


concat、append、merge、join、combine_first

concat、append、merge、join、combine_first
数据合并中,通常都会用到以上的几个函数,譬如,在titanic项目中,要合并train_df, test_ df,可以是这样
train_df=pd.read_csv("E:/python/titanic/train.csv")
test_df=pd.read_csv("E:/python/titanic/test.csv")
df=pd.concat([train_df,test_df])
print(type(df))
<class 'pandas.core.frame.DataFrame'>也可以是这样
full=train_df.append(test_df,ignore_index=True)
print(type(full))
<class 'pandas.core.frame.DataFrame'>以上的这些函数,他们之间又有什么异同呢?
一、Concat: 合并多个数组
简单的合并可以通过Pandas中的concat函数来实现的。
concat 可横向按行合并,可纵向按列合并
pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False,
keys=None, levels=None, names=None, verify_integrity=False,
copy=True)obs: 带合并的对象集合,可以是Series,DataFrame
axis: {0,1....}合并方向,默认为0,表示纵向,1表示横向;
join: {inner,outer}:合并方式,默认为outer,表示并集;inner表示交集;
join_axes: 按哪些对象的索引保存;
ignore _ i ndex :{False,True},是否忽略原 index,默认为不忽略
keys: 为原始dataframe添加一个键,默认为无
1、 result=pd.concat(frames)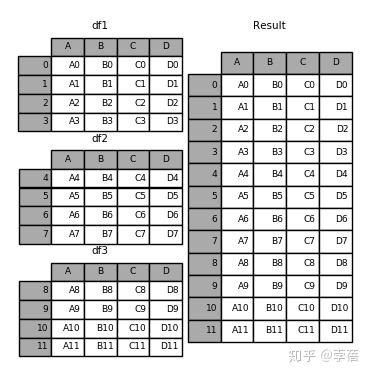
代码示例:
eg:列相连,索引保持原状
>>> s1 = pd.Series(['a', 'b'])
>>> s2 = pd.Series(['c', 'd'])
>>> pd.concat([s1, s2])
0 a
1 b
0 c
1 d
dtype: object
>>> pd.concat([s1, s2], ignore_index=True) #重新建立索引
0 a
1 b
2 c
3 d
dtype: object
2、 result = pd.concat(frames, keys=['x', 'y', 'z']) 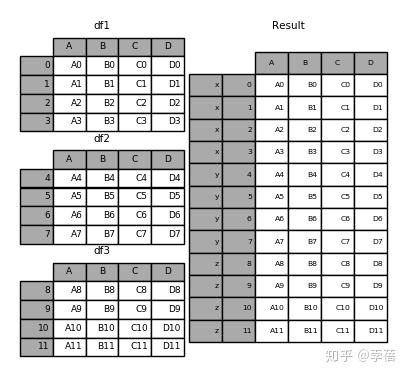
代码示例:
>>> pd.concat([s1, s2], keys=['s1', 's2',]) #增加新的keys
s1 0 a
1 b
s2 0 c
1 d
dtype: object
>>> pd.concat([s1, s2], keys=['s1', 's2'],
... names=['Series name', 'Row ID']) #新增列名
Series name Row ID
s1 0 a
1 b
s2 0 c
1 d
dtype: object
result.ix['y']
Out[7]:
A B C D
4 A4 B4 C4 D4
5 A5 B5 C5 D5
6 A6 B6 C6 D6
7 A7 B7 C7 D7
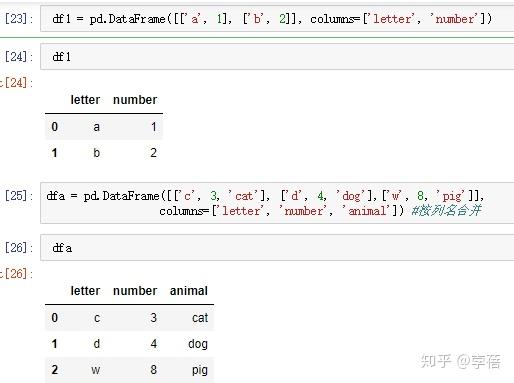
3、 result=pd.concat([df1, df2],axis=1)
#横向链接(按照index连接),这里是把所有的元素联接接在一起: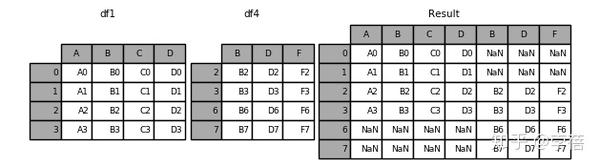

