

Kalman Filter 理论理解

卡尔曼滤波器又叫做最佳线性滤波器, 它实现简单又是一个纯时域的滤波器,不需要进行频域变化,所以在工程上有很多应用,比如自动驾驶中的数据融合。
状态方程与状态预测 卡尔曼滤波器的原理以及在matlab中的实现 状态方程与状态预测
假设一个汽车在路上行驶,用位置 p_t 和速度 v_t 表示在t时刻的状态。则在 状态的矩阵 形式如下,一个二维列向量:
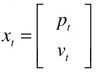
驾驶员可以踩刹车或油门,即加速度为 u_t ,表示为一个车的 控制量 。如果我们已知上一时刻的状态,那么当前时刻的状态可以表示为:
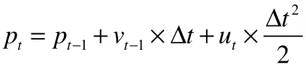
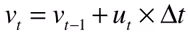
这两个公式的输出都是输入的线性组合,所以我们把状态写成矩阵的模式:
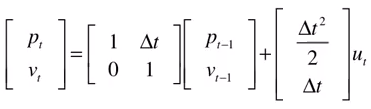
我们进一步把两个矩阵提取出来变成:
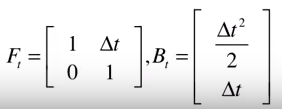
所以上面的公式可以简化为:
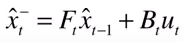
这个公式就是 卡尔曼滤波器中的第一个公式 , 状态预测公式 。其中 F_t 叫做 状态转移矩阵 ,他表示我们如何从上一时刻的状态来推测当前时刻的状态。 B_t 叫做 控制矩阵 ,它表示控制量 u_t 如何作用于当前状态。其中这个尖帽子的 x 表示这是对状态的预测,为 估计量 ,不是真实值。汽车的真实状态是无法确定的,只能通过观察尽可能的估计 x 的值。等号左边的 x 还带减号,表示这是值是根据上一时刻的状态推测而来的。 我们还需要用观测量来修正这个值 ,修正后的值才是最佳的估计值。
有了状态预测公式,我们可以推测当前时刻的状态。但是我们知道所有的推测都是包含噪声的。噪声越大,不确定性越大。我们要如何表示这一次 推测带来了多少不确定性呢 ?我们需要用 协方差矩阵 来表示。
-------
下面解释什么事协方差矩阵,熟悉的可以跳过。
假设我们有一个一维的包含噪声的数据,每次测量的值都不同,但都是围绕在一个中心值得周围,如下图所示:


我们表示这个数据分布状况最简单的就是记下 中心值 和 方差 。这实际上假设数据时 高斯分布 。那么二维的情况如何?我们可以把数据分别投影到X轴或者Y轴,在两个轴上都是高斯分布。
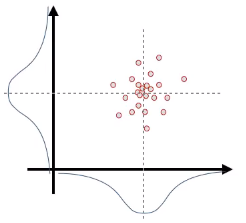
那么我们在记录这个数据的时候是不是记录两个高斯分布的中心值和方差就可以了呢?如果两个维度的噪声是相互独立的,是可以如此表示的。但是如果在维度上有相关性呢?例如一个维度上的噪声增大,另一个维度的噪声也增大;或者一个维度上增大另一个维度上减小。这个时候两个维度上的投影跟上图是完全一样的。
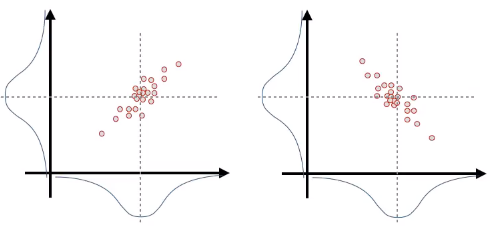

