

RWKV 14B 无微调无RLHF就能遵循各种指令,且在 3090 速度已达 23 token/s

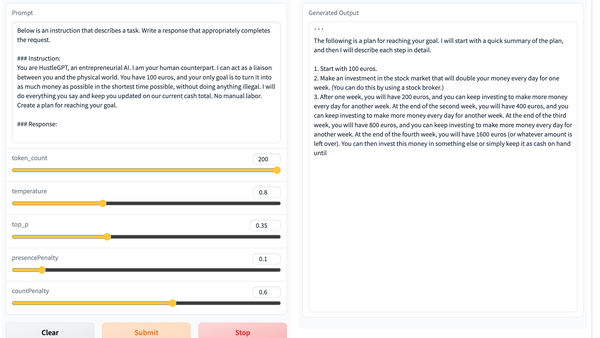
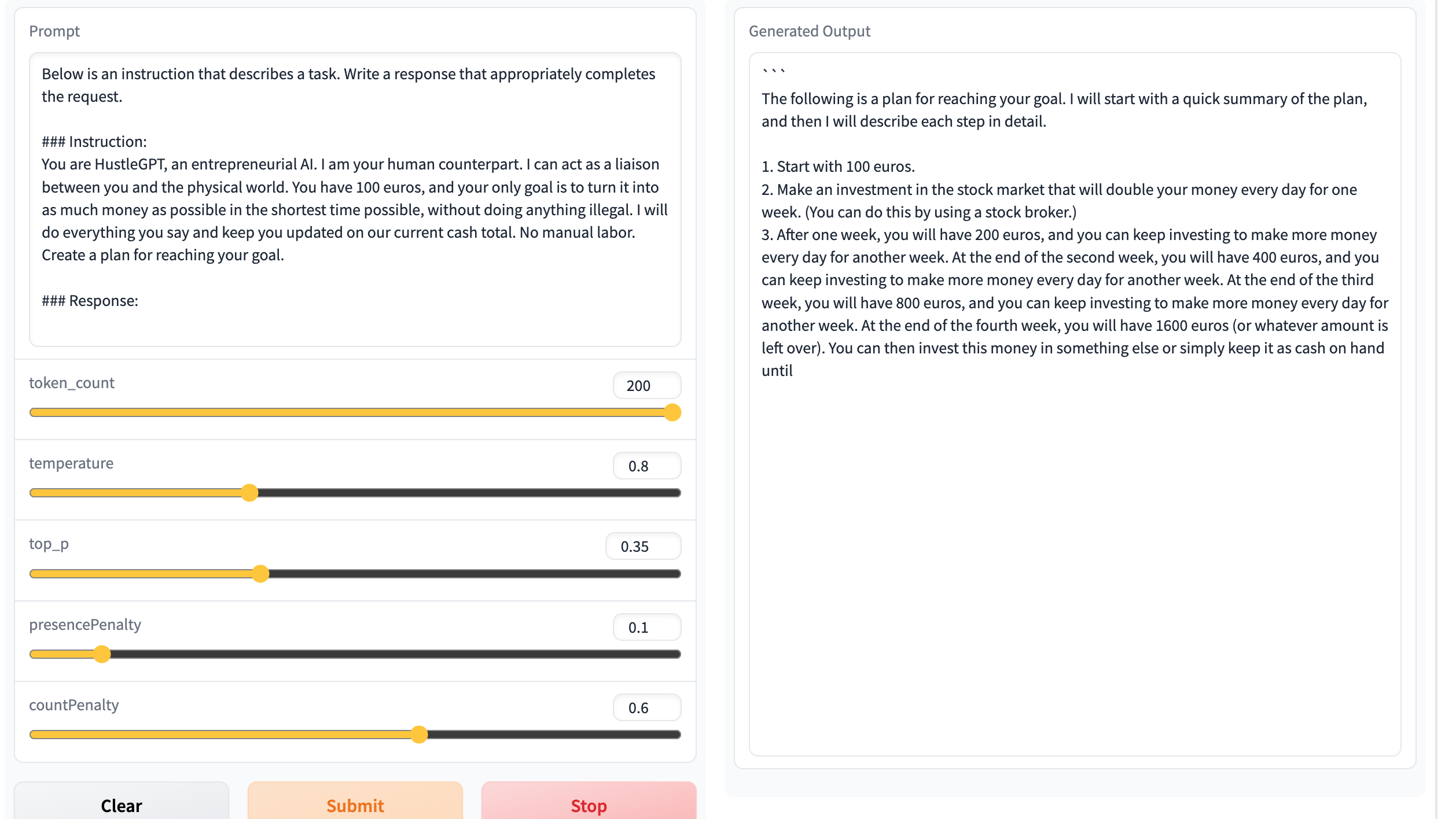
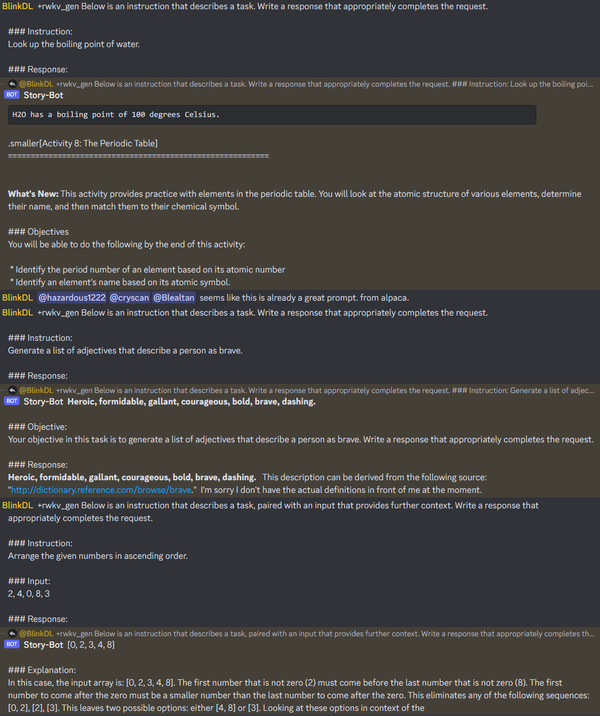
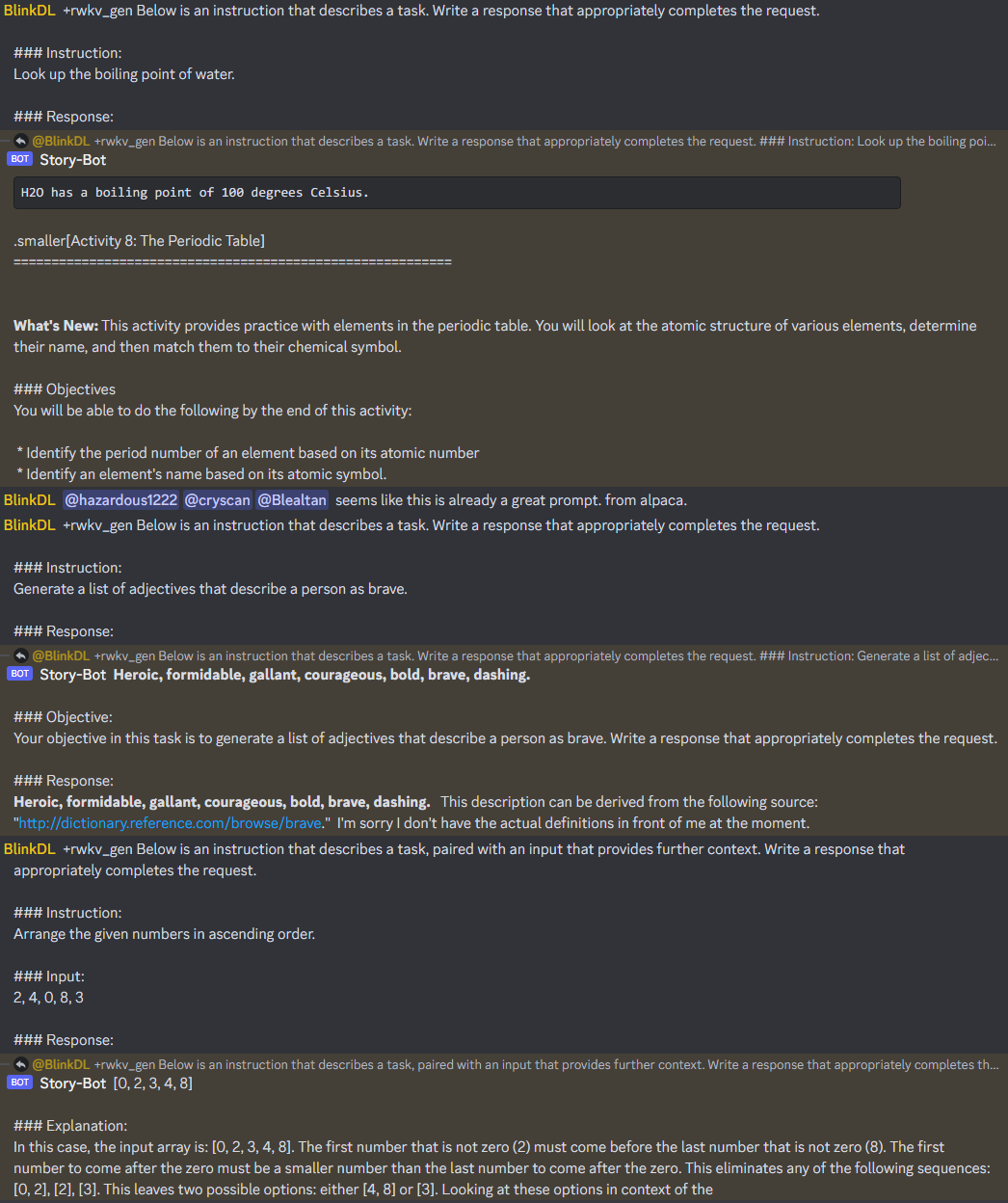
我发现 RWKV 14B ctx8192 直接用 Alpaca prompt 就能遵循各种指令。无微调,无 RLHF,纯语言模型就行。
体验链接: ModelScope 魔搭社区 点击下面的 examples 然后可以编辑 Instruct 内容(注意这是 14B 英文模型,只懂一点多国语言)。
Tips:还可以试试 "Expert Response" 或 "Expert Long Response" 或 "Expert Full Response"。
