


Python Pandas 数据处理常用语法

背景介绍:
本篇文章主要针对一些Python处理数据常用的函数和用法,Python的pandas 以及numpy的用法很丰富,本文只是介绍了冰山一角。介绍了数据分析师日常常用的Python 函数。 整理不易,感兴趣的可以帮忙点赞和收藏哈,以后我会继续整理数据分析师常用的功能
以下我会从几个方面介绍Python常用函数和功能
- 数据概览
- 数据描述性统计
- 数据合并
- 数据去重
- 数据基本操作
- 数据预处理
在函数介绍之前,我们先导入包以及创建数据集
# 导入包
import pandas as pd
import numpy as np
# 创建数据集
data={'year':['2018','2019','2018','2018','2019','2019','2018','2019'],
'name':['张三', '李四', '王五', '李四', '张三', '小明', '小明', '王五'],
'数学':[83,90,98,90,88,88,88,89],
'英语':[92,89,90,78,83,90,91,95]}
# 将数据变成dataframe格式
data=pd.DataFrame(data) 1. 数据概览
数据概览通常是在读取数据后对数据进行快速浏览,以达到对数据的初步了解,常用函数包含以下内容:
1. dt.head()
head()根据位置返回对象的前n行。如果你的对象中包含正确的数据类型, 则对于快速测试很有用。此方法用于返回数据帧或序列的前n行(默认值为5),可以更改5为任意数字显示你想看的行数
data.head(5)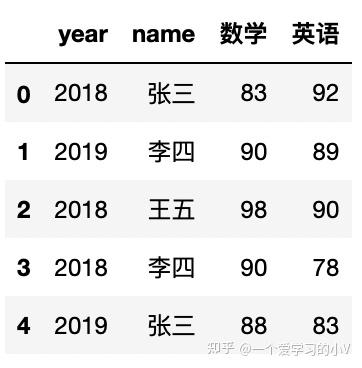
2. dt.tail()
tail 根据位置返回对象的末尾n行,函数根据函数参数,输出数据集对应行数,用于快速查看数据,默认是最后5行
data.tail()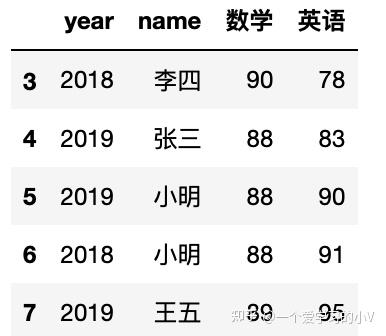
3. dt.loc()
loc是location的意思,按标签取数据;iloc中i的意思是指integer,所以它只接受整数作为参数,按位置取数据
data.loc[1,:] #输出第二行,所有列数据
data.loc[:,'year'] #输出所有行,year列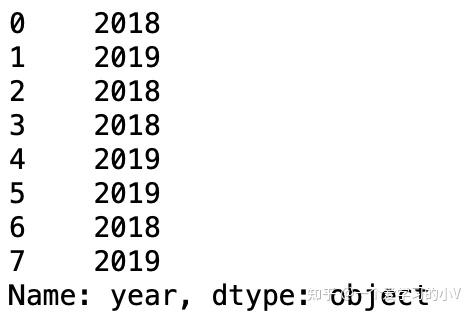
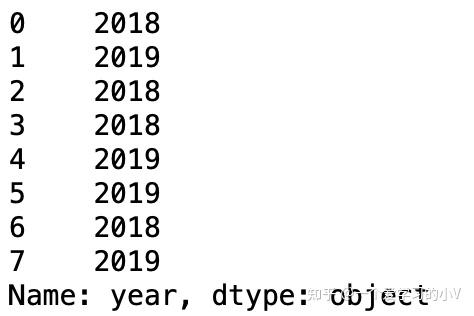
data.loc[[0,1,5],['year','name']] #0,1,5行,year,name 列
4. dt.iloc()
data.iloc[[0,2,4,6],0:2]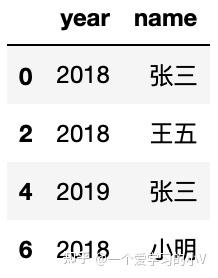
5. dt.dtypes
返回数据集中字段和字段类型
data.dtypes
6. dt.columns
返回数据字段名
data.columns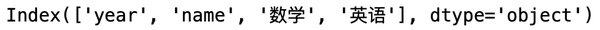
2. 数据描述性统计
数据的描述型统计结果,一般常用来输出数据的统计表现,如最大最小值,计数,均值,中位数等
1. dt.count()
count() 方法用于统计字符串里某个字符或子字符串出现的次数。可选参数为在字符串搜索的开始与结束位置
data['name'].count

2. dt.unique()
统计list中的不同值,返回的是array
data['name'].unique()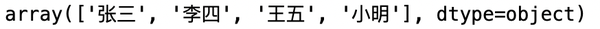
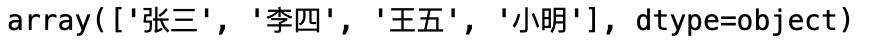
3. dt.nunique()
可直接统计dataframe中每列的不同值的个数,返回的是不同值的个数
data['name'].nunique()
4. dt.min()/ dt.max()
min() 函数返回值最小的项目,如果值是字符串,则按字母顺序进行比较。max() 函数返回值最大的项目,如果值是字符串,则按字母顺序进行比较
data['数学'].min()
data[['英语','数学']].max()
5. dt.sum()
sum() 方法对序列进行求和计算
sum(data['数学'])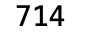
data['总分']=data['数学']+data['英语']
data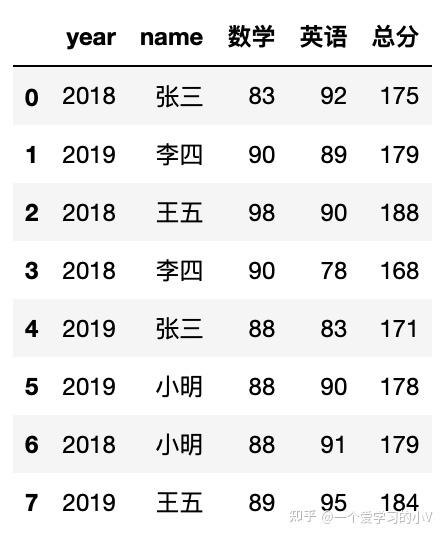
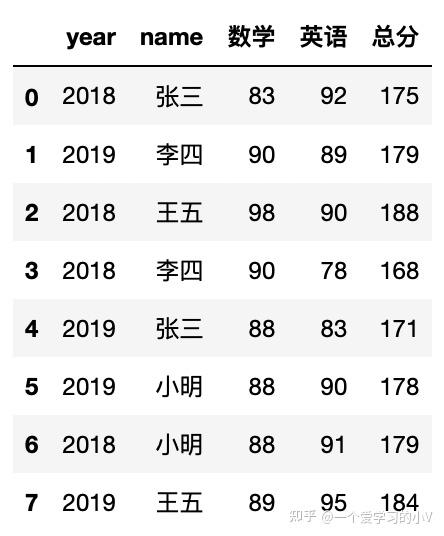
6. np.mean()
对序列进行平均计算
np.mean(data['数学'])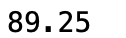
np.mean(data)
3. 数据合并
通过上面的检查探查后,我们对数据有了简单的了解。这个时候我们可能需要将多个数据进行合并处理,类似于SQL中的各种join,以下内容将为大家介绍Python中常用的几种合并函数,以及每种函数之间的差别.
