|
|
|


如果您不希望引入阿里云智能语音交互产品SDK,或者目前提供的Java、C或C++的SDK不能满足您的要求,可以基于本文描述自行开发代码访问阿里语音服务。
功能介绍
阿里云智能语音交互产品通过WebSocket协议对外提供实时语音流语音转写功能,支持长语音。其中指令、事件皆为WebSocket协议Text类型的DataFrame,音频流需要以Binary Frame的形式上传至服务端,调用时序需要符合协议要求的交互流程。发送语音数据使用Websocket的二进制帧BinaryFrame,具体可参见 Data Frames 。
-
支持的输入格式:PCM(无压缩的PCM或WAV文件)、16bit采样位数、单声道(mono)。
-
支持的音频采样率:8000Hz/16000Hz。
-
支持设置返回结果:是否返回中间识别结果,在后处理中添加标点,将中文数字转为阿拉伯数字输出。
-
支持设置多语言识别:在控制台编辑项目中进行模型选择,详情请参见 管理项目 。
鉴权
服务端通过临时Token进行鉴权,请求时需要在URL中携带Token参数,Token获取方式请参见 获取Token概述 。获取Token之后通过如下方式访问语音服务端。
|
访问类型 |
说明 |
URL |
|
外网访问 |
所有服务器均可使用外网访问URL。 |
wss://nls-gateway.cn-shanghai.aliyuncs.com/ws/v1?token=<your token> |
|
上海ECS内网访问 |
使用阿里云上海ECS(即ECS地域为华东2(上海)),可使用内网访问URL。ECS的经典网络不能访问AnyTunnel,即不能在内网访问语音服务;如果希望使用AnyTunnel,需要创建专有网络在其内部访问。
说明
|
ws://nls-gateway.cn-shanghai-internal.aliyuncs.com:80/ws/v1?token=<your token> |
交互流程
指令及音频流需要严格按照下图所示顺序发送,否则会导致和服务端交互失败。
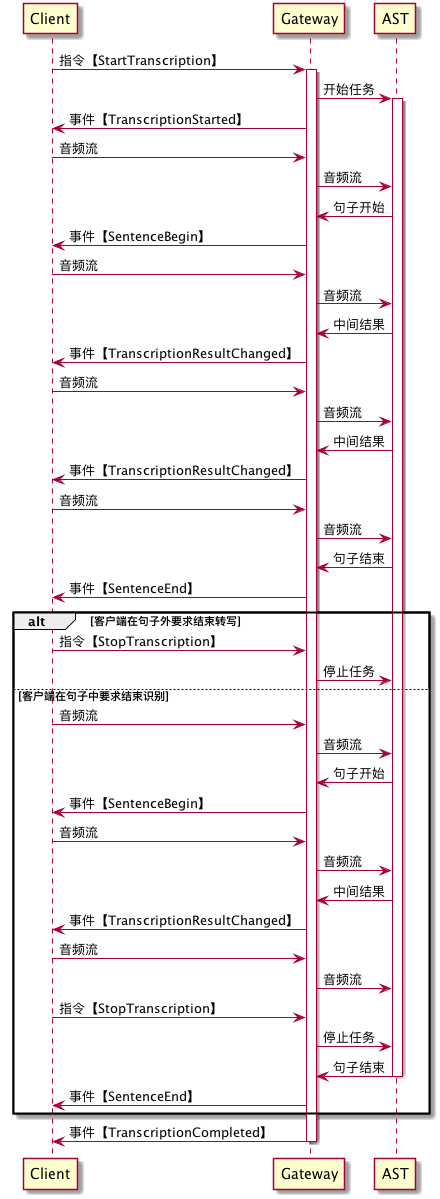
指令
请求指令用于控制语音识别任务的起止,标识任务边界,以JSON格式的Text Frame方式发送服务端请求,需要在Header中设置请求的基础信息。指令由Header和Payload两部分组成,其中Header部分为统一格式,不同指令的Payload部分格式各不相同。
1、Header格式说明
Header格式如下:
|
参数 |
类型 |
是否必选 |
说明 |
|
appkey |
String |
是 |
管控台 创建的项目Appkey。 |
|
message_id |
String |
是 |
当次消息请求ID,随机生成32位唯一ID。 |
|
task_id |
String |
是 |
整个实时语音识别的会话ID,整个请求中需要保持一致,32位唯一ID。 |
|
namespace |
String |
是 |
访问的产品名称,固定为“SpeechTranscriber”。 |
|
name |
String |
是 |
指令名称,包含StartTranscription和StopTranscription指令。具体请参见 StartTranscription指令 和 StopTranscription指令 。 |
2、StartTranscription指令
Payload对象参数说明:
|
参数 |
类型 |
是否必选 |
说明 |
|
format |
String |
否 |
音频编码格式,默认是PCM(无压缩的PCM文件或WAV文件),16bit采样位数的单声道。 |
|
sample_rate |
Integer |
否 |
音频采样率,默认是16000Hz,根据音频采样率在管控台对应项目中配置支持该采样率及场景的模型。 |
|
enable_intermediate_result |
Boolean |
否 |
是否返回中间识别结果,默认是false。 |
|
enable_punctuation_prediction |
Boolean |
