- 后剪枝决策树通常比预剪枝决策树保留了更多的分支;
- 后剪枝决策树的欠拟合风险很小,泛化性能往往优于预剪枝决策树;
- 后剪枝决策树训练时间开销比未剪枝决策树和预剪枝决策树都要大的多。
决策树生成算法递归地产生决策树,直到不能继续下去为止。这样产生的树往往对训练数据的分类很准确,但对未知的测试数据的分类却没有那么准确,即容易出现过拟合现象。解决这个问题的办法是考虑决策树的复杂度,对已生成的决策树进行简化,下面来探讨以下决策树剪枝算法。
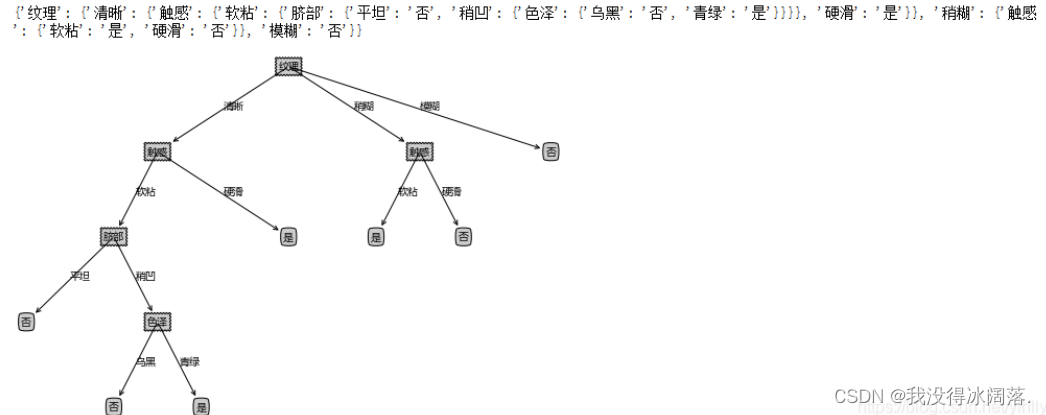
决策树预剪枝和后剪枝
决策树对训练集有很好的分类能力,但是对于未知的测试集未必有好的分类能力,导致模型的泛化能力弱,可能发生过拟合问题,为了防止过拟合问题的出现,可以对决策树进行剪枝。剪枝分为预剪枝和后剪枝。
预剪枝:就是在构建决策树的时候提前停止。比如指定树的深度最大为3,那么训练出来决策树的高度就是3,预剪枝主要是建立某些规则限制决策树的生长,降低了过拟合的风险,降低了建树的时间,但是有可...
(一)剪枝算法的简介:剪枝一般是为了避免树的过于复杂,过于拟合而进行的一个动作,剪枝操作是一个全局的操作。(二)预剪枝:预剪枝就是在树的构建过程(只用到训练集),设置一个阈值,使得当在当前分裂节点中分裂前和分裂后的误差超过这个阈值则分列,否则不进行分裂操作。(三)后剪枝:(1)后剪枝是在用训练集构建好一颗决策树后,利用测试集进行的操作。
(2)算法:
基于已有的树切分测试数据:
决策树(Decision tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。
机器学习中,决策树是一个预测模型。它代表的是对象属性与对象值之间的一种映射关系。树中每个节点表示某个对象,而每个分支叉路径则代表某个可能的属性值,而每个叶节点则对应从根节点到该叶节点所经历的路径所表示的对象的值。决策树仅有单...
前面两篇博客分别介绍了如何构造决策树(根据信息增益,信息增益率,基尼指数等)和如何对决策树进行剪枝(预剪枝和后剪枝),但是前面两篇博客主要都是基于离散变量的,然而我们现实的机器学习任务中会遇到连续属性,这篇博客主要介绍决策树如何处理连续值。
因为连续属性的可取值数目不再有限,因此不能像前面处理离散属性枚举离散属性取值来对结点进行划分。因此需要连续属性离散化,常用的离散化策略是二分法,这个技术也是C4.5中采用的策略。下面来具体介绍下,如何采用二分法对连续属性离散化: