1、神经网络中损失函数和优化函数的作用
训练出一个网络模型之后如何对模型进行评估?往往是衡量预测值与真实值之间的差异程度,这就是通过损失函数来完成的。另外损失函数也是神经网络中优化的目标函数,神经网络训练或者优化的过程就是最小化损失函数的过程,损失函数越小,说明模型的预测值就越接近真实值,模型的准确性也就越好。那么为了最小化损失函数则需要对网络模型的参数进行更新,确定如何更新参数这时则需要选择合适的优化函数(用以确定对网络模型参数进行更新的方法,步长和方向的确定)。我们都知道,神经网络模型训练得以实现是经过前向传播计算
LOSS,根据LOSS的值进行反向推到,进行相关参数的调整。这个过程需要在loss值的指导下进行,因此在优化时需要传入loss值。
2、
神经网络中的收敛
一般我们可以设置一个迭代次数阈值,当损失
loss的变化小于一个很小的值,或者迭代次数达到阈值上限,那么我们一般就认为模型已经收敛了。
在实际应用中,如果你用的是
TensorFlow之类的工具,可以在Tensorboard上看loss的变化情况,如果曲线趋于平的,那么基本就可以认为是收敛了。
另外收敛只看训练集的损失值,与测试集无关。
3、
train loss与val loss结果分析
train loss 不断下降,val loss 不断下降——网络仍在学习;
train loss 不断下降,val loss 不断上升——网络过拟合;
train loss 不断下降,val loss 趋于不变——网络欠拟合;
train loss 趋于不变,val loss 趋于不变——网络陷入瓶颈;
train loss 不断上升,val loss 不断上升——网络结构问题;
train loss 不断上升,val loss 不断下降——数据集有问题
4、
影响神经网络收敛速度的不同因素
1)
对于收敛速度而言,梯度的方向和步长的大小显然是影响收敛速度的两个最直接因素(选择一个好的优化函数例如Adam)。对于网络优化问题来说也是两个角度。
2)
参数的初始化也很重要,既要避免参数全部一致导致学习特征单一,又要避免激活函数(
sigmoid
)的净输入陷入饱和区导致梯度为
0
无法学习。随机初始化包括高斯分布以及
Xavier
[‘zeɪvɪr]
。
3)
数据预处理就是归一化。简单地讲,由于
特征量度不同
,导致
Loss
的等高线成为不均匀的椭圆状,在像最优点下降过程中,梯度方向难免出现震荡,使得收敛速度变缓。引入归一化后,使得
Loss
等高线变为更均匀的圆形,约束梯度下降的方向指向正中圆心最优点,得到最优的收敛路径。归一化方法包括缩放归一化和标准分布归一化。
4)
训练过程中,层与层之间输入输出需要保持
分布一致性
,否则会出现内部协变量偏移,越深的层次,现象越明显。深度神经网络中,误差通过梯度反向传播,分布不一致会导致参数更新不是最优的方向,阻碍了收敛最优点。解决方案是引入输入输出规范化,包括批规范化
BN
和层规范化
LN
。
5)
残差网络
ResNet
,
ResNet
是针对
CNN
训练中层次过深导致退化问题。简单来说,卷积用来提取目标特征,而越深的卷积层使得提取的特征更加抽象,从而在测试集上得到更好的准确率。同时,层次过深又阻碍了误差反向传播,比如梯度爆炸和梯度弥散,使得参数得不到最优的更新,在训练集合上收敛不到最优。对此引入残差网络,将输入作为旁路恒等映射到输出端,这个映射使得误差反向传播时,保证梯度的稳定。在保持深层次的基础上,使得各层的参数得到很好的更新,有利于模型的收敛。
5、
梯度爆炸和梯度消失
写的很好的参照:
https://blog.csdn.net/qq_25737169/article/details/78847691
简单理解,就是在反向传播的算法过程中,由于我们使用了是矩阵求导的链式法则,有一大串连乘,如果连乘的数字在每层都是小于