否 |
是否在后处理中添加标点,默认是false。 |
|
enable_inverse_text_normalization |
Boolean |
否 |
ITN(逆文本inverse text normalization)中文数字转换阿拉伯数字。设置为True时,中文数字将转为阿拉伯数字输出,默认值:False。 |
|
customization_id |
String |
否 |
自学习模型ID。 |
|
vocabulary_id |
String |
否 |
定制泛热词ID。 |
|
max_sentence_silence |
Integer |
否 |
语音断句检测阈值,静音时长超过该阈值会被认为断句,参数范围200ms~2000ms,默认值800ms。 |
|
enable_words |
Boolean |
否 |
是否开启返回词信息,默认是false。 |
|
enable_ignore_sentence_timeout |
Boolean |
否 |
是否忽略实时识别中的单句识别超时,默认是false。 |
|
disfluency |
Boolean |
否 |
过滤语气词,即声音顺滑,默认值false(关闭),开启时需要设置version为4.0。 |
|
speech_noise_threshold |
Float |
否 |
噪音参数阈值,参数范围:[-1,1]。取值说明如下:
重要
该参数属高级参数,调整需慎重并重点测试。 |
|
enable_semantic_sentence_detection |
Boolean |
否 |
是否开启语义断句,默认是false。 |
示例代码如下:
{
"header": {
"message_id": "05450bf69c53413f8d88aed1ee60****",
"task_id": "640bc797bb684bd6960185651307****",
"namespace": "SpeechTranscriber",
"name": "StartTranscription",
"appkey": "17d4c634****"
"payload": {
"format": "opus",
"sample_rate": 16000,
"enable_intermediate_result": true,
"enable_punctuation_prediction": true,
"enable_inverse_text_normalization": true
}
3、StopTranscription指令
StopTranscription指令要求服务端停止语音转写,Payload为空。示例代码如下:
{
"header": {
"message_id": "05450bf69c53413f8d88aed1ee60****",
"task_id": "640bc797bb684bd6960185651307****",
"namespace": "SpeechTranscriber",
"name": "StopTranscription",
"appkey": "17d4c634****"
}事件
1、TranscriptionStarted事件
TranscriptionStarted事件表示服务端已经准备好了进行识别,客户端可以发送音频数据了。
|
参数 |
类型 |
说明 |
|
session_id |
String |
客户端请求时传入session_id的话则原样返回,否则由服务端自动生成32位唯一ID。 |
示例格式如下:
{
"header": {
"message_id": "05450bf69c53413f8d88aed1ee60****",
"task_id": "640bc797bb684bd6960185651307****",
"namespace": "SpeechTranscriber",
"name": "TranscriptionStarted",
"status": 20000000,
"status_message": "GATEWAY|SUCCESS|Success."
