If paramName is set, param is ParamMap
param = ((ParamMap<?>) param).get(paramName);
// 创建实参对应的 MetaObject 对象,以实现对于实参对象的反射操作
MetaObject metaParam = configuration.newMetaObject(param);
try {
if (typeHandler == null) {
// 创建目标属性对应的类型处理器
if (metaParam.hasSetter(propertyName)) {
Class<?> propertyType = metaParam.getSetterType(propertyName);
typeHandler = typeHandlerRegistry.getTypeHandler(
propertyType, JdbcType.forCode(rsmd.getColumnType(columnPosition)));
} else {
throw new ExecutorException("No setter found for the keyProperty '"
+ propertyName + "' in '" + metaParam.getOriginalObject().getClass().getName() + "'.");
if (typeHandler == null) {
// Error?
} else {
// 设置目标属性值
Object value = typeHandler.getResult(rs, columnPosition);
metaParam.setValue(propertyName, value);
} catch (SQLException e) {
throw new ExecutorException("Error getting generated key or setting result to parameter object. Cause: " + e,
}如果对上述实现不能很好的理解,建议 debug 一下,能够豁然开朗。
- SelectKeyGenerator
SelectKeyGenerator 主要适用于那些不支持自动生成自增主键的数据库类型,从而为这些数据库生成主键值。SelectKeyGenerator 实现了 keyGenerator 接口中定义的全部方法,但是这些方法本质上均将请求直接委托给
SelectKeyGenerator#processGeneratedKeys
方法处理,实现如下:
private void processGeneratedKeys(Executor executor, MappedStatement ms, Object parameter) {
try {
if (parameter != null && keyStatement != null && keyStatement.getKeyProperties() != null) {
// 获取 keyProperty 属性配置,用于指定生成结果所映射的目标属性,可能存在多个
String[] keyProperties = keyStatement.getKeyProperties();
final Configuration configuration = ms.getConfiguration();
// 创建实参 parameter 对应的 MetaObject 对象,便于反射操作
final MetaObject metaParam = configuration.newMetaObject(parameter);
// 创建 SQL 执行器,并执行 <selectKey/> 中定义的 SQL 语句
Executor keyExecutor = configuration.newExecutor(executor.getTransaction(), ExecutorType.SIMPLE);
List<Object> values = keyExecutor.query(
keyStatement, parameter, RowBounds.DEFAULT, Executor.NO_RESULT_HANDLER);
/* 处理 <selectKey/> 的返回值,填充目标属性 */
if (values.size() == 0) {
throw new ExecutorException("SelectKey returned no data.");
} else if (values.size() > 1) {
throw new ExecutorException("SelectKey returned more than one value.");
} else {
// 创建主键值对应的 MetaObject 对象
MetaObject metaResult = configuration.newMetaObject(values.get(0));
// 单列主键的情况
if (keyProperties.length == 1) {
if (metaResult.hasGetter(keyProperties[0])) {
this.setValue(metaParam, keyProperties[0], metaResult.getValue(keyProperties[0]));
// 没有 getter 方法,尝试直接获取属性值
else {
// no getter for the property - maybe just a single value object, so try that
this.setValue(metaParam, keyProperties[0], values.get(0));
// 多列主键的情况,依次从主键对象中获取对应的属性记录到用户参数对象中
else {
this.handleMultipleProperties(keyProperties, metaParam, metaResult);
} catch (ExecutorException e) {
throw e;
} catch (Exception e) {
throw new ExecutorException("Error selecting key or setting result to parameter object. Cause: " + e, e);
