-
tebsorRT是什么
tensorRT是NVIDIA出的一个高性能深度学习推理(inference)优化器,可以为深度学习应用提供低延迟、高吞吐率的部署推理。TensorRT可用于对超大规模数据中心、嵌入式平台或自动驾驶平台进行推理加速。TensorRT现已能支持TensorFlow、Caffe、Mxnet、Pytorch等几乎所有的深度学习框架,将TensorRT和NVIDIA的GPU结合起来,能在几乎所有的框架中进行快速和高效的部署推理。
-
为什么能加速模型运行速度
TensorRT是英伟达针对自家平台做的加速包,TensorRT主要做了这么两件事情,来提升模型的运行速度。一个是支持INT8和FP16的计算。深度学习网络在训练时,通常使用 32 位或 16 位数据。TensorRT则在网络的推理时选用不这么高的精度,达到加速推断的目的。
第二个是TensorRT对于网络结构进行了重构,把一些能够合并的运算合并在了一起,针对GPU的特性做了优化。现在大多数深度学习框架是没有针对GPU做过性能优化的,而英伟达,GPU的生产者和搬运工,比如一些层在水平方向与深度方向都会做一定的合并,从而加速。
TensorRT具体加速效果决定于显卡和模型,例如在3080ti上resnet50从pytorch转TensorRT可以加速10倍,但是yolov5只能加速一倍多。
另外,TensorRT能做int8和fp16推理要看gpu是否支持,例如新3080ti支持int8和fp16推理,老tesla t4卡就只能做int8推理,更老的卡都不支持了。
TensorRT对网络推理的优化其实远不止CBR(conv、BN、Relu)合并这么简单,还会做Gemm、Winograd、cudnn kernel选择等一系列优化操作,然后遍历选取运行时间最短的cudnn api(打开日志verbose就能看到)。
