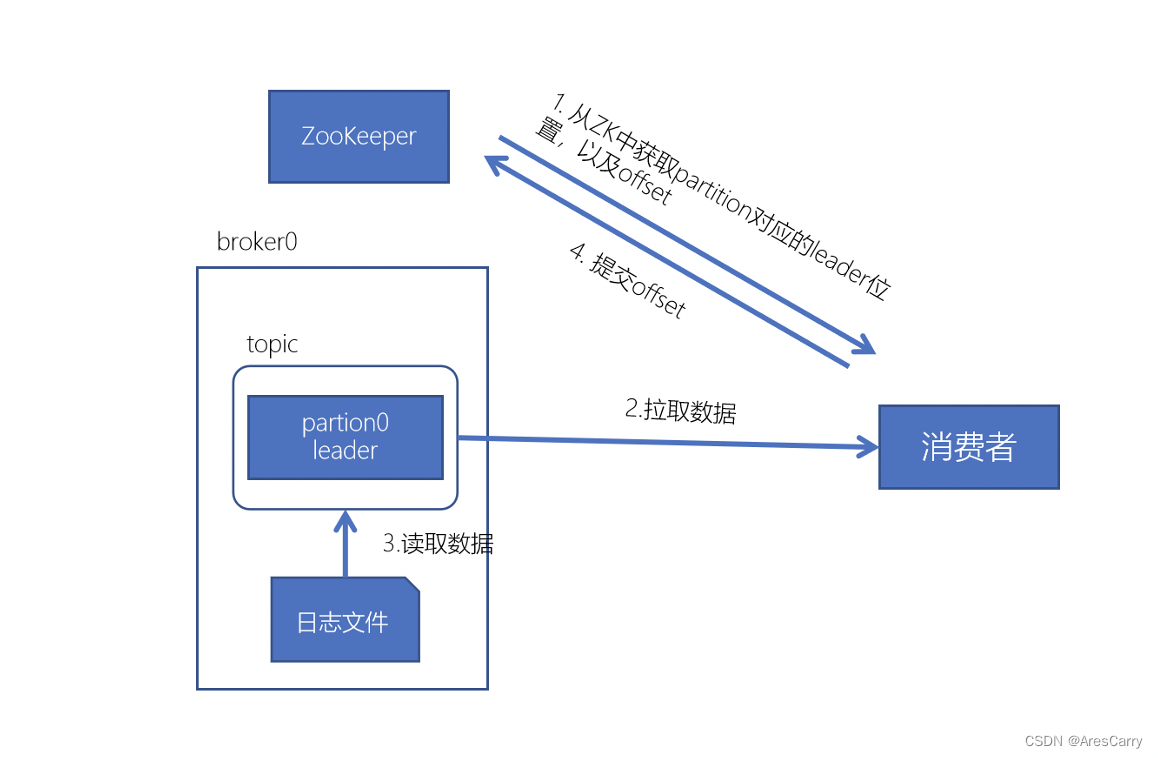
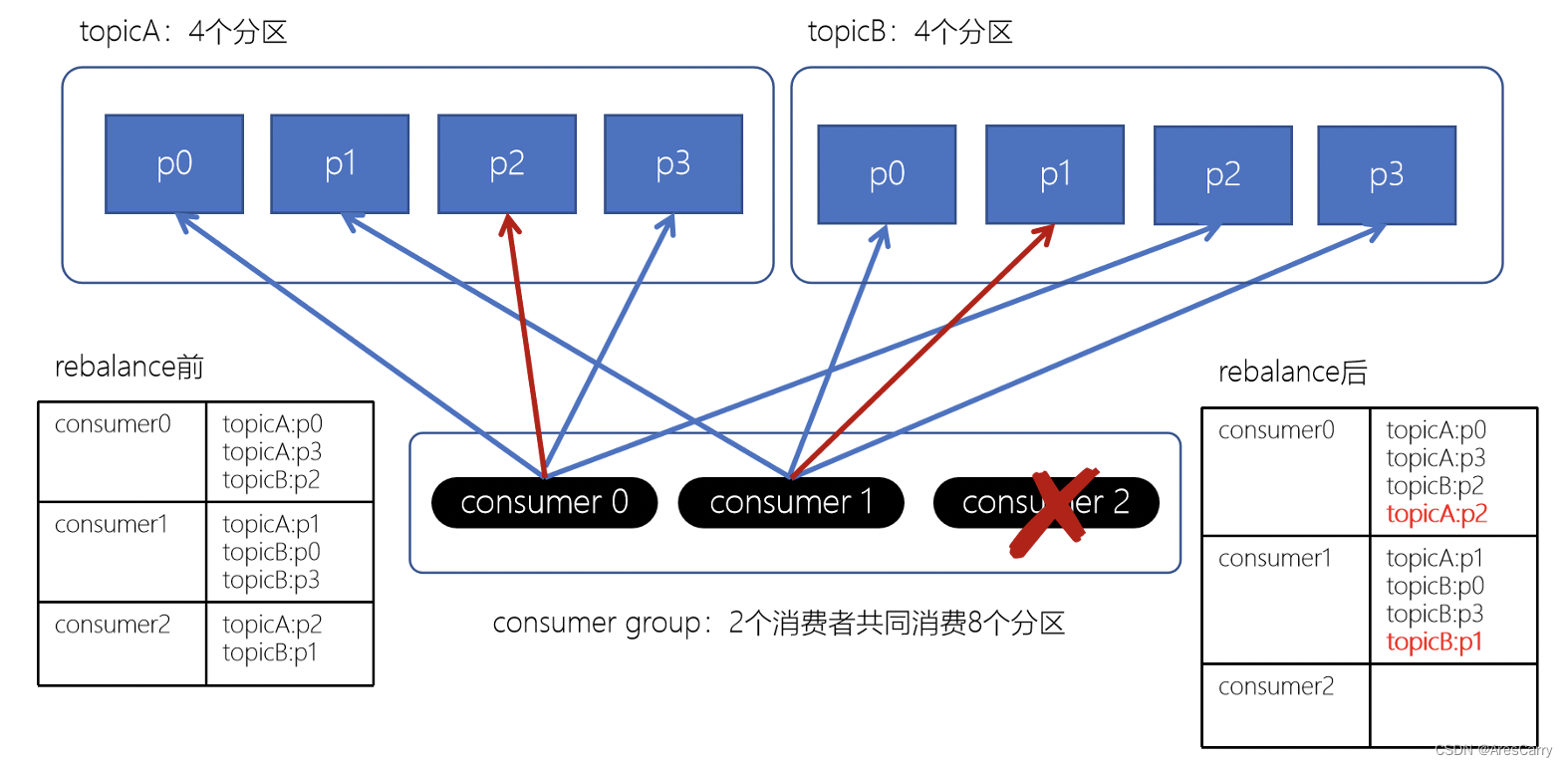
频繁出现rebalence,可能是消费者的消费时间过长,超过一定时间(max.poll.interval.ms设置的值,默认5分钟)未进行poll拉取消息,则会导致客户端主动离开队列,而引发Rebalance。
import com.ctrip.framework.apollo.ConfigService;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.annotation.EnableKafka;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.config.KafkaListenerContainerFactory;
import org.springframework.kafka.core.DefaultKafkaConsumerFactory;
import org.springframework.kafka.listener.ConcurrentMessageListenerContainer;
import java.util.HashMap;
import java.util.Map;
@Configuration
@EnableKafka
public class BehaviorConsumerConfig {
public Map<String, Object> consumerConfigs() {
Map<String, Object> propsMap = new HashMap<>();
propsMap.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, servers);
propsMap.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, enableAutoCommit);
propsMap.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
propsMap.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, autoCommitInterval);
propsMap.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, autoOffsetReset);
propsMap.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
propsMap.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
propsMap.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, maxPollRecordsConfig);
propsMap.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, org.apache.kafka.clients.consumer.StickyAssignor.class);
propsMap.put("security.protocol", protocol);
propsMap.put("ssl.truststore.location", truststoreLocation.replaceAll("file://", ""));
propsMap.put("ssl.truststore.password", truststorePassword);
propsMap.put("login.config.location", loginConfigLocation);
propsMap.put("sasl.mechanism", mechanism);
return propsMap;
@Bean("batchContainerFactory")
KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<String, String>> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(new DefaultKafkaConsumerFactory<>(consumerConfigs()));
factory.setConcurrency(4);
factory.getContainerProperties().setPollTimeout(3000);
factory.setBatchListener(true);
return factory;
本篇我们基本上把消费者的消费梳理干净了,以及消费会遇到的 重复消费,顺序消费,延迟消费等问题都也解释了给出了解决方案。方案一通百通。
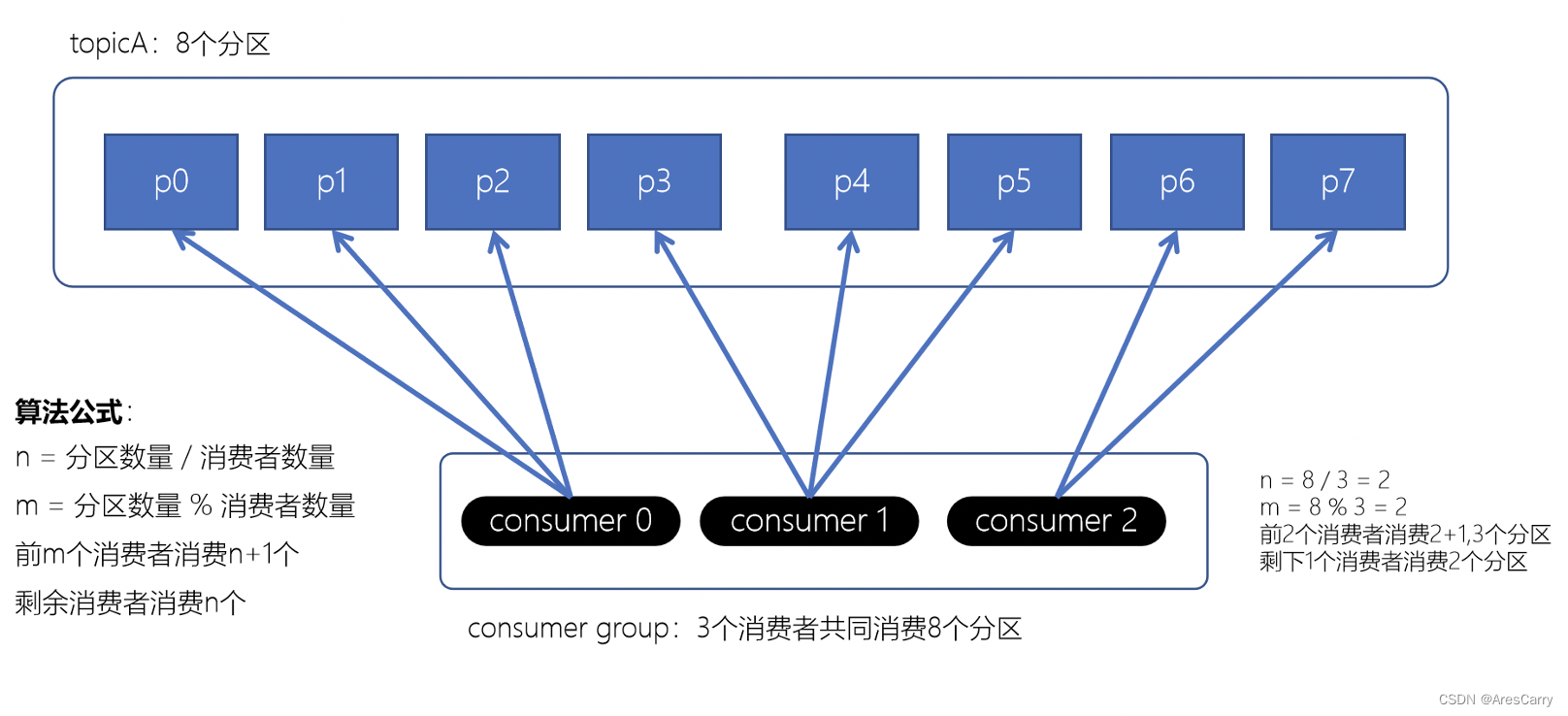
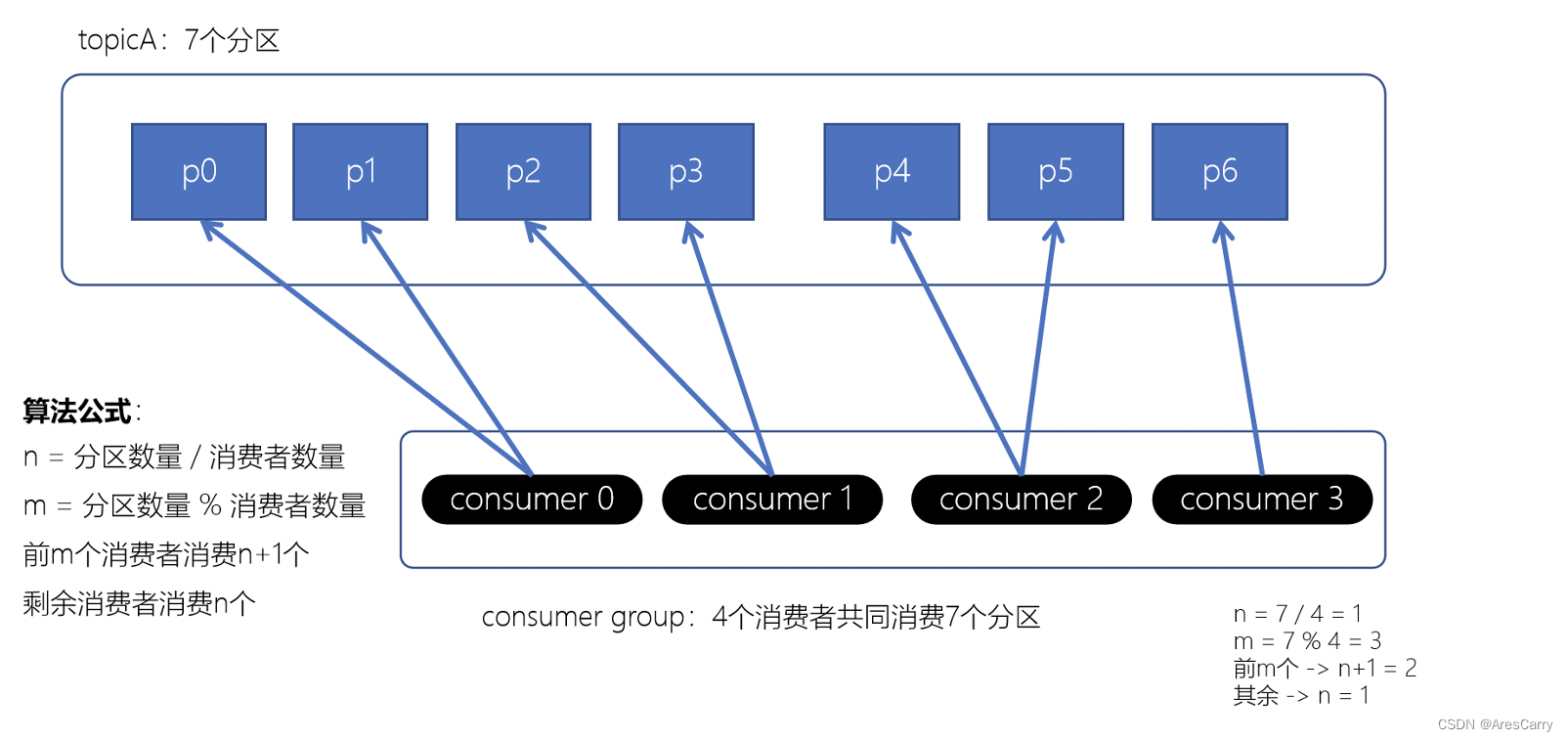
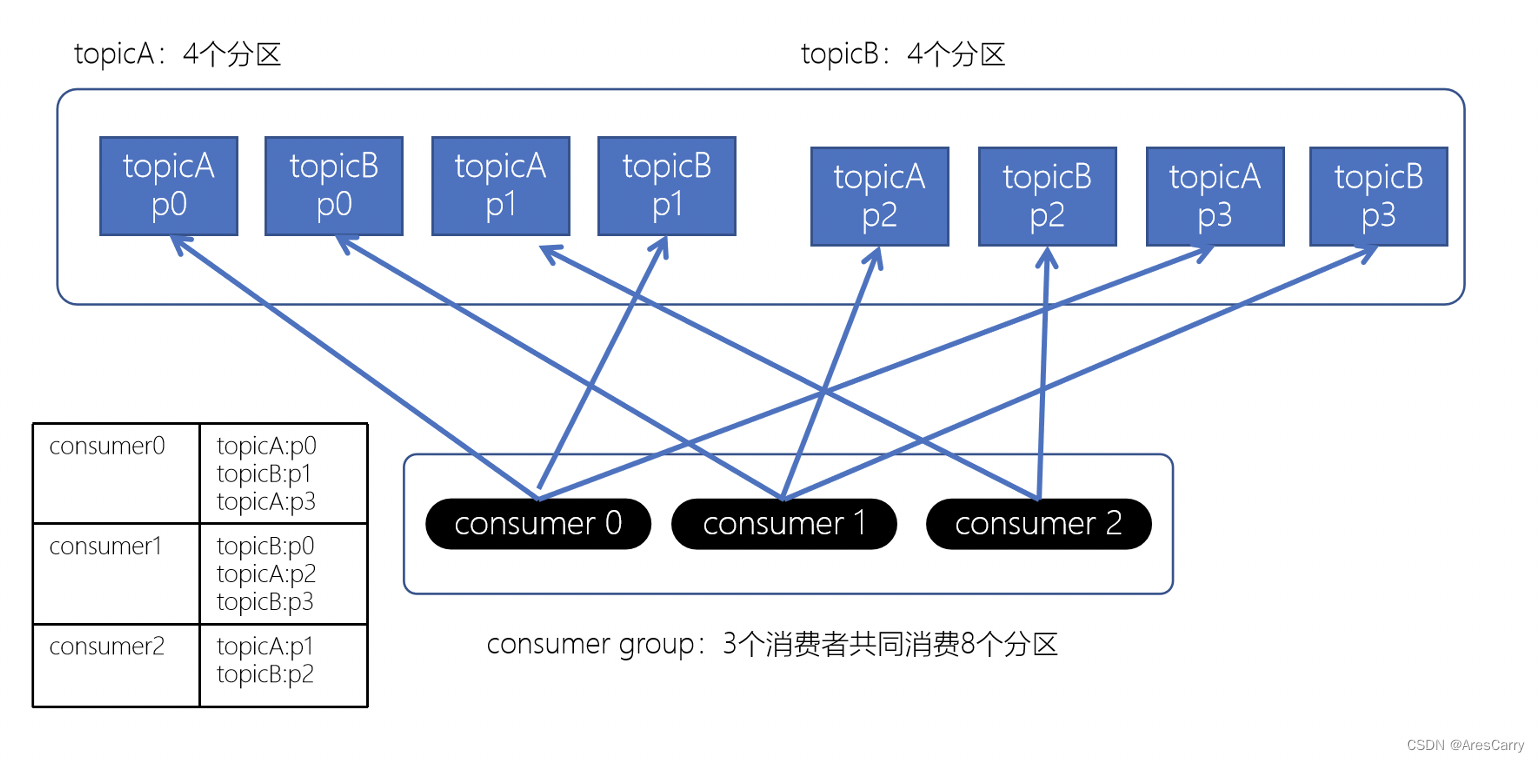
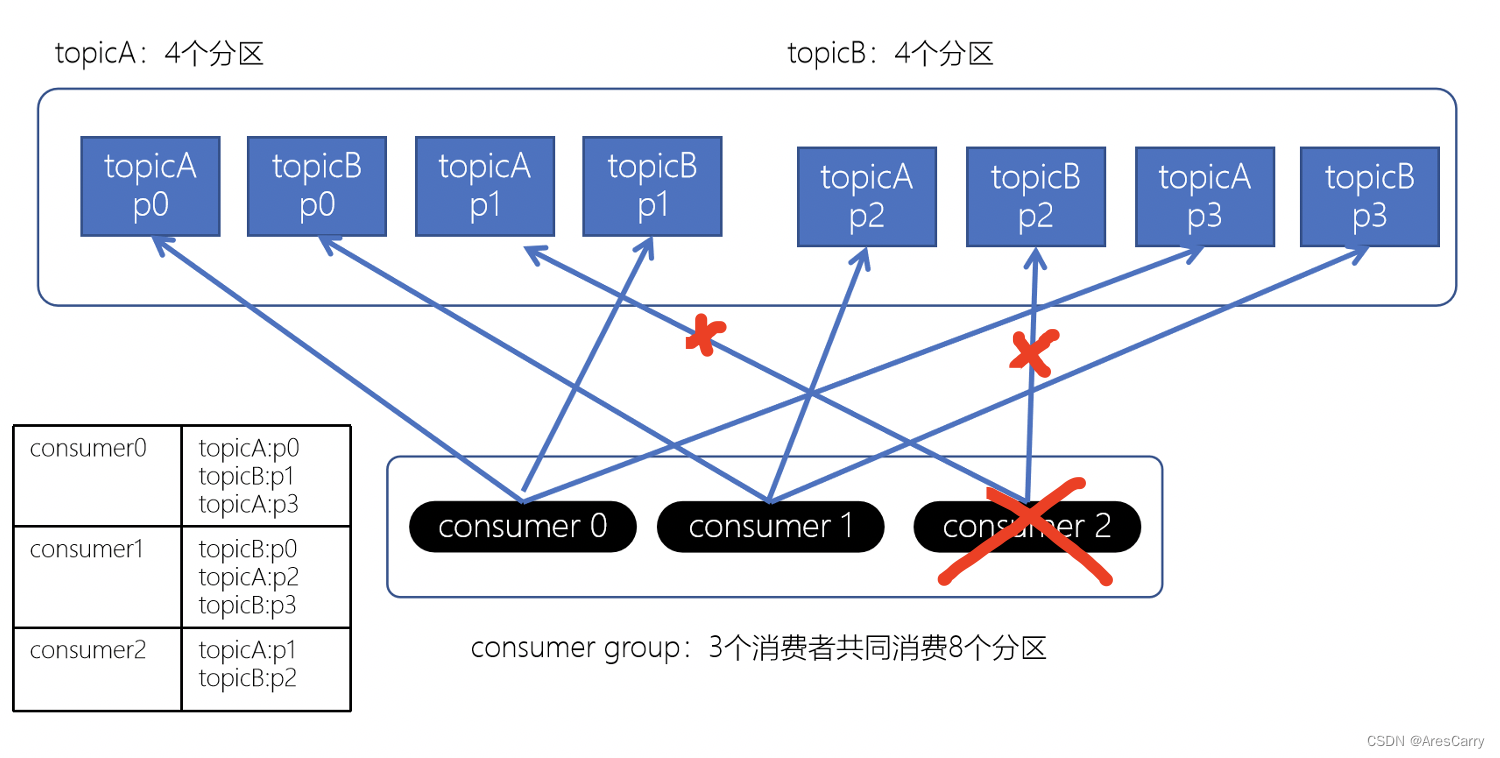
