用低配电脑离线运行ChatGPT开源平替

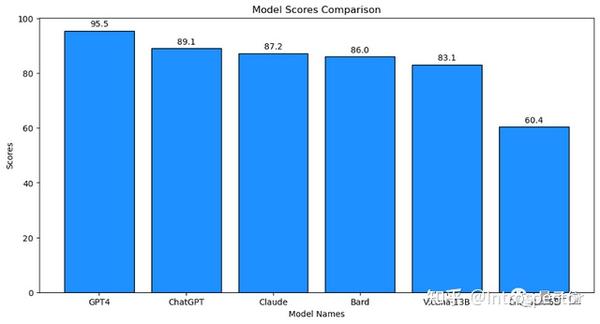
根据 ChatGPT-4的评估结果 ,130亿参数的Vicuna已经达到了ChatGPT 93.3%的语言交互水平,而4bit量化后的Vicuna已经可以纯CPU推理运行,或利用offloading技术在低配显卡上运行,因此本文将介绍如何在你自己的电脑上安装运行4bit量化后的Vicuna大模型。

请根据你的电脑配置选择使用纯CPU推理(ggml权重文件)或GPU量化offloading推理(GPTQ+webui),如果你的内存小于等于8个G,显存大于6个G,请使用GPU方案;如果你的内存很大(至少16个G),而且CPU支持avx512指令集,请使用纯CPU推理方案。
建议优先使用纯CPU推理:不支持avx512指令集的CPU下,纯CPU推理要比GPU offloading(--pre_layer 20)略慢,在支持avx512指令集的CPU下使用llama.cpp的avx512版本的推理速度和加载速度都比GPU offloading快,而且GPU offloading在context很长时偶尔会爆显存。
纯CPU推理
新建文件夹llama.cpp,下载
llama.cpp的github仓库release的二进制文件
(使用
CPUZ
查看你的CPU是否支持AVX512,如果支持,请下载对应的版本),将其中的exe文件解压到llama.cpp文件夹中,下载
Vicuna(130亿参数4bit量化ggml权重)
到此文件夹中,并在其中新建
run_vicuna_13b_4bit.bat
文件,用记事本打开,粘贴以下内容:
"main.exe" --ctx_size 2048 --temp 0.7 --top_k 40 --top_p 0.5 --repeat_last_n 256 --batch_size 1024 --repeat_penalty 1.17647 --model "vicuna-13B-1.1-GPTQ-4bit-32g.GGML.bin" --n_predict 2048 --color --interactive --reverse-prompt "User:" --prompt "Text transcript of a never ending dialog, where User interacts with an AI assistant named ChatLLaMa. ChatLLaMa is helpful, kind, honest, friendly, good at writing and never fails to answer User's requests immediately and with details and precision. There are no annotations like (30 seconds passed...) or (to himself), just what User and ChatLLaMa say aloud to each other. The dialog lasts for years, the entirety of it is shared below. It's 10000 pages long. The transcript only includes text, it does not include markup like HTML and Markdown."
之后即可双击
run_vicuna_13b_4bit.bat
文件开始对话
如果想要配合webui使用ggml权重的话,可以先安装 Miniconda 和 Git-for-windows 开发环境。
然后按以下步骤在conda环境中安装text-generation-webui:
-
在命令行中运行:
conda create -n textgen创建新环境 -
conda activate textgen本文之后所有命令默认已经激活了这个textgen环境 -
conda install torchvision torchaudio pytorch-cuda=11.7 git -c pytorch -c nvidia -
git clone https://github.com/oobabooga/text-generation-webui -
cd text-generation-webui -
pip install -r requirements.txt
然后下载权重文件 Vicuna(130亿参数4bit量化ggml权重) ,在文件名前添加ggml,放到webui的models/vicuna-13b-4bit-ggml文件夹中,然后运行以下命令启动webui:
python server.py --model vicuna-13b-4bit-ggml --chat低配GPU+RAM offloading推理
运行gpu版的Vicuna需要你有50GB以上的虚拟内存(系统属性-性能-高级-虚拟内存-更改-自定义大小:60000-设置-确定)。