-
实践中遇到的坑
根据onnx模型生成trt的过程,如果遇到不支持的算子,有的时候报错反卷积和卷积操作不支持,就比较离谱了,这个时候通常是环境问题,以及onnx导出时的torch版本,我用8.4.2.4的tensorRT版本,torch1.9,op12导出onnx模型,可以将模型序列化为trt,但在反序列化推理的时候会报错Error Code 3: API 使用错误:
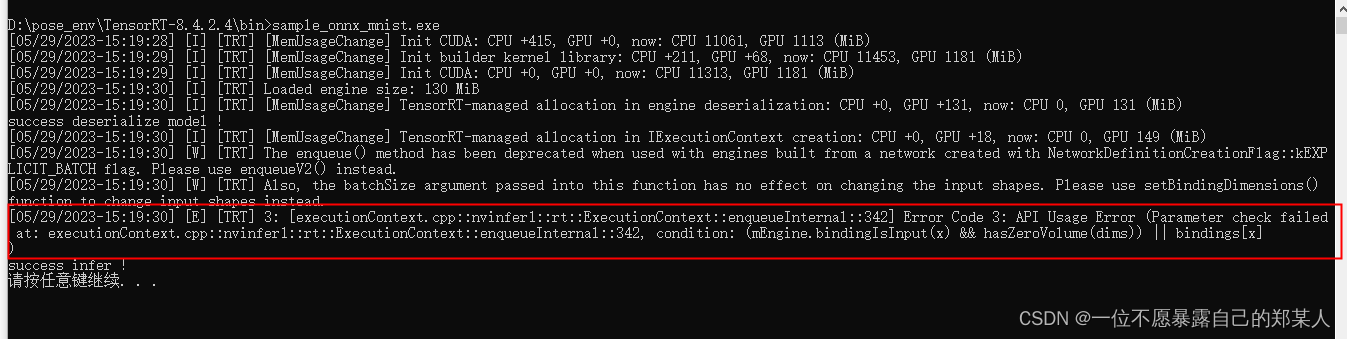
解决方法:
用低版本1.5的torch及op为9的版本,导出onnx模型,推理报错问题解决。
另外,tensorRT是不支持ATen操作的,模型网络结构只是一些矩阵的切片索引乘法,用低版本导出时就会包含ATen这个操作,奇怪,不知道为啥会有这个操作,见如下结构:
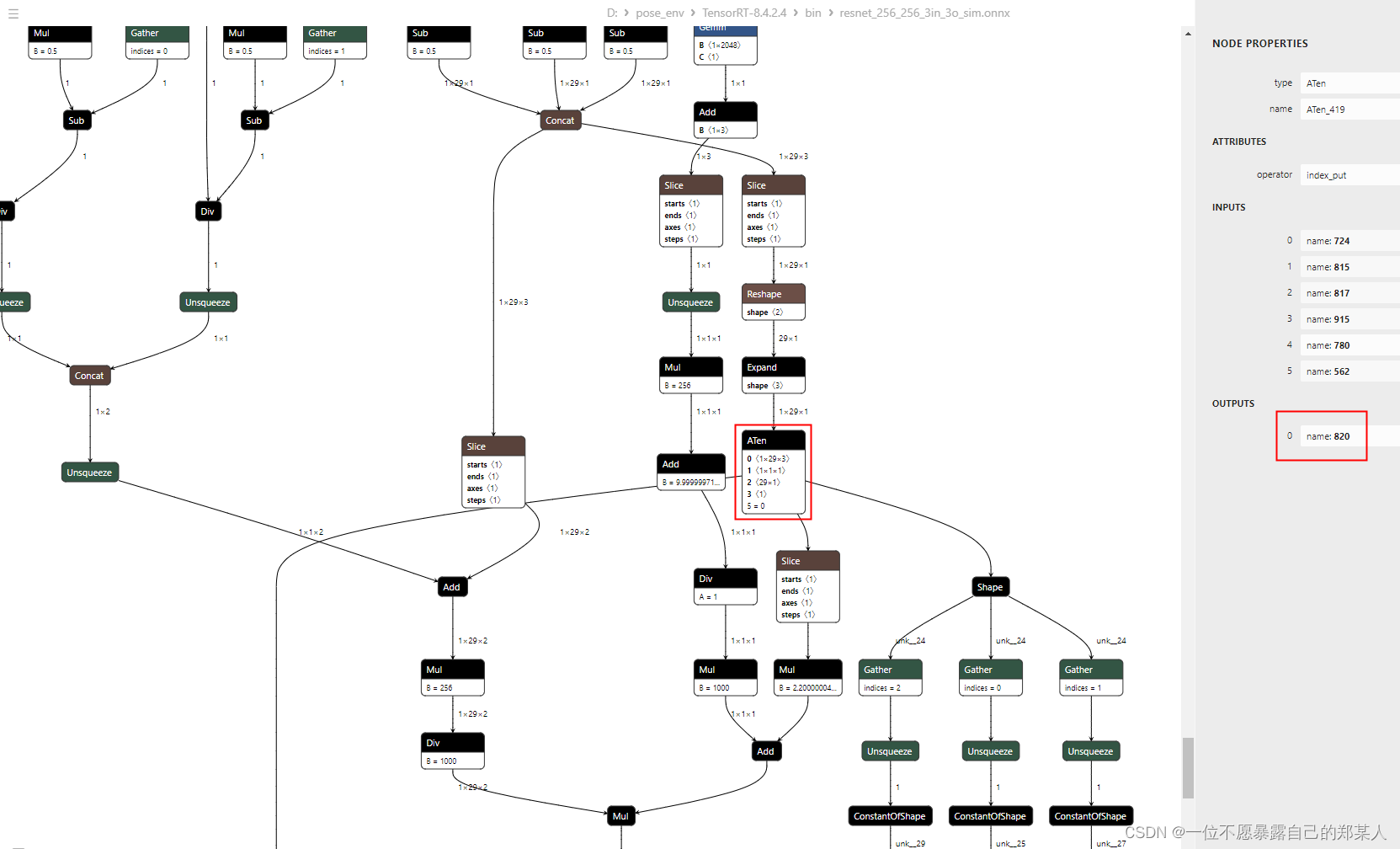
onnx包含ATen算子,tensorRT就会报错如下,然后运行卡住,异常退出:
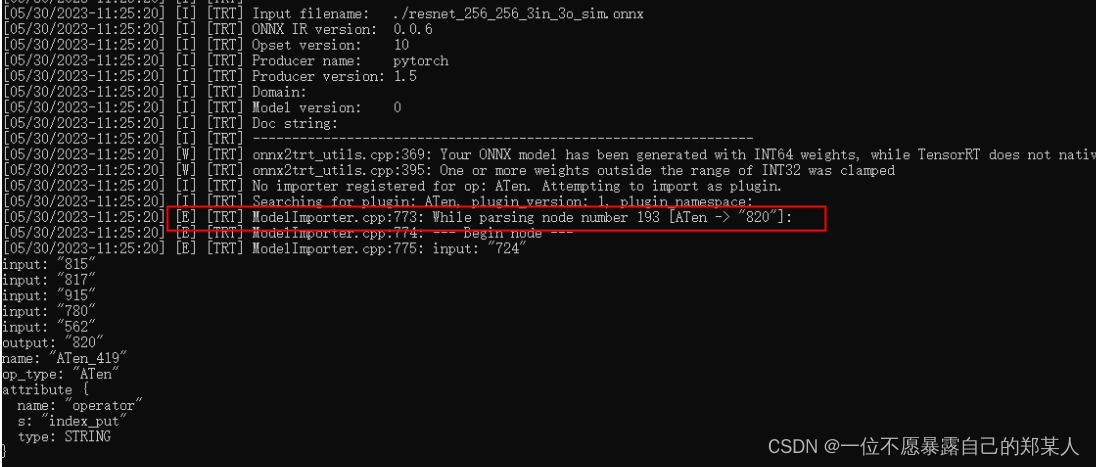
最后将产生ATen这个操作的放在后处理,onnx去掉这部分,导出后,即可成功运行。
注意:代码中声明的变量buffers, buffers的个数是输入加输出的总数,我的模型为1个输入,4个输出,所以声明如下:
void* buffers[5];
另外,模型推理时,如果没做预处理,送进推理的数据类型是U8C3时,推理也会异常退出,不会告诉你是哪里的问题,需要自己一步一步debug, 看各个步骤结果是否符合预期,tensorRt官方给出的栗子可以好好研究一下,有一篇非常详细的源码解读文章,一定要看一下,方便自己魔改:
https://blog.csdn.net/yanggg1997/article/details/111587687
在把int8的量化集成到自己工程中时,发现ubuntu系统的int8量化与win端结果不一致,相差很多,比如,python结果0.4114,ubuntu tensorRt量化后的结果0.37, 而win端量化前后的结果就是0.4114->0.4153,以为是自己细节哪里实现有问题,但是把预处理完的数据打印出来,值都一模一样,量化完结果就不一致了,最后定位到是tensorRT版本不一致造成的,这也是比较坑的一点,原来不同的tensorRt版本int8量化都会有这么大的差异,最后,在ubuntu系统上,下载和windows端一致的tensorRt 8.4.2.4版本,改变之前使用的8.2版本,量化后结果一致。
TensorRT是英伟达针对自家平台做的加速包,TensorRT主要做了这么两件事情,来提升模型的运行速度。TensorRT则在网络的推理时选用不这么高的精度,达到加速推断的目的。现在大多数深度学习框架是没有针对GPU做过性能优化的,而英伟达,GPU的生产者和搬运工,比如一些层在水平方向与深度方向都会做一定的合并,从而加速。另外,模型推理时,如果没做预处理,送进推理的数据类型是U8C3时,推理也会异常退出,不会告诉你是哪里的问题,需要自己一步一步debug, 看各个步骤结果是否符合预期。
关于tensorRT中遇到的几个问题
一、运行同一个程序,前后两次的运行结果不一样
例如运行tensorRT-SSD代码,同样的测试图片,检测出来的目标框会有轻微的抖动,但是目标还是能检测出来,不会影响精度。
二、相同的代码,相同的模型,相同的测试图片,在不同的平台上结果不一样
我在pc上的gtx1080显卡运行tensorRT代码,全部调试通过之后移植到tx2平台上运行,却发现在tx2平台上的检...
