


gurobi 高效数学规划引擎 | python3 配置、使用及建模实例


1 前言
本文源自github文章 wurmen/Gurobi-Python ,并在此基础上进行衍生扩展。
独立第三方优化器评估报告显示,Gurobi 以卓越的性能跻身大规模优化器新领袖地位,成为性价比最为优秀的企业大规模优化器首选。
Gurobi是由美国Gurobi Optimization公司开发新一代大规模优化器。无论在生产制造领域,还是在金融、保险、交通、服务等其他各种领域,当实际问题越来越复杂、问题规模越来越庞大的时候,我们需要一个经过证明可以信赖的大规模优化工具,为我们的决策提供质量保证,为我们增强信心。在理论和实践中,Gurobi 优化工具都被证明是全球性能领先的大规模优化器,具有突出的性价比,可以为客户在开发和实施中极大降低成本。
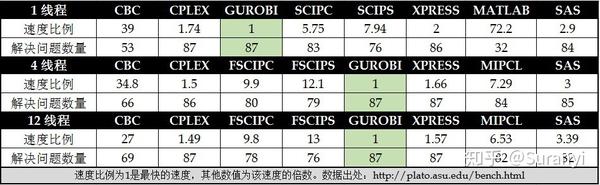
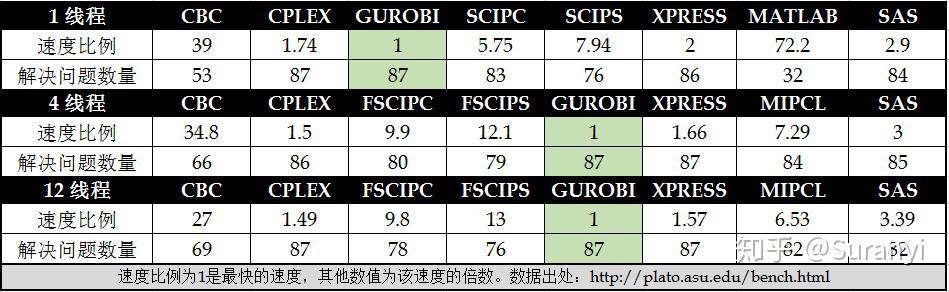
Gurobi 可以解决的数学问题:
线性问题(Linear problems)
二次型目标问题(Quadratic problems)
混合整数线性和二次型问题(Mixed integer linear and quadratic problems)
等等...几乎能解决lingo能解决的问题
中文官网: Gurobi 中文网站-Gurobi 中国
英文官网: https://www. gurobi.com/index
2 获取 gurobi
2.1 登陆官网
2.2 注册帐号
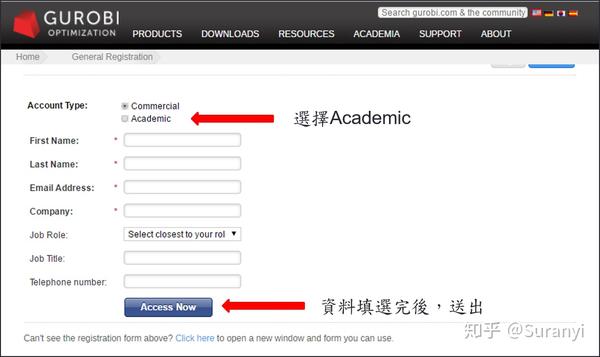
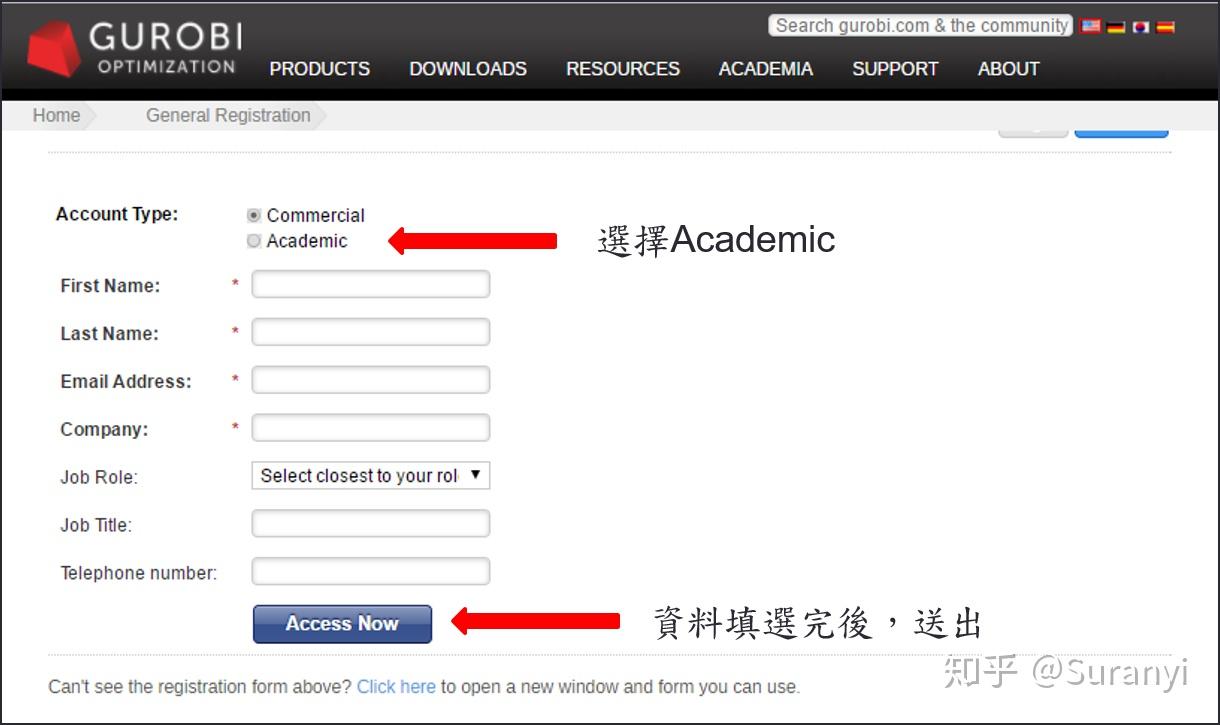
后续会收到验证邮箱,点击邮箱连接激活账号即可。
2.3 安装 gurobi 与申请 License
进入下载中心 ,上面下载 gurobi 引擎,下面申请学术许可证
2.4 验证 License
win:按下键盘 Win + R 键,输入刚刚获取到的 License,需要在 校园网下进行验证
mac:在终端中输入相同命令, 黑苹果因网卡问题,不能通过验证
无法连接校园网时, 请登陆 Gurobi 中文网站-Gurobi 中国 申请学术许可.