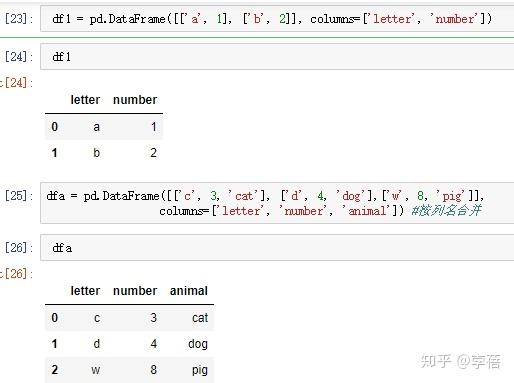
>>> df1 = pd.DataFrame([['a', 1], ['b', 2]],
... columns=['letter', 'number'])
letter number
0 a 1
1 b 2
>>> df2 = pd.DataFrame([['c', 3], ['d', 4]],
... columns=['letter', 'number']) #注意这里是列名
letter number
0 c 3
1 d 4
>>> pd.concat([df1, df2])
letter number
0 a 1
1 b 2
0 c 3
1 d 4
>>> df3 = pd.DataFrame([['c', 3, 'cat'], ['d', 4, 'dog']],
... columns=['letter', 'number', 'animal']) #按列名合并
letter number animal
0 c 3 cat
1 d 4 dog
>>> pd.concat([df1, df3])
animal letter number
0 NaN a 1
1 NaN b 2
0 cat c 3
1 dog d 4
>>>dfa = pd.DataFrame([['c', 3, 'cat'], ['d', 4, 'dog'],['w', 8, 'pig']],
... columns=['letter', 'number', 'animal']) #按列名合并
letter number animal
0 c 3 cat
1 d 4 dog
2 w 8 pig
>>>pd.concat([df1,dfa])
animal letter number
0 NaN a 1
1 NaN b 2
0 cat c 3
1 dog d 4
2 pig w 8
>>>pd.concat([df1,dfa],ignore_index=True)
animal letter number
0 NaN a 1
1 NaN b 2
2 cat c 3
3 dog d 4
4 pig w 8
axis=1,按照索引来合并
5、result = pd.concat([df1, df4], axis=1, join_axes=[df1.index])

>>> df4 = pd.DataFrame([['bird', 'polly'], ['monkey', 'george']],
columns=['animal', 'name'])
animal name
0 bird polly
1 monkey george
letter number
0 a 1
1 b 2
>>> pd.concat([df1, df4], axis=1)
letter number animal name
0 a 1 bird polly
1 b 2 monkey george
6.result = pd.concat([df1, s1], axis=1)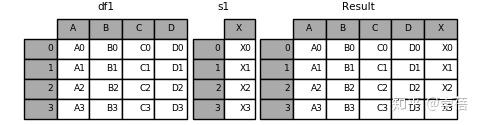

7.result = pd.concat([df1, s2, s2, s2], axis=1)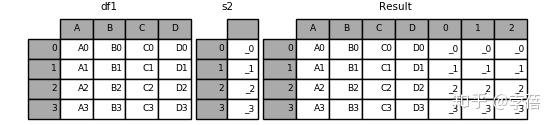

8.result = pd.concat([df1, s1], axis=1, ignore_index=True)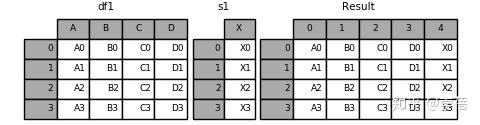

二、append:附加;贴上
横向和纵向同时扩充,不考虑columns和index
1、向数据框添加序列
In [1]: s2 = pd.Series(['X0', 'X1', 'X2', 'X3'], index=['A', 'B', 'C', 'D'])
In [2]: result = df1.append(s2, ignore_index=True)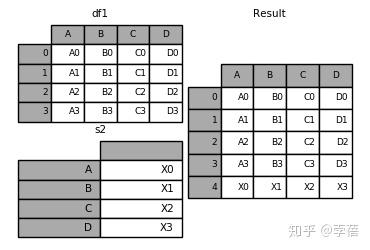
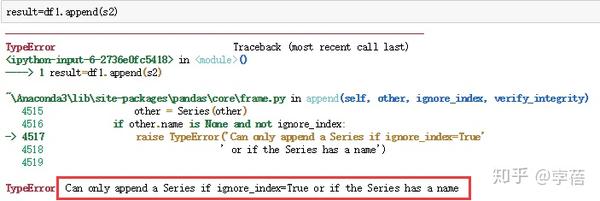

# 此刻你需要使用ignore_index,丢弃DataFrame的索引;如果你还想保存该索引,
则应该构造一个适当的DataFrame,并追加这些对象。
2、向数据框添加字典
result = df1.append(dicts, ignore_index=True)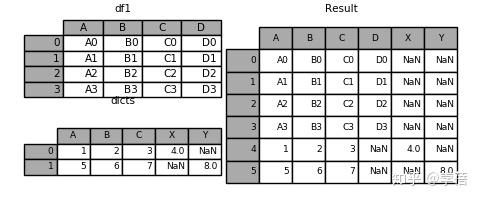

3、向数据框添加数据框
3.1 result = df1.append(df2)
>>> df = pd.DataFrame([[1, 2], [3, 4]], columns=list('AB'))
0 1 2
1 3 4
>>> df2 = pd.DataFrame([[5, 6], [7, 8]], columns=list('AB'))
>>> df.append(df2)
0 1 2
1 3 4
0 5 6
1 7 8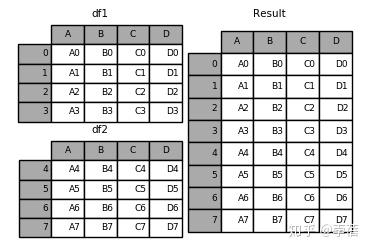
3.2、result= df1.append(df4)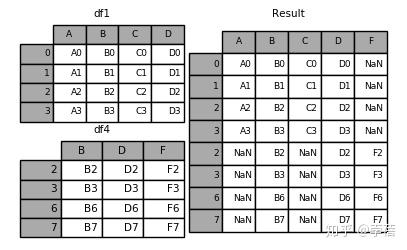
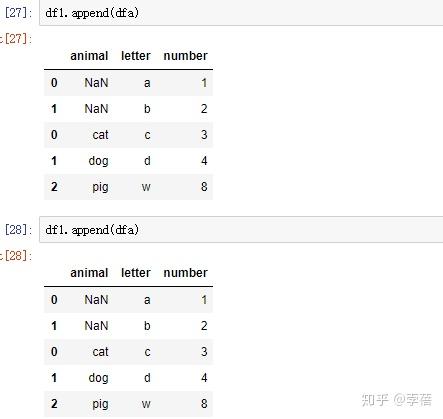

