|
|
|


本文介绍字符串函数的基本语法和示例。
日志服务支持如下字符串函数。
重要
在日志服务分析语句中,表示字符串的字符必须使用单引号('')包裹,无符号包裹或被双引号("")包裹的字符表示字段名或列名。例如:
'status'
表示字符串status,
status
或
"status"
表示日志字段status。
|
函数名称 |
语法 |
说明 |
支持SQL |
支持SPL |
|
chr( x ) |
将ASCII码转换为字符。 |
√ |
√ |
|
|
codepoint( x ) |
将字符转换为ASCII码。 |
√ |
√ |
|
|
concat( x , y ...) |
将多个字符串拼接成一个字符串。 |
√ |
√ |
|
|
from_utf8( x ) |
将二进制字符串解码为UTF-8编码格式,并使用默认字符U+FFFD替换无效的UTF-8字符。 |
√ |
√ |
|
|
from_utf8( x , replace_string ) |
将二进制字符串解码为UTF-8编码格式,并使用自定义字符串替换无效的UTF-8字符。 |
√ |
√ |
|
|
length( x ) |
计算字符串的长度。 |
√ |
√ |
|
|
levenshtein_distance( x , y ) |
计算 x 和 y 之间的最小编辑距离。 |
√ |
× |
|
|
lower( x ) |
将字符串转换为小写形式。 |
√ |
√ |
|
|
lpad( x , length , lpad_string ) |
在字符串的开头填充指定字符,直到指定长度后返回结果字符串。 |
√ |
√ |
|
|
ltrim( x ) |
删除字符串开头的空格。 |
√ |
√ |
|
|
normalize( x ) |
使用NFC格式将字符串格式化。 |
√ |
× |
|
|
position( sub_string in x ) |
返回目标子串在字符串中的位置。 |
√ |
× |
|
|
replace( x , sub_string ) |
删除字符串中匹配的字符。 |
√ |
√ |
|
|
replace( x , sub_string , replace_string ) |
将字符串中所匹配的字符替换为其他指定字符。 |
√ |
√ |
|
|
reverse( x ) |
返回反向顺序的字符串。 |
√ |
√ |
|
|
rpad( x , length , rpad_string ) |
在字符串的尾部填充指定字符,直到指定长度后返回结果字符串。 |
√ |
√ |
|
|
rtrim( x ) |
删除字符串中结尾的空格。 |
√ |
√ |
|
|
split( x , delimeter ) |
使用指定的分隔符拆分字符串,并返回子串集合。 |
√ |
× |
|
|
split( x , delimeter , limit ) |
通过指定的分隔符拆分字符串并使用 limit 限制字符串拆分的个数,然后返回拆分后的子串集合。 |
√ |
× |
|
|
split_part( x , delimeter , part ) |
使用指定的分隔符拆分字符串,并返回指定位置的内容。 |
√ |
√ |
|
|
split_to_map( x , delimiter01 , delimiter02 ) |
使用指定的第一个分隔符拆分字符串,然后再使用指定的第二个分隔符进行第二次拆分。 |
√ |
× |
|
|
strpos( x , sub_string ) |
返回目标子串在字符串中的位置。与position( sub_string in x )函数等价。 |
√ |
√ |
|
|
substr( x , start ) |
返回字符串中指定位置的子串。 |
√ |
√ |
|
|
substr( x , start , length ) |
返回字符串中指定位置的子串,并指定子串长度。 |
√ |
√ |
|
|
to_utf8( x ) |
将字符串转换为UTF-8编码格式。 |
√ |
√ |
|
|
trim( x ) |
删除字符串中开头和结尾的空格。 |
√ |
√ |
|
|
upper( x ) |
将字符串转化为大写形式。 |
√ |
√ |
chr函数
chr函数用于将ASCII码转换为字符。
语法
chr(x)参数说明
|
参数 |
说明 |
|
x |
ASCII码。 |
返回值类型
varchar类型。
示例
判断
region
字段值的首字母是否是c开头,其中99为ASCII码,代表小写字母c。
-
字段样例
region:cn-shanghai -
查询和分析语句( 调试 )
* | SELECT substr(region, 1, 1) = chr(99) -
查询和分析结果