在对比各种函数之前,先创建各种类型数据集,为后面实现各种函数对比提供数据
# 创建dataframe
df1=pd.DataFrame({'A':['A0','A1','A2','A3'],
'B':['B0','B1','B2','B3'],
'C':['C0','C1','C2','C3'],
'D':['D0','D1','D2','D3']},
index=[0, 1, 2, 3])
df2=pd.DataFrame({'A':['A4','A5','A6','A7'],
'B':['B4','B5','B6','B7'],
'C':['C4','C5','C6','C7'],
'D':['D4','D5','D6','D7']},
index=[4, 5, 6, 7])
df3=pd.DataFrame({'A':['A8','A9','A10','A11'],
'B':['B8','B9','B10','B11'],
'C':['C8','C9','C10','C11'],
'D':['D8','D9','D10','D11']},
index=[8, 9, 10, 11])
df4 = pd.DataFrame({'B': ['B2', 'B3', 'B6', 'B7'],
'D': ['D2', 'D3', 'D6', 'D7'],
'F': ['F2', 'F3', 'F6', 'F7']},
index=[2, 3, 6, 7])
df5 = pd.DataFrame({'B': ['B2', 'B3', 'B6', 'B7'],
'D': ['D2', 'D3', 'D6', 'D7'],
'F': ['F2', 'F3', 'F6', 'F7']},
index=[0, 1, 2, 3])
df6=pd.DataFrame({'A':['A4','A5','A6','A7'],
'B':['B4','B5','B6','B7'],
'C':['C4','C5','C6','C7'],
'D':['D4','D5','D6','D7']},
index=[0, 1,
2, 3])
df7=pd.DataFrame({'A':['4','5','6','7'],
'B':['4','5','6','7'],
'C':['4','5','6','7'],
'D':['4','5','6','7']},
index=[0, 1, 2, 3])
df8=pd.DataFrame({'A':['4','5','6','7'],
'b':['4','5','6','7'],
'c':['4','5','6','7'],
'd':['4','5','6','7']},
index=[0, 1, 2, 3])具体输出格式就不在这里展示了,大家有兴趣的可以复制下来在自己的电脑中运行看看。 接下来,开始介绍不同合并方式函数
1. pd.concat([df1,df2])
以下是参数说明
#objs : 参与连接的pandas对象的列表或字典,唯一必须参数
#join : {‘inner’, ‘outer’}, default ‘outer’. 指明是按交集还是并集合并
#ignore_index : 不保留连接轴上的索引,产生一组新索引
#join_axes : 按哪些对象的索引保存。指明用于其它n-1条轴的索引,不执行并集/交集运算
#keys : 与连接对象有关的值,用于形成连接轴向上的层次化索引。
#levels :如果设置了key,指定用做层次化索引各级别上的索引。
#names : 如果设置了key,用于创建分层级别的名称。
#verify_integrity : 检查结果对象新轴上的重复情况。 #axis: 0为纵向合并,1为横向合并,默认为0。
result1=pd.concat([df1,df2]) #默认按列合并
result2=pd.concat([df1,df2],axis=0) # 0表示按列合并
result3=pd.concat([df1,df2],axis=1) # 索引不同的按行合并
result4=pd.concat([df1,df6],axis=0) #
result5=pd.concat([df1,df6],axis=1) # 相同索引的按行合并
result6=pd.concat([df1,df7]) # 相同列名,列格式不同合并,也是按列名合并
result7=pd.concat([df1,df8]) # 不同列名,按列合并
result8=pd.concat([df1,df8],ignore_index=True) #合并后的数据集忽略索引,重新生成新索引
result9=pd.concat([df1,df4],axis=1,join='inner',ignore_index=True) # 对按行合并没有用?
result10=pd.concat([df1,df4],axis=1,join='outer')
result11=pd.concat([df1,df2,df3],keys=['x','y','z'])
result12=pd.concat([df1,df2,df3],axis=1,keys=['x','y','z'])
print(result1)
print(result2)
print(result3)
print(result4)
print(result5)
print(result6)
print(result7)
print(result8)
print(result9)
print(result10)
print(result11)
print(result12)
# 按列合并: 以列名为关联字段,相同列名和直接上下合并,如果不同和错列合并
# 按行合并: 以索引为关联字段,备注:由于结果较多,因此不在这里展现,有兴趣的可以自己跑一下,看下不同结果的对比
2. df1.append(df2 )
data1=df1.append(df2)
data2=df1.append([df1,df2])
data3=df1.append(df4)
data4=pd.concat([df1,df4])
data5=df1.append(df4,ignore_index=True)
print(data1)
print(data2)
print(data3)
print(data4)
print(data5)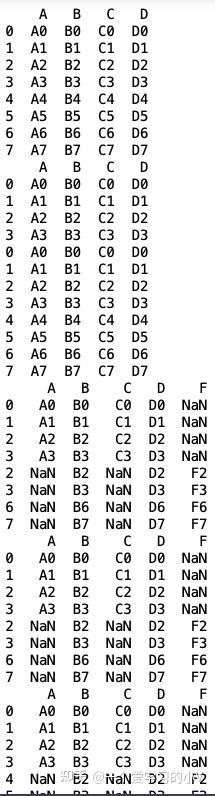
3. pd.merge(df1,df2,on=,how=)
#merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=True, indicator=False, validate=None)
#left: 对象
#right: 另一个对象
#on: 要加入的列 (名称)。必须在左、 右综合对象中找到。
#left_on: 从左边的综合使用作为键列。可以是列名或数组的长度等于长度综合
#right_on: 从正确的综合,以用作键列。可以是列名或数组的长度等于长度综合
#left_index: 如果为 True,则使用索引(行标签)从左综合作为其联接键。在与多重(层次)的综合,级别数必须匹配联接键从右综合的数目
#right_index: 相同用法作为正确综合 left_index
#how: 之一 '左','右','外在'、 '内部'。默认为内连接。每个方法的更详细说明请参阅︰
#sort: 综合通过联接键按字典顺序对结果进行排序。默认值为 True,设置为 False将提高性能极大地在许多情况下
#suffixes: 字符串后缀并不适用于重叠列的元组。默认值为 ('_x','_y')。
#copy: 即使重新索引是不必要总是从传递的综合对象,复制的数据 (默认值True)。在许多情况下不能避免,但可能会提高性能 / 内存使用情况。可以避免复制上述案件有些病理但尽管如此提供此选项。
# 合并后的字段不用重新命名,默认添加_x,_y
data1=pd.merge(df1,df2,on='B',how='outer')
data2=pd.merge(df1,df2,on='B',how='inner') # 默认形式
data3=pd.merge(df1,df2,on='B',how='left') # 左连接,连接字段是字段B
data4=pd.merge(df1,df2,left_on='B',right_on='D',how='left')
result=pd.merge(df1,df4,on='B',indicator=True,validate="one_to_one")# #
print(data1)
print(data2)
print(data3)
print(data4)
print(result)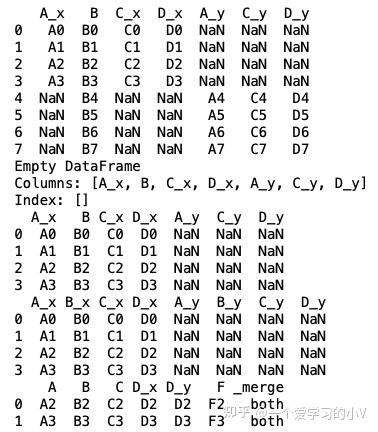
4. join df1.join(df2,how=,lsuffix=,rsuffix=)
需要给合并后的重复的字段名进行重命名
data1=df1.join(df4,how='inner',lsuffix='_left',rsuffix='_right')# 没有指明关联字段默认是以最先找到的字段为准?