2.5 安装 gurobi 模块
安装 Anaconda3,并正确配置 conda 环境后,在 cmd 中输入以下指令(添加 gurobi 地址、安装模块)
conda config --add channels "http://conda.anaconda.org/gurobi"
conda install gurobi 3 快速入门
若读者有较好的python迭代器、生成器习惯,在编写程序时能大大简化。
在利用 Python+Gurobi 建立数学规划模型时,通常会按照设置变量、更新变量空间、设置目标函数、设置约束条件、执行最优化的顺序进行。


import gurobipy
# 创建模型
MODEL = gurobipy.Model()
# 创建变量
X = MODEL.addVar(vtype=gurobipy.GRB.INTEGER,name="X")
# 更新变量环境
MODEL.update()
# 创建目标函数
MODEL.setObjective('目标函数表达式', gurobipy.GRB.MINIMIZE)
# 创建约束条件
MODEL.addConstr('约束表达式,逻辑运算')
# 执行线性规划模型
MODEL.optimize()
# 输出模型结果
print("Obj:", MODEL.objVal)
for x in X:
print(f"{x.varName}:{round(x.X,3)}")3.1 辅助函数
列表推导式/列表解析式
- 列表推导式基于迭代器进行构造,效率高,常用于遍历、过滤、重复计算,快速生成满足要求的序列。
- 形式上使用中括号作为定界符
列表推导式以
if - for
为主,主要有以下两种嵌套方式
① if 在后 —— 过滤元素
[expression for exp1 in sequence1 if condition1
for exp2 in sequence2 if condition2
for exp2 in sequence2 if conditionn]
符合
condition
条件的值会被储存在列表中,不符合的不保存 (类似于 pass 和 filter 函数)
② if 在前 —— 分段映射
[expression1 if condition1 else expression2 for exp1 in sequence1
for exp2 in sequence2
for exp2 in sequence2]③ 嵌套循环
[f'{cl}班学生{num}' for cl in list('ABCDE') for num in range(1,6)] # for 从左到右循环
>>> ['A班学生1', 'A班学生2', 'A班学生3', 'A班学生4', 'A班学生5', 'B班学生1', 'B班学生2', 'B班学生3', 'B班学生4', 'B班学生5', 'C班学生1', 'C班学生2', 'C班学生3', 'C班学生4', 'C班学生5', 'D班学生1', 'D班学生2', 'D班学生3', 'D班学生4', 'D班学生5', 'E班学生1', 'E班学生2', 'E班学生3', 'E班学生4', 'E班学生5']以上几种可以混合使用,十分高效。
案例 :列出当前文件夹下的所有 Python 源文件
[filename for filename in os.listdir() if filename.endswith(('.py', '.pyw'))]
# for 循环遍历 os.listdir() 中的所有的文件,if 过滤以 .py, .pyw 结尾的文件案例 :判断某个数是否为素数
import math
def isprime(integer):
integreNotPrime = 0 in (integer % i for i in range(2, int(math.sqrt(integer)) + 1))
print(f'{integer} {"不" * integreNotPrime}是一个素数')quicksum()
在 gurobipy 模块中,quicksum 相当于 sum 函数及求和符号:
\sum_{j\in J}x_{i,j}\le5 \qquad\forall i\in I\\
写为:
for i in I:
MODEL.addConstr(quicksum(x[i,j] for j in J)<=5)
## 用 sum 时
for i in I:
MODEL.addConstr(sum(x[i,j] for j in J)<=5)此外,它还支持迭代器、生成器协议,也就是说,可以通过下面的代码,实现更为复杂的过滤、求和方法。
for c in C:
MODEL.addConstr(gurobipy.quicksum(x[d,i,j] for d in D for i in range(0, 24) for j in range(i + 1, 25) if i <= c < j) >= R[c])
# 更进一步,可以写为:MODEL.addConstrs(gurobipy.quicksum(x[d,i,j] for d in D for i in range(0, 24) for j in range(i + 1, 25) if i <= c < j) >= R[c] for c in C)\sum_{d\in D}\sum_{i=0}^{23}\sum_{ \begin{array}{c} j>i\\ i\le c< j \end{array} }^{24} x_{d,i,j}\ge R_c\qquad\forall\ c\in C\\
要注意: quicksum() 是 gurobi 推荐的用法, 它与 sum() 是一致的,但是个别情况例外:
# 《数学模型》姜启源第五版 P120 复习题
import gurobipy
# 创建模型
MODEL = gurobipy.Model()
# 创建变量
x1 = MODEL.addVar(vtype=gurobipy.GRB.INTEGER
, name='x1')
x2 = MODEL.addVar(ub=3, vtype=gurobipy.GRB.INTEGER, name='x2')
x1_ = MODEL.addVars(range(1, 3), vtype=gurobipy.GRB.INTEGER, name='x1_')
x2_ = MODEL.addVars(range(1, 6), vtype=gurobipy.GRB.INTEGER, name='x2_')
# 更新变量环境
MODEL.update()
# 创建目标函数
MODEL.setObjective(100 * x1 + 40 * x2, sense=gurobipy.GRB.MINIMIZE)
# 创建约束条件
MODEL.addConstr(x1 + x2_[1] >= 4, name='9:00-10:00')
MODEL.addConstr(x1 + x2_[1] + x2_[2] >= 3, name='10:00-11:00')
MODEL.addConstr(x1 + x2_[1] + x2_[2] + x2_[3] >= 4, name='11:00-12:00')
MODEL.addConstr(x1_[1] + x2_[1] + x2_[2] + x2_[3] + x2_[4]>= 6, name='12:00-13:00')
MODEL.addConstr(x1_[2] + x2_[2] + x2_[3] + x2_[4] + x2_[5]>= 5, name='13:00-14:00')
MODEL.addConstr(x1 + x2_[3] + x2_[4] + x2_[5]>= 6, name='14:00-15:00')
MODEL.addConstr(x1 + x2_[4] + x2_[5] >= 8, name='15:00-16:00')
MODEL.addConstr(x1 + x2_[5]>= 8, name='16:00-17:00')
# 此处, sum(x1_) 和 x1_.sum() 结果不同, 因为 sum(x1_) 对字典进行键相加
# 更标准的写法是使用 gurobipy.quicksum(x1_) 和 gurobipy.quicksum(x2_)
MODEL.addConstr(x1_.sum() == x1, name='x1')
MODEL.addConstr(x2_.sum() == x2, name='x2')
# 执行最优化
MODEL.optimize()multidict()
扩展字典,便于处理同一个对象的不同属性约束。
EMPLOYEE, MIN, MAX, COST, START, END = gurobipy.multidict({
"SMITH" : [6, 8, 30, 6, 20], "JOHNSON": [6, 8, 50, 0, 24], 'WILLIAMS': [6, 8, 30, 0, 24],
'JONES' : [6, 8, 30, 0, 24], 'BROWN': [6, 8, 40, 0, 24], 'DAVIS': [6, 8, 50, 0, 24],
'MILLER' : [6, 8, 45, 6, 18], 'WILSON': [6, 8, 30, 0, 24], 'MOORE': [6, 8, 35, 0, 24],
'TAYLOR' : [6, 8, 40, 0, 24], 'ANDERSON': [2, 3, 60, 0, 6], 'THOMAS': [2, 4, 40, 0, 24],
'JACKSON' : [2, 4, 60, 8, 16], 'WHITE': [2, 6, 55, 0, 24], 'HARRIS': [2, 6, 45, 0, 24],
'MARTIN' : [2, 3, 40, 0, 24], 'THOMPSON': [2, 5, 50, 12, 24], 'GARCIA': [2, 4, 50, 0, 24],