}
SelectKeyGenerator 会执行
<selectKey/>
中定义的 SQL 语句,拿到具体的返回值依据 keyProperty 配置填充目标属性。
封装 SQL 语句
上面的分析中曾遇到 SqlNode 和 SqlSource 这两个接口,本小节将对这两个接口及其实现类做一个分析。在这之前我们需要简单了解一下这两个接口各自的作用,由前面的分析我们知道对于一个 SQL 语句标签而言,最后会被封装成为一个 MappedStatement 对象,而标签中定义的 SQL 语句则由 SqlSource 进行表示,SqlNode 则用来定义动态 SQL 节点和文本节点等。
SqlNode
由点及面,我们先来看一下 SqlNode 的相关实现。SqlNode 是一个接口,其中仅声明了一个
SqlNode#apply
方法,接口定义如下:
public interface SqlNode {
/** 基于传递的实参,解析动态 SQL 节点 */
boolean apply(DynamicContext context);
}围绕该接口的实现类的 UML 图如下:
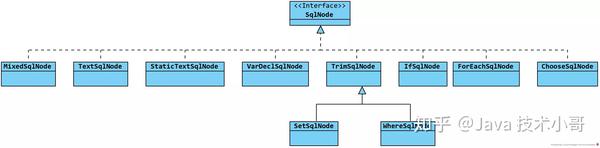

下面逐一对 SqlNode 的实现类进行分析。
- MixedSqlNode
首先来看一下前面多次遇到的 MixedSqlNode,它通过一个
MixedSqlNode#contents
集合属性记录包含的 SqlNode 对象,其
MixedSqlNode#apply
方法会遍历该集合并应用记录的各个 SqlNode 对象的
SqlNode#apply
方法,实现比较简单。
- StaticTextSqlNode
与 MixedSqlNode 实现类似的还包括 StaticTextSqlNode 类。该类采用一个 String 类型的
StaticTextSqlNode#text
属性记录非动态的 SQL 节点,其
StaticTextSqlNode#apply
方法直接调用
DynamicContext#appendSql
方法将记录的 SQL 节点添加到一个 StringBuilder 类型属性中。该属性用于记录 SQL 语句片段,当我们最后调用
DynamicContext#getSql
方法时会调用该属性的 toString 方法拼接记录的 SQL 片段,返回最终完整的 SQL 语句。
- TextSqlNode
TextSqlNode 用于封装包含占位符
${}
的动态 SQL 节点,前面在分析 SQL 语句标签时也曾遇到。该实现类的
TextSqlNode#apply
方法定义如下:
public boolean apply(DynamicContext context) {
// BindingTokenParser 是内部类,基于 DynamicContext#bindings 中的属性解析 SQL 语句中的占位符
GenericTokenParser parser = this.createParser(new BindingTokenParser(context, injectionFilter));
// 解析并记录 SQL 片段到 DynamicContext 中
context.appendSql(parser.parse(text));
return true;
}
GenericTokenParser 的执行逻辑我们之前遇到过多次,它主要用来查找指定标识的占位符(这里的占位符是
${}
),并基于指定的 TokenHandler 对解析到的占位符变量进行处理。TextSqlNode 内部实现了 TokenHandler 解析器(即 BindingTokenParser),该解析器基于
DynamicContext#bindings
属性中记录的参数值解析 SQL 语句中的占位符,并将解析结果记录到 DynamicContext 对象中。
- VarDeclSqlNode
VarDeclSqlNode 对应动态 SQL 中的
<bind/>
标签,该标签可以从 OGNL 表达式中创建一个变量并将其绑定到上下文中,官方文档中关于该标签的使用示例如下:
<select id="selectBlogsLike" resultType="Blog">
<bind name="pattern" value="'%' + _parameter.getTitle() + '%'" />
SELECT * FROM BLOG WHERE title LIKE #{pattern}
</select>
VarDeclSqlNode 定义了
VarDeclSqlNode#name
和
VarDeclSqlNode#expression
两个属性,分别与
<bind/>
标签的属性对应。该实现类的
VarDeclSqlNode#apply
方法完成了对 OGNL 表达式的解析,并将解析得到的真实值记录到
DynamicContext#bindings
属性中:
public boolean apply(DynamicContext context) {
// 解析 OGNL 表达式对应的值
final Object value = OgnlCache.getValue(expression, context.getBindings());
// 绑定到上下文中,name 对应属性 <bind/> 标签的 name 属性配置
context.bind(name, value);
return true;
}- IfSqlNode
IfSqlNode 对应动态 SQL 的
<if/>
标签,这也是我们频繁使用的条件标签。IfSqlNode 的属性定义如下:
/** 用于解析 <if/> 标签的 test 表达式 */
private final ExpressionEvaluator evaluator;
/** 记录 <if/> 标签中的 test 表达式 */
private final String test;
/** 记录 <if/> 标签的子标签 */
private final SqlNode contents;
相应的
IfSqlNode#apply
实现会首先调用
ExpressionEvaluator#evaluateBoolean
方法判定
IfSqlNode#test
属性记录的表达式是否为 true,如果为 true 则应用记录的子标签的
SqlNode#apply
方法:
public boolean apply(DynamicContext context) {