codepoint函数
codepoint函数用于将字符转换为ASCII码。
语法
codepoint(x)参数说明
|
参数 |
说明 |
|
x |
参数值为varchar类型。 |
返回值类型
integer类型。
示例
判断
region
字段值的首字母是否是c开头,其中99为ASCII码,代表小写字母c。
-
字段样例
upstream_status:200 -
查询和分析语句( 调试 )
* | SELECT codepoint(cast (substr(region, 1, 1) AS char(1))) = 99 -
查询和分析结果

concat函数
concat函数用于将多个字符串拼接成一个字符串。
语法
concat(x, y...)参数说明
|
参数 |
说明 |
|
x |
参数值为varchar类型。 |
|
y |
参数值为varchar类型。 |
返回值类型
varchar类型。
示例
将
region
字段和
request_method
字段的值拼接为一个字符串。
-
字段样例
region:cn-shanghai time:14/Jul/2021:02:19:40 -
查询和分析语句( 调试 )
* | SELECT concat(region, '-', time) -
查询和分析结果

from_utf8函数
from_utf8函数用于将二进制字符串解码为UTF-8编码格式。
语法
-
使用默认字符U+FFFD替换无效的UTF-8字符。
from_utf8(x) -
使用自定义字符替换无效的UTF-8字符。
from_utf8(x,replace_string)
参数说明
|
参数 |
说明 |
|
x |
参数值为binary类型。 |
|
replace_string |
用于替换的字符串。只能为单个字符或空格。 |
返回值类型
varchar类型。
示例


length函数
length函数用于计算字符串的长度。
语法
length(x)参数说明
|
参数 |
|
|
x |
参数值为varchar类型。 |
返回值类型
bigint类型。
示例
计算
http_user_agent
字段值的长度。
-
字段样例
http_user_agent:Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.2 (KHTML, like Gecko) Chrome/22.0.1216.0 Safari/537.2 -
查询和分析语句( 调试 )
* | SELECT length(http_user_agent) -
查询和分析结果

levenshtein_distance函数
levenshtein_distance函数用于计算两个字符串的最小编辑距离。
语法
levenshtein_distance(x, y)参数说明
|
参数 |
说明 |
|
x |
参数值为varchar类型。 |
|
y |
参数值为varchar类型。 |
返回值类型
bigint类型。
示例
查询
instance_id
字段值和
owner_id
字段值的最小编辑距离。
-
字段样例
instance_id:i-01 owner_id:owner-01 -
查询和分析语句( 调试 )
* | SELECT levenshtein_distance(owner_id, instance_id) -
查询和分析结果

lower函数
lower函数用于将字符串转换为小写形式。
语法
lower(x)参数说明
|
参数 |
说明 |
|
x |
参数值为varchar类型。 |
返回值类型
varchar类型。
示例
将
request_method
字段的值转换为小写形式。
-
字段样例
request_method:GET -
查询和分析语句( 调试 )
* | SELECT lower(request_method) -
查询和分析结果

lpad函数
lpad函数用于在目标字符串的开头填充指定的字符,直到指定长度后返回结果字符串。
语法
lpad(x, length, lpad_string)参数说明
|
参数 |
说明 |
|
x |
参数值为varchar类型。 |
|
length |
整数,用于指定结果字符串的长度。
|
|
lpad_string |
新填充的字符。 |
返回值类型
varchar类型。
示例
将
instance_id
字段值的长度补充到10位,不足10位时,在字段值的开头补充0。
-
字段样例
instance_id:i-01 -
查询和分析语句( 调试 )
* | SELECT lpad(instance_id, 10, '0') -
查询和分析结果

ltrim函数
ltrim函数用于删除字符串中开头的空格。
语法
ltrim(x)参数说明
|
参数 |
说明 |
|
x |
参数值为varchar类型。 |
返回值类型
varchar类型。
示例
删除
region
字段值开头的空格。
-
字段样例
region: cn-shanghai -
查询和分析语句( 调试 )
* | SELECT ltrim(region) -
查询和分析结果