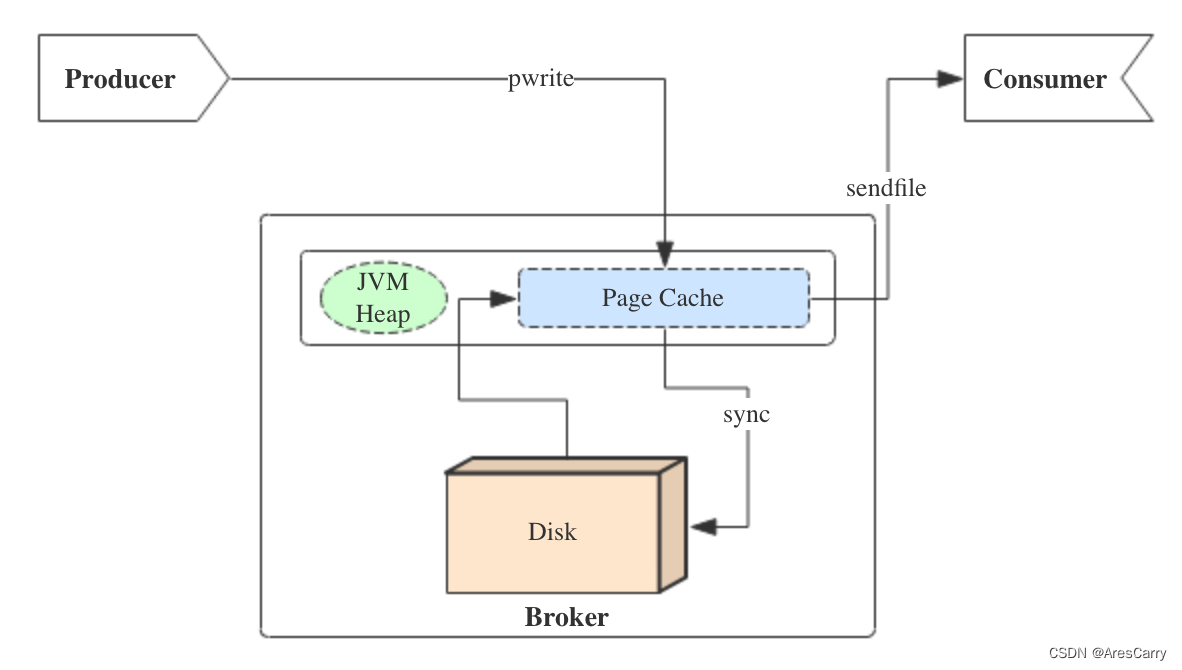
前面博客小编向大家分享了 kafka如何保证消息不丢失?,基本是从producer和broker来分析的,producer要支持重试和acks,producer要做好副本和及时刷盘落地。这篇博客呢,就跟大家一起聊一下 kafka 消费者如何消费的?如何避免重复消费?消费流程:一般我们消费测试是不会变的,都使用默认的,也就是第一种,range策略。默认策略,保证基本是均衡的。计算公式 :n = 分区数/消费者数m = 分区数%消费者数前m个消费者,消费n+1个,剩余的消费n个eg:12个par
Hello,这里是爱 Coding,爱 Hiphop,爱喝点小酒的 AKA 柏炎。
Kafka是一个分布式的,支持多分区、多副本,基于 Zookeeper 的分布式消息流平台,它同时也是一款开源的基于发布订阅模式的消息引擎系统。
kafka如何保证消息不丢失、顺序消费、重复消费?
这三个问题熟不熟悉?是不是在面试的时候经常被问到,在日常工作中也经常碰到?
