


R语言:字符串处理与正则表达式(1) :stringr包及其主要函数

记录使用R语言基于tidyverse系列stringr包及正则表达式进行字符处理;分以下几部分进行介绍:
stringr包及其主要函数介绍
R语言正则表达式内容介绍
R语言正则表达式与stringr包综合应用案例
正则表达式通常都被打上很难的标签。事实也的确如此,很多人都觉得正则表达式是蛋疼般的存在。
其实,大家在PC上使用
*.doc
之类的带有通配符字样的字符串来搜索目标文件夹内后缀为
doc
的文件,就已经是在使用
正则表达式
了。
饶是如此,正则表达式确实很难。但一旦入门,正则表达式的强大、高效甚至优雅却能给我们带来欲罢不能的奇妙体验。
在详细介绍正则表达式之前,先对stringr包进行介绍。
1. stringr包及其主要函数
stringr
包是tidyverse系列包中用于处理字符串的专业包,其函数语法简洁易懂,与base R中的字符串处理包相比,更容易上手使用。
这个链接
介绍了
stringr
与base R包中关于字符串处理的主要函数的对比,可以详细参考。
本文主要介绍stringr包相关函数。按自己的理解:字符串跟地底下石油煤炭有点类似,
- 先要 描述定义 他;
- 然后 检查定位 :
- 接着对其采挖等 编辑处理 :
- 最后 组织应用 他们。
按这四大核心动作来分类字符串处理函数。这些分类没有严谨的分类逻辑,当然前后顺序也没有标准答案,只是根据自己的认知和习惯来做分类,类别和类别之间也存在关联,不管怎么分类,核心还是把这些函数作为工具灵活高效的用起来,当然也不能为了工具而工具。
1.1 长度及顺序
这类函数主要包括:
- 长度类
- str_length():返回字符串的长度
- str_width():返回字符串宽度?
str_length()返回字符串中的codepoints的数量。简言之,就是字符串有多少字符。
str_width()返回字符串以固定宽度字体打印时(即在控制台中打印时)将占用的空间。
处理中文及一些特殊字符时需要注意,width和length之间是存在区别的;如中文汉字的宽度值会是字符数的两倍;
> (x <- c("\u6c49\u5b57", "\U0001f60a"))
[1] "汉字" " "
> (y <- "在小小的花园里挖呀挖")
[1] "在小小的花园里挖呀挖"
> (z <- "we all living in the yellow submarine")
[1] "we all living in the yellow submarine"
> str_length(x)
[1] 2 1
> str_width(x)
[1] 4 2
> str_length(y)
[1] 10
> str_width(y)
[1] 20
> str_length(z)
[1] 37
> str_width(z)
[1] 37
上述例子中,汉字和表情符的width是length的两倍,英文字母等其他字符width与length相同。实际应用中,这两个函数用的比较少,这里仅做记录,不详细展开。具体细节,可查看stringr 和stringi包的源文档。
- str_pad()
- str_trunc()
- str_trim()
str_pad()是用指定字符填充字符串到目标长度;
str_trunc()是截断字符串到一定长度;
str_trim()移除字符串2边空白符。
其中前两个函数个人几乎未实际使用到,存在即合理,能以一个函数的形式存在,他肯定有其用途。本文以包源文档示例做记录。
str_pad()函数 , 对字符串:
- 指定目标长度(指定长度小于字符串长度时,保留原长度;函数有以宽度计算与否的选项,默认以宽度计算,如果选否,则会以长度计算)
- 明确填充的位置(左,右,两边,默认为左侧)
- 指定填充字符(默认为空格,只能指定宽度为1的填充物)
# 案例1
> rbind(
str_pad("hadley", 30, "left"),
str_pad("hadley", 30, "right"),
str_pad("hadley", 30, "both")
[1,] " hadley"
[2,] "hadley "
[3,] " hadley "
# 案例2
> str_pad(c("a", "abc", "abcdef"), 10)
[1] " a" " abc" " abcdef"
> str_pad("a", c(5, 10, 20))
[1] " a"
[2] " a"
[3] " a"
# 案例3
> str_pad("a", 10, pad = c("-", "_", " "))
[1] "---------a" "_________a" " a"
# 案例4
> str_pad("hadley", 3)
[1] "hadley"
# 案例5
> str_pad("陈叔叔很酷", 10,side = "right", pad = "_", use_width = FALSE)
[1] "陈叔叔很酷_____"
> str_pad("陈叔叔很酷", 10,side = "right", pad = "_" )
[1] "陈叔叔很酷"
str_trunc()函数 , 可以看做是str_pad()的逆操作,对字符串:
- 指定目标长度(指定长度不小于字符串长度时,保留原长度)
- 明确删除的位置(左,右,两边,默认为左侧)
- 指定删除部分内容填充字符(默认为"...")
# 案例1
> rbind(
str_trunc(z, 20, "right", ellipsis = "_._"),
str_trunc(z, 40, "left"),
str_trunc(z, 20, "center")
[1,] "we all living in _._"
[2,] "we all living in the yellow submarine"
[3,] "we all li...ubmarine"
str_trim()函数 个人在实际项目工作中使用得比较频繁;甚至成为很多场合下字符串处理过程的一个标准配置动作。用工业领域的语言来表达,就像一个产品加工完成后,一定会保留一个去毛边的动作;或者用生活中的场景语言来表达,就像刷牙洗脸完成后擦拭一遍洗手台面一样;嗯......还是去毛边动作更贴切一点,trim本来就有修剪的意思。
在使用大量文本数据进行精确匹配场景,比如使用left_join()函数以一列字符型数据为"关键词"进行连接时,两个表对应字段通常需要精确匹配;但在实际执行过程中,会存在部分,甚至全部字符在开始或结尾部分存在空格,尤其是结尾部分的空格很难人肉识别;为了join效率,往往在执行join之前对关键词批量执行一次全方位的str_trim().
str_squish()函数功能与str_trim()函数相似,他能干掉两端的空白,并将字符串内部大于1格的空白全部换成1格:这样至少更符合书写规范。
这里用个例子把
长度
相关的函数串起来:
> z %>%
# "we all living in the yellow submarine"
str_pad(45, "both") %>%
# " we all living in the yellow submarine "
str_trunc(width = 30,
side = "center",
ellipsis = " ") %>%
# " we all liv submarine "
str_trim() %>%
# "we all liv submarine"
str_squish()
[1] "we all liv submarine"
# "we all liv submarine"
- 顺序类
- str_order():返回排序后各元素在原向量中的位置值;
- str_rank():返回排序前字符串向量各元素的排序;
- str_sort(): 返回排序后的字符串向量;
字符串顺序,其实是比较复杂的,涉及语言区域,数字化,NA值处理等,本文不做深入探究,仅用中文,英文+数字作为例子简单记录。
- 先看中文
# 注意指定locale与否在结果上的区别
> city <- c("上海", "北京", "深圳","广州")
> str_rank(city, locale = "zh")
[1] 3 1 4 2
# 分别指四个城市按拼音顺序的排序,上海第3,北京第1...
> str_rank(city)
[1] 1 2 4 3
# 看上去,指定locale值为"zh"更接近我们的常识:按拼音排:北京排第一,广州随后,上海跟上,最后是深圳。
# sort 和 Order一下
> str_sort(city, locale = "zh")
[1] "北京" "广州" "上海" "深圳"
# 这就是排序后的字符串向量
> str_order(city, locale = "zh")