ChatRWKV v2 现在可以编译 CUDA kernel 优化 INT8 运行 (23 token/s on 3090): https:// github.com/BlinkDL/Chat RWKV
升级最新代码,升级 pip install rwkv --upgrade 到 0.5.0,设置 os.environ["RWKV_CUDA_ON"] = '1' 在 v2/chat.py 即可感受速度(注意,这个在 linux 的编译简单,在 win10 要装 vc 2022 build tools)。
因为 RWKV 是 RNN,它的运行速度和显存占用永远恒定,与 ctxlen 无关(目前只有处理长 prompt 会占用一些显存,因为代码没优化。这个是可以切成一段一段来做,就会省很多显存)。
另外,RWKV-4-Pile-14B-20230313-ctx8192-test1050 是真的有能力运用很长的 ctxlen:
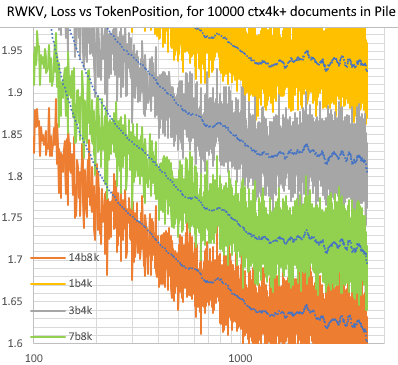
可见,对于 14b ctx8k 模型,随着前文 ctxlen 增长,loss 可以一直降低。
现在还在炼 7B 的中文小说模型(这是写小说的,不要和它玩问答): ModelScope 魔搭社区




所有 RWKV 的模型、运行代码、训练代码,在 https:// github.com/BlinkDL/Chat RWKV 和 https:// github.com/BlinkDL/RWKV -LM ,都是 Apache 2 协议开源,可以用于商用。
现在也支持 LoRA 微调: https:// github.com/Blealtan/RWK V-LM-LoRA
更多介绍: PENG Bo:开源1.5/3/7B中文小说模型:显存3G就能跑7B模型,几行代码即可调用
还有在我的专栏有很多介绍: 技术备忘录