print(data1)
4. 数据去重
在演示数据去重之前,我们用一个实际业务中产生的数据进行演示,该数据有一般数据集中的主键,以及不同类型数据,以及不同类型数据情况(缺失值,异常值等)
数据集位置:链接: https:// pan.baidu.com/s/1onmHIR y2ZNgdCA4rnfG42w?pwd=ksd9 提取码: ksd9
读入数据
import pandas as pd
import numpy as np
# 2.0 读入数据
data1=pd.read_csv(r'/Users/***/data_for_merge1.csv') #文件位置可以换成自己的文件路径
data2=pd.read_csv(r'/Users/***/data_for_merge2.csv') #文件位置可以换成自己的文件路径
print(data1.shape)
print(data2.shape)
dt=data1.append(data2,ignore_index=True)
dt.shape #(76973, 19)
print(dt.shape)
dt.head()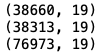
通过简单数据概览了解数据结构以及样本数据后,对数据有个简单了解,接下来将对该数据进行
1. 排序 df.sort_values()
# DataFrame.sort_values(by=‘##',axis=0,ascending=True, inplace=False, na_position=‘last')
# by 指定列名(axis=0或'index')或索引值(axis=1或'columns')
# axis 若axis=0或'index',则按照指定列中数据大小排序;若axis=1或'columns',则按照指定索引中数据大小排序,默认axis=0
# ascending 是否按指定列的数组升序排列,默认为True,即升序排列
# inplace 是否用排序后的数据集替换原来的数据,默认为False,即不替换
# na_position {‘first',‘last'},设定缺失值的显示位置以上是该函数的参数以及参数解释,接下来将进行函数的不同参数演示以及效果对比展示
dt_sort=dt.sort_values(by='MD007') # 默认按升序排列
dt_sort.head()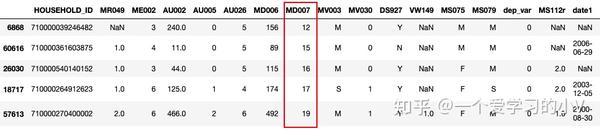
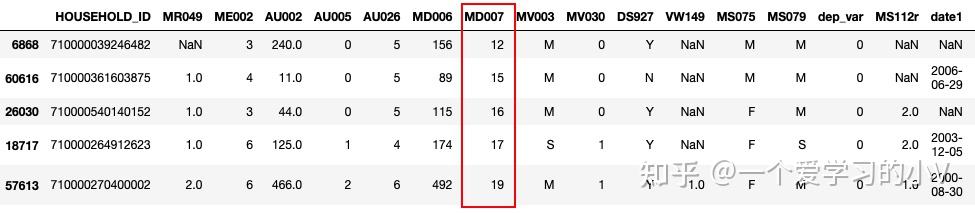
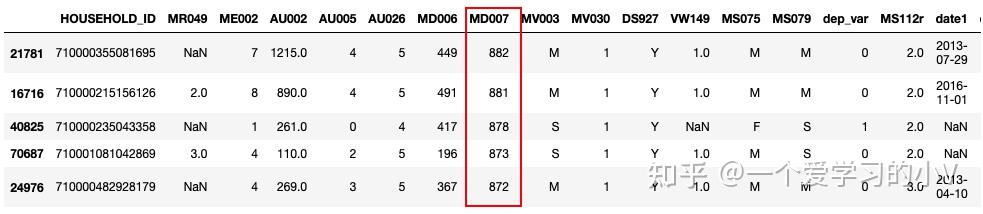
dt_sort=dt.sort_values(by='MD007',ascending=False) # 降序排列
dt_sort.head()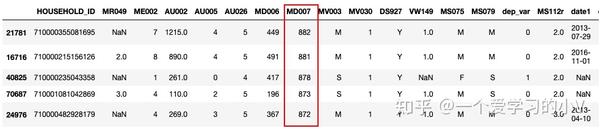
dt_sort=dt.sort_values(by='MS075',ascending=False) #降序
dt_sort.head()

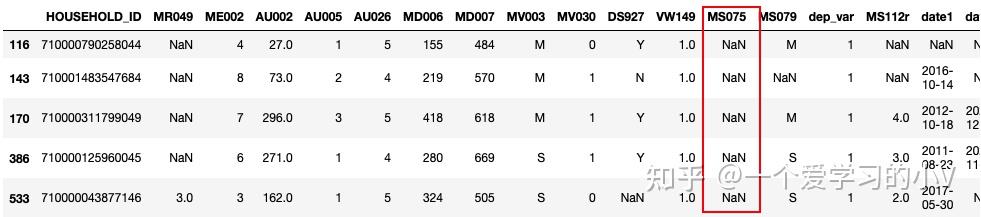
dt_sort=dt.sort_values(by='MS075') # 升序
dt_sort.head()
dt_sort.tail() #不管是升序还是降序,na值都是放在最后

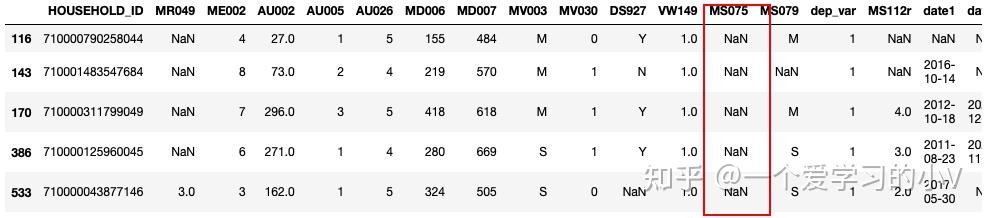