[1] 2 4 1 3
# 这个是指排好顺序后各个位置上的数字分别为原字符串向量中第几个字符串;如:排在第一的北京,为原字符串向量中的第二个......
- 英文+数字
> en_num <- c("100a10", "100a5", "2b", "2a")
> str_sort(en_num)
[1] "100a10" "100a5" "2a" "2b"
> str_sort(en_num , numeric = TRUE)
[1] "2a" "2b" "100a5" "100a10"
# 指定numeric为true的话,会先按数字大小排序
1.2 检测、匹配与定位
如果把字符串的长度系列函数的功能定义为
描述
它(字符串);那么,检测、匹配与定位类函数,则可定义为
找到
它。
实现这类功能的函数主要有:
- str_equal():判断两字符串是否相等
- str_detect():返回字符串是否匹配的逻辑值
- str_count():返回匹配的次数
- str_like():以SQL like运算符相同的模式进行匹配检测
- str_subset():查找匹配元素
- str_which():查找匹配索引
- str_locate():返回匹配字符串起始位置
- str-starts():在开始/结束时检测是否存在匹配
- str_ends():在开始/结束时检测是否存在匹配
- str_view() :查看匹配位置及结果
函数比较多,挑重点展开。
str_detect() 这个函数返回逻辑值,作为逻辑判断选择的结果输入,可以很好的与tidyverse系列其他包的函数配合使用。
- 先看几个独立使用的例子,并开始逐步引入正则表达式在函数中的应用;
en_num <- c("100a10", "100a5", "2b", "2a")
#检测是否包含字母a
> str_detect(en_num,"a")
[1] TRUE TRUE FALSE TRUE
#检测是否包含数字
> str_detect(en_num,"\\d+")
[1] TRUE TRUE TRUE TRUE
#检测是否以数字结束
> str_detect(en_num,"\\d$")
[1] TRUE TRUE FALSE FALSE
- 再来看组合使用的例子:
我们有一组足球运动员数据,其中一列为各球员最佳位置,我们想根据该信息进行位置分组(前锋,中场,后卫,门将等),组合使用str_detect()函数与mutate()和case_when()函数,快速实现上述需求。对应代码如下:
先简单浏览数据(原始数据为几万行几十列的数据表,我们找10行4列数据做案例)
fifa <- read.csv("./data/fifa23.csv") %>%
as_tibble() %>%
select(1,7,8,15) %>%
head(10)
# A tibble: 10 × 4
Known.As Best.Position Nationality Club.Name
<chr> <chr> <chr> <chr>
1 L. Messi CAM Argentina Paris Saint-Ge…
2 K. Benzema CF France Real Madrid CF
3 R. Lewandowski ST Poland FC Barcelona
4 K. De Bruyne CM Belgium Manchester City
5 K. Mbappé ST France Paris Saint-Ge…
6 M. Salah RW Egypt Liverpool
7 T. Courtois GK Belgium Real Madrid CF
8 M. Neuer GK Germany FC Bayern Münc…
9 Cristiano Ronaldo ST Portugal Manchester Uni…
10 V. van Dijk CB Netherlands Liverpool
我们在Best.Position 列后增加一列Position_Group:
- 当最佳位置为GK时,位置分组为 GK 门将;
- 当最佳位置以B结束时,位置分组为DEF 后卫;
- 当最佳位置以M结束时,位置分组为MID 中场;
- 其他剩下的全部位置分组为FWD 前锋。 如下代码实现。
fifa %>% mutate( Position_Group = case_when(Best.Position =="GK" ~ "GK",
str_detect(Best.Position, "B$") ~"DEF",
str_detect(Best.Position, "M$") ~ "MID",
TRUE ~ "FWD"), .after = Best.Position)
# A tibble: 10 × 5
Known.As Best.…¹ Posit…² Natio…³
<chr> <chr> <chr> <chr>
1 L. Messi CAM MID Argent…
2 K. Benz… CF FWD France
3 R. Lewa… ST FWD Poland
4 K. De B… CM MID Belgium
5 K. Mbap… ST FWD France
6 M. Salah RW FWD Egypt
7 T. Cour… GK GK Belgium
8 M. Neuer GK GK Germany
9 Cristia… ST FWD Portug…
10 V. van … CB DEF Nether…
# … with 1 more variable:
# Club.Name <chr>, and
# abbreviated variable names
# ¹Best.Position,
# ²Position_Group, ³Nationality
# ℹ Use `colnames()` to see all variable names
这里使用了str_detect()函数判断结果作为case_when()函数的左侧输入。
str_count() 比较简单,返回匹配的次数。 这个函数对于被查找的字符串参数,默认为正则表达式。
> en_num <- c("100a10", "100a5", "2b", "2a")
> str_count(en_num,"a")
[1] 1 1 0 1
# 字母a出现的次数
> str_count(en_num,"a|b")
[1] 1 1 1 1
# 字母a或b出现的次数
> str_count(en_num,"\\d+")
[1] 2 2 1 1
# 数字组合出现的次数
> str_count(en_num,"\\d")
[1] 5 4 1 1
# 单个数字出现的次数
> str_count(en_num,".")