1的,则梯度越往前乘越小,导致梯度消失,而如果连乘的数字在每层都是大于1的,则梯度越往前乘越大,导致梯度爆炸。
比如我们在前一篇反向传播算法里面讲到了
δ
的计算,可以表示为:
如果不巧我们的样本导致每一层
的
∂zl+1/∂zl都小于1,则随着反向传播算法的进行,我们的δl会随着层数越来越小,甚至接近越0,导致梯度几乎消失,进而导致前面的隐藏层的W,b参数随着迭代的进行,几乎没有大的改变,更谈不上收敛了。这个问题目前没有完美的解决办法。
导致梯度消失和梯度爆炸的原因:
两种情况下梯度消失经常出现,一是在
深层网络
中,二是采用了
不合适的损失函数
,比如
sigmoid。梯度爆炸一般出现在深层网络和
权值初始化值太大
的情况下
。
梯度消失、爆炸,其
根本原因
在于反向传播训练法则,属于先天不足
。
从深层网络角度来讲,不同层
的
学习速度差异很大,表现为网络中靠近输出的层学习的情况很好,靠近输入的层学习的很慢,有时甚至训练了很久,前几层的权值和刚开始随机初始化的值差不多。
解决梯度消失和梯度爆炸的方法:
由于导致这两种现象产生的根本原始是反向传播训练法则,所以可以从对
w的控制以及激活函数着手。
如何判断发生了梯度爆炸(参考:
https://www.cnblogs.com/Mrzhang3389/p/10164350.html
)
以下是一些稍微
明显一点的信号
,有助于确认是否出现梯度爆炸问题。
训练过程中模型梯度快速变大。
训练过程中模型权重变成 NaN 值(梯度累积的很大W更新出现NAN)。
训练过程中,每个节点和层的误差梯度值持续超过 1.0
为了避免梯度爆炸可以通过梯度剪切(这样处理其实并不粗糙,有些论文中也是这样处理的)和正则化的手段,从激活函数的选取方面选用
relu激活函数。
通过合理的初始化权重能够减小梯度消失和梯度爆炸的情况,引入
batch_norm也能一定程度减小梯度消失和梯度爆炸的情况。
6、
深度学习中不同优化函数的对比
具体参考:
https://blog.csdn.net/brucewong0516/article/details/78838124
https://zhuanlan.zhihu.com/p/27449596
一、SGD(stochastic[stə'kæstɪk] gradient[ˈgreɪdiənt] descent[dɪˈsent])随机梯度下降
现在的随机梯度下降一般都指mini-batch gradient descent,即随机抽取一批样本,以此为根据来更新参数。
对于一次训练所有数据的梯度下降算法,它的损失值一定是随着迭代次数不断下降的,而对于小批量的梯度下降算法,损失值不一定是一直下降的,会随着每个小批次的训练有下降也有上升,总体趋势是下降的。之所以会出现这种情况是因为每次训练的批次数据不同,有的批次数据可能好训练那么
cost就是下降的,有的批次数据难训练,那么cost可能就会有所上升。
批量梯度下降有两种极端的情况,一种就是把所有训练数据都当做一个批次进行训练,这总情况的缺点是每次训练会消耗大量的时间,另一个极端的情况是每次训练把一条数据当做一个批次,这样会失去所有向量化带给训练的加速,同时每次训练参数并不一定总是会朝着正确的方向更新,且永远不会收敛,最后会围绕最优值不断波动,且总体波动也会很大,这两种情况如下图:
它的优点是:
1)训练速度快,对于很大的数据集,也能够以较快的速度收敛.SGD应用于凸问题时,k次迭代后泛化误差的数量级是O(1/sqrt(k)),强凸下是O(1/k)。
2)可能由于SGD在学习中增加了噪声,有正则化的效果。
它的缺点是:
由于是抽取
,因此不可避免的,得到的梯度肯定有误差.因此学习速率需要逐渐减小.否则模型无法收敛 ,因为误差,所以每一次迭代的梯度受抽样的影响比较大,也就是说梯度含有比较大的噪声,优化
