使用merge的时候可以选择多个key作为复合可以来对齐合并。
1.1.1 通过on指定数据合并对齐的列
In [41]: left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
....: 'key2': ['K0', 'K1', 'K0', 'K1'],
....: 'A': ['A0', 'A1', 'A2', 'A3'],
....: 'B': ['B0', 'B1', 'B2', 'B3']})
....:
In [42]: right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
....: 'key2': ['K0', 'K0', 'K0', 'K0'],
....: 'C': ['C0', 'C1', 'C2', 'C3'],
....: 'D': ['D0', 'D1', 'D2', 'D3']})
....:
In [43]: result = pd.merge(left, right, on=['key1', 'key2'])
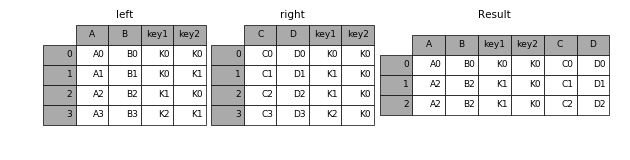
没有指定how的话默认使用inner方法。
how的方法有:
只保留左表的所有数据
In [44]: result = pd.merge(left, right, how='left', on=['key1', 'key2'])
right
只保留右表的所有数据
In [45]: result = pd.merge(left, right, how='right', on=['key1', 'key2'])
outer
保留两个表的所有信息
In [46]: result = pd.merge(left, right, how='outer', on=['key1', 'key2'])
inner
只保留两个表中公共部分的信息
In [47]: result = pd.merge(left, right, how='inner', on=['key1', 'key2'])
1.2 indicator
v0.17.0 版本的pandas开始还支持一个indicator的参数,如果置True的时候,输出结果会增加一列 ’ _merge’。_merge列可以取三个值
- left_only 只在左表中
- right_only 只在右表中
- both 两个表中都有
1.3 join方法
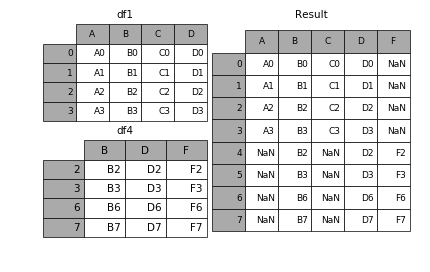
dataframe内置的join方法是一种快速合并的方法。它默认以index作为对齐的列。
1.3.1 how 参数
join中的how参数和merge中的how参数一样,用来指定表合并保留数据的规则。
具体可见前面的 how 说明。
1.3.2 on 参数
在实际应用中如果右表的索引值正是左表的某一列的值,这时可以通过将 右表的索引 和 左表的列 对齐合并这样灵活的方式进行合并。
In [59]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
....: 'B': ['B0', 'B1', 'B2', 'B3'],
....: 'key': ['K0', 'K1', 'K0', 'K1']})
....:
In [60]: right = pd.DataFrame({'C': ['C0', 'C1'],
....: 'D': ['D0', 'D1']},
....: index=['K0', 'K1'])
....:
In [61]: result = left.join(right, on='key')
1.3.3 suffix后缀参数
如果和表合并的过程中遇到有一列两个表都同名,但是值不同,合并的时候又都想保留下来,就可以用suffixes给每个表的重复列名增加后缀。
In [79]: result = pd.merge(left, right, on='k', suffixes=['_l', '_r'])
* 另外还有lsuffix 和 rsuffix分别指定左表的后缀和右表的后缀。
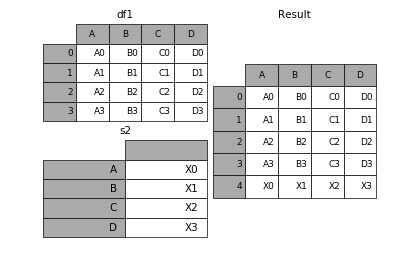
1.4 组合多个dataframe
一次组合多个dataframe的时候可以传入元素为dataframe的列表或者tuple。一次join多个,一次解决多次烦恼~
In [83]: right2 = pd.DataFrame({'v': [7, 8, 9]}, index=['K1', 'K1', 'K2'])
In [84]: result = left.join([right, right2])
1.5 更新表的nan值
1.5.1 combine_first
如果一个表的nan值,在另一个表相同位置(相同索引和相同列)可以找到,则可以通过combine_first来更新数据
1.5.2 update
如果要用一张表中的数据来更新另一张表的数据则可以用update来实现
1.5.3 combine_first 和 update 的区别
使用combine_first会只更新左表的nan值。而update则会更新左表的所有能在右表中找到的值(两表位置相对应)。
parent_teacher_data['address'] = parent_teacher_data['country']+parent_teacher_data['province']+parent_teacher_data['city']+parent_teacher_data['county']
就可以把四列合并成新的列address
如果某一列是非str类型的数据,那么我们需要用到map(s
在上一篇文章中,我整理了pandas在数据合并和重塑中常用到的concat方法的使用说明。在这里,将接着介绍pandas中也常常用到的join 和merge方法
merge
pandas的merge方法提供了一种类似于SQL的内存链接操作,官网文档提到它的性能会比其他开源语言的数据操作(例如R)要高效。
和SQL语句的对比可以看这里
merge的参数
on:列名,join用来对齐的那一列的名字,用到这个参数的时候一定要保证左表和右表用来对齐的那一列都有相同的列名。
left_on:左表对齐的列,可以是列名,也可以是和dataframe同样长度的arrays。
right_on:右表对齐的列,可
pandas.merge()是pandas库中用于合并两个或多个DataFrame对象的函数,其常用的参数有以下几个:
left:要合并的左侧DataFrame。
right:要合并的右侧DataFrame。
how:指定合并方式,包括‘left’、‘right’、‘outer’和‘inner’四种。
on:指定按照哪些列进行合并,可以是单个列名或包含多个列名的列表。
left_on和right_on:指定左侧和右侧DataFrame中进行合并的列名,如果两个DataFrame中
快速浏览一、append与assign1.append方法(加行)(a)append利用序列添加行(必须指定name)(b)append用DataFrame添加表(多行)2.assign方法(加列)二、combine与update(表的填充)1.comine方法(a)填充对象(b)一些例子(c)combine_first方法2. update方法(a)三个特点(b)例子三、concat方法四、merge与join1.merge函数2. join函数五、问题与练习阶段总结Reference
#从清华镜像拉装1.0.3版本的Pandas
!pip install -i https://pypi.t
pandas和python标准库提供了一整套高级、灵活的、高效的核心函数和算法将数据规整化为你想要的形式!
