


链路追踪-Jaeger In Django

注意: Jaeger 是德语单词,猎人的意思,读做“耶格”
链路追踪背景
微服务的流行程度不需要我们多说,随着业务的扩张和规模的扩大,单体架构的支撑能力越来越有限。所以服务拆分成了必须的选择,而随着服务的增多,以前单体应用里的函数调用都变成了服务之间的请求与调用。随之而来的就是运维和问题定位难度也会变的很大。所以,我们就需要一个工具来帮助我们排查系统性能瓶颈和定位问题, 称他为 Tracing 吧,tracing能记录每次调用的过程和耗时。
Tracing简介
Tracing 在90年代就已经出现了,真正的老大是Google的 Dapper.随后出现了不少比较不错的 tracing 软件。比如StackDriver Trace (Google),Zipkin(twitter),鹰眼(taobao) 等等。
一般 tracing 系统核心组成都有:代码打点;数据发送;数据存储;数据查询展示。
在数据采集过程中,需要在代码中打点,并且不同系统的 API 并不兼容,这就导致了如果希望切换追踪系统,往往会带来较大改动成本。
Opentracing
为了解决不同的分布式追踪系统 API 不兼容的问题,诞生了 OpenTracing 规范。OpenTracing 是一个轻量级的标准化层,它位于应用程序/类库和追踪或日志分析程序之间。
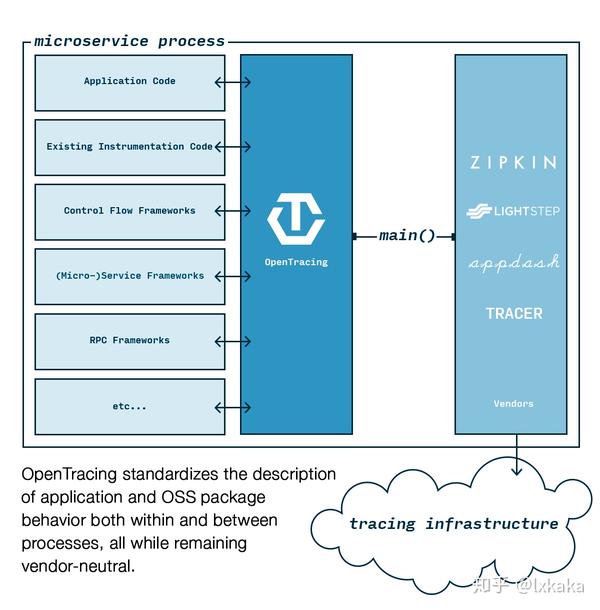

- opentracing 优点
* opentracing 进入了CNCF,为分布式追踪,提供统一的概念和数据标准。
* opentracing 通过提供平台无关、厂商无关的 API,使得开发人员能够方便的添加(或更换)追踪系统的实现。
-
opentracing 数据定义
两个核心组成 trace 和 span trace 是一次调用的统称(一条调用链),经过的各个服务生成一个 span, 多个 span 组成一个 trace。 span 与 span形成链式关系。 下图展示了两者的关系
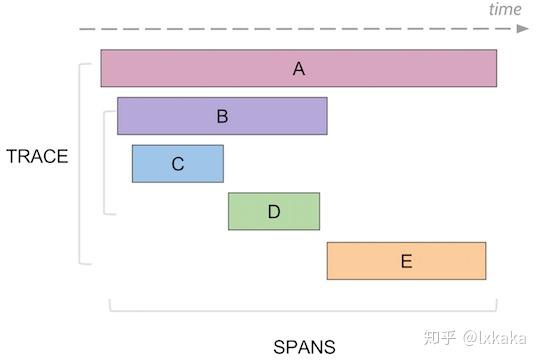