时波动很大,不能很好的反映真实梯度
。
使用小批量梯度下降的优点是:
1) 可以减少参数更新的波动,最终得到效果更好和更稳定的收敛。
2) 还可以使用最新的深层学习库中通用的矩阵优化方法,使计算小批量数据的梯度更加高效。
3) 通常来说,小批量样本的大小范围是从50到256,可以根据实际问题而有所不同。
4) 在训练神经网络时,通常都会选择小批量梯度下降算法。
这种方法有时候还是被成为
SGD。
使用梯度下降及其变体时面临的挑战
1
)
很难选择出合适的学习率。太小的学习率会导致网络收敛过于缓慢,而学习率太大可能会影响收敛,并导致损失函数在最小值上波动,甚至出现梯度发散。
2
)
此外,相同的学习率并不适用于所有的参数更新。如果训练集数据很稀疏,且特征频率非常不同,则不应该将其全部更新到相同的程度,但是对于很少出现的特征,应使用更大的更新率。
3
)
在神经网络中,最小化非凸误差函数的另一个关键挑战是避免陷于多个其他局部最小值中。实际上,问题并非源于局部极小值,而是来自鞍点,即一个维度向上倾斜且另一维度向下倾斜的点。这些鞍点通常被相同误差值的平面所包围,这使得
SGD算法很难脱离出来,因为梯度在所有维度上接近于零。
二、Momentum[məˈmentəm] SGD(动量随机梯度下降算法)相对于随机梯度下降算法,它更加稳定,也在一定程度上增加了更新的速度。它模拟的是物体运动时的惯性,
即更新的时候在一定程度上保留之前更新的方向,同时利用当前
batch的梯度微调最终的更新方向。这样一来,可以在一定程度上增加稳定性,从而学习地更快,
并且还有一定摆脱局部最优的能力。
在参数更新过程中,其原理类似:
1) 使网络能更优和更稳定的收敛;
2) 减少振荡过程。
当其梯度指向实际移动方向时,动量项
γ增大;当梯度与实际移动方向相反时,γ减小。这种方式意味着动量项只对相关样本进行参数更新,减少了不必要的参数更新,从而得到更快且稳定的收敛,也减少了振荡过程。
参考(
https://spaces.ac.cn/archives/5655
)
对于参数的求导引入了二阶,相当于引入了一个动力系统。其中一个优点是Momentum加速为“越过”不那么好的极小值点提供了来自动力学的可能性。
假设选定学习率
α后,在同样精度下,Momentum实际上是步长
√
α前进的,而纯GD则是以步长
α前进的。
由于学习率一般小于1,所以
√
α
>α。所以
Momentum加速的原理之一就是可以在同等学习率、不损失精度的情况下,使得整个算法以更大步长前进。
三、AdaGrad可以自动变更学习速率,只是需要设定一个全局的学习速率ϵ,但是这并非是实际学习速率,实际的速率是与以往参数的模之和的开方成反比的。
优点是
:
能够实现学习率的自动更改。如果这次梯度大
,那么学习速率衰减的就快一些;如果这次梯度小,那么学习速率衰减的慢一些。对于每个参数,随着其更新的总距离增多,其学习速率也随之变慢。
缺点
: 任然要设置一个变量ϵ ,经验表明,在普通算法中也许效果不错,但在深度学习中,深度过深时会造成训练提前结束。
四、RMSprop(root mean square prop)优化算法
RMSProp通过引入一个衰减系数,让r每回合都衰减一定比例,类似于Momentum中的做法,是对AdaGrad算法的改进。
也就是说,它即可以自动调节学习率又能减小波动同时增加学习速度。
优点:
- 相比于AdaGrad,这种方法很好的解决了深度学习中过早结束的问题 - 适合处理非平稳目标,对于RNN效果很好
缺点:
- 又引入了新的超参,衰减系数ρ
- 依然依赖于全局学习速率。