dt_sort=dt.sort_values(by='MS075',ascending=False,na_position='first') # 降序,将na值放在最前面
dt_sort.head()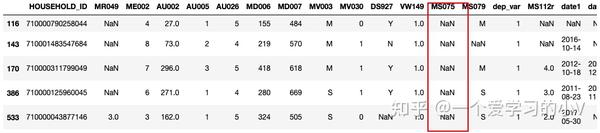
dt_sort=dt.sort_values(by='MS075',na_position='first') # 升序,将na值放在最前面
dt_sort.head()
# 只要添加na_position 参数后,不管是升序还是降序,na值都会放在最前面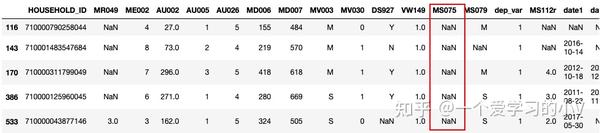
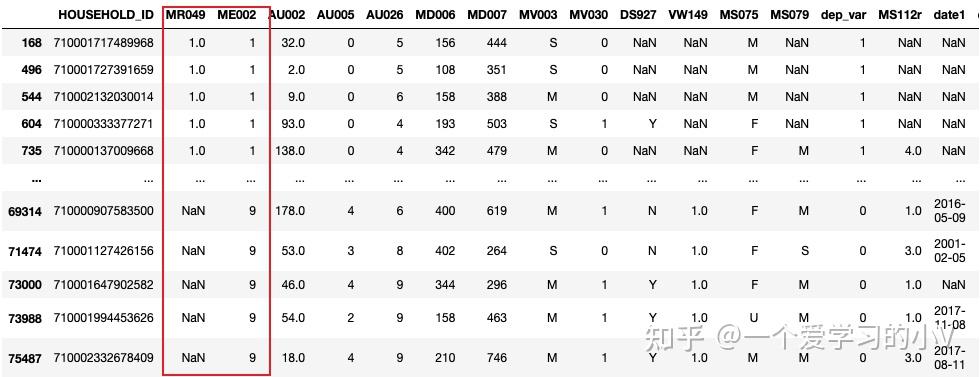
# 按两个字段排序,默认都是升序排列
dt.sort_values(by=['MR049','ME002'])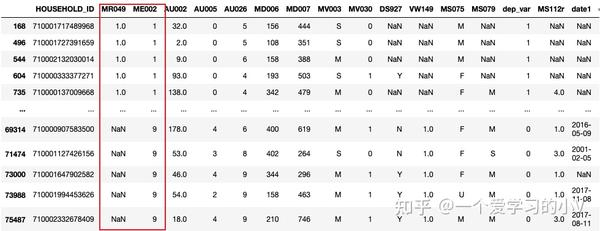
#按两个字段排序,一个升序,一个降序
dt.sort_values(by=['MR049','ME002'],ascending=[True,False])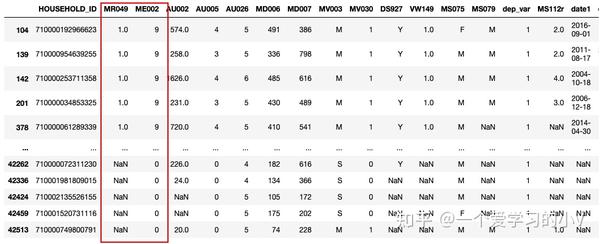
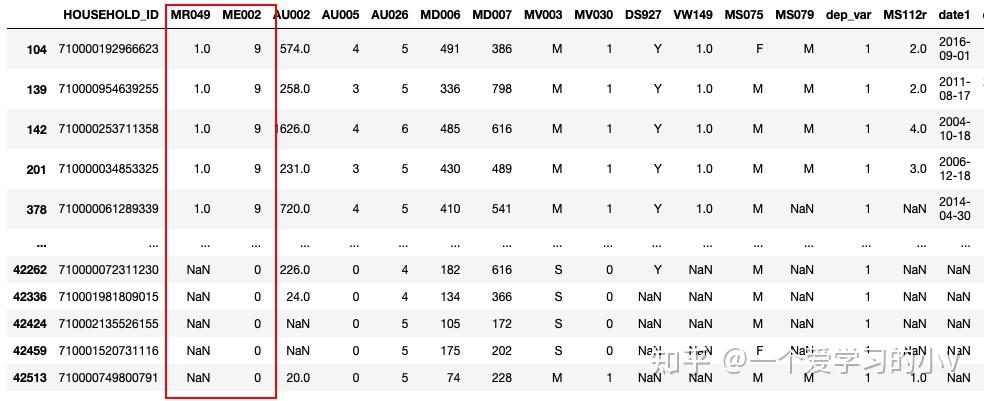
2. 去重 df.drop_duplicates()
#drop_duplicate方法是对DataFrame格式的数据,去除特定列下面的重复行。返回DataFrame格式的数据
# df.drop_duplicates(keep= , subset=[], inplace= )
#subset: 用来指定特定的列,默认所有列
#keep:指定要保留的行 first-第一次出现的行;last-最后一次出现的行;False-删除所有的重复航
#inplace:直接在原来数据上修改还是保留一个副本以上是去重函数的参数以及参数解释
#按照某一列进行去重,并保留第一次出现的行
dt_dedupe=dt.drop_duplicates('MR049',keep='first')
dt_dedupe.shape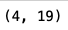
# 按照几列进行去重
dt_dedupe=dt.drop_duplicates(subset=['MR049','ME002'])
dt_dedupe.shape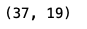
5. 数据基本操作
1. 重命名 df.rename()
# 方法一:制定列名与修改后列名
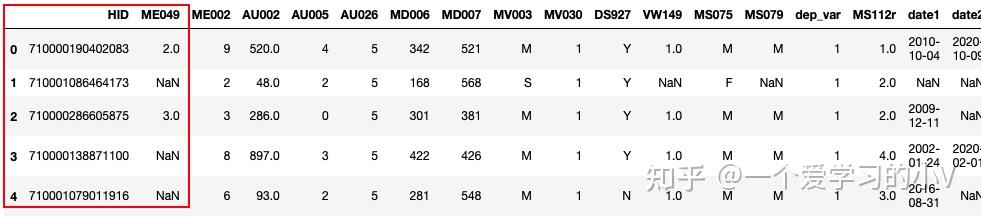
dt_rename=dt.rename(columns={'HOUSEHOLD_ID':'HID','MR049':'ME049'})
dt_rename.head()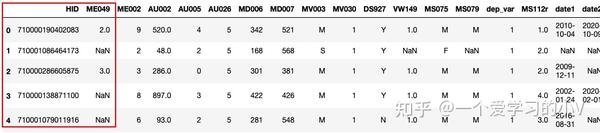
# 方法二:直接写出你想要修改的列名,与原列一一对应
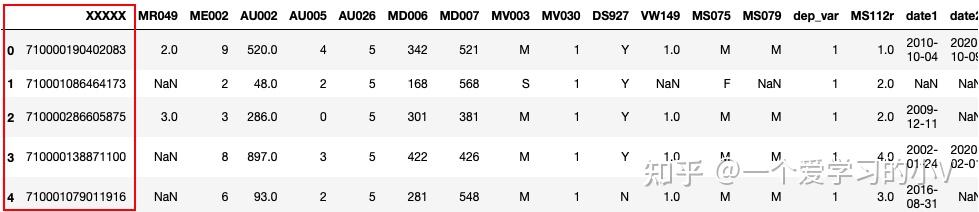
dt.columns=['XXXXX', 'MR049', 'ME002', 'AU002', 'AU005', 'AU026',
'MD006', 'MD007', 'MV003', 'MV030', 'DS927', 'VW149', 'MS075',
'MS079', 'dep_var', 'MS112r', 'date1', 'date2', 'id']