[1] 6 5 2 2
# 任意字符出现的次数
> str_count(en_num, fixed("."))
[1] 0 0 0 0
# 字符"."出现的次数
这里已经开始显示正则表达式的强大,比如我们需要知道大量字符串,一句话,一段文字等字符串中数字出现的次数,用正则表达式来处理就会很简单。
str_subset()函数和str_which()函数 这两个函数也比较简单,前者使用率会高一点。同样,这些函数也是默认待匹配参数为正则表达式模式。
str_subset()函数,字符串中只要有一个匹配上了目标模式,就返回全部元素;
str_which()函数,字符串中只要有一个匹配上了目标模式,就返回其所在位置;
> en_num <- c("100a10", "100a5", "2b", "2a")
> str_subset(en_num,"a")
[1] "100a10" "100a5" "2a"
> str_subset(en_num,"a|b")
[1] "100a10" "100a5" "2b" "2a"
> str_which(en_num,"a")
[1] 1 2 4
为了方便记忆,我们用一组通俗的示例来串这几个函数: 把字符串向量理解为一个村子,向量中的一个元素理解为一户人家,每个元素中的字符串理解为家人,现在要找这个村里窝藏的嫌疑犯(比如说参与了聚众斗殴或者电信诈骗什么的):
str_detect()负责报告每家每户是不是窝藏了嫌疑犯;
str_count()负责清点每家每户分别有多少个嫌疑犯,没有嫌疑犯的也记录在案;
str_which()负责记录有嫌疑犯的家庭地址门牌号;没嫌疑犯的他不管;
str_subset()函数理解为"株连九族"的存在,只要家里有嫌疑犯,全家人都先请出来。
要抓真正的嫌疑犯,还得后面介绍的提取插入类函数来实现。
如果说上述这组函数只是负责找到嫌疑犯,记录门牌号。接下来这组函数则实现匹配目标字符串在字符串中的精确定位;通俗一点就是找到嫌烦住哪个屋,有没有明目张胆的在家门口晃悠或躲在后门随时准备逃跑......
