


聊聊MySql8.0中的group by 和 max函数取最新(优)一条记录的问题

最近遇到一个业务场景,是一个一对多的表关系,A表关联B表,然后取B表中最新的一条记录结果与A表中数据进行组合返回;
刚看到这个业务的时候脑子里一溜烟解题思路就出来了,于是也很快的将SQL写完了,再对比结果的时候发现存在一些数据误差;才明白在写SQL的时候忽略了一些细节,导致出现了数据误差;
聊到这里,不得不聊一个比较经典的统计学生考试成绩的问题了;有一张学生成绩表,记录了学生在考试中各科成绩情况,需要根据不同业务场景查询出对应的数据;数据如下:
-- 表结构
DROP TABLE IF EXISTS `my_test`;
CREATE TABLE `my_test` (
`id` int(0) NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL COMMENT '学生姓名',
`type` varchar(255) NOT NULL COMMENT '科目',
`score` int(0) NOT NULL COMMENT '成绩',
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=13 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='考试科目分数表';
-- 初始化数据
INSERT INTO `my_test` VALUES (1, '张三', '数学', 67);
INSERT INTO `my_test` VALUES (2, '李四', '数学', 20);
INSERT INTO `my_test` VALUES (3, '王五', '数学', 63);
INSERT INTO `my_test` VALUES (4, '张三', '语文', 88);
INSERT INTO `my_test` VALUES (5, '李四', '语文', 78);
INSERT INTO `my_test` VALUES (6, '王五', '语文', 68);
INSERT INTO `my_test` VALUES (7, '张三', '化学', 70);
INSERT INTO `my_test` VALUES (8, '李四', '化学', 80);
INSERT INTO `my_test` VALUES (9, '王五', '化学', 100);
INSERT INTO `my_test` VALUES (10, '赵六', '化学', 100);
数据呈现如下:
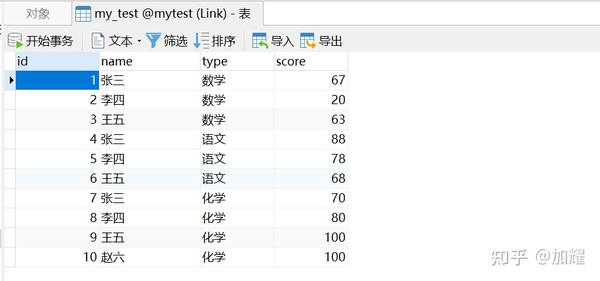
问题: 按科目查询最优成绩及学生
现需要统计出每个科目中分数最高的同学名字及对应的分数;按照我最开始的思路就是简单的根据科目分组,然后取最优成绩的记录即可,SQL及对应的结果集如下:
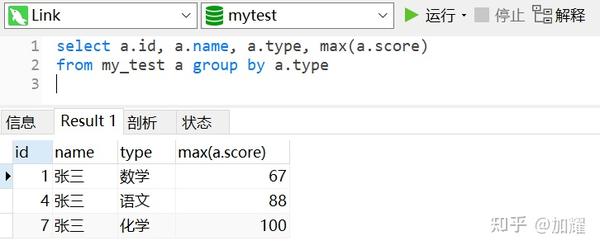

不过对比原数据会发现,在化学这一科目上的学生信息是不对的;化学科目成绩最优的学员应该是 王五和赵六;再回过头来分析一下这个sql会发现, 在mysql中的group by函数,默认分组后取的第一条数据为根据聚簇索引分组得来的第一条记录 ;
简单来说,也就是分组后id升序的第一条记录;可以在上一sql中再多加一个字段,执行结果如下:
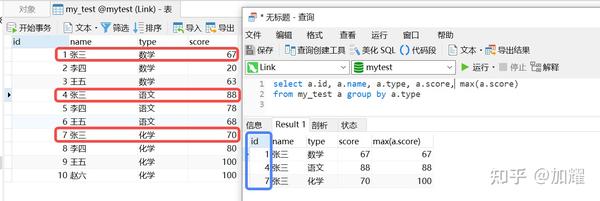