// 检测 test 表达式是否为 true
if (evaluator.evaluateBoolean(test, context.getBindings())) {
// 执行子标签的 apply 方法
contents.apply(context);
return true;
return false;
// org.apache.ibatis.scripting.xmltags.ExpressionEvaluator#evaluateBoolean
public boolean evaluateBoolean(String expression, Object parameterObject) {
// 获取 OGNL 表达式对应的值
Object value = OgnlCache.getValue(expression, parameterObject);
// 转换为 boolean 类型返回
if (value instanceof Boolean) {
return (Boolean) value;
if (value instanceof Number) {
return new BigDecimal(String.valueOf(value)).compareTo(BigDecimal.ZERO) != 0;
return value != null;
}- ChooseSqlNode
ChooseSqlNode 对应动态 SQL 中的
<choose/>
标签,我们通常利用此标签配合
<when/>
和
<otherwise/>
标签实现 switch 功能,具体使用方式可以参考官方示例。实现层面,MyBatis 并没有定义 WhenSqlNode 和 OtherwiseSqlNode 类与另外两个标签相对应,而是采用 IfSqlNode 表示
<when/>
标签,采用 MixedSqlNode 表示
<otherwise/>
标签。ChooseSqlNode 类的属性和
ChooseSqlNode#apply
方法定义如下:
/** 对应 <otherwise/> 标签,采用 {@link MixedSqlNode} 表示 */
private final SqlNode defaultSqlNode;
/** 对应 <when/> 标签,采用 {@link IfSqlNode} 表示 */
private final List<SqlNode> ifSqlNodes;
public boolean apply(DynamicContext context) {
// 遍历应用 <when/> 标签,一旦成功一个就返回
for (SqlNode sqlNode : ifSqlNodes) {
if (sqlNode.apply(context)) {
return true;
// 所有的 <when/> 都不满足,执行 <otherwise/> 标签
if (defaultSqlNode != null) {
defaultSqlNode.apply(context);
return true;
return false;
}- TrimSqlNode
TrimSqlNode 对应
<trim/>
标签,用于处理动态 SQL 拼接在一些条件下出现不完整 SQL 的情况,具体使用可以参考官方示例。该实现类的属性和
TrimSqlNode#apply
方法定义如下:
/** 记录 <trim/> 标签的子标签 */
private final SqlNode contents;
/** 期望追加的前缀字符串 */
private final String prefix;
/** 期望追加的后缀字符串 */
private final String suffix;
/** 如果 <trim/> 包裹的 SQL 语句为空,则删除指定前缀 */
private final List<String> prefixesToOverride;
/** 如果 <trim/> 包裹的 SQL 语句为空,则删除指定后缀 */
private final List<String> suffixesToOverride;
public boolean apply(DynamicContext context) {
// 创建 FilteredDynamicContext 对象,封装上下文
FilteredDynamicContext filteredDynamicContext = new FilteredDynamicContext(context);
// 应用子标签的 apply 方法
boolean result = contents.apply(filteredDynamicContext);
// 处理前缀和后缀
filteredDynamicContext.applyAll();
return result;
}
TrimSqlNode 中定义了内部类 FilteredDynamicContext,它是对上下文对象 DynamicContext 的封装,其
FilteredDynamicContext#applyAll
方法实现了对不完整 SQL 的处理。该方法调用
FilteredDynamicContext#applyPrefix
和
FilteredDynamicContext#applySuffix
方法分别处理 SQL 的前缀和后缀,并将处理完后的 SQL 片段记录到上下文对象中:
public void applyAll() {
sqlBuffer = new StringBuilder(sqlBuffer.toString().trim());
// 全部转换成大写
String trimmedUppercaseSql = sqlBuffer.toString().toUpperCase(Locale.ENGLISH);
if (trimmedUppercaseSql.length() > 0) {
// 处理前缀
this.applyPrefix(sqlBuffer, trimmedUppercaseSql);
// 处理后缀
this.applySuffix(sqlBuffer, trimmedUppercaseSql);
// 添加解析后的结果到 delegate 中
delegate.appendSql(sqlBuffer.toString());
}
方法
FilteredDynamicContext#applyPrefix
和
FilteredDynamicContext#applySuffix
