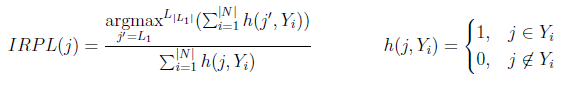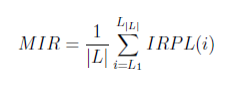在处理分类问题时,类别失衡是我们经常遇到的问题,也是经常出现在实际使用场景中的问题。类别失衡会给预测任务带来挑战,并且会导致少数类别的预测效果较差因为大部分机器学习算法的假设场景是类别(数据)平衡的前提。
分类是一种有监督学习技术,是将目标数据分类至提前已经定义好的类别中。大多数有监督学习方法,基于一种正式的设定,其数据对象用特征向量的形式表示,每一个对象唯一对应于一组不相交的类标签(目标)。主要有以下四大类:
# -*- coding: utf-8 -*-
# Importing required Library
import numpy as np
import pandas as pd
import random
from sklearn.datasets import make_classification
from sklearn.neighbors import NearestNeighbors
def create_dataset(n_sample=1000):
Create a unevenly distributed sample data set multilabel
classification using make_classification function
nsample: int, Number of sample to be created
return
X: pandas.DataFrame, feature vector dataframe with 10 features
y: pandas.DataFrame, target vector dataframe with 5 labels
X, y = make_classification(n_classes=5, class_sep=2,
weights=[0.1,0.025, 0.205, 0.008, 0.9], n_informative=3, n_redundant=1, flip_y=0,
n_features=10, n_clusters_per_class=1, n_samples=1000, random_state=10)
y = pd.get_dummies(y, prefix='class')
return pd.DataFrame(X), y
def get_tail_label(df):
Give tail label colums of the given target dataframe
df: pandas.DataFrame, target label df whose tail label has to identified
return
tail_label: list, a list containing column name of all the tail label
columns = df.columns
n = len(columns)
irpl = np.zeros(n)
for column in range(n):
irpl[column] = df[columns[column]].value_counts()[1]
irpl = max(irpl)/irpl
mir = np.average(irpl)
tail_label = []
for i in range(n):
if irpl[i] > mir:
tail_label.append(columns[i])
return tail_label
def get_index(df):
give the index of all tail_label rows
df: pandas.DataFrame, target label df from which index for tail label has to identified
return
index: list, a list containing index number of all the tail label
tail_labels = get_tail_label(df)
index = set()
for tail_label in tail_labels:
sub_index = set(df[df[tail_label]==1].index)
index = index.union(sub_index)
return list(index)
def get_minority_instace(X, y):
Give minority dataframe containing all the tail labels
X: pandas.DataFrame, the feature vector dataframe
y: pandas.DataFrame, the target vector dataframe
return
X_sub: pandas.DataFrame, the feature vector minority dataframe
y_sub: pandas.DataFrame, the target vector minority dataframe
index = get_index(y)
X_sub = X[X.index.isin(index)].reset_index(drop = True)
y_sub = y[y.index.isin(index)].reset_index(drop = True)
return X_sub, y_sub
def nearest_neighbour(X):
Give index of 5 nearest neighbor of all the instance
X: np.array, array whose nearest neighbor has to find
return
indices: list of list, index of 5 NN of each element in X
nbs=NearestNeighbors(n_neighbors=5,metric='euclidean',algorithm='kd_tree').fit(X)
euclidean,indices= nbs.kneighbors(X)
return indices
def MLSMOTE(X,y, n_sample):
Give the augmented data using MLSMOTE algorithm
X: pandas.DataFrame, input vector DataFrame
y: pandas.DataFrame, feature vector dataframe
n_sample: int, number of newly generated sample
return
new_X: pandas.DataFrame, augmented feature vector data
target: pandas.DataFrame, augmented target vector data
indices2 = nearest_neighbour(X)
n = len(indices2)
new_X = np.zeros((n_sample, X.shape[1]))
target = np.zeros((n_sample, y.shape[1]))
for i in range(n_sample):
reference = random.randint(0,n-1)
neighbour = random.choice(indices2[reference,1:])
all_point = indices2[reference]
nn_df = y[y.index.isin(all_point)]
ser = nn_df.sum(axis = 0, skipna = True)
target[i] = np.array([1 if val>2 else 0 for val in ser])
ratio = random.random()
gap = X.loc[reference,:] - X.loc[neighbour,:]
new_X[i] = np.array(X.loc[reference,:] + ratio * gap)
new_X = pd.DataFrame(new_X, columns=X.columns)
target = pd.DataFrame(target, columns=y.columns)
new_X = pd.concat([X, new_X], axis=0)
target = pd.concat([y, target], axis=0)
return new_X, target
if __name__=='__main__':
main function to use the MLSMOTE
X, y = create_dataset() #Creating a Dataframe
X_sub, y_sub = get_minority_instace(X, y) #Getting minority instance of that datframe
X_res,y_res =MLSMOTE(X_sub, y_sub, 100) #Applying MLSMOTE to augment the dataframe
处理在多标签分类任务中数据不平衡问题——多标签合成少数类过采样技术(Multi label Synthetic Minority Over-sampling Technique,MLSMOTE)
Multi label Synthetic Minority Over-sampling Technique,MLSMOTEMLSMOTE代码(Python)在处理分类问题时,类别失衡是我们经常遇到的问题,也是经常出现在实际使用场景中的问题。类别失衡会给预测任务带来挑战,并且会导致少数类别的预测效果较差因为大部分机器学习算法的假设场景是类别(数据)平衡的前提。本文原始链接 MLSMOTE分类是一种有监督学习技术,是将目标数据分类至提前已经定义好的类别中。大多数有监督学习方法,基于一种正式的设定,
????categorical_crossentropy????