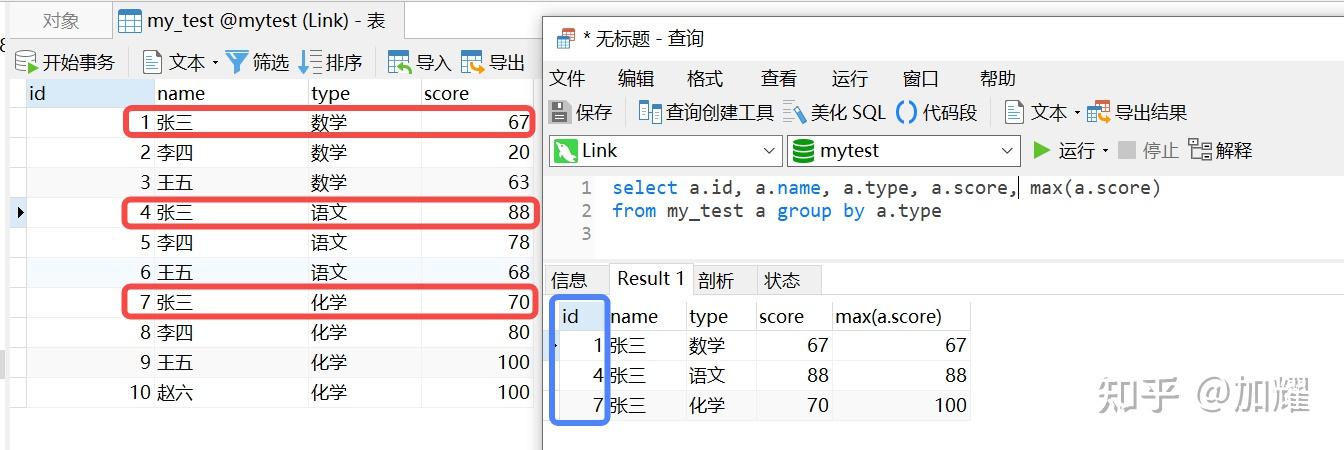
由于我这边的数据库表采用的是自增id,group by 函数分组后,取的是分组后id升序的第一条数据;
验证group by函数取值聚簇索引
为了验证一下在上面所提到的 在mysql中的group by函数,默认分组后取的第一条数据为根据聚簇索引分组得来的第一条记录 这一说法,我这边重新建了一张表,不指定主键,并且将上述数据的第一条调整顺序为最后一条;
完整SQL如下:
-- 建表语句,无主键
CREATE TABLE `my_test_2` (
`id` int NOT NULL,
`name` varchar(255) NOT NULL COMMENT '学生姓名',
`type` varchar(255) NOT NULL COMMENT '科目',
`score` int NOT NULL COMMENT '成绩'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci ROW_FORMAT=DYNAMIC COMMENT='考试科目分数表';
-- 插入数据并置换第一条的顺序
INSERT INTO `my_test_2` VALUES ('2', '李四', '数学', 20);
INSERT INTO `my_test_2` VALUES ('3', '王五', '数学', 63);
INSERT INTO `my_test_2` VALUES ('4', '张三', '语文', 88);
INSERT INTO `my_test_2` VALUES ('5', '李四', '语文', 78);
INSERT INTO `my_test_2` VALUES ('6', '王五', '语文', 68);
INSERT INTO `my_test_2` VALUES ('7', '张三', '化学', 70);
INSERT INTO `my_test_2` VALUES ('8', '李四', '化学', 80);
INSERT INTO `my_test_2` VALUES ('9', '王五', '化学', 100);
INSERT INTO `my_test_2` VALUES ('10', '赵六', '化学', 100);
INSERT INTO `my_test_2` VALUES ('1', '张三', '数学', 67);
此时,再执行上述SQL,可以得到以下结果:
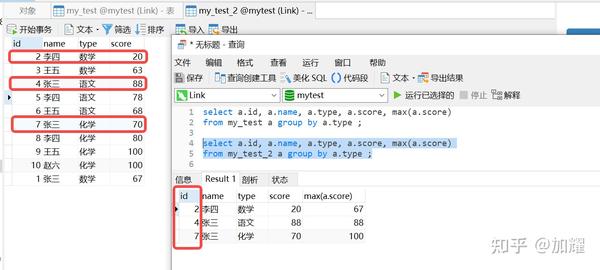
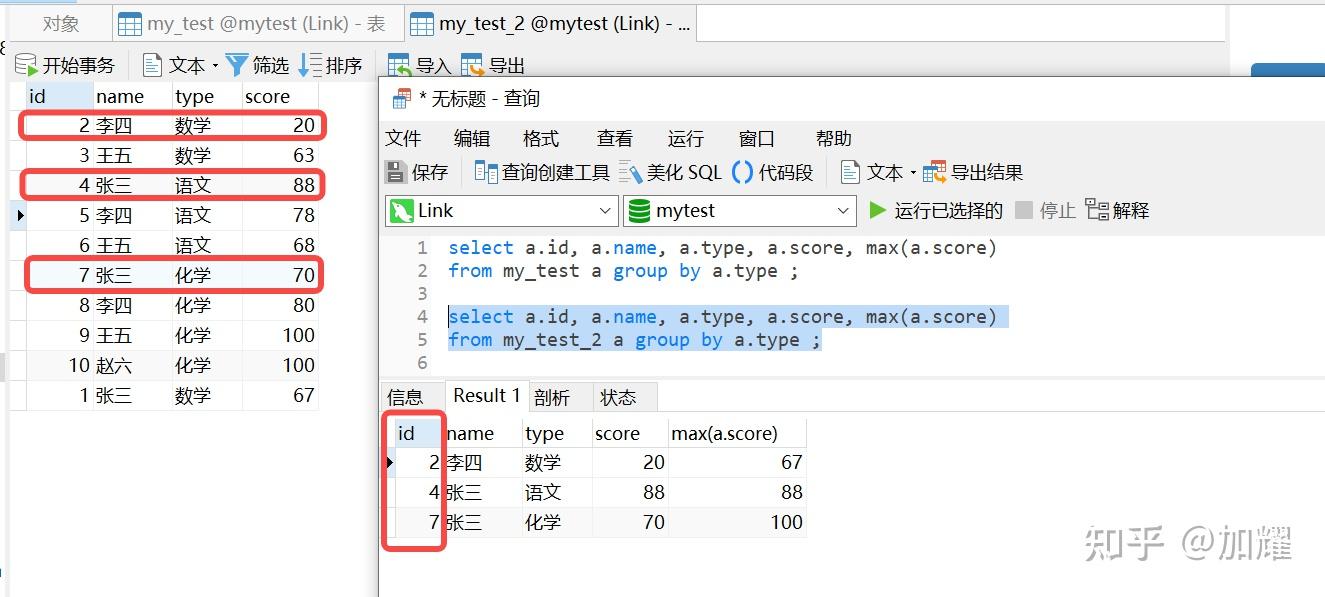
可以看到,其执行结果集与上一执行较为相似,都是取值与根据科目分组后的第一条记录;当数据库中有指定主键或者是存在唯一索引时,mysql采用主键或者是唯一索引且唯一索引字段为数值类型且存在非空约束作为聚簇索引,否则mysql会采用隐藏id(_rowid)作为聚簇索引;
小知识:当有主键并且主键时数值类型的时候,可以使用列 "_rowid"显示展示隐藏列id;同理,当无主键但是有唯一索引并且唯一索引为数值类型并且字段有非空约束时,也可以使用相同的方式进行查询; 联合唯一索引不行;
由此可以验证 在mysql中的group by函数,默认分组后取的第一条数据为根据聚簇索引分组得来的第一条记录 这一说法;
查询每科目最优成绩及学生
方案一: 采用先排序后分组