本篇博客主要介绍:
合并数据集:.merge()、.concat()等方法,类似于SQL或其他关系型数据库的连接操作。
合并数据集
1) merge 函数参数
最近在工作中,遇到了数据合并、连接的问题,故整理如下,供需要者参考~一、concat:沿着一条轴,将多个对象堆叠到一起 concat方法相当于数据库中的全连接(union all),它不仅可以指定连接的方式(outer join或inner join)还可以指定按照某个轴进行连接。与数据库不同的是,它不会去重,但是可以使用drop_duplicates方法达到去重的效果。concat(...
concat函数是在pandas底下的方法,可以将数据根据不同的轴作简单的融合
pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False,
keys=None, levels=None, names=None, verify_integrity=False)121212
Pandas中Merge函数的使用Merge函数按index合并
Merge函数按index合并
有的时候需要按列去匹配(比如说两个表单colmun有些相同的,又有些不同的,这个时候按左表或者右表匹配如果还是用on这个简单参数,那就匹配不上),然而找了好多,没找到合适的,发现原来可以采用Merge函数里的一些方法来实现,首先将表单转置(df.T),经过转置后的column就变成了index,此时采用merge函数里的left_index和rght_index参数,即可实现表单的合并。之后再将合并的表单转置
import pandas as pd
pd.merge(dataframe1,dataframe2,left_index=True,right_index=True)
修改合并的方式,可以更改merge函数中的一个属性how:
left:只使用左框架中的键,类似于SQL左外部连接;保留密钥顺序。
right:只使用右框架中的键,类似于SQL右外部联接;保留密钥顺序。
outer:使用来自两个帧的键的并集,类似于SQL完全外部连接;按字典顺序对键排序。
inner:使用两个帧的键的交集,类似于
1. Merge
首先merge的操作非常类似sql里面的join,实现将两个Dataframe根据一些共有的列连接起来,当然,在实际场景中,这些共有列一般是Id,
连接方式也丰富多样,可以选择inner(默认),left,right,out...
Pandas数据合并与拼接的5种方法。必须存在于左右两个DataFrame中,如果没有指定且其他参数也没有指定,则以两个DataFrame列名交集作为连接键;suffixes:字符串值组成的元组,用于指定当左右DataFrame存在相同列名时在列名后面附加的后缀名称,默认为('_x', '_y');left_on:左侧DataFrame中用于连接键的列名,这个参数左右列名不同但代表的含义相同时非常的有用;没有指定连接键,默认用重叠列名,没有指定连接方式,默认inner内连接(取key的交集)
Merge, Join, Concat大家好,我有回来啦,这周更新的有点慢,主要是因为我更新了个人简历哈哈,如果感兴趣的朋友可以去看看哈:个人认为还是很漂亮的~,不得不说,很多时候老外的设计能力还是很强。好了,有点扯远了,这一期我想和大家分享的是pandas中最常见的几种方法,这些方法如果你学会了,某种程度上可以很好的替代Excel,这篇文章是pandas之旅的第三篇,主要会从以下几个方面和大家分...
文章目录前言参数on参数 index参数indicator参数 suffixes
根据 莫烦Python的教程 总结写成,以便自己复习和使用,这里我就不哟林地挂原创了????。
on:以列为索引进行合并
left = pd.DataFrame({'key':['K0','K1','K2','K3'],
'A':['A0','A1','A2','A3'],
'B':['B0','B1','B2','B3']})
在进行数据合并时,Excel 数据,我们用到最多的是 vlookup 函数,SQL 数据库数据,join 用得最多,都可以实现多表匹配查询,合并等功能。Python 的 Pandas 也有有类似的功能函数,就是我们今天要介绍的 pd.merge()
**内容提要:**
1. merge() 方法介绍
2. inner join merge 内连接
3. outer join merge 外连接
4. left join merge 左连接
5. right join merge 右连接