'MARTINEZ': [2, 4, 40, 0, 24], 'ROBINSON': [2, 5, 50, 0, 24]})EMPLOYEE 变成了list,而 MIN、MAX 等等则变成了字典
EMPLOYEE = [“SMITH”, "JOHNSON",...]
MIN = {“SMITH”: 6, "JOHNSON": 6,...}
tuplelist()
扩展列表元组,可以使用通配符筛选变量组。若使用 tuplelist 创建变量:
Cities= [('A','B'), ('A','C'), ('B','C'),('B','D'),('C','D')]
Routes = gurobipy.tuplelist(Cities)
Routes.select('A','*') # 选出所有第一个, 素为 "A" 的, 组
# 此外, 对于addVars创建的变量, x.select("*", i, j) 也可以进行筛选(详见案例3.6)可以将 '*' 理解为切片操作(列表的 list[:])
prod() 和 sum() 下标聚合
\sum_i\sum_jx_{ij}c_{ij} \\
gurobipy.quicksum(cost[i,j
] * x[i,j] for i,j in arcs)
# 等价于 x.prod(cost)
# 效果为对应元素相乘再相加3.2 添加决策变量 Model.addVar() 和 Model.addVars()
(1) 创建一个变量
x = MODEL.addVar(lb=0.0, ub=gurobipy.GRB.INFINITY, vtype=gurobipy.GRB.CONTINUOUS, name="")
-
lb = 0.0:变量的下界,默认为 0 -
ub = GRB.INFINITY:变量的上界,默认为无穷大 -
vtype = GRB.CONTINUOUS:变量的类型,默认为连续型,可改为GRB.BINARY0-1变量,GRB.INTEGER整型 -
name = "":变量名,默认为空
使用方法:
x1 = MODEL.addVar(lb=0, ub=1, name="x1")(2) 创建多个变量
x = MODEL.addVars(*indexes, lb=0, ub=gurobipy.GRB.INFINITY, vtype=gurobipy.GRB.CONTINUOUS, name="")
x = MODEL.addVars(3, 4, 5, vtype=gurobipy.GRB.BINARY, name="C") # 创建 3*4*5 个变量,使用 x[1,2,3] 进行访问
# lb,ub,vtype 可以单独设置(同样维度数据),也可以全部设置(单个值)
# 此外,若使用 m.addVars(iterable1,iterable2,iterable3) ,相当于笛卡尔积,参考案例 4.2
# 这种创建方法可以使用通配符命令,能简化代码添加完变量后需要 MODEL.update() 更新变量空间
3.3 添加目标函数 Model.setObjective() 和 Model.setObjectiveN()
(1) 单目标优化
MODEL.setObjective(expression, sense=None)
-
expression: 表达式,可以是一次或二次函数类型 -
sense:求解类型,可以是GRB.MINIMIZE或GRB.MAXIMIZE
使用方法:
MODEL.setObjective(8 * x1 + 10 * x2 + 7 * x3 + 6 * x4 + 11 * x5 + 9 * x6, gurobipy.GRB.MINIMIZE)
# 执行完成最优化后,可以通过 MODEL.objVal 获取目标函数值(如果存在的话)(2) 多目标优化(默认最小值)
-
expression: 表达式,可以是一次或二次函数类型 -
index: 目标函数对应的序号 (默认 0,1,2,…), 以 index=0 作为目标函数的值, 其余值需要另外设置参数 -
priority: 分层序列法多目标决策优先级(整数值), 值越大优先级越高 -
weight: 线性加权多目标决策权重(在优先级相同时发挥作用) -
abstol: 分层序列法多目标决策时允许的目标函数值最大的降低量 -
reltol: 分层序列法多目标决策时允许的目标函数值最大的降低比率 reltol*|目标函数值|
多目标优化案例
# 1. 合成型 ######################################################
# Obj1 = x + y weight = 1
# Obj2 = x - 5 * y weight = -2
# MODEL.setObjectiveN(x + y, index=0, weight=1, name='obj1')
# MODEL.setObjectiveN(x -5 * y, index=1, weight=-2, name='obj2')
# 即转化为:(x + y) - 2 * (x - 5 * y) = - x + 11 * y
# 2. 分层优化型(目标约束时使用) #####################################
# Obj1 = x + y priority = 5
# Obj2 = x - 5 * y priority = 1
# MODEL.setObjectiveN(x + y, index=0, priority=5, name='obj1')
# MODEL.setObjectiveN(x -5 * y, index=1, priority=1, name='obj2')
# 即转化为:先优化 Obj1,再优化 Obj2(按照 priority 的大小关系)
# 3. 混合优化型 ##################################################
# MODEL.setObjectiveN(x + y, index=0, weight=1, priority=5, name='obj1')
# MODEL.setObjectiveN(x -5 * y, index=1, weight=-2, priority=1, name='obj2')
# 则 先优化 Obj1 再优化 Obj2 最后相加作为目标值
# 4. 执行最优化结束后,获取目标函数值 ###############################
# MODEL.setParam(gurobipy.GRB.Param.ObjNumber, i) # 第 i 个目标
# print(MODEL.ObjNVal) # 打印第 i 个值虽然 gurobi 只支持线性优化,但可以通过变量换元实现多种优化形式。如下两例:
\begin{array}{lll} &\min\frac{2x+y+1}{x+3y}\\ &5x+y\le6\\ &x+3y\gt0\\ &x,y\gt0 \end{array}令z=1/(x+3y)\begin{array}{lll} &\min(2x+y)z+z\\ &5x+y\le6\\ &z(x+3y)=1\\ &x,y\gt0\\ &z>0 \end{array}\\
\begin{array}{l} &\min\max&\{x,y,3\}\\ &代码:&\text{MODEL.addConstr(z==max{x,y,3})}\\ &&\text{MODEL.setObjective(z, sense=GRB.MINIMIZE)} \end{array}\\
(3) 分段目标
MODEL.setPWLObj(var, x, y)
-
var指定变量的目标函数是分段线性 -
x定义分段线性目标函数的点的横坐标值(非减序列) -
y定义分段线性目标函数的点的纵坐标值
例 1: 线性分段函数
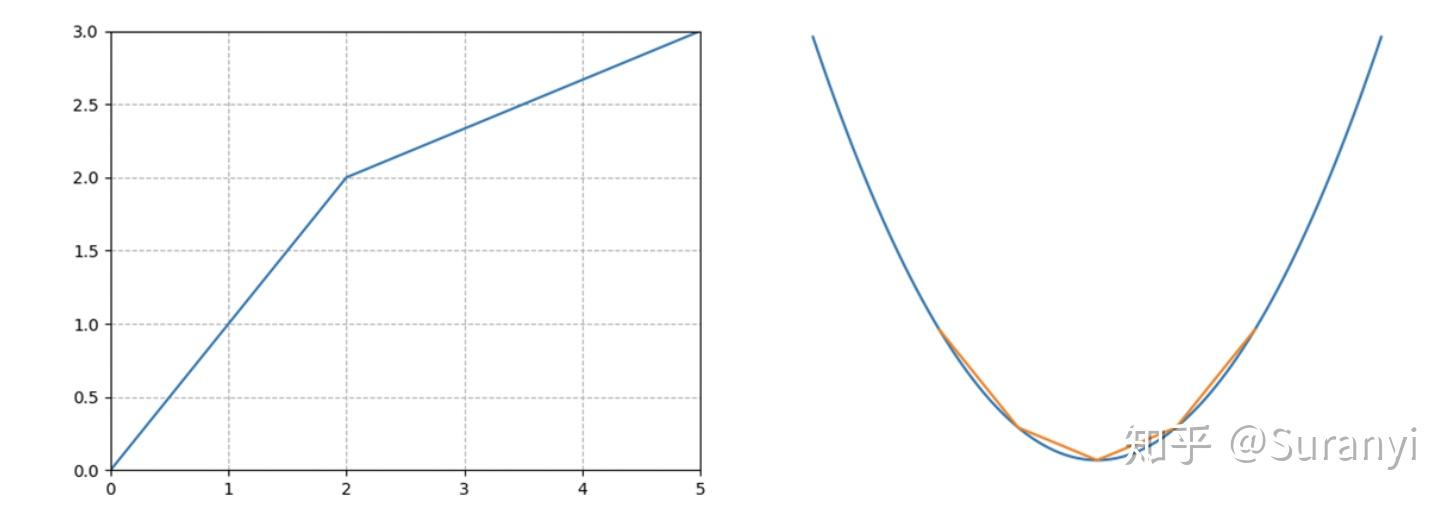
\max f(x)= \left\{ \begin{split} &x&,(0\le x\le2)\\ &\frac{1}{3}x+\frac{4}{3}&,(2\le x\le5) \end{split} \right.\\
MODEL.setPWLObj(x, [0, 2, 5], [0, 2, 3])
MODEL.setAttr(gurobipy.GRB.Attr.ModelSense, -1)例 2: 非线性函数折线逼近
\min f(x)=(x-1)^2+2\\
MODEL.setPWLObj(x, [-4, -1.5, 1, 3.5, 6], [27, 8.25, 2, 8.25, 27])
MODEL.setAttr(gurobipy.GRB.Attr.ModelSense, -1)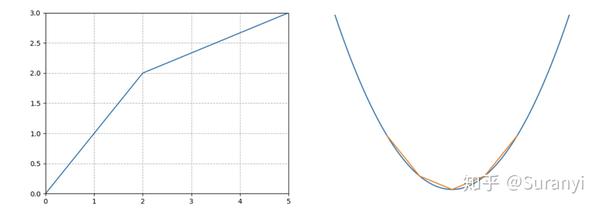
例 3: 引入指标变量
如函数 c(x)=\left\{ \begin{split} &10x&0\le x\le500\\ &1000+8x&500\le x\le1000\\ &3000+6x\quad&1000\le x\le 1500 \end{split} \right. 可以分解为: x=x_1+x_2+x_3 ,并满足:
(x_1-500)\cdot x_2=0\\ (x_2-500)\cdot x_3=0\\ 0\le x_1, x_2, x_3\le500
引入指标变量 y_1,y_2,y_3 , 当 0\le x\le500, y_1=1,y_2=0,y_3=0 , 当 500\le x\le1000, y_1=1,y_2=1,y_3=0 , 当 1000\le x\le1500, y_1=1,y_2=1,y_3=1 , 从而上述约束可以替换为:
500\cdot y_2\le x_1\le 500y_1\\ 500\cdot y_3\le x_2\le 500y_2\\ x_3\le500y_3\\ y_1,y_2,y_3=0或1
此时:
c(x)=10x_1+8x_2+6x_3
如果 c(x) 在分段处不连续如何处理?


3.4 添加约束条件 Model.addConstr() 和 Model.addConstrs()
(1) 创建一个常规一次/二次/等式约束
MODEL.addConstr(expression, name="")
-
expression: 布尔表达式,可以是一次或二次函数类型 -
name: 约束式的名称
使用方法:
MODEL.addConstr(12 * x1 + 9 * x2 + 25 * x3 + 20 * x4 + 17 * x5 + 13 * x6 >= 60, "c0")
# 注意,此处是调用 c 库实现的,若有 a < b < c,只能拆开写成 a < b,和 b < c(2) 创建多个常规一次/二次/等式约束
MODEL.addConstrs(expressions, name="")
addConstrs 用于添加多个约束条件,参数与 addConstr 类似,最大的优势是可以将外层的 for 循环转化为内部迭代器形式
\sum^7_{j=0}x_{ij}\le1, \forall\ i=0,1,\cdots,19\\ x_{ij}=0\text{ or }1\\
x = MODEL.addVars(20, 8, vtype=gurobipy.GRB.BINARY)
# 写法 1
for i in range(20):
MODEL.addConstr(x.sum(i, "*") <= 1)
# 写法 2
MODEL.addConstrs(x.sum(i, "*") <= 1 for i in range(20))(3) 创建一个范围约束
MODEL.addRange(expression, min_value, max_value, name="")
表达式 min_value<=expression<=max_value 的简写, 但这里的 min_value, max_value 必须是具体的实数值, 不能含有变量
(4) 创建一个指示变量约束
MODEL.addGenConstrIndicator(binvar, binval, expression, name="")
指示变量 binvar 的值取 binval 时, 进行约束 expression
案例:
x_1, x_2,x_3=0 或 \ge80\\
方法一: 构造指示变量 , 则上述约束转化为
80\cdot y_i\le x_i\le M\cdot y_i\qquad (M是一个很大的数, 可取1000)\\
方法二 : 转为二次约束, 若矩阵非正定矩阵, 则无法求解
x_i(x_i-80)\ge0\\
# 案例: 如果生产某一类型汽车 (x[i] > 0), 则至少要生产 80 辆
# %% 方法一
for i in range(3):
MODEL.addGenConstrIndicator(y[i + 1], 1, x[i + 1] >= 80)
MODEL.addGenConstrIndicator(y[i + 1], 0, x[i + 1] == 0)
# 以上代码等价于
for i in range(3):
MODEL.addConstr(x[i + 1] >= 80 * y[i + 1])
MODEL.addConstr(x[i + 1] <= 1000 * y[i + 1])3.5 执行最优化 Model.optimize()
MODEL.Params.LogToConsole=True # 显示求解过程
MODEL.Params.MIPGap=0.0001 # 百分比界差
MODEL.Params.TimeLimit=100 # 限制求解时间为 100s
MODEL.optimize()求解非凸二次问题
MODEL.setParam("NonConvex", 2) # 求解非凸二次型问题
Gurobi 运行时提示 “Objective Q not PSD (diagonal adjustment of 1.0e+01 would be required). Set NonConvex parameter to 2 to solve model.”
参考: gurobi 9.0 新功能
整数规划/混合整数规划问题评价准则: 百分比界差
Gap(f(x))=\frac{OPT-LP}{LP}\\
OPT 为当前的最优解,LP 为去掉整数约東后的松弛最优解百分比界差是数学规划领域常用的评价参数,具体可视为在去除问题参数整数取值的限制后,问题松弛解与最优解之间的绝对差距。
3.6 查看模型结果
(1) 模型是否取得最优解
MODEL.status == gurobipy.GRB.Status.OPTIMAL
- True 最优
- False 非最优, 在TimeLimit模式下, 不能用这个方法判断最优解
(2) 单目标优化 —— 查看目标函数值
# 查看单目标规划模型的目标函数值
print("Optimal Objective Value", MODEL.objVal)(3) 多目标优化 —— 查看目标函数值
# 查看多目标规划模型的目标函数值
for i in range(MODEL.NumObj):
MODEL.setParam(gurobipy.GRB.Param.ObjNumber, i)
print(f"Obj {i+1} = {MODEL.ObjNVal}")(4) 查看变量取值
# 查看变量取值,这个方法用的很少,请看第 4 部分案例
for var
in MODEL.getVars():
print(f"{var.varName}: {round(var.X, 3)}")(5) LP 问题灵敏度分析
通过 MODEL.getVars() 得到的变量 var
- 使用 var.X 可以获取变量值, var.RC 可以获取 Reduced Cost;
- var.Obj 可以得到在目标函数中的系数
- var.SAObjLow 可以得到 Allowable Minimize
- var.SAObjUp 可以得到 Allowable Maximize
通过 MODEL.getConstrs() 得到的约束式 Constr
- Constr.Slack 可以得到 Slack or Surplus
- Constr.pi 可以得到 Dual Price
- Constr.RHS 可以得到约束式右侧常值
- Constr.SARHSLow 可以得到 Allowable Minimize
- Constr.SARHSUp 可以得到 Allowable Maximize
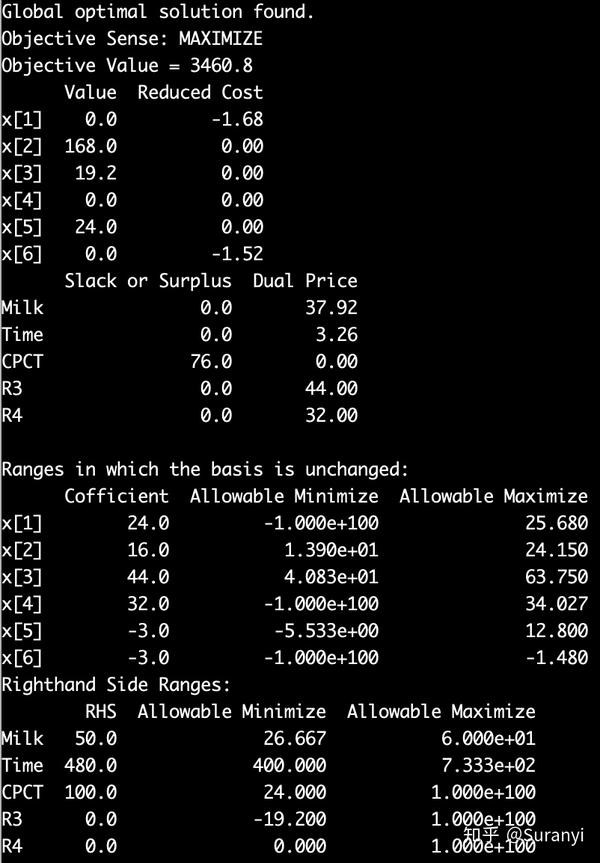
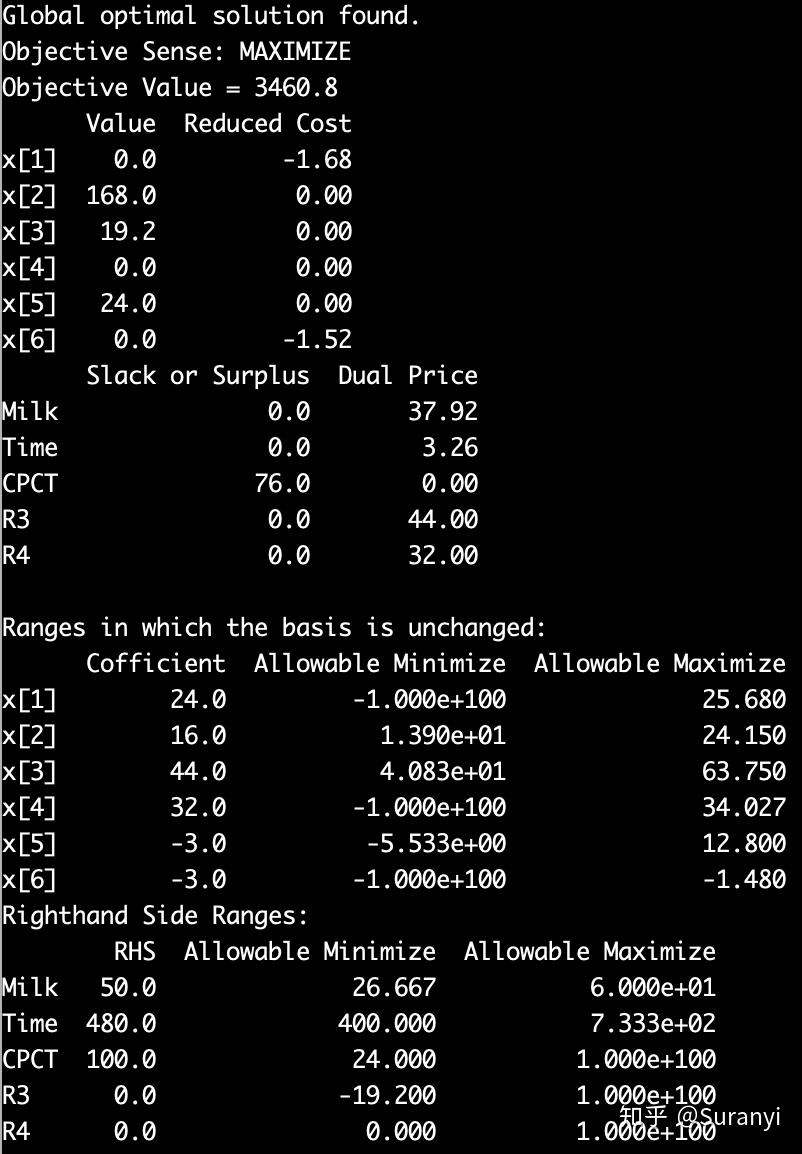
import gurobipy
def LP_Model_Analysis(MODEL, precision=3):
if MODEL.status == gurobipy.GRB.Status.OPTIMAL:
pd.set_option('display.precision', precision) # 设置精度
print("\nGlobal optimal solution found.")
print(f"Objective Sense: {'MINIMIZE' if MODEL.ModelSense is 1 else 'MAXIMIZE'}")
print(f"Objective Value = {MODEL.ObjVal}")
try:
print(pd.DataFrame([[var.X, var.RC] for var in MODEL.getVars()], index=[var.Varname for var in MODEL.getVars()], columns=["Value", "Reduced Cost"]))
print(pd.DataFrame([[Constr.Slack, Constr.pi] for Constr in MODEL.getConstrs()], index=[Constr.constrName for Constr in MODEL.getConstrs()], columns=["Slack or Surplus", "Dual Price"]))
print("\nRanges in which the basis is unchanged: ")
print(pd.DataFrame([[var.Obj, var.SAObjLow, var.SAObjUp] for var in MODEL.getVars()], index=[var.Varname for var in MODEL.getVars()], columns=["Cofficient", "Allowable Minimize", "Allowable Maximize"]))
print("Righthand Side Ranges:")
print(pd.DataFrame([[Constr.RHS, Constr.SARHSLow, Constr.SARHSUp] for Constr in MODEL.getConstrs()], index=[Constr.constrName for Constr in MODEL.getConstrs()], columns=["RHS", "Allowable Minimize", "Allowable Maximize"]))
except:
print(pd.DataFrame([var.X for var in MODEL.getVars()], index=[var.Varname for var in MODEL.getVars()], columns=["Value"]))
print(pd.DataFrame([Constr.Slack for Constr in MODEL.getConstrs()], index=[Constr.constrName for Constr in MODEL.getConstrs()], columns=["Slack or Surplus"]))4 案例
4.1 一般线性规划问题
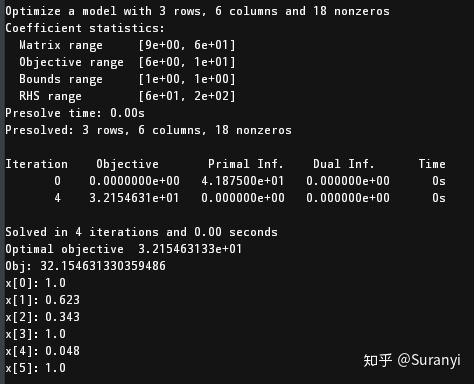
\begin{array} &\min\quad &Z=8x_1+10x_2+7x_3+6x_4+11x_5+9x_6\\ s.t. &12x_1+9x+25x_3+20x_4+17x_5+13x_6\ge60\\ &35x_1+42x_2+18x_3+31x_4+56x_5+49x_6\ge150\\ &37x_1+53x_2+28x_3+24x_4+29x_5+20x_6\ge125\\ &0\le x_j\le1,j=1,2,\cdots,6 \end{array}\\
import gurobipy
# 创建模型
c = [8, 10, 7, 6, 11, 9]
p = [[12, 9, 25, 20, 17, 13],
[35, 42, 18, 31, 56, 49],
[37, 53, 28, 24, 29, 20]]
r = [60, 150, 125]
MODEL = gurobipy.Model("Example")
# 创建变量
x = MODEL.addVars(6, lb=0, ub=1, name='x')
# 更新变量环境
MODEL.update()
# 创建目标函数
MODEL.setObjective(x.prod(c), gurobipy.GRB.MINIMIZE)
# 创建约束条件
MODEL.addConstrs(x.prod(p[i]) >= r[i] for i in range(3))
# 执行线性规划模型
MODEL.optimize()
print("Obj:", MODEL.objVal)
for v in MODEL.getVars():
print(f"{v.varName}:{round(v.x,3)}")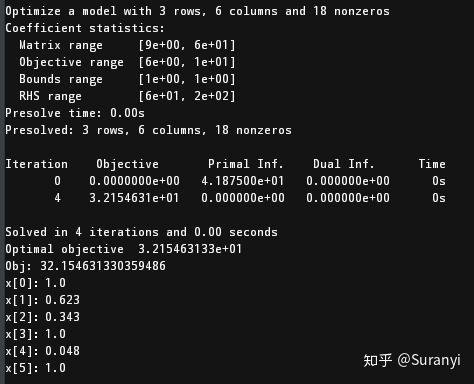
4.2 利用整数线性规划最优化员工工作表
(1) 问题描述
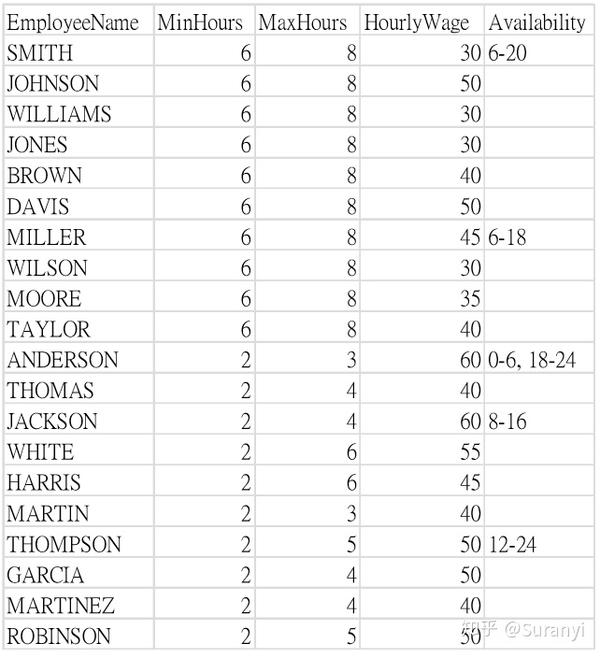
下图分别为员工信息(包含每日最短工作时长、最长工作时长、单位小时工作薪资、可工作时间)、每小时最短工作人数,要求满足以下条件:
- 满足每小时最短工作人数
- 如果员工进行工作,则需满足个人工作时长不低于最小值、不高于最大值
- 每位员工每天至多工作一个班次,每个班次都是一段连续的时间
请给出一种分配方案,使得每日支付员工的薪水最少。


(2) 模型建立
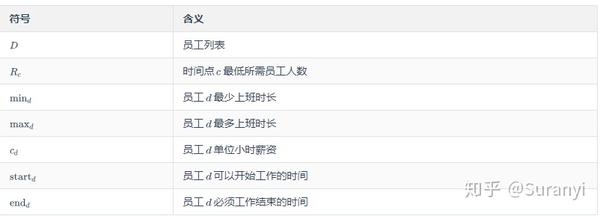
符号说明
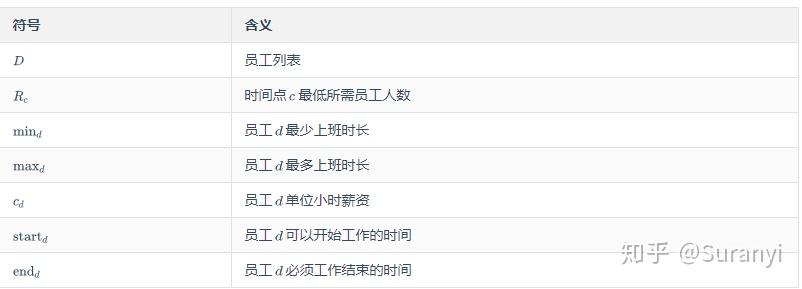
决策变量 :创建 20 * 24 * 24 个变量, i=0,1,2,\cdots,23;j=1,2,\cdots,24
x_{d,i,j}=\left\{ \begin{split} &1\qquad&如果员工d从时间i到时间j工作\\ &0&其他 \end{split} \right.\tag{1}
注意: i=6,j=9 表示员工在 6:00-9:00 工作,如果 \max j=23 ,则会造成在 23:00-24:00 无人工作。
目标函数
\min \sum_{d\in D} \sum_{i=0}^{23}\sum_{j>i}^{24}(j-i)\cdot x_{d,i,j}\cdot c_d\tag{2}
限制条件
① 员工 d 只工作一个班次,即至多只有一组 (i,j) 使得 x_{d,i,j}\ne0 ,从员工可开始工作时间开始扫描,在大于员工最少上班时间、小于最长上班时间内搜索,到员工必须结束工作时间为止,至多有一个状态变量为 1。
\sum_{i=0}^{23}\sum_{j>i}^{24}x_{d,i,j}\le\sum_{i=\text{start_d}}^{\text{end_d}}\sum_{\begin{array}{c} i<j\\ \text{min}_d\le j-i\le\max_d \end{array}}^\text{end_d}x_{d,i,j}\le1\qquad\forall\ d\in D\tag{3}