-
span
组成部分
- An operation name,操作名称
- A start timestamp,起始时间
- A finish timestamp,结束时间
- Span Tag,一组键值对构成的Span标签集合。键值对中,键必须为string,值可以是字符串,布尔,或者数字类型。
- Span Log,一组span的日志集合。 每次log操作包含一个键值对,以及一个时间戳。 键值对中,键必须为string,值可以是任意类型。 但是需要注意,不是所有的支持OpenTracing的Tracer,都需要支持所有的值类型。
- SpanContext,Span上下文对象 (下面会详细说明)
- References(Span间关系),相关的零个或者多个Span(Span间通过SpanContext建立这种关系) 每一个SpanContext包含以下状态:
- 任何一个OpenTracing的实现,都需要将当前调用链的状态(例如:trace和span的id),依赖一个独特的Span去跨进程边界传输
- Baggage Items,Trace的随行数据,是一个键值对集合,它存在于trace中,也需要跨进程边界传输 关于 OpenTracing 更多语义,请参考 OpenTracing语义标准 。
Jaeger架构
在 OpenTracing的实现中, Zipkin 和 Jaeger 是比较留下的方案。 在 Jaeger 和 Zipkin的对比中,我认为Jaeger的优势在: 更加cloud native(docker环境搭建更加方便,对kubernetes支持的更好) 支持的客户端更多,并且我觉得代码(python客户端)易读和清晰 * 组成架构更加科学(我喜欢)
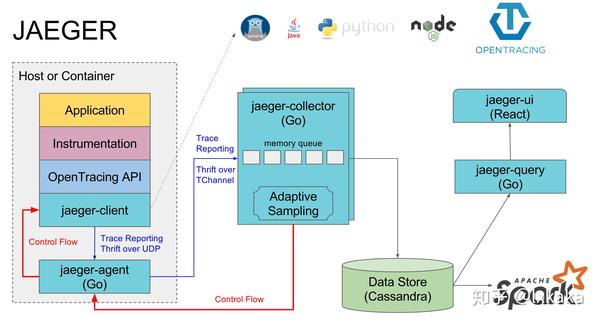
Jaeger 主要由以下几部分组成。
- Jaeger Client - 为不同语言实现了符合 OpenTracing 标准的 SDK。应用程序通过 API 写入数据,client library 把 trace 信息按照应用程序指定的采样策略传递给 jaeger-agent。
- Agent - 它是一个监听在 UDP 端口上接收 span 数据的网络守护进程,它会将数据批量发送给 collector。它被设计成一个基础组件,部署到所有的宿主机上。Agent 将 client library 和 collector 解耦,为 client library 屏蔽了路由和发现 collector 的细节。
- Collector - 接收 jaeger-agent 发送来的数据,然后将数据写入后端存储。Collector 被设计成无状态的组件,因此您可以同时运行任意数量的 jaeger-collector。 Data Store - 后端存储被设计成一个可插拔的组件,支持将数据写入 cassandra、elastic search。
- Query - 接收查询请求,然后从后端存储系统中检索 trace 并通过 UI 进行展示。Query 是无状态的,您可以启动多个实例,把它们部署在 nginx 这样的负载均衡器后面。 下图是 Jaeger官方文档的架构图

Jaeger搭建
- 本地测试
我们使用官方的 all-in-one image就可以运行一个完整的链路追踪系统。这种方式数据存在内存中,仅供我们用来本地开发和测试。
运行方式
docker run -d --name jaeger \
-e COLLECTOR_ZIPKIN_HTTP_PORT=9411 \
-p 5775:5775/udp \
-p 6831:6831/udp \
-p 6832:6832/udp \
-p 5778:5778 \
-p 16686:16686 \
-p 14268:14268 \
-p 9411:9411 \
jaegertracing/all-in-one:latest
访问 http://localhost:16686就能看到 jaeger的数据查询页
-
正式环境搭建 Jaeger目前支持的后代存储有 Cassandra 和 Elasticsearch, 因为我们已经有搭建好的 ES, 所以自然存储选择使用 ES.
-
agent
运行方式
version: "3"
services:
jaeger-agent:
image: jaegertracing/jaeger-agent
hostname: jaeger-agent
command: ["--collector.host-port=collector-host:14267"]
ports:
- "5775:5775/udp"
- "6831:6831/udp"
- "6832:6832/udp"
- "5778:5778"
networks:
- default
restart: on-failure
environment:
- SPAN_STORAGE_TYPE=elasticsearch- collector 和 query
可以搭建在同一个实例上
运行方式
version: "3"
services:
jaeger-collector:
image: jaegertracing/jaeger-collector
ports:
- "14269:14269"
- "14268:14268"
- "14267:14267"
- "9411:9411"
networks:
- default
restart: on-failure
environment:
- SPAN_STORAGE_TYPE=elasticsearch
command: [
"--es.server-urls=http:es-host:9200",
"--log-level=debug"
#depends_on:
# - elasticsearch
jaeger-query:
image: jaegertracing/jaeger-query
environment:
- SPAN_STORAGE_TYPE=elasticsearch
- no_proxy=localhost
ports:
- "16686:16686"
- "16687:16687"
networks:
- default
restart: on-failure
command: [
"--es.server-urls=http://es-host:9200",
"--span-storage.type=elasticsearch",
"--log-level=debug",
#"--query.static-files=/go/jaeger-ui/"
depends_on:
- jaeger-collector
networks:
elastic-jaeger:
driver: bridge数据简单展示图例