????binary_crossentropy????
二分类、多分类与多标签问题的区别及对应损失函数的选择
这篇主要分析了so
不平衡的MLC
对于单标签分类(SLC)问题,已经对不平衡数据集对分类模型的有效性的影响进行了彻底和广泛的研究。 这些问题需要二进制分类输出来预测给定输入实例中单个类的存在。 在多标签分类(MLC)的域中,单个输入实例可能具有与其关联的多个类。 由于这种固有的标签并发性,应用于单标签分类问题的许多数据集不平衡补救措施在应用于多标签数据集(MLD)时均无效且可能有害。 例如,最常见的SLC不平衡补救措施之一是随机过采样。 也就是说,随机复制具有不常见标签的实例。 如果将这种幼稚的方法应用于MLD,我们很可能会复制在输入实例中同时存在的不想要的标签,甚至可能加剧数据集失衡的严重性。
这是对不平衡的多标签分类数据集上几种最新方法功效的实证分析。
在我们的实验中,我们使用2017 Pascal VOC图像数据库,该数据库使用自定义的90%/ 10%火车/ Val数据集拆分,手动分区提
重点(Top highlight)
One of the common problems in Machine Learning is handling the imbalanced data, in which there is a highly disproportionate in the target classes.
机器学习中的常见问题之一是处理不平衡的数据,其中目标类别的比例非常不均衡。
Hello world,.
来了一个kmer
1.首先确认其prefix_array-> hash2inde即prefix转换为int类型,在通过map找到对应的array_index. prefix array index要保存在中
2.已知prefix array index,如何在data_array中定位,首先需要一个数组,里面保存了prefix array index对应数组的大小,比如第0个index对应后...
一、
SMOTE原理
SMOTE的全称是
Synthetic Minority Over-
Sampling Technique 即“人工
少数类过采样法”,非直接对
少数类进行重采样,而是设计算法来人工
合成一些新的少数样本。
SMOTE步骤__1.选一个正样本
红色圈覆盖
SMOTE的全称是Synthetic Minority Over-Sampling Technique 即“人工少数类过采样法”,非直接对少数类进行重采样,而是设计算法来人工合成一些新的少数样本。
一、SMOTE原理
1、SMOTE步骤__1.选一个正样本
红色圈覆盖
2、SMOTE步骤__2.找到该正样本的K个近邻(假设K = 3)
3、SMOTE步骤__3.随机从K个近邻中选出一个样本
4、SMOTE步骤__4.在正样本和随机选出的这个近邻之间的连线上,随机找一点。这个点就是人工合成的新正
1. SMOTE
JAIR’2002的文章《SMOTE: Synthetic Minority Over-sampling Technique》提出了一种过采样算法SMOTE。概括来说,本算法基于“插值”来为少数类合成新的样本。
设训练集的一个少数类的样本数为T,那么SMOTE 算法将为这少数类合成NT个新样本。
考虑少数类一个样本 i,特征向量 xi,i∈1,...,Tx_i, i\in {1,...
(JAIR 2002) SMOTE Synthetic Minority Over-sampling Technique
这篇文章讨论了样本不均衡问题。思路很简单清晰。
简单介绍一下:样本不均衡是指在分类过程中,有些类拥有大量的训练样本,有些类则只有少数的样本,让分类器学习起来很困难。而这样的情况又是最常见的,比如说二分类:要对图像中检测到的物体识别是苹果还是非苹果,那么非类作为负样本具有无穷
利用深度学习做多分类在工业或是在科研环境中都是常见的任务。在科研环境下,无论是NLP、CV或是TTS系列任务,数据都是丰富且干净的。而在现实的工业环境中,数据问题常常成为困扰从业者的一大难题;常见的数据问题包含有:
数据样本量少
数据缺乏标注
数据不干净,存在大量的扰动
数据的类间样本数量分布不均衡等等。
除此之外,还存在其他的问题,本文不逐一列举。针对上述第4个问题,2020年7月google发表论文《 Long-Tail Learning via Logit Adjustment 》 通过 BER
训练集标签类别不平衡是机器学习模型训练非常常见的一个问题。它是指训练集中标签A和标签B样本数比例差别很大,当要预测小类标签,即使模型的效果特别差,模型预测的准确率也能达到很高的数值。因此,我们需要处理不平衡的数据集,避免这种情况出现。
一般情况下,我们需要处理的是极不平衡的问题(比如类别比例在1:100)。
在类别不平衡的情况下,关于混淆矩阵评估指标(准确率:accuracy;精确率:precision;召回率:recall)的解读:
高召回率+高精确率:模型具有很全很好的预测效果
低召回率+高精确率:模
处理在多标签分类任务中数据不平衡问题——多标签合成少数类过采样技术(Multi label Synthetic Minority Over-sampling Technique,MLSMOTE)