3.3 可同时添加两个数据框
result = df1.append([df2, df3])3.4 添加数据框以后重新排列索引
result = df1.append(df4, ignore_index=True)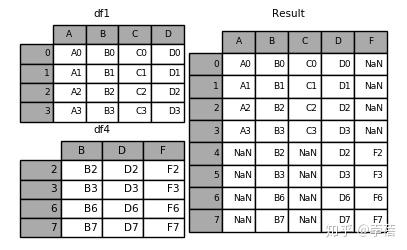
三、merge
merge 函数通过一个或多个键来将数据集的行连接起来。该函数的应用场景是针对同一个主键存在两张包含不同特征的表,通过该主键的链接,将两张表进行合并。合并之后,两张表的行数没有增加,列数是两张表的列数之和减一。
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,
suffixes=('_x', '_y'), copy=True, indicator=False)当两个数据集合并的列名不相同时用 left_on,right_on
on=None: 指定连接的列名,若两列希望连接的列名不一样,可以通过left_on和right_on 来具体指定,不指定时pandas会自动找到相同名字的列
how=’inner’,参数指的是左右两个表主键那一列中存在不重合的行时,取结果的方式:inner表示交集,outer 表示并集,left 和right 表示取某一边。
1、
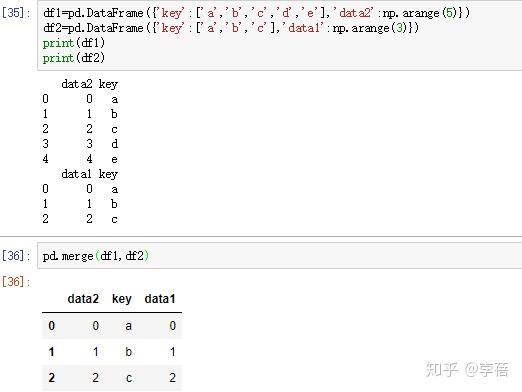

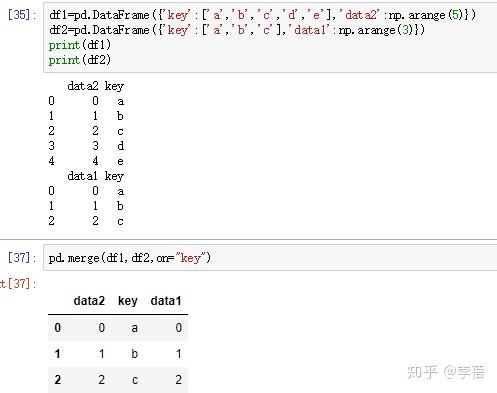
2. result = pd.merge(left, right, on='key')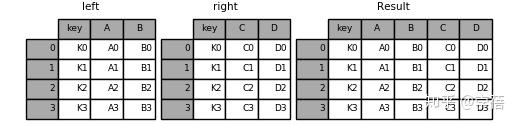


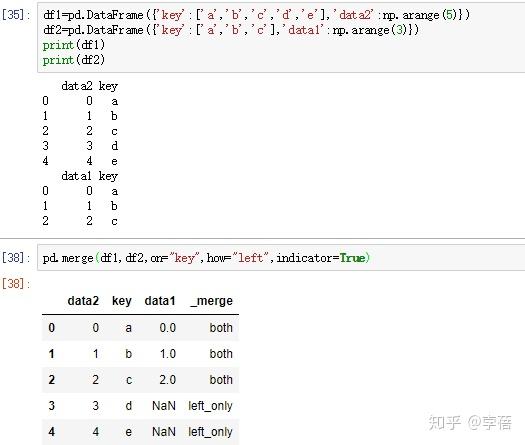
3、通过indicator表明merge的方式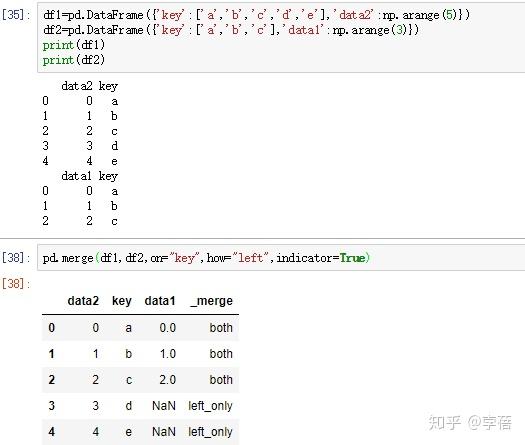
4.多条件合并
result = pd.merge(left, right, on=['key1', 'key2'])

result = pd.merge(left, right, how='left', on=['key1', 'key2'])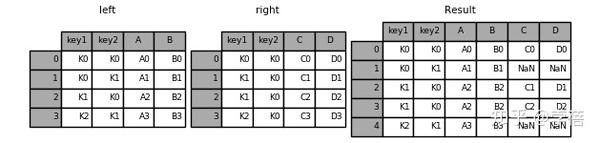

result = pd.merge(left, right, how='right', on=['key1', 'key2'])