- str_locate():返回匹配字符串起始位置
- str-starts():在开始/结束时检测是否存在匹配
- str_ends():在开始/结束时检测是否存在匹配
> en_num_2 <- c("100aa10", "a100a5", "2b", "2a")
> str_locate(en_num_2,"a")
start end
[1,] 4 4
[2,] 1 1
[3,] NA NA
[4,] 2 2
# 返回第一个匹配的结果
> str_locate_all(en_num_2,"a")
[[1]]
start end
[1,] 4 4
[2,] 5 5
[[2]]
start end
[1,] 1 1
[2,] 5 5
[[3]]
start end
[[4]]
start end
[1,] 2 2
# 返回全部匹配的结果
> str_starts(en_num_2,"a")
[1] FALSE TRUE FALSE FALSE
# 是否以字母a开头
> str_ends(en_num_2,"a")
[1] FALSE FALSE FALSE TRUE
# 是否以字母a结尾
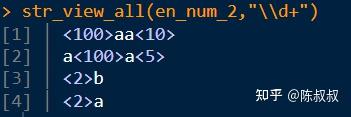
上面的函数都以数字信息传递结果,str_view()和 str_view_all() 函数则对其位置进行直观的
可视化
。
在下面代码中,匹配的字符被
<>
括起来了,谁?在哪个位置?非常清楚的显示出来。
在RStudio软件界面中,显示效果更佳。
> str_view(en_num_2,"a")
[1] │ 100<a><a>10
[2] │ <a>100<a>5
[4] │ 2<a>
> str_view_all(en_num_2,"a")
[1] │ 100<a><a>10
[2] │ <a>100<a>5
[3] │ 2b
[4] │ 2<a>
> str_view_all(en_num_2,"\\d+")
[1] │ <100>aa<10>
[2] │ a<100>a<5>
[3] │ <2>b
[4] │ <2>a
1.3 字符串编辑修改:复制转换,提取插入,移除替换等
- 转换复制类
-
str_dup():复制字符串
-
str_escape(): 正则表达式元字符转义
-
str_to_xxx():字符大小写转换。有:
- to_lower: 大写转小写
- to_upper: 小写转大写
- to_sentence:句子首字母大写
- to_title: 单词首字母大写
-
str_conv():指定字符串编码,使用场景较少
转换复制类的函数比较简单,这里做简单记录。
# str_dup()函数
> str_dup(en_num_2,2)
[1] "100aa10100aa10" "a100a5a100a5" "2b2b"
[4] "2a2a"
> str_dup(en_num_2,2:5)
[1] "100aa10100aa10" "a100a5a100a5a100a5"
[3] "2b2b2b2b" "2a2a2a2a2a"
# 分别对第1-4个元素执行2-5次重复;
# str_escape()函数
> str_detect(c("a", "."), ".")
[1] TRUE TRUE
# 转义前:"."被作为正则表达式元字符,能匹配任意非换行字符
> str_detect(c("a", "."), str_escape("."))
[1] FALSE TRUE
# 转义后:"."只能作为自己本身,无元字符技能,匹配不到字母a,只能匹配到自己:"."
# str_to_XXX()函数
> (z2 <- "we all living in the YELLOW submarine")
[1] "we all living in the YELLOW submarine"
> str_to_lower(z2)
[1] "we all living in the yellow submarine"
> str_to_upper(z2)
[1] "WE ALL LIVING IN THE YELLOW SUBMARINE"
> str_to_sentence(z2)
[1] "We all living in the yellow submarine"
> str_to_title(z2)
[1] "We All Living In The Yellow Submarine"
- 提取插入
- str_sub():根据位置设置或获取子字符串
- str_extract():提取完全匹配的字符串
- str_match():提取全部匹配内容及各个匹配组的内容
提取插入类函数应用范围很广,其中str_extract()函数更为常用。
str_sub()函数 根据子字符串的位置来获取和设置(修改,插入)字符串,以单个字符串和字符串向量分别展开介绍上述功能。
- 获取字符串
#简单的根据位置信息获取子字符串,负数表示倒数位。
> str_sub(z2,4,6) # 第4个字符开始,第6个字符结束
[1] "all"
> str_sub(z2,-9) # 倒数第9个字符开始,直到全部结束
[1] "submarine"
> str_sub(z2, end = -11) # 始于最开始,倒数第11个字符结束
[1] "we all living in the YELLOW"
#获取多组位置信息处的子字符串 注意str_sub与str_sub_all的区别