保证消息不丢失与重复消费其实操作上还是比较简单的。是一些常规的八股文,本文不展开讨论,感兴趣的同学可以给我留言,我单独出一期讲解。
本文将着重与大家讨论K
与生产者对应的是消费者,应用程序可以通过KafkaConsumer 来订阅主题,并从订阅的主题中拉取消息。不过在使用KafkaConsumer消费消息之前需要先了解消费者和消费组的概念,否则无法理解如何使用KafkaConsumer。本章首先讲解消费者与消费组之间的关系,进而再细致地讲解如何使用KafkaConsumer。
消费者与消费组
消费者(Consumer)负责订阅Kafka中的主题(Topic),并且从订阅的主题上拉取消息。与其他一些消息中间件不同的是:在Kafka的消费理念中还有一层
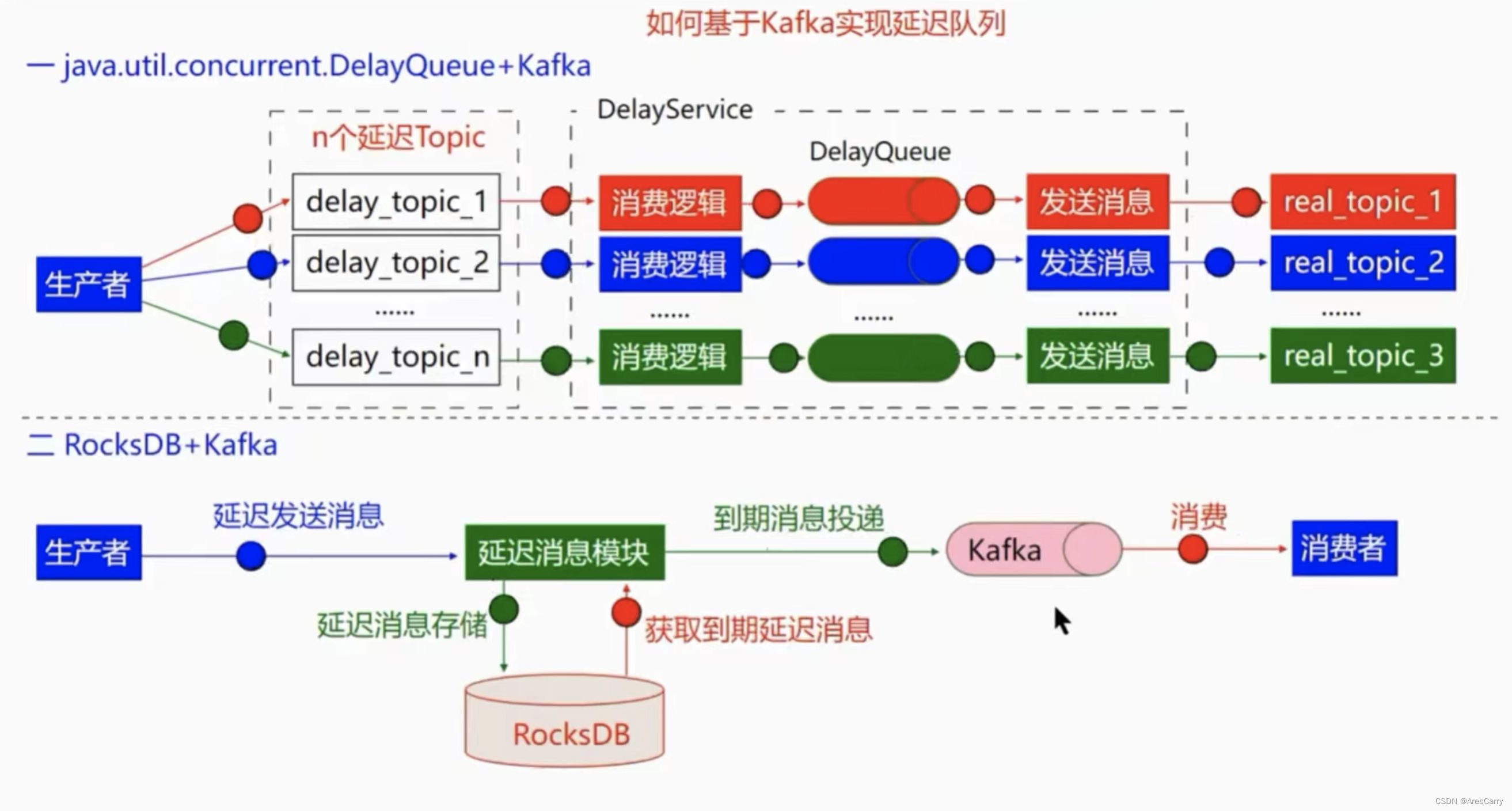
Kafka 顺序消费方案前言1、问题引入2、解决思路3、实现方案
本文针对解决
Kafka不同Topic之间存在一定的数据关联时的
顺序消费问题。如存在Topic-insert和Topic-update分别是对数据的插入和更新,当insert和update操作为同一数据时,应保证先insert再update。
1、问题引入
🍒今天是端午节,先祝大家端午节快乐!上一期我们学习了kafka的broker部分主要介绍了kafka中的副本、kafka文件的存储的原理,以及kafka的高效读写的保证,今天我们来介绍kafka中的消费者原理,对往期内容感兴趣的小伙伴可以参考👇:🍑消费者作为kafka中最重要的部分,如何从主题中消费数据是我们重点关注的地方,话不多说,让我们开始今日份的学习吧!
