|
|
|


python如何使用遍历循环读取多个csv文件?
关注者
19
被浏览
79,098
8 个回答

1、先取得所有的csv 文件,将文件名(如果不在一个目录下,包括路径名)保存到一个list 中
2、循环list,依次处理csv 文件。
第一种方法
import pandas as pd
import os
import glob
# use glob to get all the csv files
# in the folder
path = os.getcwd()
csv_files = glob.glob(os.path.join(path, "*.csv"))
# loop over the list of csv files
for f in csv_files:
# read the csv file
df = pd.read_csv(f)
# print the location and filename
print('Location:', f)
print('File Name:', f.split("\\")[-1])
# print the content
print('Content:')
display(df)
print()
第二种方法
from pathlib import Path
files = Path('/your/path/here/').glob('*.csv') # get all csvs in your dir.
for file in files:
df = pd.read_csv(file,index_col = 0)
# your plots.
需求确认:
从Akshare上面下载的股票数据是dataframe结构,如果每支股票存入不同csv文件。那么请问用spyder如何 遍历循环读取多个csv文件 ?重点是循环遍历多个csv文件。
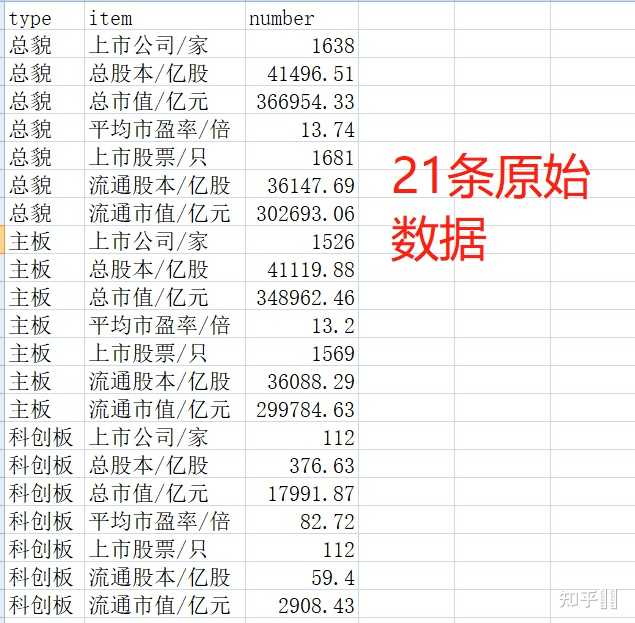
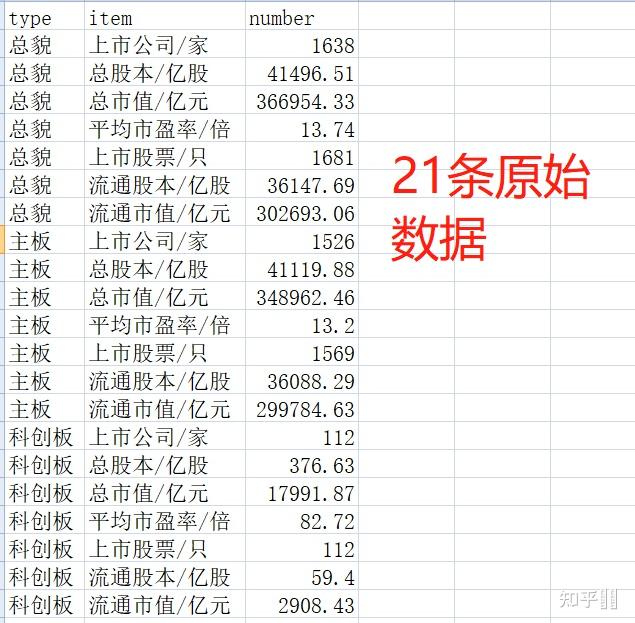
如下有三个csv文件,字段相同,数据量相等均为21条数据。


代码实现:
- 利用os.listdir()获得文件夹中的文件名
file_name=os.listdir(r'C:\Users\admin\Desktop\Jupyter_notebook_test\csv')
file_name

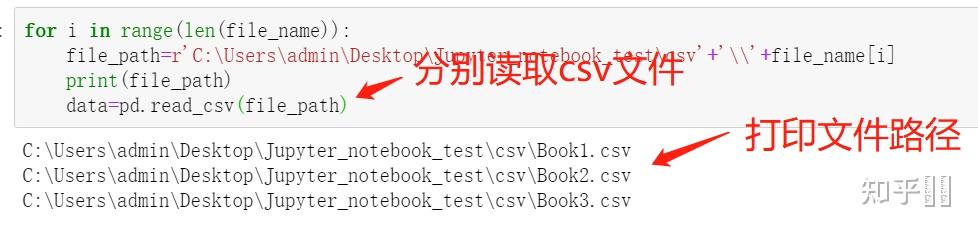
- 循环遍历csv文件
for i in range(len(file_name)):
file_path=r'C:\Users\admin\Desktop\Jupyter_notebook_test\csv'+'\\'+file_name[i]
print(file_path)
data=pd.read_csv(file_path)
- 总代码:
file_name=os.listdir(r'C:\Users\admin\Desktop\Jupyter_notebook_test\csv')
for i in range(len(file_name)):
file_path=r'C:\Users\admin\Desktop\Jupyter_notebook_test\csv'+'\\'+file_name[i]
print(file_path)
data=pd.read_csv(file_path)- 用os.walk扫描csv文件夹下所有的子目录和文件
file_path=r'C:\Users\admin\Desktop\Jupyter_notebook_test\csv'
for root, dirs, files in os.walk(file_path):
print("现在的目录:" + root)
print("该目录下包含的子目录:" + str(dirs))
print("该目录下包含的文件:" + str(files))

- 循环遍历csv文件
for root, dirs, files in os.walk(file_path):