这是很常见的构造技巧:左约束保证了若员工进行工作,则一定会在时间限制内,右约束保证了员工在时间限制内最多只有1个班次的工作
② 每小时所需员工数限制:
对每一个时刻 c\in C ,对每一个员工 d ,判断其工作时间 [i,j) 是否包含 c :
\sum_{d\in D}\sum_{i=0}^{23}\sum_{ \begin{array}{c} j>i\\ i\le c< j \end{array} }^{24} x_{d,i,j}\ge R_c\qquad\forall\ c\in C\tag{4}
算法程序
import gurobipy
# 创建模型
EMPLOYEE, MIN, MAX, COST, START, END = gurobipy.multidict({
"SMITH" : [6, 8, 30, 6, 20], "JOHNSON": [6, 8, 50, 0, 24], 'WILLIAMS': [6, 8, 30, 0, 24],
'JONES' : [6, 8, 30, 0, 24], 'BROWN': [6, 8, 40, 0, 24], 'DAVIS': [6, 8, 50, 0, 24],
'MILLER' : [6, 8, 45, 6, 18], 'WILSON': [6, 8, 30, 0, 24], 'MOORE': [6, 8, 35, 0, 24],
'TAYLOR' : [6, 8, 40, 0, 24], 'ANDERSON': [2, 3, 60, 0, 6], 'THOMAS': [2, 4, 40, 0, 24],
'JACKSON' : [2, 4, 60, 8, 16], 'WHITE': [2, 6, 55, 0, 24], 'HARRIS': [2, 6, 45, 0, 24],
'MARTIN' : [2, 3, 40, 0, 24], 'THOMPSON': [2, 5, 50, 12, 24], 'GARCIA': [2, 4, 50, 0, 24],
'MARTINEZ': [2, 4, 40, 0, 24], 'ROBINSON': [2, 5, 50, 0, 24]})
REQUIRED = [1, 1, 2, 3, 6, 6, 7, 8, 9, 8, 8, 8, 7, 6, 6, 5, 5, 4, 4, 3, 2, 2, 2, 2]
MODEL = gurobipy.Model("Work Schedule")
# 创建变量
x = MODEL.addVars(EMPLOYEE, range(24), range(1, 25), vtype
=gurobipy.GRB.BINARY)
# 更新变量环境
MODEL.update()
# 创建目标函数
MODEL.setObjective(gurobipy.quicksum((j - i) * x[d, i, j] * COST[d] for d in EMPLOYEE for i in range(24) for j in range(i + 1, 25)), sense=gurobipy.GRB.MINIMIZE)
# 创建约束条件
MODEL.addConstrs(x.sum(d) <= (gurobipy.quicksum(x[d, i, j] for i in range(START[d], END[d] + 1) for j in range(i + 1, END[d] + 1) if MIN[d] <= j - i <= MAX[d])) for d in EMPLOYEE)
MODEL.addConstrs(gurobipy.quicksum(x[d, i, j] for i in range(START[d], END[d] + 1) for j in range(i + 1,END[d] + 1) if MIN[d] <= j - i <= MAX[d]) <= 1 for d in EMPLOYEE)
MODEL.addConstrs(gurobipy.quicksum(x[d, i, j] for d in EMPLOYEE for i in range(24) for j in range(i + 1, 25) if i <= c < j) >= REQUIRED[c] for c in range(24))
# 执行最优化
MODEL.optimize()
# 输出结果 —— 使用pyecharts 0.5.11
from pyecharts import HeatMap
x_axis = list(range(24))
y_axis = []
data = []
if MODEL.status == gurobipy.GRB.Status.OPTIMAL:
solution = [k for k, v in MODEL.getAttr('x', x).items() if v == 1]
for d, i, j in solution:
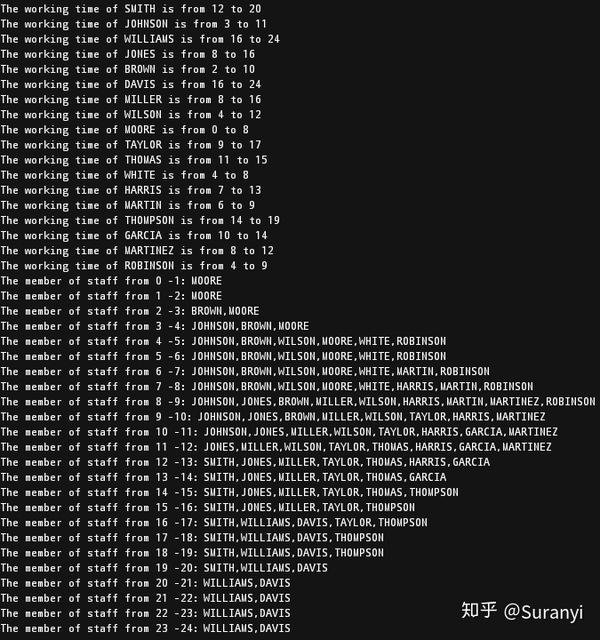
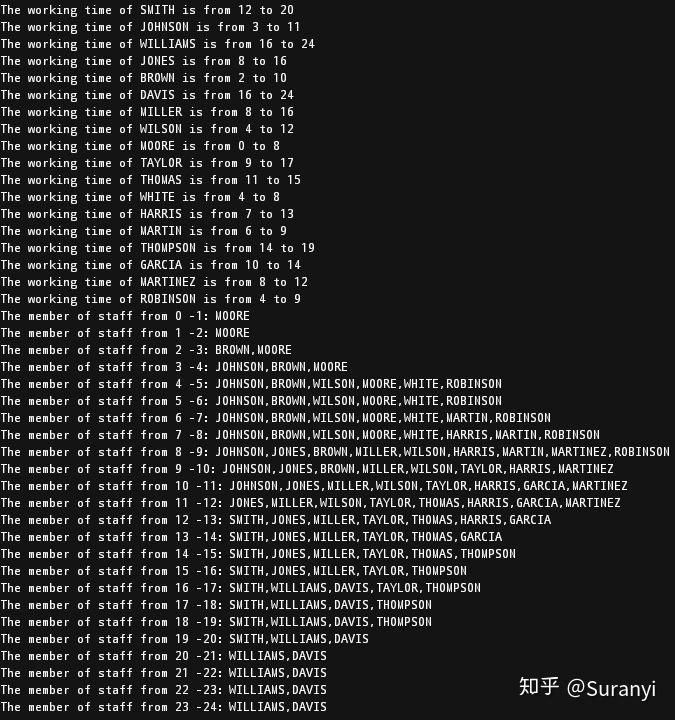
print(f"The working time of {d} is from {i} to {j}")
y_axis.append(d)
data.extend([[time, d, COST[d]] for time in range(i, j)])
for c in range(24):
member = [d for d, i, j in solution if i <= c < j]
print(f'The member of staff from {c} -{c+1}: {",".join(member)}')
def label_formatter(param):
return param.x
def yaxis_formatter(param):
return param
heatmap = HeatMap(width=1100, height=500)
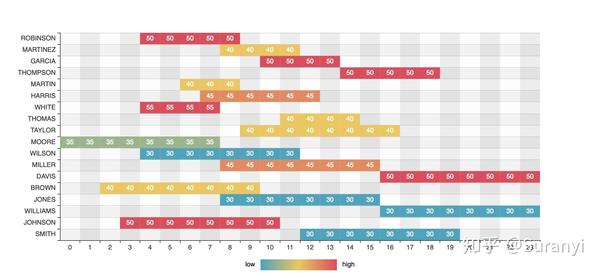
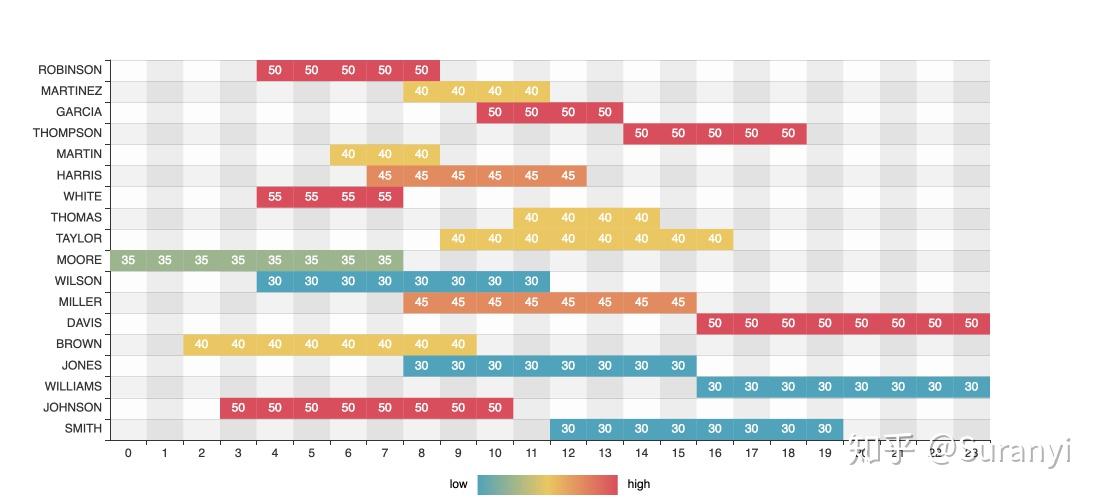
heatmap.add("", x_axis, y_axis, data, is_visualmap=True, visual_text_color="#000", visual_orient="horizontal", visual_pos="center", visual_range=[30, 50], is_calculable=False, is_label_show=True, label_formatter=label_formatter, yaxis_formatter=yaxis_formatter, label_pos="inside")
heatmap.render("result.png")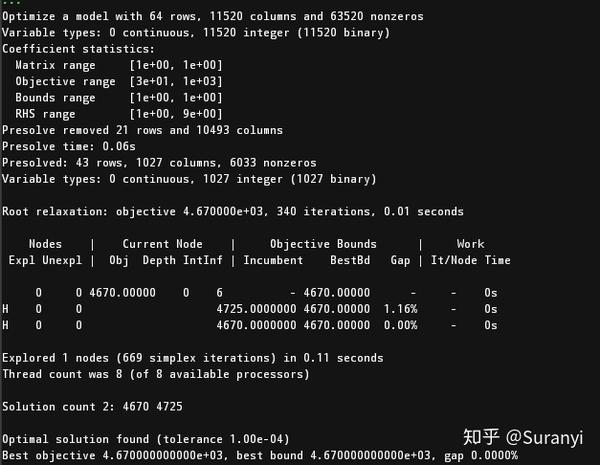
4.3 非平衡指派问题
设 C=(c_{ij})_{n\times m} 是一个 n 行 m 列的代价矩阵,则指派问题的一般形式为:
\begin{split} &\min\quad &\sum_{i=1}^n\sum_{j=1}^mx_{ij}c_{ij}\\ &s.t.&\sum_{j=1}^mx_{ij}\le1 &\forall\ i=1,2,\cdots,n\\ &&\sum_{i=1}^nx_{ij}\le1&\forall\ j=1,2,\cdots,m\\ &&\sum_{i=1}^n\sum_{j=1}^mx_{ij}=\min\{m,n\}\\ &&x_{ij}=0\ 或\ 1 \end{split}\\
算法程序
import gurobipy
def assignment(cost_matrix):
# 保存行列标签
index = cost_matrix.index
columns = cost_matrix.columns
# 创建模型
model = gurobipy.Model('Assignment')
x =
model.addVars(index, columns, vtype=gurobipy.GRB.BINARY)
model.update()
# 设置目标函数
model.setObjective(gurobipy.quicksum(x[i, j] * cost_matrix.at[i, j] for i in index for j in columns))
# 添加约束条件
model.addConstr(gurobipy.quicksum(x[i, j] for i in index for j in columns) == min([len(index), len(columns)]))
model.addConstrs(gurobipy.quicksum(x[i, j] for j in columns) <= 1 for i in index)
model.addConstrs(gurobipy.quicksum(x[i, j] for i in index) <= 1 for j in columns)
# 执行最优化
model.optimize()
# 输出信息
result = cost_matrix * 0
if model.status == gurobipy.GRB.Status.OPTIMAL:
solution = [k for k, v in model.getAttr('x', x).items() if v == 1]
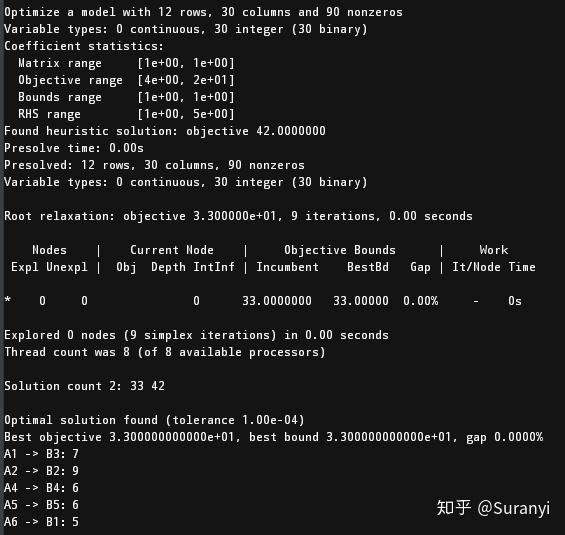
for i, j in solution:
print(f"{i} -> {j}:{cost_matrix.at[i,j]}")
result.at[i, j] = 1
return result
if __name__ == '__main__':
import pandas as pd
cost_matrix = pd.DataFrame(
[[4, 8, 7, 15, 12], [7, 9, 17, 14, 10], [6, 9, 12, 8, 7], [6, 7, 14, 6, 10], [6, 9, 12, 10, 6],
[5, 8, 13, 11, 10]],
index=['A1', 'A2', 'A3', 'A4', 'A5', 'A6'], columns=['B1', 'B2', 'B3', 'B4', 'B5'])
assignment(cost_matrix)

在 scipy 模块中,也有 linear_sum_assignment 函数可以求解指派问题,使用的是匈牙利算法,虽然求解速度也很快,但对于数据要求比较苛刻(矩阵不能太大,大型矩阵需要先进行稀疏处理)
def zeros_ones_integer_programmingg(cost_matrix):
import numpy as np
from scipy.optimize import linear_sum_assignment
solution_matrix = np.zeros_like(cost_matrix)
row_ind, col_ind = linear_sum_assignment(cost_matrix)
solution_matrix[row_ind, col_ind] = 1
minimize = (cost_matrix*solution_matrix).sum()
if type(cost_matrix) == pd.core.frame.DataFrame:
solution_matrix = pd.DataFrame(solution_matrix, index = cost_matrix.index,columns= cost_matrix.columns)
minimize = minimize.sum()
return solution_matrix,minimize
if __name__ == '__main__':
import numpy as np
cost_matrix = np.array([[2, 15, 13, 4], [10, 4, 14, 15], [9, 14, 16, 13], [7, 8, 11, 9]]) # 代价矩阵
print(zeros_ones_integer_programmingg(cost_matrix))4.4 LP问题与灵敏度分析
问题描述
企业内部的生产计划有各种不同的情况,从空间层次看,在工厂级要根据外部需求和内部设备、人力、原料等条件,以最大利润为目标制订产品的生产计划,在车间级则要根据产品生产计划、工艺流程、资源约束及费用参数等,以最小成本为目标制定生产作业计划. 从时间层次看,若在短时间内认为外部需求和内部资源等不随时间变化,可制订单阶段生产计划,否则就要制订多阶段生产计划.
一奶制品加工厂用牛奶生产 A1, A2 两种奶制品,1 桶牛奶可以在甲类设备上用 12h 加工成 3kg A1,或者在乙类设备上用 8h 加工成 4kg A2. 根据市场需求,生产的 A1, A2 全部能售出,且每千克 A1 获利 24, ,每千克 A2 获利 16 , . 现在加工厂每天能得到 50 桶牛奶的供应,每天正式工人总的劳动时间为 480h,并且甲类设备每天至多能加工 100kg A1,乙类设备的加工能力没有限制. 该厂还开发了奶制品的深加工技术: 用 2h 和 3, 加工费,可将 1kg A1 加工成 0.8kg 高级奶制品 B1,也可将 1kg A2 加工成 0.75kg 高级奶制品 B2,每千克 B1 能获利 44, ,每千克 B2 能获利 32 , . 试为该厂制订一个生产销售计划,使每天的净利润最大,并讨论以下问题:
(1) 若投资 30, 可以增加供应 1 桶牛奶,投资 3, 可以增加 1h 劳动时间,应否作这些投资?若每天投资 150 , ,可赚回多少?
(2) 每千克高级奶制品 B1, B2 的获利经常有 10%的波动,对制订的生产销售计划有无影响?若每千克 B1 的获利下降 10%, 计划应该变化吗?
(3) 若公司已经签订了每天销售 10 kg A1 的合同并且必须满足,该合同对公司的利润有什么影响?
模型建立


import gurobipy
# 创建模型
MODEL = gurobipy.Model()
# 创建变量
x = MODEL.addVars(range(1, 7), name='x')
# 更新变量环境
MODEL.update()
# 创建目标函数
Cost = [24, 16, 44, 32, -3, -3]
MODEL.setObjective(sum(x[i +
1] * Cost[i] for i in range(6)), sense=gurobipy.GRB.MAXIMIZE)
# 创建约束条件
MODEL.addConstr(1 / 3 * (x[1] + x[5]) + 1 / 4 * (x[2] + x[6]) <= 50, name="Milk")
MODEL.addConstr(4 * (x[1] + x[5]) + 2 * (x[2] + x[6]) + 2 * (x[5] + x[6]) <= 480, name="Time")
MODEL.addConstr(x[1] + x[5] <= 100, name="CPCT")
MODEL.addConstr(x[3] == 0.8 * x[5])
MODEL.addConstr(x[4] == 0.75 * x[6])
# 执行线性规划模型
MODEL.optimize()
# 输出模型结果
LP_Model_Analysis(MODEL)分析


4.5 解数独
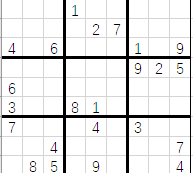
数独问题就是将 9 × 9 的网格填充上1~9的整数值,同时保证每个整数在每一行、每一列和每个 3 × 3 方格只出现一次。网格中分布有一些线索,你的任务就是填充剩余的网格数字。对于此问题,可以使用0-1变量优化求解。
标准数独问题只要有解即可,无需设置目标函数,即:可行解就是数独问题的解。
决策变量
x_{ijk}=\left\{\begin{split} &1\qquad &第i行j列值为k\\&0&其他 \end{split} \right.\\
约束条件
① 对于给定的初始元素,都认为是等式约束:
x_{ijk}=1\qquad\forall\ k=c_{ij} \in C\\
② 所有格子只能取一个值:
\sum_{k=1}^9x_{ijk}=1\qquad\forall\ i,j=1,2,\cdots,9\\
③ 每个数字在同一行、同一列、同一个九宫格只能出现一次:
\sum_{j=1}^9x_{ijk}=1\qquad\forall\ i,k=1,2,...,9\\ \sum_{i=1}^9x_{ijk}=1\qquad\forall\ j,k=1,2,...,9\\ \sum_{i=1+3\times I}^{3+3\times I}\sum^{3+3\times J}_{j=1+3\times J}x_{ijk}=1\qquad\forall\ k=1,2,...,9;\ I,J=0,1,2\\
算法程序
import gurobipy
import pandas as pd
def sudoku(matrix):
MODEL = gurobipy.Model('solve_sudoku')
x = MODEL.addVars(9, 9, 9, vtype=gurobipy.GRB.BINARY)
MODEL.update()
MODEL.setObjective(1, gurobipy.GRB.MINIMIZE)
MODEL.addConstrs(x[i, j, k] == 1 for i in range(9) for j in range(9) for k in range(9) if isinstance(matrix.at[i, j], int) and k == matrix.at[i, j] - 1)
MODEL.addConstrs(sum(x.select(i, j, '*')) == 1 for i in range(9) for j in range(9))
MODEL.addConstrs(sum(x.select(i, '*', j)) == 1 for i in range(9) for j in range(9))
MODEL.addConstrs(sum(x.select('*', i, j)) == 1 for i in range(9) for j in range(9))
MODEL.addConstrs(sum(x[i + 3 * I, j + 3 * J, k] for i in range(3) for j in range(3)) == 1 for k in range(9) for I in range(3) for J in range(3))
MODEL.optimize()
Result = pd.DataFrame()
for k, v in MODEL.getAttr('x', x).items():
if v == 1:
Result.at[k[0], k[1]] = k[2
] + 1
return Result.astype(int)
if __name__ == '__main__':
matrix = pd.read_excel('sudoku_test.xlsx', index_col=False, header=None, na_filter=False)
print(sudoku(matrix))
t(sudoku(matrix))sudoku_test.xlsx 文件长这样,可以修改成自己想要的数字:
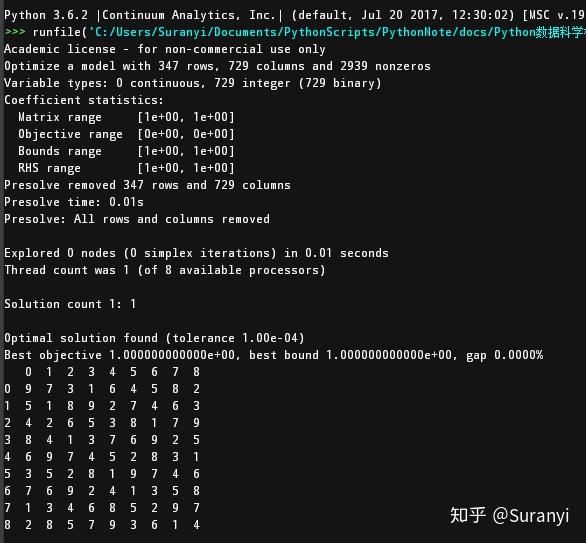
求解结果
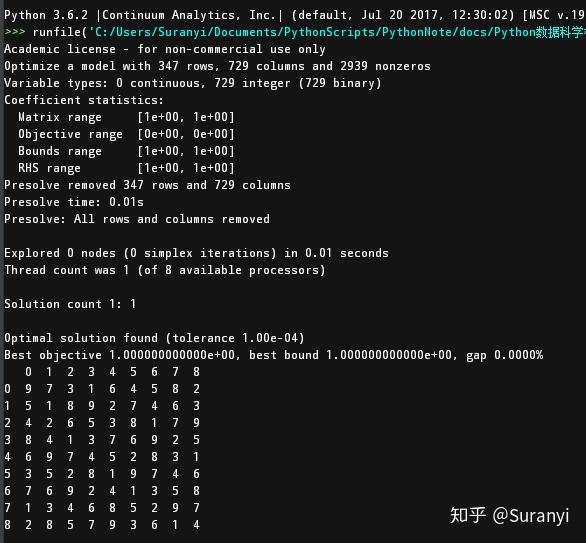
(求解数独问题有很多方法~)
【2019.3.28更新: 结合 pyqt5 设计解数独小程序】
 https://www.zhihu.com/video/1095039243348422656
https://www.zhihu.com/video/1095039243348422656
4.6 求解 CCR-DEA 问题
内容摘自笔记




算法程序
import os
import gurobipy
import pandas as pd
class DEA(object):
def __init__(self, DMUs_Name, X, Y, AP=False):
self.m1, self.m1_name, self.m2, self.m2_name, self.AP = X.shape[1], X.columns.tolist(), Y.shape[1], Y.columns.tolist(), AP
self.DMUs, self.X, self.Y = gurobipy.multidict({DMU: [X.loc[DMU].tolist(), Y.loc[DMU].tolist()] for DMU in DMUs_Name})
print(f'DEA(AP={AP}) MODEL RUNING...')
def __CCR(self):
for k in self.DMUs:
MODEL = gurobipy.Model()
OE, lambdas, s_negitive, s_positive = MODEL.addVar(), MODEL.addVars(self.DMUs), MODEL.addVars(self.m1), MODEL.addVars(self.m2)
MODEL.update()
MODEL.setObjectiveN(OE, index=0, priority=1)
MODEL.setObjectiveN(-(sum(s_negitive) + sum(s_positive)), index=1, priority=0)
MODEL.addConstrs(gurobipy.quicksum(lambdas[i] * self.X[i][j] for i in self.DMUs if i != k or not self.AP) + s_negitive[j] == OE * self.X[k][j] for j in range(self.m1))
MODEL.addConstrs(gurobipy.quicksum(lambdas[i] * self.Y[i][j] for i in self.DMUs if i != k or not self.AP) - s_positive[j] == self.Y[k][j] for j in range(self.m2))
MODEL.setParam('OutputFlag', 0)
MODEL.optimize()
self.Result.at[k, ('效益分析', '综合技术效益(CCR)')] = MODEL.objVal
return self.Result
def dea(self):
columns_Page = ['效益分析'] * 3 + ['规模报酬分析'] * 2 + ['差额变数分析'] * (self.m1 + self.m2) + ['投入冗余率'] * self.m1 + ['产出不足率'] * self.m2
columns_Group = ['技术效益(BCC)', '规模效益(CCR/BCC)', '综合技术效益(CCR)','有效性', '类型'] + (self.m1_name + self.m2_name) * 2
self.Result = pd.DataFrame(index=self.DMUs, columns=[columns_Page, columns_Group])
self.__CCR()
return self.Result
def analysis(self, path=None, name=None):
Result = self.dea()
file_path = os.path.join(os.path.expanduser("~"), 'Desktop') if path == None else r'../table'
file_name = '\\DEA 数据包络分析报告.xlsx' if name == None else f'\\{name}.xlsx'
Result.to_excel(file_path + file_name, 'DEA 数据包络分析报告')
if __name__ == '__main__':
data = pd.DataFrame({1990: [14.40, 0.65, 31.30, 3621.00, 0.00], 1991: [16.90, 0.72, 32.20, 3943.00, 0.09],
1992: [15.53, 0.72, 31.87, 4086.67, 0.07], 1993: [15.40, 0.76, 32.23, 4904.67, 0.13],
1994: [14.17, 0.76, 32.40, 6311.67, 0.37], 1995: [13.33, 0.69, 30.77, 8173.33, 0.59],
1996: [12.83, 0.61, 29.23, 10236.00, 0.51], 1997: [13.00, 0.63, 28.20, 12094.33, 0.44],
1998: [13.40, 0.75, 28.80, 13603.33, 0.58], 1999: [14.00, 0.84, 29.10, 14841.00, 1.00]},
index=['政府财政收入占 GDP 的比例/%', '环保投资占 GDP 的比例/%', '每千人科技人员数/人', '人均 GDP/元', '城市环境质量指数']).T