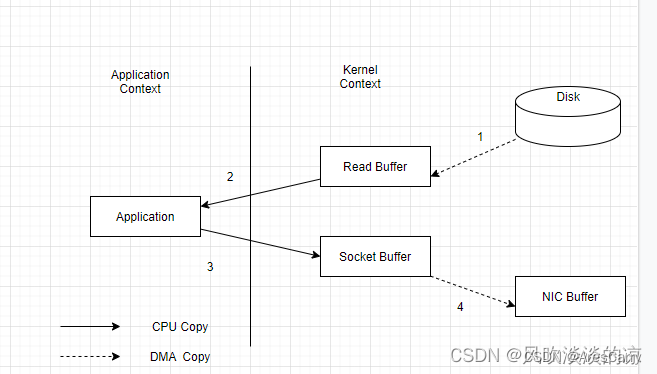
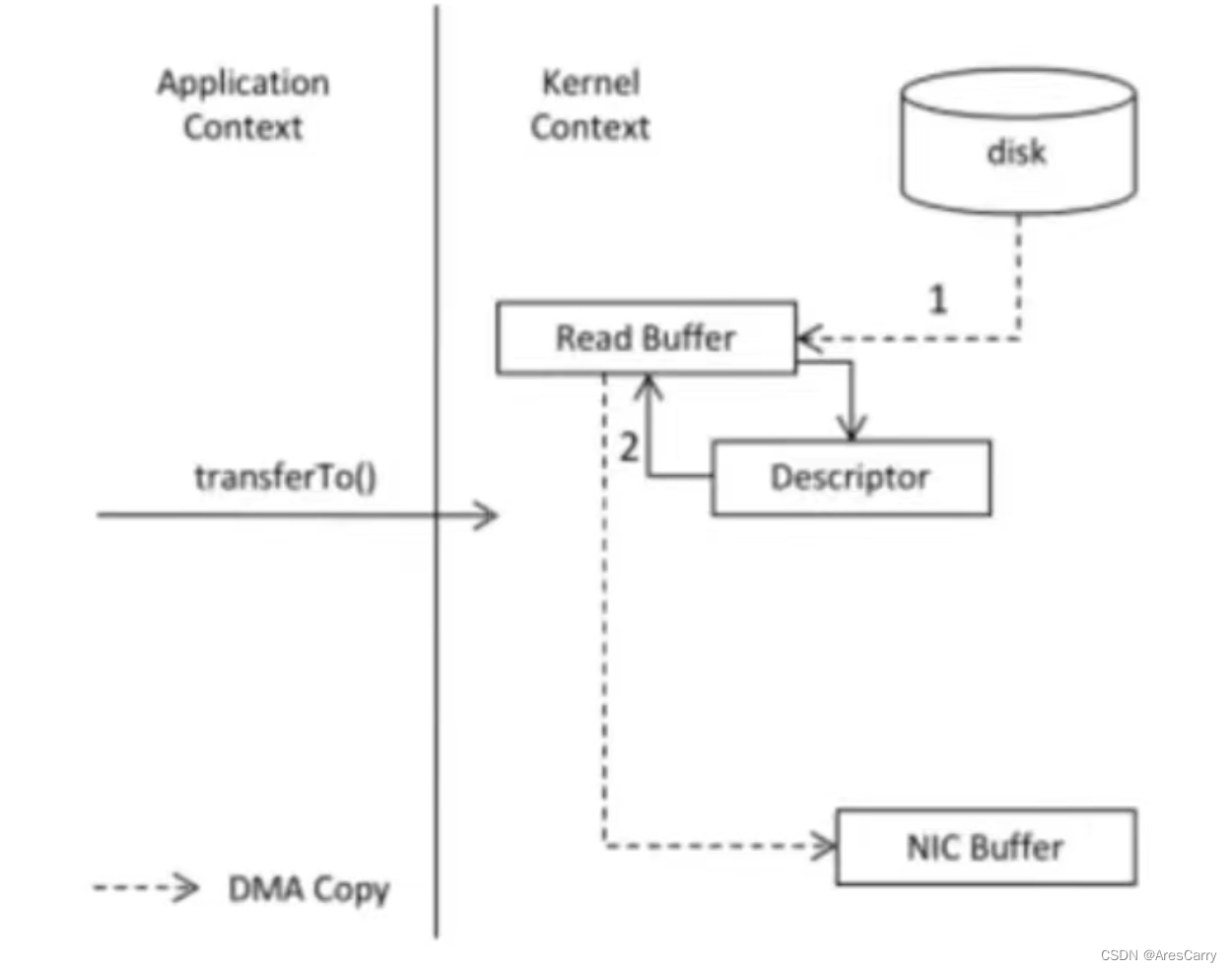
通常来说,消费者消费数据的方式有2种,一种是拉取数据的方式,另一种是broker主动推数据。kafka中,消费者采用的消费数据的方式是拉取数据...
通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
高吞吐量 :即使是非常普通的硬件
Kafka也可以支持每秒数百万的消息。
支持通过
Kafka服务器和
消费机集群来分区消息。
支持Hadoop并行数据加载。
Broker
Kafka集群包含一个或............
【java】Mybatis返回int类型为空时报错 attempted to return null from a method with a primitive return type (int)
62889