dt.head()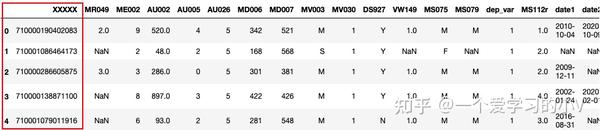
2. 抽样 df.sample()
# n 抽样个数
# frac=0.05 按总记录数的比例进行抽样,不可与n同时使用
# replace: True-有放回抽样;False-不放回抽样 - 默认不放回
# weights=None
# random_state=随机数种子,可以是随便一个整数,如果没有此参数,则每次选取的样本数是随机的。如果添加则每次选择的样本是相同的以上是sample参数以及对应解释
dt.sample(n=1000,replace=False,random_state=123)
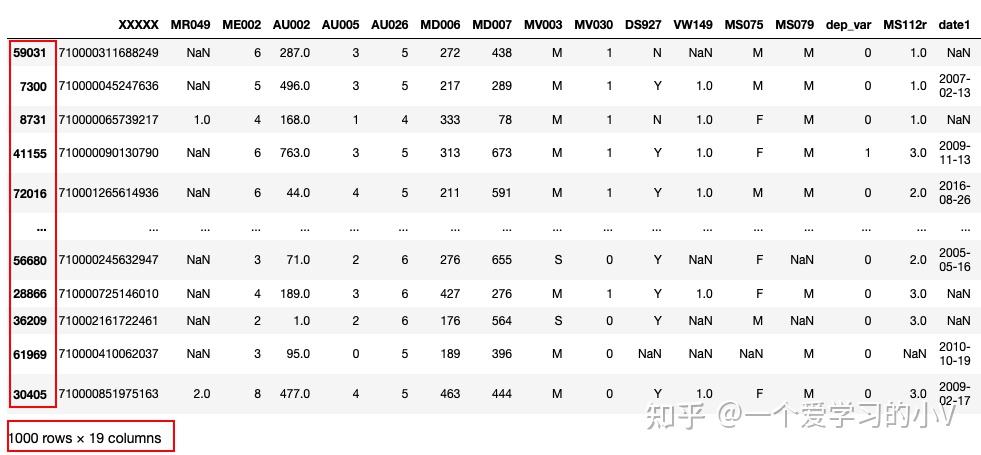
index被随机打乱,且产生了1000条记录
dt.sample(frac=0.01,replace=False,random_state=123) 
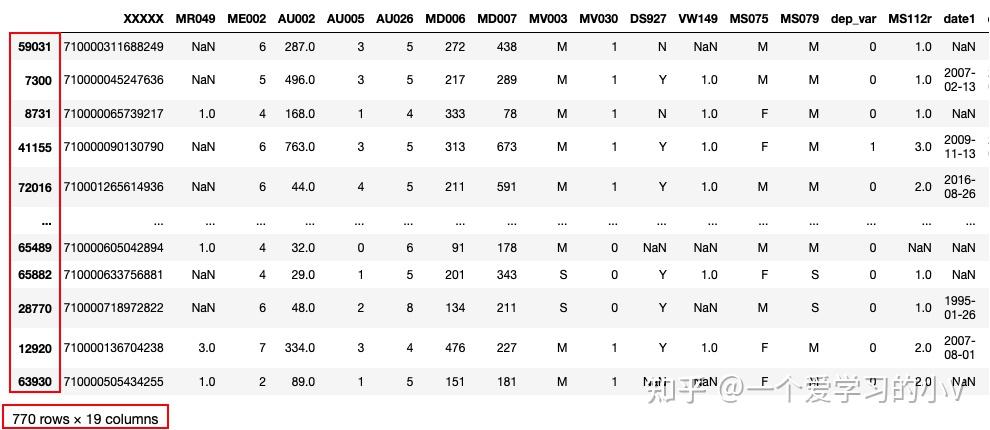
index被随机打乱,且只产生了770条记录,约为总记录的1%
3. 条件筛选
1. 筛选行
# 单条件筛选
dt1=dt[dt['AU005']==1]#数据某列取值先确定,再引用这个值
dt1.head()
# 多条件筛选 且
dt2=dt[(dt['AU005']==1)&(dt['AU026']==5)]
dt2.head()

# 多条件筛选 或
dt3=dt[(dt['AU005']==1)|(dt['AU026']==5)]
dt3.head()
2. 筛选列
# 如果出现字符型的代码就要用loc,如果是纯数字的则用iloc
dt_sort_dedup_1=dt.loc[:,"MR049":"MV003"]
dt_sort_dedup_1=dt.iloc[:,[0,1,2,3]]
dt_sort_dedup_1=dt.iloc[:,0:2] #前闭后开,从0编号
dt_sort_dedup_1=dt[["MR049","ME002"]]以上是筛选列常用方式,在这里我就不一一展示了,大家可以自己尝试一下
6. 数据预处理
有了以上知识的储备,对数据的基本操作算是学会了,接下来将介绍在数据分析工作中,需要占据数据分析师大量时间的数据处理流程,在这一阶段,数据分析师需要对将分析的数据做很多处理,如:缺失值处理,异常值处理,连续变量离散化处理,哑变量处理,数据聚合等。以下将为大家一一介绍:
1. 缺失值处理 (删除/填充)
1.1 缺失值删除- df.dropna()
# 函数形式:dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
# axis:轴,0或'index',表示按行删除;1或'columns',表示按列删除。
# how:筛选方式。‘any’,表示该行/列只要有一个以上的空值,就删除该行/列;‘all’,表示该行/列全部都为空值,就删除该行/列。
# thresh:非空元素最低数量。int型,默认为None。如果该行/列中,非空元素数量小于这个值,就删除该行/列。
# subset:子集。列表,元素为行或者列的索引。如果axis=0或者‘index’,subset中元素为列的索引;如果axis=1或者‘column’,subset中元素为行的索引。由subset限制的子区域,是判断是否删除该行/列的条件判断区域。
# inplace:是否原地替换。布尔值,默认为False。如果为True,则在原DataFrame上进行操作,返回值为None。以上是函数参数以及参数解释
# 删除任何列有缺失值的行
cleandt=dt.dropna()