> str_sub(en_num_2,c(1,2,2,1),c(2,3,3,1)) #
[1] "10" "10" "b" "2"
> str_sub_all(en_num_2,c(1,2,2,1),c(2,3,3,1)) #
[[1]]
[1] "10" "00" "00" "1"
[[2]]
[1] "a1" "10" "10" "a"
[[3]]
[1] "2b" "b" "b" "2"
[[4]]
[1] "2a" "a" "a" "2"
# 根据获取的位置提取子字符串
> (locate <- str_locate_all(en_num_2,"\\d+"))
[[1]]
start end
[1,] 1 3
[2,] 6 7
[[2]]
start end
[1,] 2 4
[2,] 6 6
[[3]]
start end
[1,] 1 1
[[4]]
start end
[1,] 1 1
> str_sub_all(en_num_2,locate)
[[1]]
[1] "100" "10"
[[2]]
[1] "100" "5"
[[3]]
[1] "2"
[[4]]
[1] "2"
# 根据获取的位置提取子字符串,其实就等同于使用str_extract_all()函数获取的信息
> str_extract_all(en_num_2,"\\d+")
[[1]]
[1] "100" "10"
[[2]]
[1] "100" "5"
[[3]]
[1] "2"
[[4]]
[1] "2"
- 设置字符串(修改 插入) 给指定位置字符串进行赋值,实现对字符串的修改或插入(空白的地方)
> z3 <- "smile"
> str_sub(z3,1,0) <- "A";z3
[1] "Asmile"
> str_sub(z3,1,1) <- "As";z3
[1] "Assmile"
> str_sub(z3,-1) <- "ed";z3
[1] "Assmiled"
再来看 str_extract() 和 str_match() 函数。 因为涉及到比较多与正则表达式相关的内容,这里仅做部分用法和效果展示,后续在正则表达式部分会多次、详细记录、说明。
str_extract() 函数返回第一个完全匹配,以字符串向量形式输出;
str_extract_all() 函数返回每一个完全匹配,以list形式输出;
str_match() 函数返回第一个完全匹配及对应分组匹配的字符串矩阵;如对捕获组进行了命名,矩阵里也会显示对应列名。
str_match_all() 函数返回全部完全匹配及对应分组匹配的包含字符串矩阵的列表;
str_match()仅支持正则表达式,对应与正则表达式相关的内容,在后续篇幅里会详细展开。
来看几个例子,我们以前面例子messi 和neymar 字符串为例:
(vip <- c(messi, neymar))
[1] "https://sofifa.com/player/158023/lionel-messi/230033/"
[2] "https://sofifa.com/player/190871/neymar-da-silva-santos-jr/230033/"
# 看match 与 extract 在输出形式上的区别
# \\d+ 表示一个或多个数字
# 简单的提取匹配模式下,两者只在输出形式上存在区别,具体字符串内容是一致的。
> str_match(vip, "\\d+")
[1,] "158023"
[2,] "190871"
> str_extract(vip, "\\d+")
[1] "158023" "190871"
# 看有无_all的区别
> str_extract(vip, "\\d+")
[1] "158023" "190871"
> str_extract_all(vip, "\\d+")
[[1]]
[1] "158023" "230033"
[[2]]
[1] "190871" "230033"
# 同时提取ID和姓名
# str_match 函数比 str_extract 函数显得更暖男一点,总体和个体都提取,而且做分列处理
> str_match(vip, "(\\d+).((?:\\w+-)+\\w+)")
[,1] [,2]
[1,] "158023/lionel-messi" "158023"
[2,] "190871/neymar-da-silva-santos-jr" "190871"
[1,] "lionel-messi"
[2,] "neymar-da-silva-santos-jr"
> str_extract(vip, "(\\d+).((?:\\w+-)+\\w+)")
[1] "158023/lionel-messi"
[2] "190871/neymar-da-silva-santos-jr"
# 并且能进行命名
> str_match(vip, "(?<ID>\\d+).(?<Name>(?:\\w+-)+\\w+)")
[1,] "158023/lionel-messi" "158023"
[2,] "190871/neymar-da-silva-santos-jr" "190871"
[1,] "lionel-messi"
[2,] "neymar-da-silva-santos-jr"
- 移除替换
- str_remove():移除匹配的字符串
- str_replace():替换匹配的字符串,使用空值替换,就等于是移除
