近年来,随着我国老龄化进程的加速,我国出台了多项政策积极应对人口老龄化。1月15日,国务院办公厅下发了关于发展银发经济增进老年人福祉的意见,从发展民生事业、扩大产品供给、培育潜力产业、强化要素保障等多层次、多方面为发展银发经济服务。
“积极应对人口老龄化”已上升为国家战略,面对快速增长的老龄人口,我国面临着“6个劳动人口养一个老年人”的社会养老压力和社会资源不足的问题。2021年,我国首次提出了“规范发展第三支柱养老保险”,随后,为积极建设完善我国三支柱养老体系,个人养老金制度于2022年11月正式落地。
个人养老金制度是指政府政策支持、个人自愿参加、市场化运营、实现养老保险补充功能的制度。具体来看,个人养老金实行个人账户制,缴费完全由参加人个人承担,自主选择购买符合规定的储蓄存款、理财产品、商业养老保险、公募基金等四大类金融产品,并实行完全积累,按照国家有关规定享受税收优惠政策。
事实上,个人养老金制度落地至今,各家金融机构纷纷积极参与,各类产品令人应接不暇:2022年11月以来,首批特定养老储蓄产品、首批个人养老金基金、首批个人养老金保险产品名单陆续发布,并在随后几个月内多次扩容。
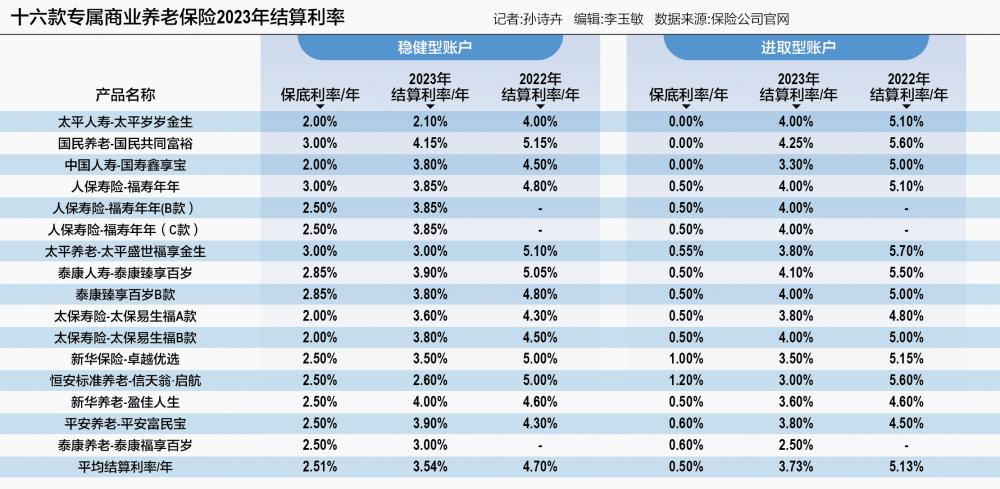
其中,专属商业养老保险作为专为个人养老金账户制度设计的保险产品,其收益表现备受关注,随着2023年的收尾,专属商业养老保险也交出了正式运行以来的第二份答卷。21世纪经济报道记者梳理发现有十六款专属商业养老保险已经披露了其2023年结算利率,整体来看,稳健型账户结算利率均值为3.54%,进取型账户结算利率均值为3.73%。
2023年各账户结算利率均超保底利率
本期测评的十六款专属商业养老保险产品为中国银行保险信息技术管理有限公司个人养老金产品名单上的个人养老金账户商业养老保险产品。专属商业养老保险是指以养老保障为目的,领取年龄在60周岁及以上的个人养老年金保险产品。产品设计分为积累期和领取期两个阶段,领取期不得短于10年。积累期采取“保证+浮动”的收益模式,有稳健型账户和进取型账户两类账户可供选择。
稳健账户主要配置长期固定收益类资产、少量配置具有投资价值的权益类资产,追求长期稳健的投资收益;进取型则灵活配置长期固定收益类资产和具有投资价值的权益类资产,在有效控制风险的同时追求长期较高的投资收益。
十六款专属商业养老保险产品中,稳健型账户2023年最高结算利率为4.15%,均值为3.54%,其中大多数产品结算利率处于3%-4%之间,只有两款产品低于3%,分别是太平人寿的太平岁岁金生和恒安标准养老的信天翁.启航。不过所有产品稳健型账户的结算利率均高于2.00%,即最低的稳健性账户保底利率。虽然各款专属商业养老保险产品稳健型账户的保底利率各不相同,不过从结算利率来看,保底利率与结算利率没有明显相关性,保底利率的高低并不代表结算利率的高低。
进取型账户2023年最高结算利率为4.25%,均值为3.73%,与稳健型账户类似,其大多数产品结算利率也处于3%-4%之间。两类账户之间结算利率差异不大,进取型账户结算利率略高于稳健型账户结算利率。但也有不少产品2023年进取型账户收益低于稳健型账户收益,例如中国人寿的国寿鑫享宝、新华养老的盈佳人生、平安养老的平安富民宝以及泰康养老的泰康福享百岁。
在十六款产品中,国民养老的国民共同富裕专属商业养老保险两类账户的结算利率在十六款产品中均为最高。
值得注意的是,据21世纪经济报道记者统计,2022年稳健型账户和进取型账户结算利率均值差距为0.43个百分点,而2023年,这一数据进一步缩小至0.19个百分点。
结算利率均值较上年有所下降
与2022年相比,2023年整体的结算利率有所下降,且两类账户结算利率均值差距的进一步缩小。业内人士认为,专属商业养老保险2023年的结算利率下滑与去年整体投资环境承压有关。
对于如何配置两类账户,相关业内人士建议,消费者需注意作为养老保险产品,产品主要以保障为主,建议消费者在账户选择上应以安全性为主,适当配比进取型资产。
北京工商大学保险研究中心副秘书长宋占军对21世纪经济报道记者表示:“专属商业养老保险作为一类保险+投资的设计类型,产品收益率是动态调整的。2023年保险公司投资端收益率的下滑,也随之调整负债端专属商业养老保险的结算利率。总的来看,专属养老保险产品期限长,保险公司可以运用的资金期限久,该产品相对市场其他产品的收益率仍是较高的。”
从市场反馈来看,大部分消费者也对专属商业养老保险2023年结算利率的下降态度较为宽容,记者发现这一方面是由于专属商业养老保险本身的保险长期属性,选择此类产品的投资者本身也具有较强的长期投资意识;另一方面也是在整体市场低利率环境下的预期修正。一位相关产品投资者对于2023年结算利率的下调表示了理解,该人士对21世纪经济报道记者表示,毕竟整体市场处于低利率环境,去年许多投资型产品均表现欠佳,专属商业养老保险的结算利率还是“可以接受的”。
专属商业养老保险已进入常态运营
目前,专属商业养老保险已由国家金融监管总局公告进入常态化运营,2023年11月,国家金融监管总局印发《关于促进专属商业养老保险发展有关事项的通知》(以下简称《通知》),明确进一步扩大经营专属商业养老保险业务的机构范围。
国家金融监管总局相关负责人在答记者问时表示,“自试点启动以来,专属商业养老保险业务进展总体平稳,社会反映良好。金融监管总局认真梳理总结试点经验,广泛听取各界意见,决定将专属商业养老保险从试点转为正常业务。”
2021年6月,原银保监会发布公告,允许人保寿险、中国人寿、太平人寿、太保寿险、泰康人寿及新华人寿6家公司在浙江省(含宁波市)和重庆市开展为期一年的专属商业养老保险试点;2022年3月,试点区域扩大到全国范围,试点公司也由6家头部机构扩展至养老保险公司。
1月16日,中央金融工作会议再次强调了要推动商业养老保险高质量发展,金融监管总局人身险司表示,“围绕人民群众日益增长的多样化养老保障需求,我们支持保险机构发挥长期储蓄、长期投资和养老风险管理优势,不断扩大产品和服务供给,满足人民群众差异化养老需求。”
截至目前,根据中国保险行业协会统计,目前专属商业养老保险仅有16款,其中12款在售,4款停售或停用。业内人士认为,随着政策鼓励和居民需求的持续旺盛,专属商业养老保险品类有望持续丰富。
(作者:孙诗卉 编辑:李玉敏)