还是回到上述案例中,基于上面的sql的前提下,我们可以考虑先给考试成绩按照分数从高到低按照分数排个序,得到一张临时表;
然后基于group by 的取值取聚簇索引的第一条的特性,我们再将得到的临时表进行group by ,这时候理论上就可以得到我们想要的数据了;
思路有了,即可开工;很很容易就可以得到如下的sql:
select co.* from (
-- 先根据总分数降序排序,得到临时表
select a.* from my_test a order by a.score desc
) as co group by co.type
通过上述sql语法进行查询后,依旧没有得到期望值;我在想,是否是因为采用了select *导致子查询中并没有产生临时表,导致查询结果依旧是按照表my_test的原数据的形式进行查询的;
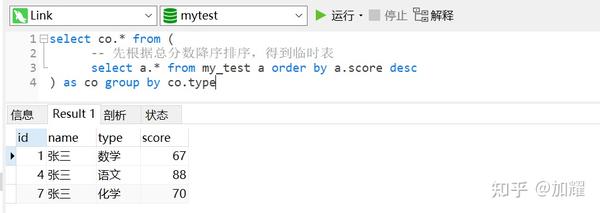
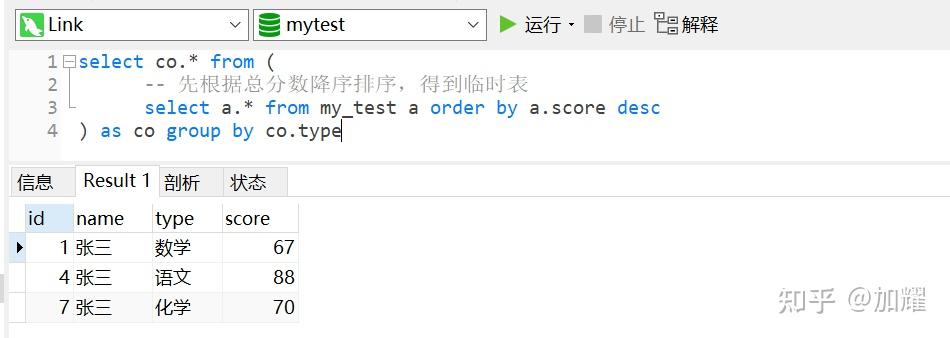
按理来说,当子查询中得到一张排好序的临时表,再采用group by分组,应该会根据分组取第一条记录的,就可以得到预期结果值的;
通过执行计划,看到上述SQL只有一条执行计划,按理说应该会有两条的,先有一条子查询,然后再一条对子查询进行查询的查询;
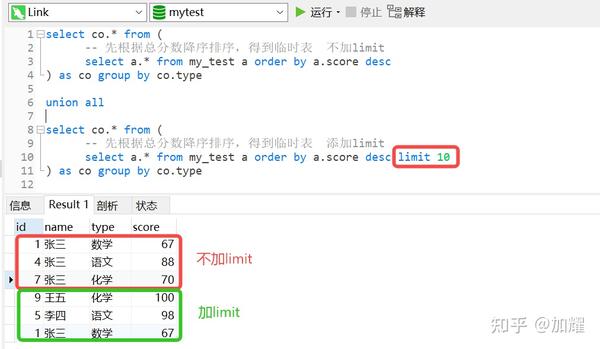
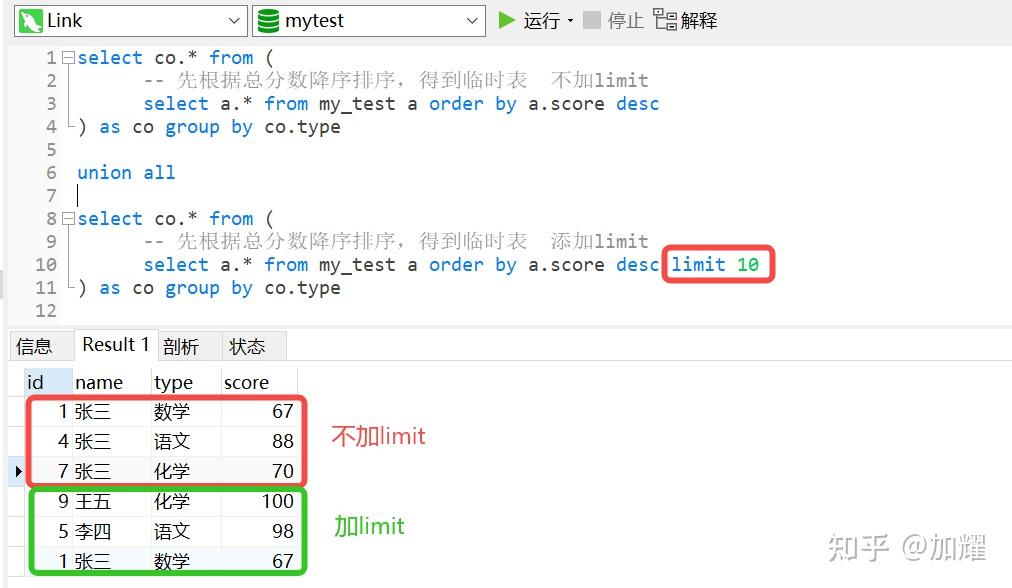
上网查询了一下,需要在上述子查询中添加一个limit条件,添加了limit条件后,得到的结果确实和预期结果是一样的;如下:
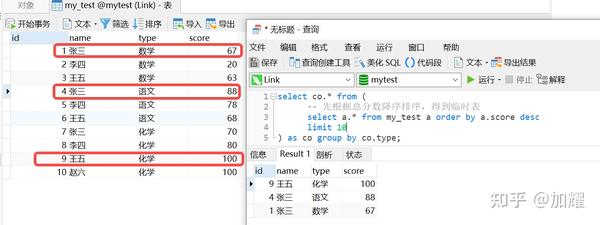