相对来讲这两个函数也是比较简单的。都默认支持正则表达式,str_remove()对第一个匹配的字符串进行移除,str_replace()对第一个匹配的字符串进行替换,替换为对应指定的字符串。
str_remove()函数有时也是str_extract()的有益补充,当需要提取的字符串无规律或不好批量操作,可以选择把有规律的一些内容删除掉,剩下的内容即时我们想要提取的内容。
str_remove_all()和str_replace_all() 则对全部匹配的字符串进行对应的移除和替换操作;以list的形式输出。
来看几个示例,使用前文中的字符串向量。
- str_remove()和str_remove_all()
> vip
[1] "https://sofifa.com/player/158023/lionel-messi/230033/"
[2] "https://sofifa.com/player/190871/neymar-da-silva-santos-jr/230033/"
#移除不是数字的字符串,直到数字出现为止
> str_remove(vip,"\\D+")
[1] "158023/lionel-messi/230033/"
[2] "190871/neymar-da-silva-santos-jr/230033/"
#移除全部不是数字的字符串,等同于提取数字字符串,
#但这些字符串会全部排在一起,以一个元素的形式呈现。
> str_remove_all(vip,"\\D+")
[1] "158023230033" "190871230033"
> str_extract_all(vip,"\\d+")
[[1]]
[1] "158023" "230033"
[[2]]
[1] "190871" "230033"
#提取数字字符串,分开返回;这是不一样的地方。
- str_replace()
这里我们想把上述字符串向量中小写字母人名直接替换成首字母大写的人名,顺便串联前文介绍的几个函数,来结束本小节。
逻辑方法是找到字符串中的人名所在的位置,按位置信息把他提取出来,然后使用对字符串进行转换处理,最后作为被替换参数植入str_replace()函数即可;
> pattern <- "((?:\\w+-)+\\w+)"
> str_locate_all(vip, pattern ) %>%
str_sub_all(vip, .) %>%
str_to_title() %>%
str_replace_all(vip, pattern, .)
[1] "https://sofifa.com/player/158023/Lionel-Messi/230033/"
[2] "https://sofifa.com/player/190871/Neymar-Da-Silva-Santos-Jr/230033/"
也可直接提取人名字符串操作。
> str_extract_all(vip, pattern ) %>%
str_to_title() %>%
str_replace_all(vip, pattern, .)
[1] "https://sofifa.com/player/158023/Lionel-Messi/230033/"
[2] "https://sofifa.com/player/190871/Neymar-Da-Silva-Santos-Jr/230033/"
1.4 字符串拼接拆分
这是关于stringr包函数介绍的最后一节,字符串的拆分拼接以及组合应用等,就是剩下的一些比较重要、常用的函数。
- str_c(): 字符串拼接
- str_flatten():压扁字符串,将字符串向量压减为字符串
- str_glue():使用"glue"进行插值,超级好用的一个函数,将向量中的变动值插入到字符串中,实现拼接插值效果。
这三个函数放在一起记录介绍,我们使用前文用到的fifa样本数据,展示上述三个函数的用法。
- 数据准备
fifa <- read.csv("./data/fifa23.csv") %>%
as_tibble() %>%
select(1,7,8,15) %>%
head(10)
fifa_pg <- fifa %>% mutate( Position_Group = case_when(Best.Position =="GK" ~ "GK",
str_detect(Best.Position, "B$") ~"DEF",
str_detect(Best.Position, "M$") ~ "MID",
TRUE ~ "FWD"), .after = Best.Position)
- 字符串拼接
# 人名及位置分组字符串向量
> (a <- fifa_pg$Known.As)
[1] "L. Messi" "K. Benzema" "R. Lewandowski"
[4] "K. De Bruyne" "K. Mbappé" "M. Salah"
[7] "T. Courtois" "M. Neuer" "Cristiano Ronaldo"
[10] "V. van Dijk"
> (b <- fifa_pg$Position_Group)
[1] "MID" "FWD" "FWD" "MID" "FWD" "FWD" "GK" "GK" "FWD" "DEF"
# 将人名及位置分组字符串拼接,中间用":"连接(也可以适用其他字符),这里向量化操作;
> ( c <- str_c(a,b, sep = " : "))
[1] "L. Messi : MID" "K. Benzema : FWD"