"payload": {
"session_id": "1231231dfdf****"
}2、SentenceBegin事件
SentenceBegin事件表示服务端检测到了一句话的开始。
|
参数 |
类型 |
说明 |
|
index |
Integer |
句子编号,从1开始递增。 |
|
time |
Integer |
句子开始时间相对整个音频流的开始时间,单位是毫秒。 |
示例格式如下:
{
"header": {
"message_id": "05450bf69c53413f8d88aed1ee60****",
"task_id": "640bc797bb684bd6960185651307****",
"namespace": "SpeechTranscriber",
"name": "SentenceBegin",
"status": 20000000,
"status_message": "GATEWAY|SUCCESS|Success."
"payload": {
"index": 1,
"time": 320
}3、TranscriptionResultChanged事件
TranscriptionResultChanged事件表示识别结果发生了变化。
|
参数 |
类型 |
说明 |
|
index |
Integer |
句子编号,从1开始递增。 |
|
time |
Integer |
当前已处理的音频时长,单位是毫秒。 |
|
result |
String |
当前的识别结果。 |
|
words |
Word |
词信息。 |
|
status |
Integer |
状态码。 |
Word 结构:
|
参数 |
类型 |
说明 |
|
text |
String |
文本。 |
|
startTime |
Integer |
词开始时间。 |
|
endTime |
Integer |
词结束时间。 |
示例格式如下:
{
"header":{
"message_id":"05450bf69c53413f8d88aed1ee60****",
"task_id":"640bc797bb684bd6960185651307****",
"namespace":"SpeechTranscriber",
"name":"TranscriptionResultChanged",
"status":20000000,
"status_message":"GATEWAY|SUCCESS|Success."
"payload":{
"index":1,
"time":1800,
"result":"今年双十一",
"words":[
"text":"今年",
"startTime":1,
"endTime":2
"text":"双十一",
"startTime":2,
"endTime":3
}4、SentenceEnd事件
SentenceEnd事件表示服务端检测到了一句话的结束。
|
参数 |
类型 |
说明 |
|
index |
Integer |
句子编号,从1开始递增。 |
|
time |
Integer |
当前已处理的音频时长,单位是毫秒。 |
|
begin_time |
Integer |
这句话对应的SentenceBegin事件的时间,单位是毫秒。 |
|
result |
String |
当前的识别结果。 |
|
confidence |
Double |
结果置信度,取值范围[0.0,1.0],值越大表示置信度越高。 |
|
words |
Word |
词信息。 |
|
status |
Integer |
状态码,默认值 20000000,开启
|
|
stash_result |
StashResult |
暂存结果,开启语意断句后会返回下一句未断句中间结果。 |
StashResult结构:
|
参数 |
类型 |
说明 |
|
sentenceId |
Integer |
句子编号,从1开始递增。 |
|
beginTime |
Integer |
句子开始时间。 |
|
text |
String |
转写内容。 |
|
currentTime |
Integer |
当前处理时间。 |
示例格式如下:
{
"header": {
"message_id": "05450bf69c53413f8d88aed1ee60****",
"task_id": "640bc797bb684bd6960185651307****",
"namespace": "SpeechTranscriber",
"name": "SentenceEnd",
"status": 20000000,
"status_message": "GATEWAY|SUCCESS|Success."
"payload": {
"index": 1,
"time": 3260,
"begin_time": 1800,
"result": "今年双十一我要买电视"
}5、TranscriptionCompleted事件
TranscriptionCompleted事件表示服务端已停止了语音转写。示例格式如下:
{
"header": {
"message_id": "05450bf69c53413f8d88aed1ee60****",
"task_id": "640bc797bb684bd6960185651307****",
"namespace": "SpeechTranscriber",
"name": "TranscriptionCompleted",
"status": 20000000,
"status_message": "GATEWAY|SUCCESS|Success."
}