的实现思路相同,这里以
FilteredDynamicContext#applyPrefix
方法为例进行说明。该方法会遍历指定的前缀并判断当前 SQL 片段是否以包含的前缀开头,是的话则会删除该前缀,如果指定了 prefix 属性则会在 SQL 语句片段前面追加对应的前缀值。WhereSqlNode 和 SetSqlNode 均由 TrimSqlNode 派生而来,实现比较简单,不多作撰述。
- ForEachSqlNode
最后再来看一下 ForEachSqlNode 类,该类对应
<foreach/>
标签,前面我们曾介绍了相关的 ForEachHandler 类实现。ForEachSqlNode 类是所有 SqlNode 实现类中最复杂的一个,其主要的属性定义如下(建议参考官方文档进行理解):
/** 标识符 */
public static final String ITEM_PREFIX = "__frch_";
/** 用于判断循环的终止条件 */
private final ExpressionEvaluator evaluator;
/** 迭代的集合表达式 */
private final String collectionExpression;
/** 记录子标签 */
private final SqlNode contents;
/** open 标识 */
private final String open;
/** close 标识 */
private final String close;
/** 循环过程中,各项之间的分隔符 */
private final String separator;
/** index 是迭代的次数,item 是当前迭代的元素 */
private final String item;
private final String index;ForEachSqlNode 中定义了两个内部类:FilteredDynamicContext 和 PrefixedContext。
FilteredDynamicContext
由 DynamicContext 派生而来,其中稍复杂的实现是
FilteredDynamicContext#appendSql
方法:
public void appendSql(String sql) {
GenericTokenParser parser = new GenericTokenParser("#{", "}", content -> {
// 替换 item 为 __frch_item_index
String newContent = content.replaceFirst("^\\s*" + item + "(?![^.,:\\s])", itemizeItem(item, index));
// 替换 itemIndex 为 __frch_itemIndex_index
if (itemIndex != null && newContent.equals(content)) {
newContent = content.replaceFirst("^\\s*" + itemIndex + "(?![^.,:\\s])", itemizeItem(itemIndex, index));
// 追加 #{} 标识
return "#{" + newContent + "}";
delegate.appendSql(parser.parse(sql));
}
实际上这里还是之前多次碰到的 GenericTokenParser 解析占位符的套路(这里的占位符是
#{}
),对应的
TokenHandler#handleToken
方法会将 item 替换成
__frch_item_index
的形式,拼接的过程由
ForEachSqlNode#itemizeItem
方法实现:
private static String itemizeItem(String item, int i) {
// 返回 __frch_item_i 的形式
return new StringBuilder(ITEM_PREFIX).append(item).append("_").append(i).toString();
}PrefixedContext 也派生自 DynamicContext 类,在遍历集合拼接时主要用于封装一个由指定前缀和集合元素组成的基本元组,具体实现比较简单。
回到 ForEachSqlNode 类本身,继续来看
ForEachSqlNode#apply
方法实现:
public boolean apply(DynamicContext context) {
Map<String, Object> bindings = context.getBindings();
// 解析集合 OGNL 表达式对应的值,返回值对应的迭代器
final Iterable<?> iterable = evaluator.evaluateIterable(collectionExpression, bindings);
if (!iterable.iterator().hasNext()) {
return true;
boolean first = true;
// 添加 open 前缀标识
this.applyOpen(context);
int i = 0;
// 迭代处理集合
for (Object o : iterable) {
// 备份一下上下文对象
DynamicContext oldContext = context;
// 第一次遍历,或未指定分隔符
if (first || separator == null) {
context = new PrefixedContext(context, "");
// 其它情况
else {
context = new PrefixedContext(context, separator);
int uniqueNumber = context.getUniqueNumber();
// 如果是 Map 类型,将 key 和 value 记录到 DynamicContext#bindings 属性中
if (o instanceof Map.Entry) {
@SuppressWarnings("unchecked")
Map.Entry<Object, Object> mapEntry = (Map.Entry<Object, Object>) o;