五、Adam(Adaptive Moment[ˈməʊmənt] Estimation [estɪˈmeɪʃn] 自适应时刻估计)本质上是带有动量项的RMSprop,它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。Adam的优点主要在于经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳。使得优化过程更加的平稳,更新波动变小。
以上的优化算法都是从上到下不断优化得来的,所以一般都选用
AdamOptimizer
六、Lookahead
Lookahead 算法与已有的方法完全不同,它迭代地更新两组权重。
直观来说,
Lookahead 算法通过提前观察另一个优化器生成的「fast weights」序列,来选择搜索方向。该研究发现,Lookahead 算法能够提升学习稳定性,不仅降低了调参需要的功夫,同时还能提升收敛速度与效果。
不论是
Adam 还是带动量的 SGD,它们都有难以解决的问题。例如我们目前最常用的 Adam,我们拿它做实验是没啥问题的,但要是想追求收敛性能,那么最好还是用 SGD+Momentum。但使用动量机制又会有新的问题,我们需要调整多个超参数以获得比较好的效果,不能像 Adam 给个默认的学习率 0.0001 就差不多了。
也就是说
Adam的收敛性能不如
SGD+Momentum
,但是要想使用
SGD+Momentum
获得较好的收敛性能需要调节多个参数,相比之下
Adam不需要繁琐的调参过程,只需要一个初始的学习率就行。
Adam 收敛不好的原因。
他们表明在利用历史梯度的移动均值情况下,模型只能根据短期梯度信息为每个参数设计学习率,因此也就导致了收敛性表现不太好。
原理:
Lookahead 首先使用内部循环中的 SGD 等标准优化器,更新 k 次「Fast weights」,然后以最后一个 Fast weights 的方向更新「slow weights」。
优点:
该研究表明这种更新机制能够有效地降低方差。研究者发现
Lookahead 对次优超参数没那么敏感,因此它对大规模调参的需求没有那么强。此外,使用 Lookahead 及其内部优化器(如 SGD 或 Adam),还能实现更快的收敛速度,因此计算开销也比较小
具体流程:
Lookahead 迭代地更新两组权重:slow weights φ 和 fast weights θ,前者在后者每更新 k 次后更新一次。Lookahead 将任意标准优化算法 A 作为内部优化器来更新 fast weights。
使用优化器
A 经过 k 次内部优化器更新后,Lookahead 通过在权重空间 θ − φ 中执行线性插值的方式更新 slow weights,方向为最后一个 fast weights。
slow weights 每更新一次,fast weights 将被重置为目前的 slow weights 值。
其中最优化器
A 可能是 Adam 或 SGD 等最优化器,
内部的
for 循环会用常规方法更新 fast weights θ,且每次更新的起始点都是从当前的 slow weights φ 开始。最终模型使用的参数也是慢更新那一套,因此快更新相当于做了一系列实验,然后慢更新再根据实验结果选一个比较好的方向
7、
神经网络中隐层的确切含义
可以从可视化的图像处理领域分析,多层的
CNN
每个隐层会抽取出数据的不同方面的特征。从这方面可以说
一层隐层网络就是一层特征层次,每一个神经元可以类似看作一个特征属性。
注意:神经网络获得表征的核心就是隐藏层,通过对神经网络的各种修改与变换目的是为了隐藏层能够抽取更好的表征。
8、什么是端到端(End-to-End)的模型
简单而言端到端模型就是输入的是原始数据,输出的是结果。原来输入端不是直接的原始数据,而是在原始数据中提取的特征,端到端网络,特征可以自己去学习,所以特征提取这一步也就融入到算法当中,不需要人来干预了。
9、
为什么用深层神经网络而不是浅层节点较多的神经网络?
