现象:
在数据库新增的时候,有时需要判断此条数据是否已经存在,防止插入 重复的数据。有时是根据条件查询list判断list是否有值、有时是根据条件返回查询的条数进行判断。
方法:
这里是有exists函数进行判断
一:exists函数的使用
1:使用exists判断不存时的情况
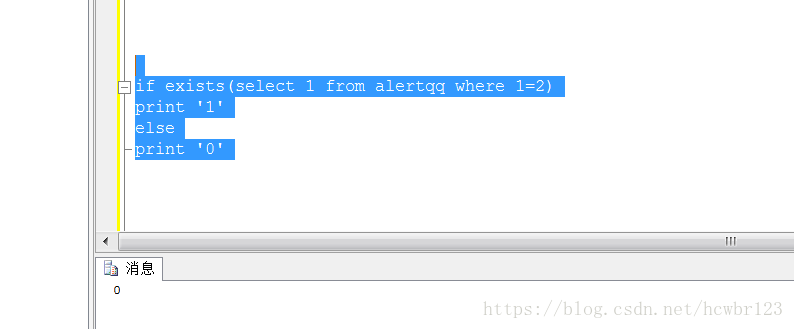
2:使用exists判断结果存在时的情况

以上是exists函数的使用但是只是对结果进行了输出 没有进行返回。后台无法获取进行判断
二:exists函数结合case when 对结果进行返回
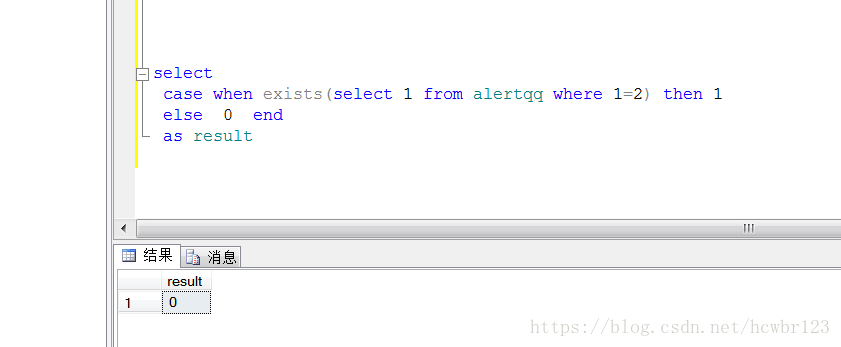
1:将结果返回判断,首先结合case when函数获取结果,存在返回1 不存在则返回0
2:建立单元测试方法
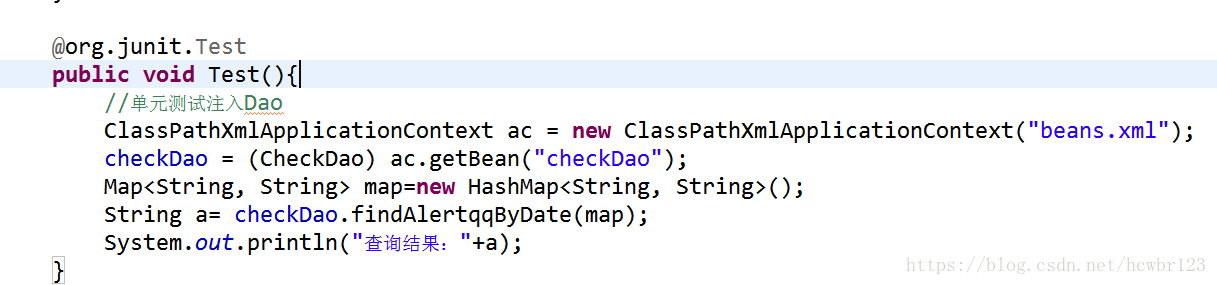
3:mybatis sql编写语句检查是否存在 此处条件写死1=1 方便测试 实际可结合其他条件进行改版

4:测试存在时返回的结果

5:测试不存在时的返回

:

三:将结果用int类型返回方便判断

2:sql返回result为int

3:可以实现转换 java得到int数字,但是如果数据库语句返回的值不能转换为数字则会报错

最近有个需求是要跨库进行
数据
同步,两个
数据
库分布在两台物理计算机上,自动定期同步可以通过
SQL
Server代理作业来实现,但是前提是需要编写一个存储过程来实现同步逻辑处理。这里的存储过程用的不是opendatasource,而是用的链接服务器来实现的。存储过程创建在IP1:192.168.0.3服务器上,需要将视图v_custom的客户信息同步到IP2:192.168.0.10服务器上的t_custom表中。逻辑是如果不存在则插入,存在则更新字段。
create PROCEDURE [dbo].[p_pm_项目平台客户批量同步到报销平台](
@destserver nvarchar(
不相关子
查询
:子
查询
的
查询
条件不依赖于父
查询
的称为不相关子
查询
相关子
查询
:子
查询
的
查询
条件依赖于外层父
查询
的某个属性值的称为相关子
查询
。带Exists的子
查询
就是相关子
查询
Exists表示存在量词:带有Exists的子
查询
不返回任何记录的
数据
,只返回逻辑值“True”或“False”
2、表结构
选课表:学号StudentNo、课程号CourseNo
学生表:学号Stude...
根据某一条件从
数据
库表中
查询
『有』与『没有』,只有两种状态,那为什么在写
SQL
的时候,还要SELECT count(*) 呢?无论是刚入道的程序员新星,还是精湛沙场多年的程序员老白,都是一如既往的count。
目前多数人的写法
多次REVIEW代码时,发现如现现象:业务代码中,需要根据一个或多个条件,
查询
是否存在
记录,不关心有多少条记录。普遍的
SQL
及代码写法如下:
//
SQL
写法:
SELECTcount(*)FROMtableWHEREa=1ANDb=2
--判断
数据
库
是否存在
if exists(select * from master..sysdatabases where name=N '库名 ')
print 'exists '
print 'not exists '
---------------
-- 判断要创建的表名
是否存在
if e
SELECT c.CustomerId,CompanyName FROM Customers c
WHERE EXISTS(
SELECT OrderID FROM Orders o WHERE o.CustomerID=c.CustomerID)
这里面的EXISTS是如何运作呢?子
查询
返回的是OrderId字段,可是外面的
查询
要找的是CustomerID和CompanyName字段,这两个字段肯定不在OrderID里面啊,这是.
查询
数据
是指从
数据
库中获取所需要的
数据
。
查询
数据
是
数据
库操作中最常用,也是最重要的操作。用户可以根据自己对
数据
的需求,使用不同的
查询
方式。通过不同的
查询
方式,可以获得不同的
数据
。在My
SQL
中是使用SELECT语句来
查询
数据
的。...
<br />sql判断
是否存在
<br />--判断
数据
库
是否存在
<br />if exists(select * from master..sysdatabases where name=N'库名') <br />print 'exists' <br />else <br />print 'not exists' <br />--------------- <br />-- 判断要创建的表名
是否存在
<br />if exists (select * from dbo.sysobjects where