print('cleandt:',cleandt.shape,'dt:',dt.shape)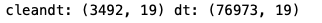
# 删除所有列都是缺失值的行
cleandt=dt.dropna(how='all')
cleandt.shape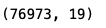
cleandt=dt.dropna(axis=1,thresh=30000)
cleandt.head()
cleandt.shape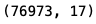
1.1 缺失值填充- df.fillna()
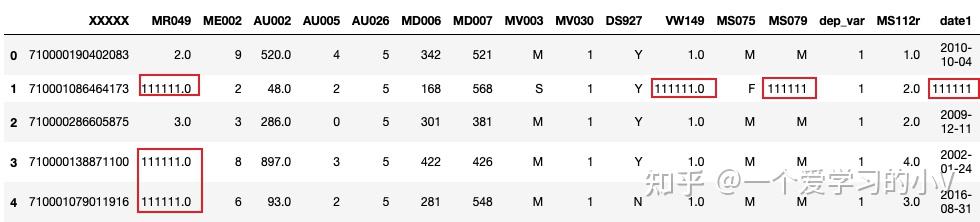
#对所有缺失值用相同常数进行填充
filled=dt.fillna(111111)
filled.head()
# 注:字符型变量也会被填充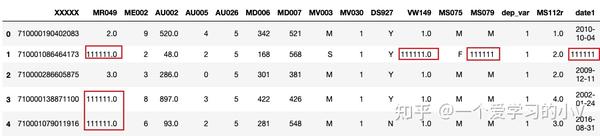
# 对所有缺失值用相同字符串进行填充
filled=dt.fillna("aaaa")
filled.head()
#注:原本数值型变量也被填充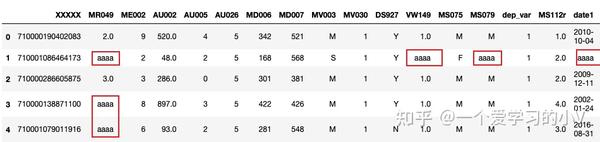
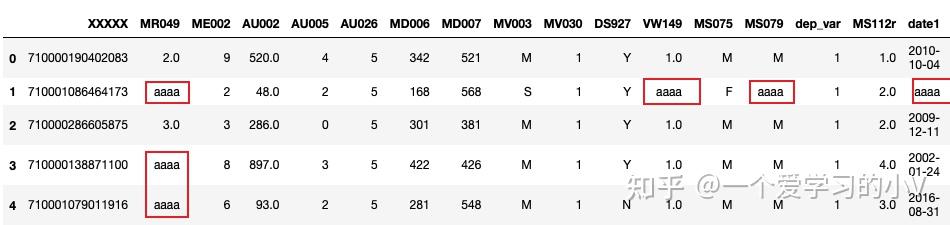
#对不同变量填充不同值
filled=dt.fillna({'MR049':222222,'AU002':1111111})
filled.head()
filled[['MR049','AU002']].describe()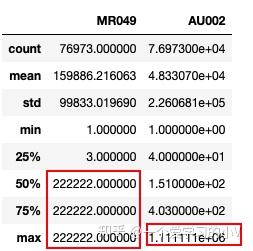
#用字段缺失值前一个数值或后一个数值进行填充(常用于时间序列中)
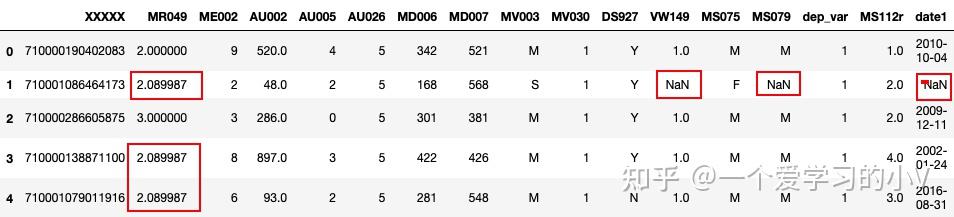
filled=dt.fillna(method='ffill') #用前一个值填充缺失值 front
filled.head()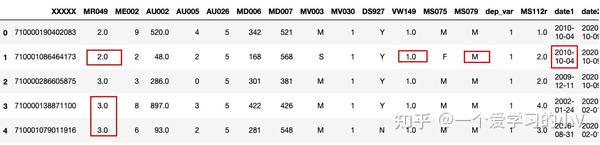
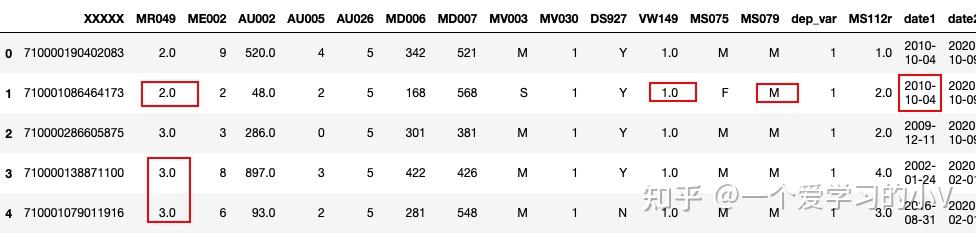
filled=dt.fillna(method='bfill') #用后一个值填充缺失值 behind
filled.head()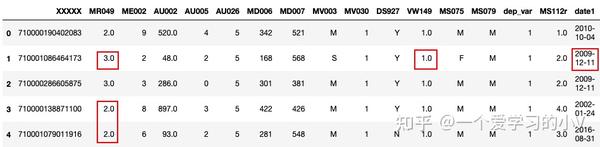
# 用该列的平均值或中位数填充该列
# dt.mean() # 输出所有数据集中所有数值型变量的均值
filled=dt.fillna(dt.mean())
filled.head()
# 注:只填充数值型变量,字符型变量不变(字符型变量没有平均值或中位数)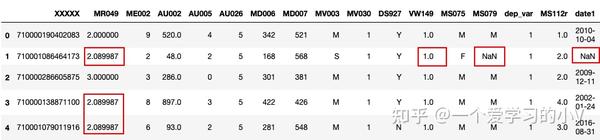
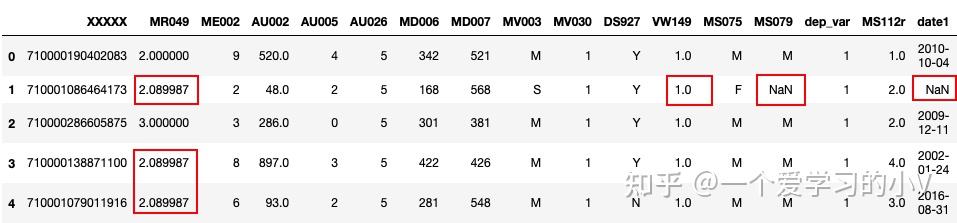
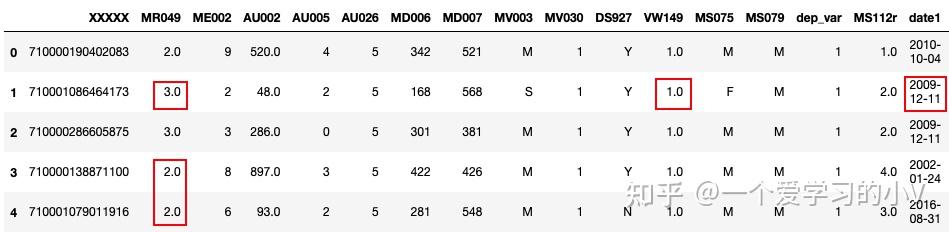
# 用该列的分位数进行填充该列
filled=dt.fillna(dt.quantile(0.5))
filled.head()
# 注:只填充数值型变量,字符型变量不变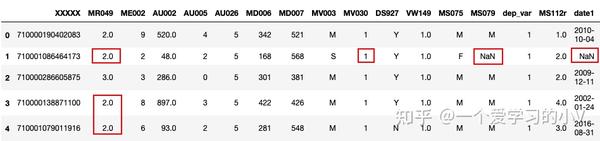
#用指定列的指定方式填充所有列
filled=dt.fillna(dt.mean()['MR049'])
filled.head()
# 注:所有列都会被填充,与不指定列的区别是是否填充所有列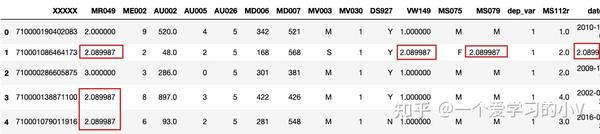
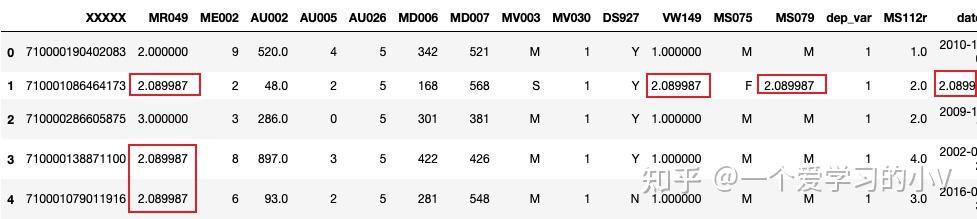
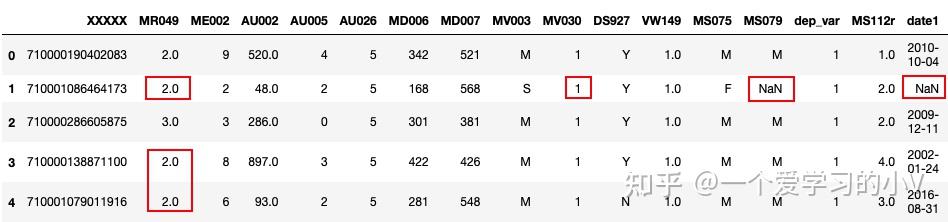
#用指定列的指定方式填充指定列,其他列不变
filled=dt.fillna({'MR049':dt.mean()['MR049']})
filled.head()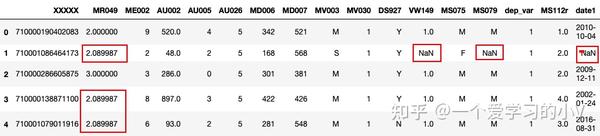
2. 异常值处理 df.quantile()
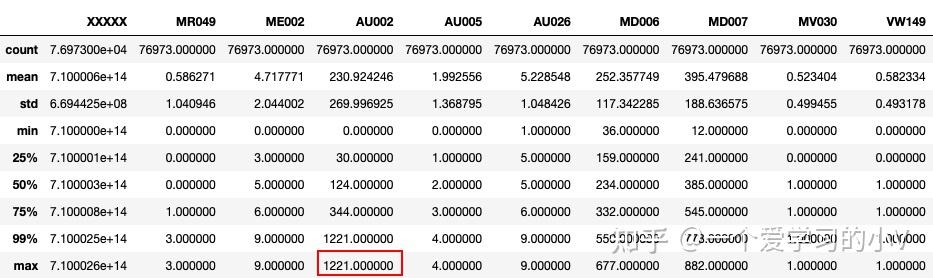
一般当我们获取数据后,原始数据中可能由于业务系统问题或者是由于认为人为问题导致的异常值,如极大值或者极小值,偏离数据群体太多的数据。 这个时候需要对数据进行异常值处理,因为异常值的存在对结果的判断产生误导。 异常值处理一般会将极大值用99%分位数代替,极小值一般用0或者1%分位数替代,这个具体要原始数据分布情况
# 输出数据统计描述
dt.describe()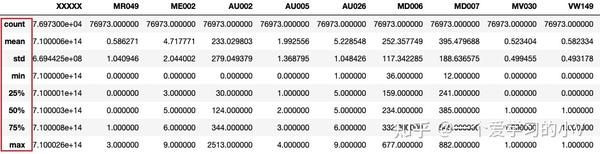
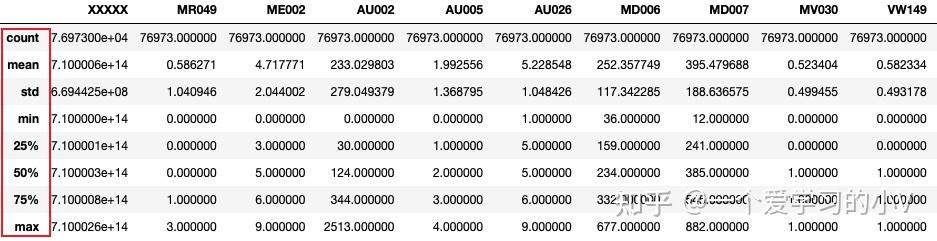
# 输出数据统计描述,人为设置输出分位数
dt.describe(percentiles=[0.25,0.5,0.75,0.99])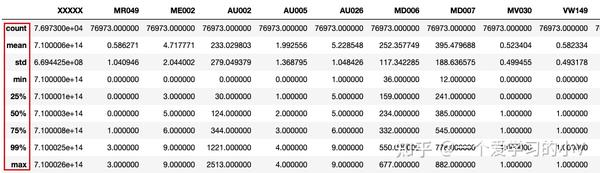
也可以用quantile 函数输出99%分位数
dt.quantile(0.99)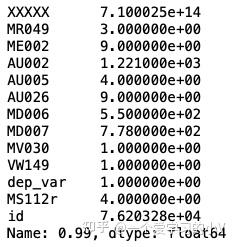
#将大于99%分位数的值用99%分位数替换
dt['AU002']=np.where(dt['AU002']>dt['AU002'].quantile(0.99),dt['AU002'].quantile(0.99),dt['AU002'])
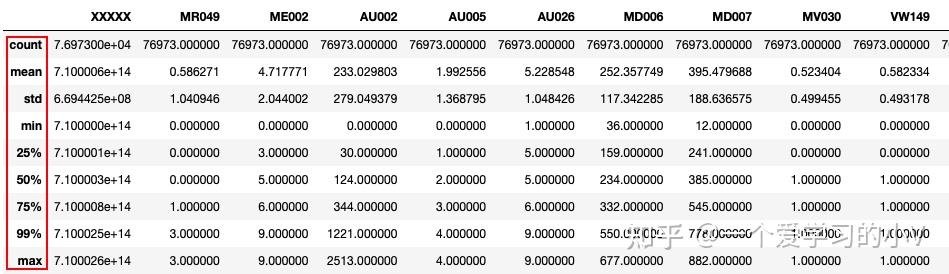
dt.describe(percentiles=[0.25,0.5,0.75,0.99]) 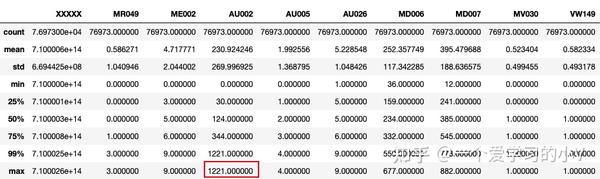
3. 连续变量离散化处理
连续变量离散化处理是将原始数据中的数值型变量进行分类型处理,例如,我们在一组客户数据中收集到的客户年龄是从15-80岁之间的连续值,但是这样的数据不方便我们做分析统计,因此我们需要将这些数据进行离散化处理,变成类似15-25岁,26-40岁,40-60岁,60岁+ 这种分段处理,这样我们好进行统计分析,同时也比较符合实际业务中该字段的使用
一般我们有以下几种方式进行离散化处理
- 3.1 等宽
- 3.1.1 用指定分段进行分组
- 3.1.2 用最大最小值分成相同长度的箱子
- 3.2 等深
- 3.2.1 用最大最小值指定分组个数进行分位数分割
- 3.2.2 用指定分位数进行分组
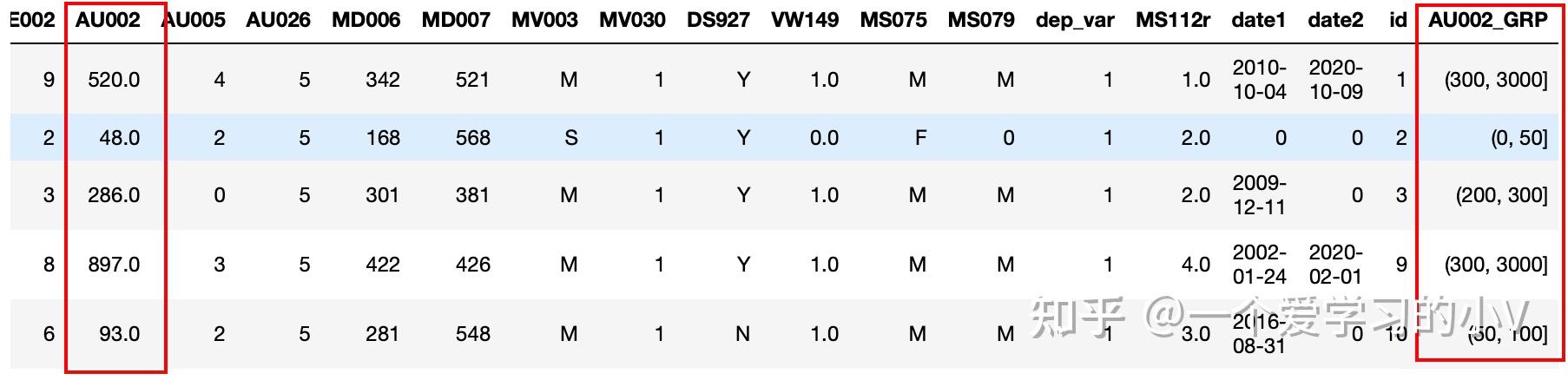
# 3.1.1 用指定分段进行分组
bins=[0,50,100,200,300,3000]#设置分箱的分段
dt['AU002
_GRP']=pd.cut(dt['AU002'],bins)#指定某个字段,将其按照设置的分段进行分段并重新设置字段名,默认左开右并
dt.head()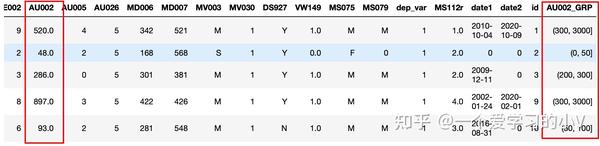