this.applyIndex(context, mapEntry.getKey(), uniqueNumber);
this.applyItem(context, mapEntry.getValue(), uniqueNumber);
// 将当前索引值和元素记录到 DynamicContext#bindings 属性中
else {
this.applyIndex(context, i, uniqueNumber);
this.applyItem(context, o, uniqueNumber);
// 应用子标签的 apply 方法
contents.apply(new FilteredDynamicContext(configuration, context, index, item, uniqueNumber));
if (first) {
first = !((PrefixedContext) context).isPrefixApplied();
// 恢复上下文对象
context = oldContext;
// 添加 close 后缀标识
this.applyClose(context);
context.getBindings().remove(item);
context.getBindings().remove(index);
return true;
}上述方法的执行过程阅读起来没什么压力,但就是不知道具体在做什么事情。下面我们以批量查询用户信息表 t_user 中的多个用户信息为例来走一遍上述方法的执行过程,对应的动态查询语句定义如下:
<select id="selectByIds" parameterType="java.util.List" resultMap="BaseResultMap">
SELECT * FROM t_user WHERE id IN
<foreach collection="ids" index="idx" item="itm" open="(" close=")" separator=",">
#{itm}
</foreach>
</select>假设我们现在希望查询 id 为 1 和 2 的两个用户,执行流程可以表述如下:
- 解析获取到集合表达式对应的集合迭代器对象,这里对应的是一个 List 类型集合的迭代器,其中包含了 1 和 2 两个元素;
-
调用
ForEachSqlNode#applyOpen方法添加 OPEN 标识符,这里即(; - 进入 for 循环,因为是第一次遍历,所以会创建 prefix 参数为空字符串的 PrefixedContext 对象;
-
这里集合类型中封装的是 Long 类型(不是 Map 类型):
①调用ForEachSqlNode#applyIndex方法,记录键值对(idx, 0)和(__frch_idx_0, 0)到DynamicContext#bindings属性中
②调用ForEachSqlNode#applyItem方法,记录键值对(itm, 1)和(__frch_itm_0, 1)到DynamicContext#bindings中;
-
应用子标签的
SqlNode#apply方法,这里会触发FilteredDynamicContext#appendSql方法解析占位符#{itm}为#{__frch_itm_0},此时生成的 SQL 语句片段已然成为SELECT * FROM t_user WHERE id IN ( #{__frch_itm_0}; -
进入 for 循环的第二次遍历,此时 first 变量已经置为 false,且这里设置了分隔符,所以执行
new PrefixedContext(context, separator)创建上下文对象; -
这里集合类型同样是 Long 类型(不是 Map 类型):
①调用ForEachSqlNode#applyIndex方法,记录键值对(idx, 1)和(__frch_idx_1, 1)到DynamicContext#bindings属性中;
②调用ForEachSqlNode#applyItem方法,记录键值对(itm, 2)和(__frch_itm_1, 2)到DynamicContext#bindings属性中;
-
应用子标签的
SqlNode#apply方法,这里会触发FilteredDynamicContext#appendSql方法解析占位符#{itm}为#{__frch_itm_1},此时生成的 SQL 语句片段已然成为SELECT * FROM t_user WHERE id IN ( #{__frch_itm_0}, #{__frch_itm_1} -
for 循环结束,调用
ForEachSqlNode#applyClose追加 CLOSE 标识符,这里即)。
最后解析得到的 SQL 为SELECT * FROM t_user WHERE id IN ( #{__frch_itm_0} , #{__frch_itm_1} )。希望通过这样一个过程辅助读者进行理解,如果还是云里雾里可以 debug 一下整个过程。
SqlSource
前面介绍了 SqlSource 用于表示映射文件或注解定义的 SQL 语句标签中的 SQL 语句,但是这里的 SQL 语句并不是可执行的,其中可能包含一些动态占位符。SqlSource 接口的定义如下:
public interface SqlSource {
* 基于传入的参数返回可执行的 SQL 语句
* @param parameterObject 用户传递的实参
* @return
BoundSql getBoundSql(Object parameterObject);
}围绕该接口的实现类的 UML 图如下:


其中,RawSqlSource 用于封装静态定义的 SQL 语句;DynamicSqlSource 用于封装动态定义的 SQL 语句;ProviderSqlSource 则用于封装注解形式定义的 SQL 语句。不管是动态还是静态的 SQL 语句,经过处理之后都会封装成为 StaticSqlSource 对象,其中包含的 SQL 语句是可以直接执行的。
考虑 MyBatis 目前还是主推 XML 的配置使用方式,所以不打算对 ProviderSqlSource 展开说明。在开始分析剩余三个实现类之前,需要先对这几个类共享的一个核心组件 SqlSourceBuilder 进行分析。SqlSourceBuilder 继承自 BaseBuilder,主要用于解析前面经过
SqlNode#apply
方法处理的 SQL 语句中的占位符属性,同时将占位符替换成
?