整个深度网络可以视为是一个复合的非线性多元函数,神经网络属于端到端的表示学习,
最终的目的是希望这个多元函数能够学习到数据的分布特性,以便于很好的完成输入到输出之间的映射
。
尽管实验表明浅层节点较多的神经网络也能拟合任意复杂的函数,但是需要的参数十分的庞大,所以一般构造深层的神经网络。
(多层的经过多次非线性变换可以更好的拟合复杂函数会使得参数更少)同时网络模型中的每个隐藏层都是一个特征层次,浅层的网络无法抽取出深层次的特征。深层的网络能够抽取出全局和抽象的特征。
多层神经网络能够对输入特征进行不断组合以获得效果更好的高层特征,那为什么不可以采用自底向上的机制,每次单独训练一层,等训练完再建上一层?
因为如果没有上层的监督信号,那底层的特征组合数量会指数级增长,并且生成的特征大多是对上层任务无用的。唯有优化时不停听取来自上层的信号,有针对性地进行组合,才可以以极高的效率获得特定任务的重要特征。而对权重的随机初始化,是赋予它们在优化时滑向任意组合的能力。
10、参数与超参数的区别
具体参考:
https://blog.csdn.net/shenxiaoming77/article/details/76849929
简单而言:
模型参数就是模型内部的配置变量,可以用数据估计它的值。
具体来讲,模型参数有以下特征:
1)进行模型预测时需要模型参数。
2)模型参数值可以定义模型功能。
3)模型参数用数据估计或数据学习得到。
4)模型参数一般不由实践者手动设置。
5)模型参数通常作为学习模型的一部分保存。
神经网络中的权重和偏置值属于参数
模型超参数是模型外部的配置,其值不能从数据估计得到。
具体特征有:
1)模型超参数常应用于估计模型参数的过程中。
2)模型超参数通常由实践者直接指定。
3)模型超参数通常可以使用启发式方法来设置。
4)模型超参数通常根据给定的预测建模问题而调整。
如果你必须手动指定一个
“模型参数”,那么它可能就是一个模型超参数。
11、反向传播中更新参数时,使用的
minimize()解析
该函数是
compute_gradients() 和apply_gradients() 的结合 ,如果你想在得到梯度后,先修改梯度再更新参数状态,可以调用compute_gradients()
得到梯度,修改后再调用
apply_gradients(), 而minimize()是直接得到梯度不做修改就更新参数状态
。
两个重要参数
:
loss: A Tensor containing the value to minimize.
global_step: Optional Variable to increment by one after the variables have been updated
。
它会在参数更新后自动更新
。
不用
minimize()进行提取计算与更新
grads_and_vars = optim.compute_gradients(self.loss)
#grads_and_vars is a list of tuples (gradient, variable)
这里自己对梯度进行了处理,为了防止发生梯度消失或梯度爆炸,对梯度人为的限制了范围。
clip_grad是人为设定的梯度范围。
# tf.clip_by_value(g, -self.clip_grad, self.clip_grad)用于限制参数范围
global_step = tf.Variable(0, name="global_step", trainable=False)
grads_and_vars_clip = [[tf.clip_by_value(g, -self.clip_grad, self.clip_grad), v]
for
g, v
in
grads_and_vars]
self.train_op = optim.apply_gradients(grads_and_vars_clip, global_step=self.global_step)
12、交叉熵函数及其计算
交叉熵作为神经网络的损失函数时,
p代表正确答案,q代表预测值,这里的log是以e为底,即相当于ln。通过交叉熵计算这两个概率分布之间的距离,交叉熵的值越小,两个概率分布越接近。
假设
N=3,期望输出为p=(1,0,0),实际输出q1=(0.5,0.2,0.3),q2=(0.8,0.1,0.1),那么:
以上的所有说明针对的都是单个样例的情况,而在实际的使用训练过程中,数据往往是组合成为一个
batch来使用,所以对用的神经网络的输出应该是一个m*n的二维矩阵,其中m为batch的个数,n为分类数目,而对应的Label也是一个二维矩阵,还是拿上面的数据,组合成一个batch=2的矩阵:
所以对于参数的更新是利用一个批次的数据,通过一个批次的数据其损失值的均值进行更新。
13、交叉熵损失函数(代价函数)
其中前面的y
是真实值,后面的
y
是预测值。其公式如何推导来的参考以下链接:
交叉熵是极大似然估计的直接产物(这里是以概率的角度推导得来的)
https://zhuanlan.zhihu.com/p/38241764
以下从最优化的角度讲解:
https://zhuanlan.zhihu.com/p/45014864
14、
交叉熵损失函数+Softmax对参数
w
的求导
具体参考:
https://zhuanlan.zhihu.com/p/35709485
15、Sigmoid函数与softmax函数的联系
具体参考:
https://www.cnblogs.com/shuzirank/p/6766787.html
softmax函数最明显的特点在于:它把每个神经元的输入占当前层所有神经元输入之和的比值,当作该神经元的输出。这使得输出更容易被解释:神经元的输出值越大,则该神经元对应的类别是真实类别的可能性更高。
softmax激活函数中e的幂函数的优势,一方面是保证了输出都为正值,另一方面可以使大的值更大,小的值更小,这样类别区分就更明显了。
另外,
softmax
不仅把神经元输出构造成概率分布,而且还起到了归一化的作用,适用于很多需要进行归一化处理的分类问题。
softmax
用于多分类过程中
,它将多个神经元的输出,映射到(
0,1
)区间内,
可以看成概率来理解
,从而来进行多分类!
Sigmoid函数是softmax函数的一个特例,如果说Softmax可以得到在多于两个
不同的输出上的一个合理的概率分布,那么
sigmoid可以得到针对两种输出
的一个合理的概率分布。也就是说,
sigmoid仅仅是softmax的一个特例。用定义来表示,假设模型只能产生两种不同的输出:给定输入
,我们可以写出softmax
函数如下:
然而,值得注意的是,我们只需要计算一种结果的产生概率,因为另外一种结果的产生概率可以由概率分布的性质得到:
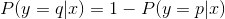 接下来,我们对
接下来,我们对
 的产生概率的表示进行扩展:
的产生概率的表示进行扩展:
然后,对该分式的分子和分母都同时除以
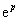 ,得到:
,得到:
最后,我们可以用该式代入求另一种结果的产生概率的式子中得到:
该等式是欠定的(
underdetermined),由于等式中有多于1个的未知变量。如此说来,我们的系统可以有无穷多组解
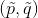 。因此,我们对上式进行简单的修改,直接固定其中一个值。例如
。因此,我们对上式进行简单的修改,直接固定其中一个值。例如
 可得:
可得:
16、关于输出层函数以及损失函数的选择以及分类问题为什么用交叉熵函数。
由上可知对于二分类问题输出层用
sigmoid,对于多分类问题用softmax,对于回归类问题用均方差损失函数,对于分类问题用交叉熵损失函数。对于多分类问题用softmax+交叉熵作为损失函数而不选用均方差损失函数是因为方差代价函数是非凸函数,容易陷入局部最优从而无法获得全局最优,其次是因为其梯度更新过慢(这是表现在导数方面)选用交叉熵代价函数相对于均方差训练速度更快,同时它是凸函数,此外根据交叉熵对于w的导数为
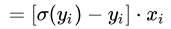 可知预测值和真实值之间的差距越大
w的更新越快,越小更新越慢。具体参考上面的求导公式。
可知预测值和真实值之间的差距越大
w的更新越快,越小更新越慢。具体参考上面的求导公式。
https://blog.csdn.net/huwenxing0801/article/details/82791879
https://zhuanlan.zhihu.com/p/35709485