# 3.1.2 用最大最小值分成相同长度的箱子
dt['AU002_GRP']=pd.cut(dt['AU002'],4) #用变量的最大最小值差值,除以要分段的个数(4)得到每个箱子的长度 (1221-(-1.221))/4=305
b=pd.value_counts(dt['AU002_GRP'],sort=False,dropna=True)
b.plot(kind='bar')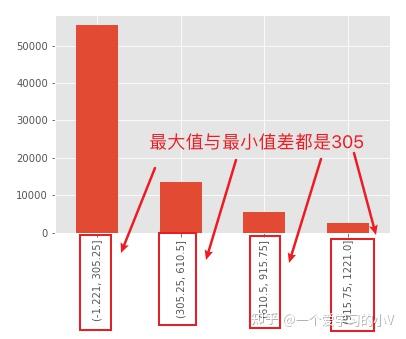
3.2.1 用最大最小值指定分组个数进行分位数分割
dt['AU002_GRP']=pd.qcut(dt['AU002'],4)
dt.head()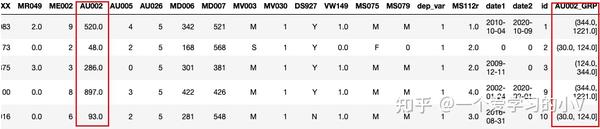
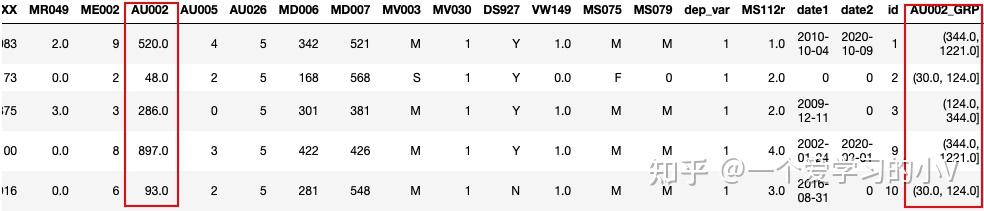
b=pd.value_counts(dt['AU002_GRP'],sort=False,dropna=True)
b.plot(kind='bar')#等分,每个分组里面的数量一样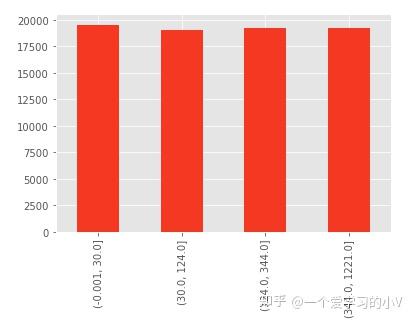
3.2.2 用指定分位数进行分组
bins=[0,0.1,0.5,0.9,1.0]
dt['AU002_GRP']=pd.qcut(dt['AU002'],bins)
dt.head()
b=pd.value_counts(dt['AU002_GRP'],sort=False,dropna=True)
b.plot(kind='bar')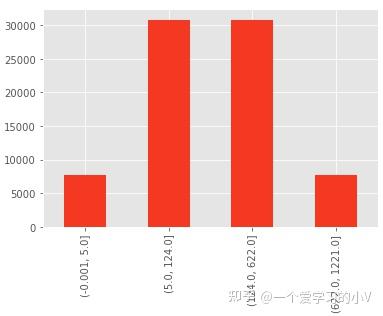
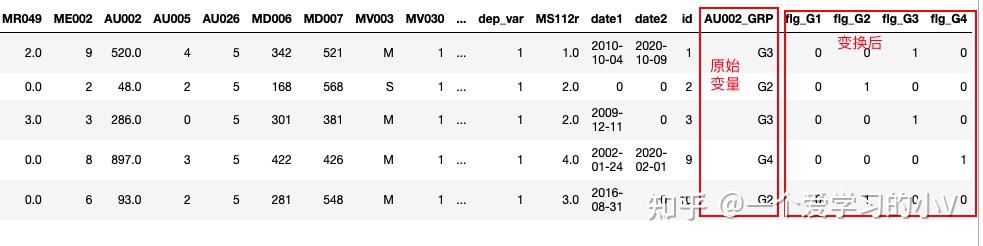
4. 计算哑变量 pd.get_dummies()
数据做哑变量处理是指将字符型变量转化成数值型变量。如有一个变量是学历(初中及以下,高中,大专,本科及以上)我们将其转化成四个字段,分别对应原有变量内容,如果原有变量中有该值则新变量为1,否则为0,一般是在建模时候会用到,因为有的模型只能针对数值型变量,如XGBoost模型。有时候我们也叫 One-Hot Encoding或One-Hot 编码
dummies=pd.get_dummies(dt['AU002_GRP'],prefix='flg') # 变换后,新变量前缀,添加 flg
dt=dt.join(dummies)
dt.head()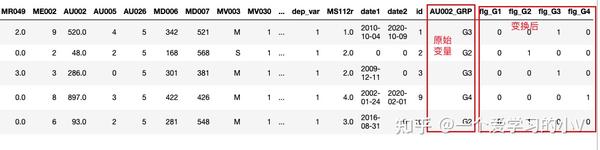
数据聚合 df.groupby()
- 一个主键,全局聚合
- 一个主键,指定列聚合
- 两组主键,全局聚合
- 两组主键,指定列聚合聚合
1. 一个主键,全局聚合
dt.groupby('MV003').mean() # 指定需要分组的变量,以及要聚合的方式

2. 一个主键,指定列聚合
dt.groupby('MV003')['AU002'].count() #统计字符串里某个字符或子字符串出现的次数
dt.groupby('MV003')['AU002'].mean() # 统计字符串均值
dt.groupby('MV003')['AU002'].nunique() # nunique返回唯一值个数 unique返回数组,具体唯一值的取值
dt.groupby('MV003')['AU002'].first()
dt.groupby('MV003')['AU002'].last()
dt.groupby('MV003')['AU002'].max() #求最大值