normalize函数
normalize函数使用NFC格式将字符串格式化。
语法
normalize(x)参数说明
|
参数 |
说明 |
|
x |
参数值为varchar类型。 |
返回值类型
varchar类型。
示例
使用NFC格式将字符串schön格式化。
-
查询和分析语句( 调试 )
* | SELECT normalize('schön') -
查询和分析结果

position函数
position函数用于查询目标子串在字符串中的位置。
语法
position(sub_string in x)参数说明
|
参数 |
说明 |
|
sub_string |
目标子串。 |
|
x |
参数值为varchar类型。 |
返回值类型
int类型,从1开始。如果字符串中不存在目标子串,则返回0。
示例
查询子串
cn
在
region
字段值中位置。
-
字段样例
region:cn-shanghai -
查询和分析语句( 调试 )
* | SELECT position('cn' in region) -
查询和分析结果

replace函数
replace函数用于删除字符串中所匹配的字符或者将字符串中所匹配的字符替换为其他指定字符。
语法
-
删除字符串中所匹配的字符。
replace(x, sub_string) -
将字符串中所匹配的字符替换为其他指定字符。
replace(x, sub_string, replace_string)
参数说明
|
参数 |
说明 |
|
x |
参数值为varchar类型。 |
|
sub_string |
目标子串。 |
|
replace_string |
用于替换的子串。 |
返回值类型
varchar类型。
示例
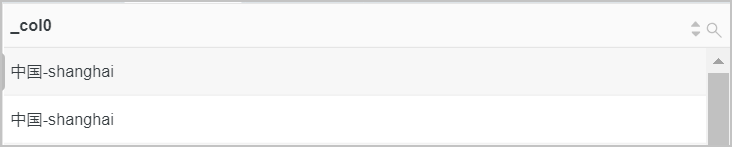

reverse函数
reverse函数用于返回反向顺序的字符串。
语法
reverse(x)参数说明
|
参数 |
说明 |
|
x |
参数值为varchar类型。 |
返回值类型
varchar类型。
示例
将
request_method
字段值反向排序。
-
字段样例
request_method:GET -
查询和分析语句( 调试 )
* | SELECT reverse(request_method) -
查询和分析结果

rpad函数
rpad函数用于在字符串的尾部填充指定的字符,直到指定长度后返回结果字符串。
语法
rpad(x, length, rpad_string)参数说明
|
参数 |
说明 |
|
x |
参数值为varchar类型。 |
|
length |
整数,用于指定结果字符串的长度。
|
|
rpad_string |
新填充的字符。 |
返回值类型
varchar类型。
示例
将
instance_id
字段值的长度补充到10位,不足10位时,在字段值的尾部补充0。
-
字段样例
instance_id:i-01 -
查询和分析语句( 调试 )
* | SELECT rpad(instance_id, 10, '0') -
查询和分析结果

rtrim函数
rtrim函数用于删除字符串中结尾的空格。
语法
rtrim(x)参数说明
|
参数 |
说明 |
|
x |
参数值为varchar类型。 |
返回值类型
varchar类型。
示例
删除
instance_id
字段值中结尾的空格。
-
字段样例
instance_id:i-01 -
查询和分析语句( 调试 )
* | SELECT rtrim(instance_id) -
查询和分析结果

split函数
split函数用于通过指定的分隔符拆分字符串,并返回拆分后的子串集合。
语法
-
通过指定的分隔符拆分字符串,并返回拆分后的子串集合。
split(x, delimeter) -
通过指定的分隔符拆分字符串并使用 limit 限制字符串拆分的个数,然后返回拆分后的子串集合。
split(x,delimeter,limit)
参数说明
|
参数 |
说明 |
|
x |
参数值为varchar类型。 |
|
delimeter |
分隔符。 |
|
limit |
限制字符串拆分的个数,大于0的整数。 |
返回值类型
array类型。
示例


