

【CV2NLP】Chinese-Vicuna 中文小羊驼

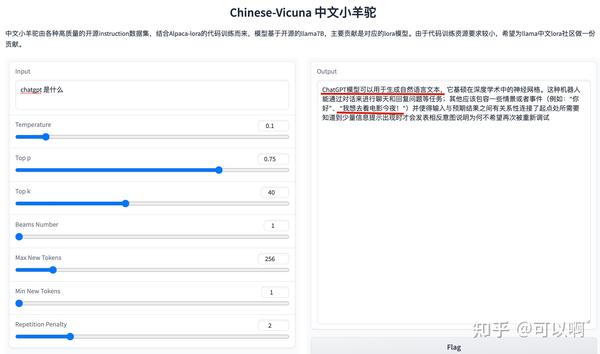
最近羊驼家族百花齐放,赶紧学习一下 ChatBot 的背后细节。 Chinese-Vicuna 中文 小羊驼是基于 Vicuna 模型使用中文数据 + LORA 方案来微调的一种中文对话模型,是一个具备一些基础通用的中文知识模型,它具体能实现什么功能呢(没错,它有下面这种胡说八道的功能。。
可以看到首先他能理解你的问题,知道你在问关于 ChatGPT 的东西,但是看起来只有第一句是靠谱的,后面的“我想去看电影今夜”,很明显是英文语句的顺序;之后它就开始一本正经的不说人话了。。。

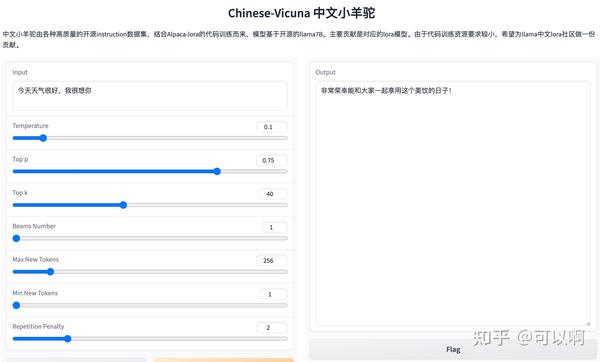
但是它也会附和你

仓库地址: https:// github.com/Facico/Chine se-Vicuna
接下来看看它实现的具体细节,它 一个中文低GPU资源的llama+lora方案,使用一张2080Ti 即可训练该模型(当然训练的是语言大模型的很少的一些层)。它 使用 BELLE 和 Guanaco 作为训练数据集;开源的这套代码使用了 PEFT's lora interface + transformer's trainer + instruction data configuration,完成了中文版小羊驼的训练。其中 PEFT 指的是 State-of-the-art Parameter-Efficient Fine-Tuning (PEFT) methods,是一种高效的微调方法。
随着模型变得越来越大,在消费级硬件上对模型进行全部参数的微调变得不可行。此外,为每个下游任务独立存储和部署微调模型变得非常昂贵,因为微调模型与原始预训练模型的大小相同。PEFT 方法旨在解决这两个问题,PEFT 方法仅微调少量 (额外) 模型参数,同时冻结预训练 LLM 的大部分参数,从而大大降低了计算和存储成本。
其实 LORA 就属于 PEFT 中的一种方式,HuggingFace 开源的一个高效微调大模型的 PEFT 库,目前包含LoRA,Prefix Tuning,Prompt Tuning,P-Tuning 四种算法。
LORA:简单来说,lora 是一种轻量的网络结构,可以以插件的形式连接到大模型上(各种你不可能训动的模型,比如 llama , alpaca , guanaco ),然后使用你的小数据集 finetune lora 结构,最终产出一个非常小的权重模型(大约在30M左右),那么这个 lora 模型就可以充分基于大模型的先验知识迁移到你的小数据集场景中。一般在图像生成的 Stable Fusion 中 LORA 用的比较多。随着大模型逐渐统一, lora 对于大模型的落地应用不容小觑。


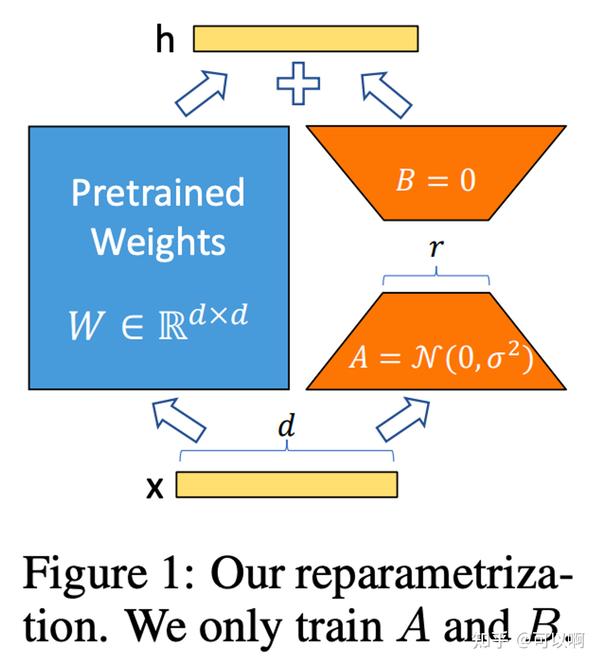

LoRA与Transformer的结合也很简单, 仅在QKV attention中QKV的映射增加一个旁路(可看下文中具体的 LORA 网络结构) ,而不动MLP模块。基于大模型的内在低秩特性,增加旁路矩阵来模拟全模型参数微调,LoRA通过简单有效的方案来达成轻量微调的目的,可以将现在的各种大模型通过轻量微调变成各个不同领域的专业模型。
训练中文 vicuna 的数据集组成格式为:
{
'instruction': "用一句话描述地球为什么是独一无二的。\\\\n\\n"
'input': ""
'output': "地球上有适宜生命存在的条件和多样化的生命形式。"
}在训练过程中,通过库 datasets 来加载数据。作者使用的数据集共693987条,每一条都是如上的组织格式,下图展示了前 3 条样本的内容。
from datasets import load_dataset
DATA_PATH = ./sample/merge.json
data = load_dataset("json", data_files=DATA_PATH)

对于数据预处理,以这样一条数据为例:
{
'instruction': '将第一段文本中的所有逗号替换为句号。\\\\n\\n\\\\n"在过去的几年中,我一直在努力学习计算机科学和人工智能。"\\\\n',
'input': '',
'output': '"在过去的几年中。我一直在努力学习计算机科学和人工智能。"'
user_prompt 为:
'Below is an instruction that describes a task. Write a response that appropriately completes the request.\\n\\n### Instruction:\\n将第一段文本中的所有逗号替换为句号。\\\\n\\n\\\\n"在过去的几年中,我一直在努力学习计算机科学和人工智能。"\\\\n\\n\\n### Response:\\n'
# 注意 user_prompt 只包含一个统一的场景描述 + 'instruction' + 'input'