5、result = pd.merge(left, right, how='outer', on=['key1', 'key2'])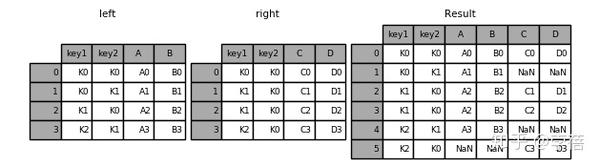

6、result = pd.merge(left, right, how='inner', on=['key1', 'key2'])7、多数据集合并
是针对合并后的数据再合并,不是一次性合并几个数据集
df1=pd.DataFrame({'key':['a','b','c','d','e'],'data1':np.arange(5)})
df2=pd.DataFrame({'key':['a','b','c'],'data2':np.arange(3)})
df3=pd.DataFrame({'key':['a','b','c','d'],'data3':np.arange(4)})
data=pd.merge(pd.merge(df1,df2,on='key',how='left'),df3,on='key',how='left')
In [55]: data
Out[55]:
data1 key data2 data3
0 0 a 0.0 0.0
1 1 b 1.0 1.0
2 2 c 2.0 2.0
3 3 d NaN 3.0
4 4 e NaN NaN四、join
In [1]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
'B': ['B0', 'B1', 'B2']},
index=['K0', 'K1', 'K2'])
In [2]: right = pd.DataFrame({'C': ['C0', 'C2', 'C3'],
'D': ['D0', 'D2', 'D3']},
index=['K0', 'K2', 'K3'])
In [3]: result = left.join(right)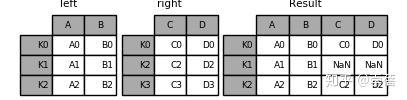
In [4]: result = left.join(right, how='outer')
#这与merge的以下用法相似
result = pd.merge(left, right, left_index=True, right_index=True, how='outer')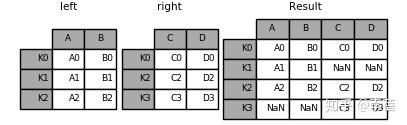
result = left.join(right, how='inner')
#这与merge的以下用法相似
result = pd.merge(left, right, left_index=True, right_index=True, how='inner');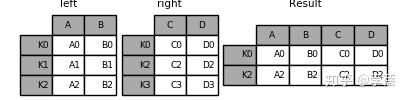
result = pd.concat([df1, df4], axis=1, join_axes=[df1.index])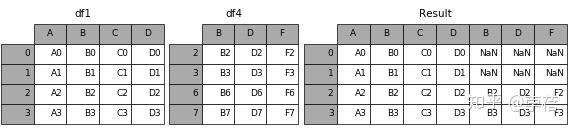

四、combine
若df1的数据缺失,则用df2的数据值填充df1的数据值
df1 = pd.DataFrame([[1, np.nan]])
df2 = pd.DataFrame([[3, 4]])
0 1 NaN
0 3 4
df1.combine_first(df2)
0 1 4.0
a=pd.Series([np.nan,2.5,np.nan,3.5,4.5,np.nan],index=['f','e','d','c','b','a'])
b=pd.Series([1,np.nan,3,4,5,np.nan],index=['f','e','d','c','b','a'])
print(a)
print(b)
f NaN
e 2.5
d NaN
c 3.5
b 4.5
a NaN
dtype: float64
f 1.0
e NaN
d 3.0
c 4.0
b 5.0
a NaN
dtype: float64
b.combine_first(a)
f 1.0