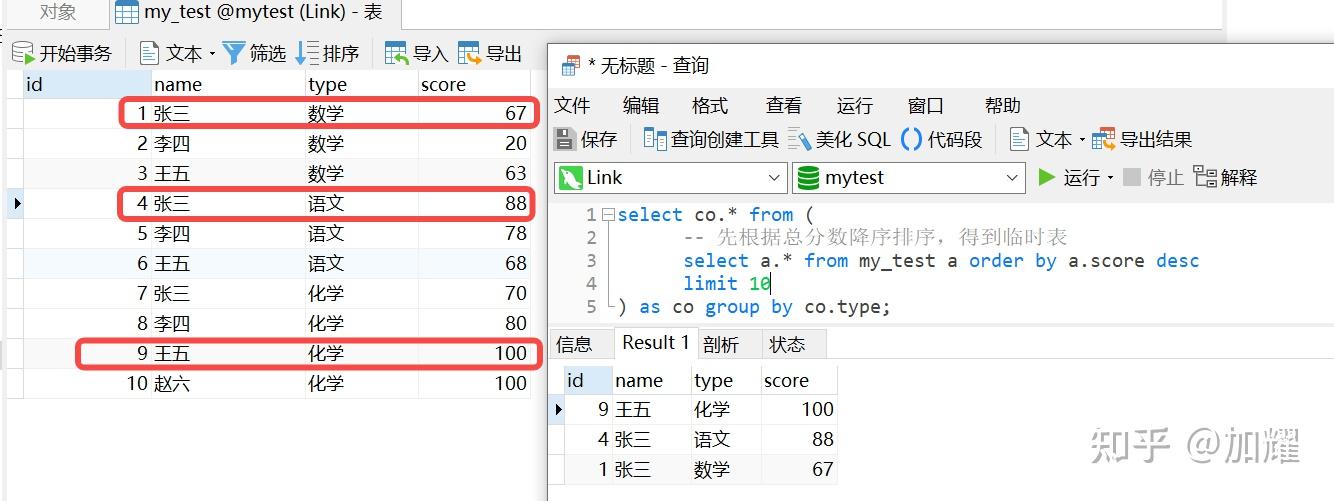
再次通过执行计划进行查看,可以看到在上述sql中,添加了Limit条件后,产生了两条执行计划
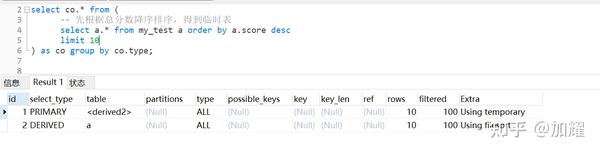
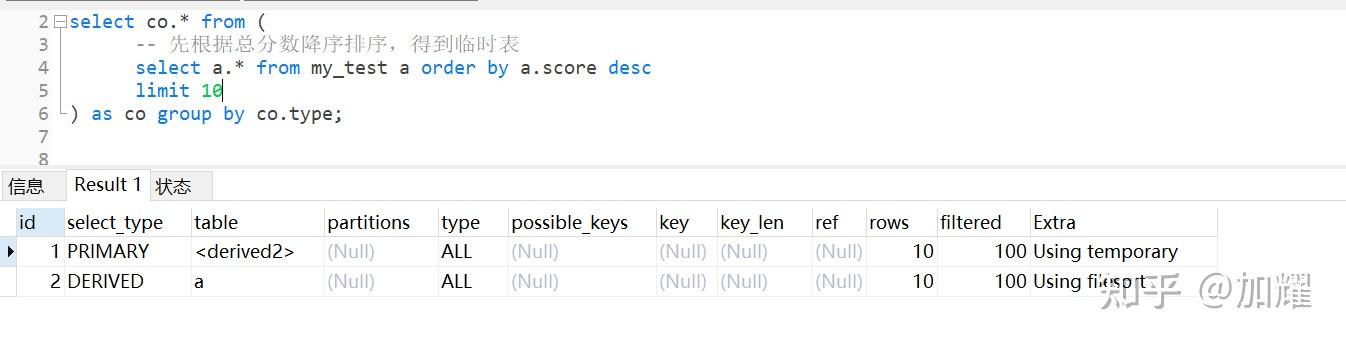
在上述执行计划中,根据id值越大优先级越高,先执行子查询,然后对子查询的结果进行分组,得到一张临时表;
比较好奇的是,为什么在这个SQL语法的子查询中,添加一个limit就可以查询出预期结果,通过对比子查询的执行计划,并没有发现有什么不一样的;
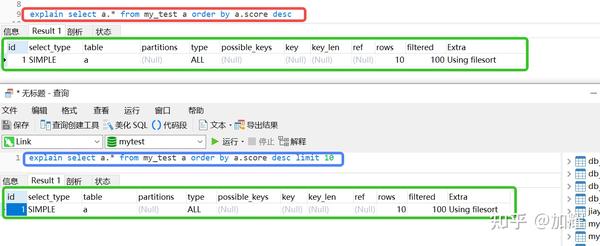
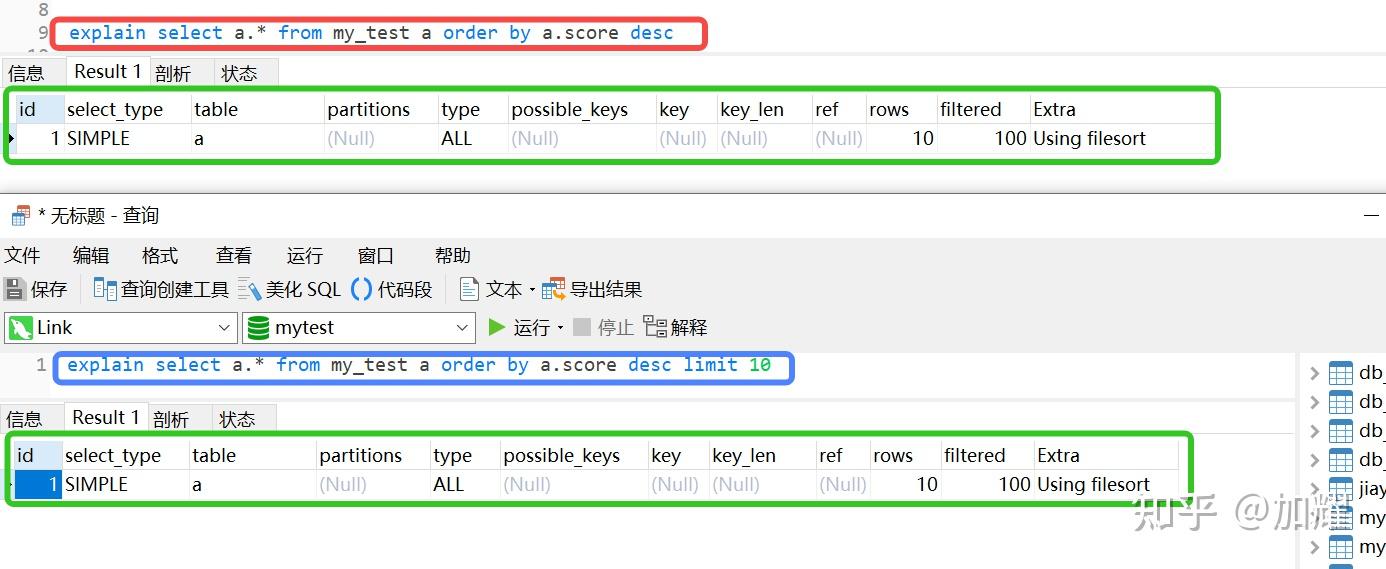
查阅了很多的资料,依然没有找到问题所在,由于我本地采用的是MySql8.0版本,并且关闭了默认的严格模式;我 分别尝试了在MySql8.0.25和MySql5.7.22版本 上,手动开启严格模式,然后再执行上述sql,问题依旧没有得到解决;
-- 开启会话级严格模式
set sql_mode="NO_AUTO_VALUE_ON_ZERO,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION,PIPES_AS_CONCAT,ANSI_QUOTES";
-- 查看会话级
select @@session.sql_mode;
-- 查看全局
select @@global.sql_mode;
-- 查看MySql版本号
select version();
select co.* from (
-- 先根据总分数降序排序,得到临时表