[3] "R. Lewandowski : FWD" "K. De Bruyne : MID"
[5] "K. Mbappé : FWD" "M. Salah : FWD"
[7] "T. Courtois : GK" "M. Neuer : GK"
[9] "Cristiano Ronaldo : FWD" "V. van Dijk : DEF"
- 将字符串向量拼接成一串字符串,在组合多个句子组成一段话或一篇文章时,这个函数效果很好;
> str_flatten(c, collapse = " , ")
[1] "L. Messi : MID , K. Benzema : FWD , R. Lewandowski : FWD , K. De Bruyne : MID , K. Mbappé : FWD , M. Salah : FWD , T. Courtois : GK , M. Neuer : GK , Cristiano Ronaldo : FWD , V. van Dijk : DEF"
-
字符串中拼接向量,使用
{}将向量传入到字符串中,具体使用方法及其他用途,可参考包帮助文档,
-
这函数来自
glue包,也可详细学习参考该包内容,是字符文本处理的一大利器,本文不做深入介绍。
> str_glue("Mwssi, known as {a[[1]]}, \n\n his position group is {b[[1]]}" )
Mwssi, known as L. Messi,
his position group is MID
> fifa_pg[1:3,] %>%
str_glue_data("\n\n {Known.As} is from {Nationality}, play for {Club.Name},\n he is a {Position_Group},and his best position is {Best.Position}.")
L. Messi is from Argentina, play for Paris Saint-Germain,
he is a MID,and his best postion is CAM.
K. Benzema is from France, play for Real Madrid CF,
he is a FWD,and his best postion is CF.
R. Lewandowski is from Poland, play for FC Barcelona,
he is a FWD,and his best postion is ST.
- str_split()
- str_unique()
str_split() 函数 类似str_c()函数的逆函数,能实现对字符串的拆分,这对于批量处理字符串很有帮助,比如我们有时候还会一股脑的爬取一些文本信息,爬取后再进行批量拆分处理。主要有以下四个函数:
- str_split()
- str_split_1()
- str_split_i()
- str_split_fixed()
我们用前文fifa数据样本做示例,记录上述函数的用法
(a <- fifa_pg$Known.As)
(b <- fifa_pg$Position_Group)
(n <- fifa_pg$Nationality)
(m <- fifa_pg$Best.Position)
(l <- str_c(a,b,m,n, sep = " : "))
(d <- str_flatten(c, collapse = " , "))
#str_split()返回列表
> str_split(l[1], " : ")
[[1]]
[1] "L. Messi" "MID" "CAM" "Argentina"
#指定拆分列数,超出部分不再拆分。
> str_split(l[1], " : ", 3)
[[1]]
[1] "L. Messi" "MID"
[3] "CAM : Argentina"
#str_split_fixed()返回矩阵
> str_split_fixed(l[1], " : ",4)
[,1] [,2] [,3] [,4]
[1,] "L. Messi" "MID" "CAM" "Argentina"
#str_split_1()对字符串进行处理,返回矩阵
> str_split_1(d, " , ") %>%
+ str_split(" : ")
[[1]]
[1] "L. Messi" "MID"
[[2]]
[1] "K. Benzema" "FWD"
[[3]]
[1] "R. Lewandowski" "FWD"
[[4]]
[1] "K. De Bruyne" "MID"
[[5]]
[1] "K. Mbappé" "FWD"
[[6]]
[1] "M. Salah" "FWD"
[[7]]
[1] "T. Courtois" "GK"
[[8]]
[1] "M. Neuer" "GK"
[[9]]
[1] "Cristiano Ronaldo" "FWD"
[[10]]
[1] "V. van Dijk" "DEF"
#str_split_i()返回第几个(倒数第几个用负数表示)
> str_split_i(d, " , ",-4)
[1] "T. Courtois : GK"
str_unique() 函数比较简单,就是unique()函数的str 版。 字符串去重功能。 只是增加了一些控制选项,比如大小写、字符串编码等。这里不一一展开。
> m