字符串。
SqlSourceBuilder 中仅定义了一个
SqlSourceBuilder#parse
方法,实现了对占位符
#{}
中属性的解析,并将占位符替换成
?
。最终将解析得到的 SQL 语句和相关参数封装成 StaticSqlSource 对象返回。方法
SqlSourceBuilder#parse
的实现如下:
public SqlSource parse(
String originalSql, // 经过 SqlNode#apply 方法处理后的 SQL 语句
Class<?> parameterType, // 用户传递的实参类型
Map<String, Object> additionalParameters) { // 记录形参与实参之间的对应关系,即 SqlNode#apply 方法处理之后记录在 DynamicContext#bindings 属性中的键值对
// 创建 ParameterMappingTokenHandler 对象,用于解析 #{} 占位符
ParameterMappingTokenHandler handler =
new ParameterMappingTokenHandler(configuration, parameterType, additionalParameters);
GenericTokenParser parser = new GenericTokenParser("#{", "}", handler);
String sql = parser.parse(originalSql); // SELECT * FROM t_user WHERE id IN ( ? , ? )
// 构造 StaticSqlSource 对象,其中封装了被替换成 ? 的 SQL 语句,以及参数对应的 ParameterMapping 集合
return new StaticSqlSource(configuration, sql, handler.getParameterMappings());
}
该方法的实现还是我们熟悉的套路,获取指定占位符中的属性,然后交由对应的 TokenHandler 进行处理。SqlSourceBuilder 定义了 ParameterMappingTokenHandler 内部类,这是一个具体的 TokenHandler 实现,该内部类同时还继承自 BaseBuilder 抽象类,对应的
ParameterMappingTokenHandler#handleToken
方法实现如下;
public String handleToken(String content) { // 占位符中定义的属性,例如 __frch_itm_0
// 调用 buildParameterMapping 方法构造当前 content 对应的 ParameterMapping 对象,并记录到 parameterMappings 集合中
// ParameterMapping{property='__frch_itm_0', mode=IN, javaType=class java.lang.Long, jdbcType=null, numericScale=null, resultMapId='null', jdbcTypeName='null', expression='null'}
parameterMappings.add(this.buildParameterMapping(content));
// 全部返回 ? 字符串
return "?";
}
上述方法会调用
ParameterMappingTokenHandler#buildParameterMapping
方法构造实参 content (占位符中的属性)对应的 ParameterMapping 对象,并记录到
ParameterMappingTokenHandler#parameterMappings
属性中,同时返回
?
占位符将原始 SQL 中对应的占位符全部替换成
?