这里写自定义目录标题欢迎使用Markdown编辑器新的改变功能快捷键合理的创建标题,有助于目录的生成如何改变文本的样式插入链接与图片如何插入一段漂亮的代码片生成一个适合你的列表创建一个表格设定内容居中、居左、居右SmartyPants创建一个自定义列表如何创建一个注脚注释也是必不可少的KaTeX数学公式新的甘特图功能,丰富你的文章UML 图表FLowchart流程图导出与导入导出导入
欢迎使用Markdown编辑器
你好! 这是你第一次使用 Markdown编辑器 所展示的欢迎页。如果你想学习如何使用Mar
tensorrt c++ 推理示例项目,支持分类网络,比如alexnet,mobileone,skipnet等轻量级网络。
环境:win10 vs2017环境,cuda11.0,亲测成功。
tensorrt库版本:
TensorRT-8.2.1.8.Windows10.x86_64.cuda-11.4.cudnn8.2
转换流程:pytorch转onnx,onnx转tensorrt引擎
python生成tensorrt引擎步骤,可以查看我的博客:
https://blog.csdn.net/jacke121/article/details/125382721
而不能调用libtorch1.7.1cu111里面的
所以建议在系统环境变量中添加CUDA11.1的变量即可,不要把Libtorch1.7.1里面的cudart64_110.dll放到程序执行目录下。
问题描述:
最近进行把TF的模型转化为UFF文件部署到TensorRT。在进行测试的时候发现一个问题,同一个数据使用TRT进行推理,但是每次结果都不一样。输出的结果本应是softmax算子输出结果, 但是输出的结果看着都是随机的,而且数值求和结果非1,而是有的非常大,有的非常小。
排查了一整天发现是因为我的日志头文件导入的顺序导致这个问题。
#include "easylogging++.h"
#include "common.h"
#include "buffers.h"
#include "Nv
FP 16量化推理的结果不一致的原因
(抛砖引玉)TensorRT的FP16不得劲?怎么办?在线支招!
模型中某一层的计算FP 16因为动态范围和精度不够,导致某个OP节点的计算值溢出。迁一发而动全身,整个模型后面的所有层都崩塌了。
TensorRT只是加速,对精度有影响吗?
TensorRT有多个方式进行inference加速,一个是layer的融合,这个是没有精度损失的;另外还可以采用低精度的FP 16 INT 8计算,FP 16基本没有精度损失,INT 8需要做量化,这时候会有很高的加速,精度损失也很
YOLOX TensorRT推理是一种将YOLOX模型以TensorRT的方式进行推理的方法。
YOLOX是一种高效且实时的目标检测算法,结合了YOLO系列的优点,并在训练速度和检测精度上进行了改进。而TensorRT是NVIDIA推出的深度学习推理引擎,可以将训练好的模型部署到边缘设备上进行高效的推理。
在YOLOX TensorRT推理中,首先需要将YOLOX模型转换为TensorRT引擎。这个过程包括将YOLOX模型的权重文件加载进来,构建TensorRT的计算图,并对推理过程进行优化。通过TensorRT的优化,可以显著提高模型的推理速度,同时减少模型所需的资源占用。
在完成模型转换后,就可以使用TensorRT引擎进行推理了。推理过程可以输入一张图像,通过TensorRT引擎对图像进行前向计算,得到检测结果。与传统的推理方式相比,使用TensorRT引擎进行推理可以大幅度提高推理速度,适用于对实时性要求较高的应用场景。
总体来说,YOLOX TensorRT推理是一种将YOLOX模型以TensorRT引擎进行加速的方法。通过将YOLOX模型转换为TensorRT引擎,可以提高模型的推理速度,使得模型可以在边缘设备上以实时的方式进行目标检测。
RuntimeError: [enforce fail at ..\c10\core\CPUAllocator.cpp:72] data. DefaultCPUAllocator: not enoug
23123