链路依赖关系图


Django接入
我们开发了自己的 jaeger-python 包(huipy),可以非常简单的在 Django 项目中使用。
接入方式
- 在中间件中引入
MIDDLEWARE = [
'huipy.tracer.middleware.TraceMiddleware',
# 其他中间件
'django.middleware.security.SecurityMiddleware',
'django.contrib.sessions.middleware.SessionMiddleware',
'corsheaders.middleware.CorsMiddleware',
'django.middleware.common.CommonMiddleware',
'django.contrib.auth.middleware.AuthenticationMiddleware',
'django.contrib.messages.middleware.MessageMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware',
settings.SERVICE_NAME = 'atlas'
# 其他配置
...- 在发送请求时引入
from huipy.tracer.httpclient import HttpClient
HttpClient(url='http://httpbin.org/get').get()线上部署问题
我们使用 uWSGI 作为 Django app 的容器, 默认的启动模式是 preforking 在 uWSGI 启动的时候,首先主进程会初始化并且load app, 然后会 fork 出指定数目的子进程。
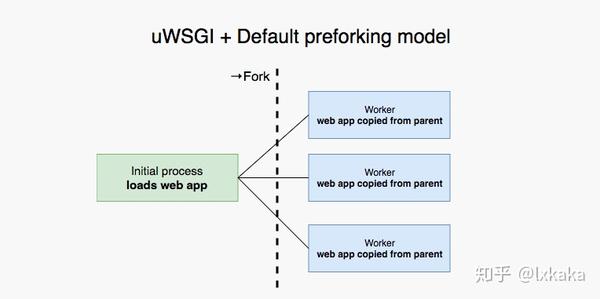

使用fork函数得到的子进程从父进程的继承了整个进程的地址空间,包括:进程上下文、进程堆栈、内存信息、打开的文件描述符、信号控制设置、进程优先级、进程组号、当前工作目录、根目录、资源限制、控制终端等。
这里提一下linux fork 使用的机制是
copy-on-write
(inux系统为了提高系统性能和资源利用率,for出一个新进程时,系统并没有真正复制一个副本。如果多个进程要读取它们自己的那部分资源的副本,那么复制是不必要的。每个进程只要保存一个指向这个资源的指针就可以了。如果一个进程要修改自己的那份资源的“副本”,那么就会复制那份资源)
在绝大多数场景下这种方式不会有问题, 但是当主进程本身是多线程的时候可能就会造成问题。
我们的 tracer初始化后会启动一个后台线程向agent 发送udp数据包,而这个过程在主进程 load app 的时候就完成了。fork子进程的时候这个后台线程当然是不会被fork的, 所以当子进程真正处理请求时,没有后台线程来发送数据。早造成的后果就是我们始终看不到我们请求的trace。
我们可以通过查看特定进程的系统调用来查看到信息:
首先是
preforking
模式,我们查看某一个 uWSGI进程的调用情况
# mac上使用 dtruss, linux使用 strace
sudo dtruss -p 1310
SYSCALL(args) = returnlazy-apps 模式
sudo dtruss -p 1509
SYSCALL(args) = return
gettimeofday(0x7000050F58E8, 0x0, 0x0) = 0 0
psynch_cvwait(0x105FABF80, 0xC2901000C2A00, 0x5B700) = -1 Err#316
gettimeofday(0x7000050F58E8, 0x0, 0x0) = 0 0
psynch_cvwait(0x105FABF80, 0xC2A01000C2B00, 0x5B700) = -1 Err#316
gettimeofday(0x7000050F58E8, 0x0, 0x0) = 0 0