split_part函数
split_part函数通过指定的分隔符拆分字符串,并返回指定位置的内容。
语法
split_part(x, delimeter, part)参数说明
|
参数 |
说明 |
|
x |
参数值为varchar类型。 |
|
delimeter |
分隔符。 |
|
part |
大于0的整数。 |
返回值类型
varchar类型。
示例
使用英文问号(?)拆分
request_uri
字段的值并返回第一个子串(即文件路径部分),然后统计不同路径对应的请求数量。
-
字段样例
request_uri: /request/path-2/file-6?name=value&age=18 request_uri: /request/path-2/file-0?name=value&age=18 request_uri: /request/path-3/file-2?name=value&age=18 -
查询和分析语句( 调试 )
* | SELECT count(*) AS PV, split_part(request_uri, '?', 1) AS Path GROUP BY ORDER BY pv DESC -
查询和分析结果

split_to_map函数
split_to_map函数用于使用指定的第一个分隔符拆分字符串,然后再使用指定的第二个分隔符进行第二次拆分。
语法
split_to_map(x, delimiter01, delimiter02)参数说明
|
参数 |
说明 |
|
x |
参数值为varchar类型。 |
|
delimeter01 |
分隔符。 |
|
delimeter02 |
分隔符。 |
返回值类型
map类型。
示例
使用英文逗号(,)和英文冒号(:)拆分
time
字段的值,返回结果为MAP类型。
-
字段样例
time:upstream_response_time:"80", request_time:"40" -
查询和分析语句
* | SELECT split_to_map(time, ',', ':') -
查询和分析结果

strpos函数
strpos函数用于返回目标子串在字符串中的位置。与position函数等价。
语法
strpos(x, sub_string)参数说明
|
参数 |
说明 |
|
x |
参数值为varchar类型。 |
|
sub_string |
目标子串。 |
返回值类型
int类型,从1开始。如果字符串中不存在目标子串,则返回0。
示例
返回字母H在
server_protocol
字段值中的位置。
-
查询和分析语句( 调试 )
* | SELECT strpos(server_protocol, 'H') -
查询和分析结果

substr函数
substr函数用于返回字符串中指定位置的子串。
语法
-
返回字符串中指定位置的子串。
substr(x, start) -
返回字符串中指定位置的子串,并指定子串长度。
substr(x,start,length)
参数说明
|
参数 |
说明 |
|
x |
参数值为varchar类型。 |
|
start |
开始提取子串的位置,从1开始。 |
|
length |
子串的长度。 |
返回值类型
varchar类型。
示例
提取
server_protocol
字段值中的前4个字符(即
HTTP
部分),然后统计HTTP协议对应的请求数量。
-
字段样例
server_protocol:HTTP/2.0 -
查询和分析语句( 调试 )
* | SELECT substr(server_protocol, 1, 4) AS protocol, count(*) AS count GROUP BY server_protocol -
查询和分析结果

to_utf8函数
to_utf8函数用于将字符串转换为UTF-8编码格式。
语法
to_utf8(x)参数说明
|
参数 |
说明 |
|
x |
参数值为varchar类型。 |
返回值类型
varbinary类型。
示例
将字符串log转换为UTF-8编码格式。
-
查询和分析语句( 调试 )
* | SELECT to_utf8('log') -
查询和分析结果

trim函数
trim函数用于删除字符串中开头和结尾的空格。
语法
trim(x)参数说明
|
参数 |
说明 |
|
x |
参数值为varchar类型。 |
返回值类型
varchar类型。
示例
删除
instance_id
字段值的开头和结尾的空格。
-
字段样例
instance_id: i-01 -
查询和分析语句( 调试 )
* | SELECT trim(instance_id) -
查询和分析结果
upper函数
upper函数用于将目标字符串转化为大写形式。
语法
upper(x)参数说明
|
参数 |
说明 |
|
x |
参数值为varchar类型。 |
返回值类型
varchar类型。
示例
将
region
字段值转换为大写形式。
-
字段样例
region:cn-shanghai -
查询和分析语句( 调试 )
* | SELECT upper(region) -
查询和分析结果