字符。这里我们以前面
SqlNode#apply
方法解析得到的
SELECT * FROM t_user WHERE id IN ( #{__frch_itm_0} , #{__frch_itm_1} )
为例,该 SQL 语句经过
SqlSourceBuilder#parse
方法处理之后会被解析成
SELECT * FROM t_user WHERE id IN ( ? , ? )
的形式封装到 StaticSqlSource 对象中。对应的
ParameterMappingTokenHandler#parameterMappings
参数内容如下:
ParameterMapping{property='__frch_itm_0', mode=IN, javaType=class java.lang.Long, jdbcType=null, numericScale=null, resultMapId='null', jdbcTypeName='null', expression='null'}
ParameterMapping{property='__frch_itm_1', mode=IN, javaType=class java.lang.Long, jdbcType=null, numericScale=null, resultMapId='null', jdbcTypeName='null', expression='null'}
了解了 SqlSourceBuilder 的作用,我们回头来看 DynamicSqlSource 的实现就会比较容易,DynamicSqlSource 实现了 SqlSource 接口中声明的
SqlSource#getBoundSql
方法,如下:
public BoundSql getBoundSql(Object parameterObject) {
// 构造上下文对象
DynamicContext context = new DynamicContext(configuration, parameterObject);
// 应用 SqlNode#apply 方法(树型结构,会遍历应用树中各个节点的 SqlNode#apply 方法),各司其职追加 SQL 片段到上下文中
rootSqlNode.apply(context);
// 创建 SqlSourceBuilder 对象,解析占位符属性,并将 SQL 语句中的 #{} 占位符替换成 ? 字符
SqlSourceBuilder sqlSourceParser = new SqlSourceBuilder(configuration);
Class<?> parameterType = parameterObject == null ? Object.class : parameterObject.getClass(); // 解析用户实参类型
SqlSource sqlSource = sqlSourceParser.parse(context.getSql(), parameterType, context.getBindings()); // 解析并封装结果为 StaticSqlSource 对象
// 基于 SqlSourceBuilder 解析结果和实参创建 BoundSql 对象
BoundSql boundSql = sqlSource.getBoundSql(parameterObject);
// 将 DynamicContext#bindings 中的参数信息复制到 BoundSql#additionalParameters 属性中
context.getBindings().forEach(boundSql::setAdditionalParameter);
return boundSql;
}该方法最终会将解析得到的 SQL 语句,以及相应的参数全部封装到 BoundSql 对象中返回,具体过程可以参考上述代码注释。
相对于 DynamicSqlSource 来说,RawSqlSource 的
RawSqlSource#getBoundSql
方法实现就要简单了许多。RawSqlSource 直接将请求委托给了 StaticSqlSource 处理,本质上就是基于用户传递的参数来构造 BoundSql 对象。对应 SQL 的解析则放置在构造方法中,在构造方法中会调用
RawSqlSource#getSql
方法获取对应的 SQL 定义,同样基于 SqlSourceBuilder 对原始 SQL 语句进行解析,封装成 StaticSqlSource 对象记录到属性中,在实际运行时只要填充参数即可。这也是很容易理解的,毕竟对于静态 SQL 来说,它的模式在整个应用程序运行过程中是不变的,所以在系统初始化时完成解析操作,后续可以直接拿来使用,但是对于动态 SQL 来说,SQL 语句的具体模式取决于用户传递的参数,需要在运行时实时解析。
绑定 Mapper 接口
饶了一大圈,看起来我们似乎完成了对映射文件的加载和解析工作,实际上我们确实完成了对映射文件的解析,但是光解析还是不够的,实际开发中我们对于这些定义在映射文件中的 SQL 语句的调用一般都是通过 Mapper 接口完成。所以还需要建立映射文件与具体 Mapper 接口之间的映射关系,这一过程由
XMLMapperBuilder#bindMapperForNamespace
方法实现:
private void bindMapperForNamespace() {
// 获取当前映射文件的 namespace 配置
String namespace = builderAssistant.getCurrentNamespace();
if (namespace != null) {
Class<?> boundType = null;
try {
// 解析 namespace 对应的 Mapper 接口类型
boundType = Resources.classForName(namespace);
} catch (ClassNotFoundException e) {
// ignore, bound type is not required
if (boundType != null) {
// 当前 Mapper 还未加载
if (!configuration.hasMapper(boundType)) {
// Spring may not know the real resource name so we set a flag
// to prevent loading again this resource from the mapper interface
// look at MapperAnnotationBuilder#loadXmlResource
// 记录当前已经加载的 namespace 标识到 Configuration#loadedResources 属性中
configuration.addLoadedResource("namespace:" + namespace);
// 注册对应的 Mapper 接口到 Configuration#mapperRegistry 属性中(对应 MapperRegistry)
configuration.addMapper(boundType);