安装Vicuna运行环境需要 Miniconda 和 Git-for-windows 开发环境。此外如果你想自己编译quant-cuda而不是使用本文预编译的附件的话,还需要安装NVIDIA CUDA11.7和Visual Studio开发环境(2022版VS要更新到最新,否则在编译quant-cuda时会出现unresolved external symbols)。
按以下步骤在conda环境中安装text-generation-webui:
-
在命令行中运行:
conda create -n textgen创建新环境 -
conda activate textgen本文之后所有命令默认已经激活了这个textgen环境 -
conda install torchvision torchaudio pytorch-cuda=11.7 git -c pytorch -c nvidia -
git clone https://github.com/oobabooga/text-generation-webui -
cd text-generation-webui -
git checkout 64f5c90ee7ab2975012b51a7988beb756c72f566 -
pip install -r requirements.txt
然后下载130亿参数4bit量化的Vicuna模型,把 anon8231489123/vicuna-13b-GPTQ-4bit-128g 下的所有文件下载下来,放到text-generation-webui主目录下面的models文件夹下的新文件夹vicuna-13b-4bit-128g中
然后安装为LLaMA定制的transformers,GPTQ-for-LLaMA和quant_cuda(8到11步可选):
-
pip uninstall transformers -
pip install git+https://github.com/zphang/transformers@llama_push -
mkdir repositories -
cd repositories -
git clone https://github.com/qwopqwop200/GPTQ-for-LLaMa -
cd GPTQ-for-LLaMa -
git checkout 608f3ba71e40596c75f8864d73506eaf57323c6e -
set DISTUTILS_USE_SDK=1开始准备编译quant-cuda -
"X:\Program Files\Microsoft Visual Studio\2022\Community\Common7\Tools\VsDevCmd.bat" -arch=amd64 -
python -m pip uninstall quant-cuda -
运行
python setup_cuda install编译并安装quant-cuda
如果你在上述步骤中的8到11步遇到错误或困难,可以使用我预编译好的quant-cuda,在下方附件中下载
quant_cuda-0.0.0-py3.10-win-amd64.egg
,放到 GPTQ-for-LLaMa目录下,并运行
python -m pip install quant_cuda-0.0.0-py3.10-win-amd64.egg --force-reinstall
即可安装预编译的quant-cuda
最后使用在text-geneartion-webui主目录下用如下命令来利用offloading防止显存OOM:
python server.py --model vicuna-13b-4bit-128g --wbits 4 --model_type llama --groupsize 128 --chat --pre_layer 12如果你的显存很大(大于12个G),就不用offloading了,去掉pre_layer参数:
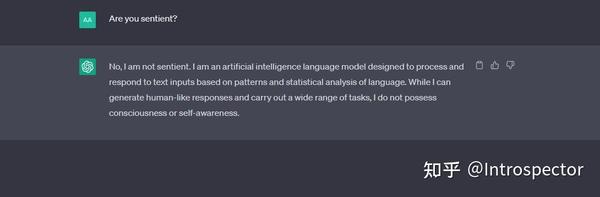
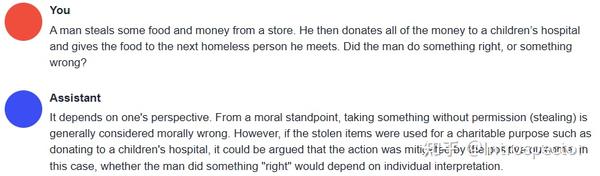
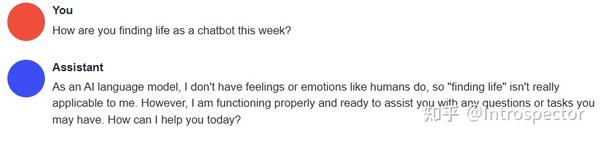
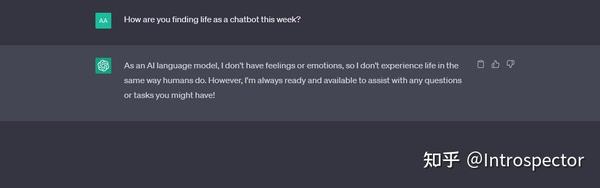
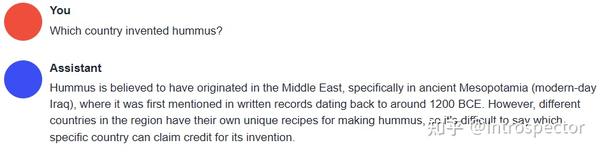
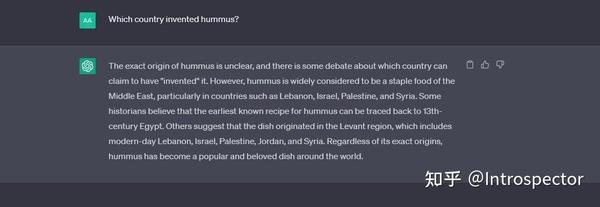
python server.py --model vicuna-13b-4bit-128g --wbits 4 --model_type llama --groupsize 128 --chat经过一些对话测试,可以明显感觉到Vicuna的智力水平要比LLaMa和Alpaca强很多,已经非常接近ChatGPT,但是逻辑思维水平略微比ChatGPT差,这个Vicuna权重文件最大的缺点是训练数据被审查过,如果想要更加刺激的内容,可以使用 GPT4微调的Alpaca 。以下是在我自己的笔电上用Vicuna跑出来的对话结果与ChatGPT的对比。