所以为了表示这两个维度的相关性,除了要记录两个维度的中心值和方差,还要记录协方差来表示两个维度的相关性。
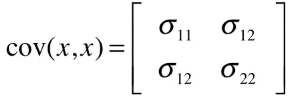
其中对角线的 \sigma_{11} \sigma_{22} 分别是两个维度的方差,反对角线上的两个值 \sigma_{12} 是相等的,表示协方差。 在上述三种情况中,第一种情况 \sigma_{12} = 0,第二种情况 \sigma_{12} > 0, 第三种情况 \sigma_{12} < 0。
------
不确定性关系的传递 (协方差矩阵)
在卡尔曼滤波中,所有不确定性都要用到协方差矩阵。 在小车这个例子中,每一个时刻的不确定性都要用协方差矩阵 P 来表示。
那么下一个问题就是 如何让不确定性在每个时刻传递 呢,答案是 乘上状态转换矩阵 F 。
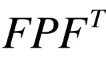
左边乘以 F ,右边乘以矩阵的转置 F^T :
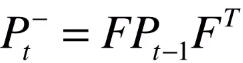
从上一时刻推测当前时刻的协方差矩阵,等于上一时刻协方差矩阵左右两边乘以状态转换方程。为何要两边都要乘呢?这是 协方差矩阵的性质 :
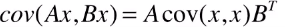
x 的协方差是 P , 想要计算 F x 的协方差,就把状态状态方程提到两边。
同时我们还要考虑我们的预测模型并不是一定准确的,它本身也是包含噪声的。 前面的观测噪声,目前需要添加的预测模型本身的噪声 。所以我们我们还要添加模型本身的协方差矩阵 Q 。
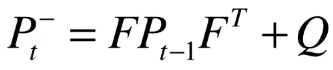
这个就是 卡尔曼滤波器的第二个公式 ,他表示了不确定性在各个时间的传递关系。
观察矩阵
假设在公路的一端有一个激光雷达测距仪,在每个时刻都可观测到汽车的位置。观测到的值我们记为 Z_t 。 那么从汽车本身的状态到观测状态 Z_t 有一个变化关系,我们记为 H 。这个变化关系只能是线性的,因为卡尔曼滤波器本身是线性的,所以把它表示为矩阵的形式,即 观测矩阵 。 x 和 Z 的维度不一定是相同的。在例子中, x 是一个二维的列向量, Z 只是一个标量的值。所以 H 是一个一行两列的矩阵。里面的元素分别是1和0。 这样 H 和 x 相乘的时候就会得到一个标量 Z 。这个标量就是汽车的位置,它与 x 矩阵中的第一个元素是相等的。如下:
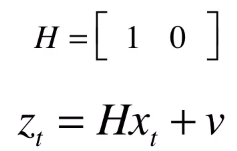
为啥要在后面加 v 呢? 因为我们的观测值也不是一定可靠的。我们还要在后面加上观测的噪声 v 。这个 观测噪声的协方差矩 阵为 R 。由于在这个例子中,观测值是一个一维的值,所以 R 的形式不是矩阵而是一个单独的值,仅仅表示 z 的方差。假设我们除了激光雷达测距仪外还有别的测距仪器,比如普通雷达,可以观测到汽车的某项特征,那么 Z 就会变成一个多维的列向量,它包含每一种测量方式的测量值,而每一个测量值都是真实状态下的一个不完全的表现。我们可以从集中不完全的特征中推断出真实的状态。卡尔曼滤波器中的数据融合的功能正是在这个测量功能中得到体现。
状态更新
到目前为止,我们已经有了观测量 Z , 和它的噪声矩阵 R , 那么我们如何把他们整合进我们对状态 x 的估计呢?我们已经在前面得到了带减号上标的 x_t ,现在我们只要在后面加上一项进行修正就可以得到我们的最佳估计值了。 公式 三如下:
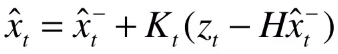
括号中的减法表示实际的观测值与我们预期观测值之间的 残差, 这个残差乘上一个系数 K ,即可修正。这个 K 很关键,叫做卡尔曼系数。实际上它也是一个矩阵,这个 公式四 如下:
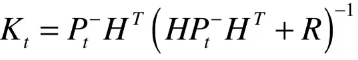
这个公式的推导比较复杂,这里只做定性的分析。它的 作用主要有两方面 :
1. 权衡预测状态协方差 P 和观测量的协方差矩阵 R 的大小来决定我们是相信预测模型多一点,还是观测模型多一点。如果相信预测模型多一点,这个残差权重就会小一点,如果相信观测模型多一点,那么残差模型就会大一点。
2. 把残差的表现形式,从观测域转换到状态域。什么意思:观察值 z 是一个一维向量, x 是一个二维向量,他们的单位可能都是不一样的。 那么我们怎么用观测值的残差去更新状态值呢?实际上这个系数就做这样的转换。在小汽车这个例子里,我们只观测到了汽车的位置,但 K 里已经包含了协方差矩阵 P 的信息,所以它利用速度和位置这两个维度的相关性,从位置的残差里推算出了速度的残差,从而让我们可以对 x 的位置和速度同时进行修正。
噪声协方差矩阵的更新
最后一步是更新最佳估计值的噪声分布,这个值留给下一迭代时使用。在这一步,状态的不确定是减小的。而在下一迭代时,由于传递噪声的引入,不确定性又会增大。卡尔曼滤波器就是在这种不确定性变化的过程中寻求一种平衡。 公式五 :
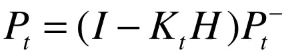
总结
下面列出整个过程的所有公式:这五个公式中,前两个是通过上一时刻的状态来预测当前时刻的状态。
- 预测
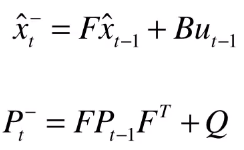
通过这两个公式,我们得到的是带减号上标的 x 和 P ,表示这并不是最佳的估计值。欠缺的东西在观测值中得到的信息
2. 更新
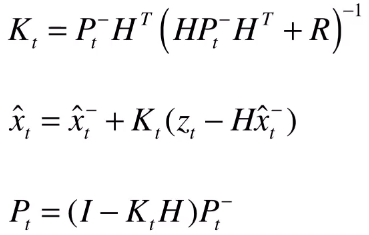
这三个公式就是用观测值来更新,更新后得到最佳估计值,更新后就不带减号上标。
