本文将如何如何使用HuggingFace中的翻译模型。
HuggingFace是NLP领域中响当当的团体,它在预训练模型方面作出了很多接触的工作,并开源了许多预训练模型和已经针对具体某个NLP人物训练好的直接可以使用的模型。本文将使用HuggingFace提供的可直接使用的翻译模型。
HuggingFace的翻译模型可参考网址:
https://huggingface.co/models?pipeline_tag=translation
,该部分模型中的绝大部分是由Helsinki-NLP(Language Technology Research Group at the University of Helsinki)机构开源,模型数量为1333个。
笔者将在PyTorch框架下使用HuggingFace的
中译英模型
和
英译中模型
。其中
中译英模型
的模型名称为:opus-mt-zh-en,下载网址为:
https://huggingface.co/Helsinki-NLP/opus-mt-zh-en/tree/main
;
英译中模型
的模型名称为opus-mt-en-zh,下载网址为:
https://huggingface.co/Helsinki-NLP/opus-mt-en-zh/tree/main
。
首先我们先尝试
中译英模型
,即把中文翻译成英语,代码如下:
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("./opus-mt-zh-en")
model = AutoModelForSeq2SeqLM.from_pretrained("./opus-mt-zh-en")
text = "从时间上看,中国空间站的建造比国际空间站晚20多年。"
batch = tokenizer.prepare_seq2seq_batch(src_texts=[text])
batch["input_ids"] = batch["input_ids"][:, :512]
batch["attention_mask"] = batch["attention_mask"][:, :512]
translation = model.generate(**batch)
result = tokenizer.batch_decode(translation, skip_special_tokens=True)
print(result)
翻译结果如下:
["In terms of time, the Chinese space station was built more than 20 years later than the International Space Station."]
接着我们先尝试英译中模型,即把英文翻译成汉语,代码如下:
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("./opus-mt-en-zh")
model = AutoModelForSeq2SeqLM.from_pretrained("./opus-mt-en-zh")
text = "In terms of time, the Chinese space station was built more than 20 years later than the International Space Station."
batch = tokenizer.prepare_seq2seq_batch(src_texts=[text])
batch["input_ids"] = batch["input_ids"][:, :512]
batch["attention_mask"] = batch["attention_mask"][:, :512]
translation = model.generate(**batch)
result = tokenizer.batch_decode(translation, skip_special_tokens=True)
print(result)
翻译结果如下:
['就时间而言,中国空间站的建造比国际空间站晚了20多年。']
有了HuggingFace的transformers模块,我们使用起这些模型相当方便,同时也有很不错的翻译效果。
接着我们再接触一款工具,名称为shap。shap是Python开发的一个模型解释包,可以任何机器学习模型的输出。其名称来源于SHapley Additive exPlanation,在合作博弈论的启发下SHAP构建一个加性的解释模型,所有的特征都视为“贡献者”。对于每个预测样本,模型都产生一个预测值,SHAP value就是该样本中每个特征所分配到的数值。
我们尝试着使用shap模块来对翻译模型进行解释,可以看到shap可视化效果非常棒的解释界面,如下:

默认输出结果为翻译结果,如下:
模型解释的热力图效果如下:
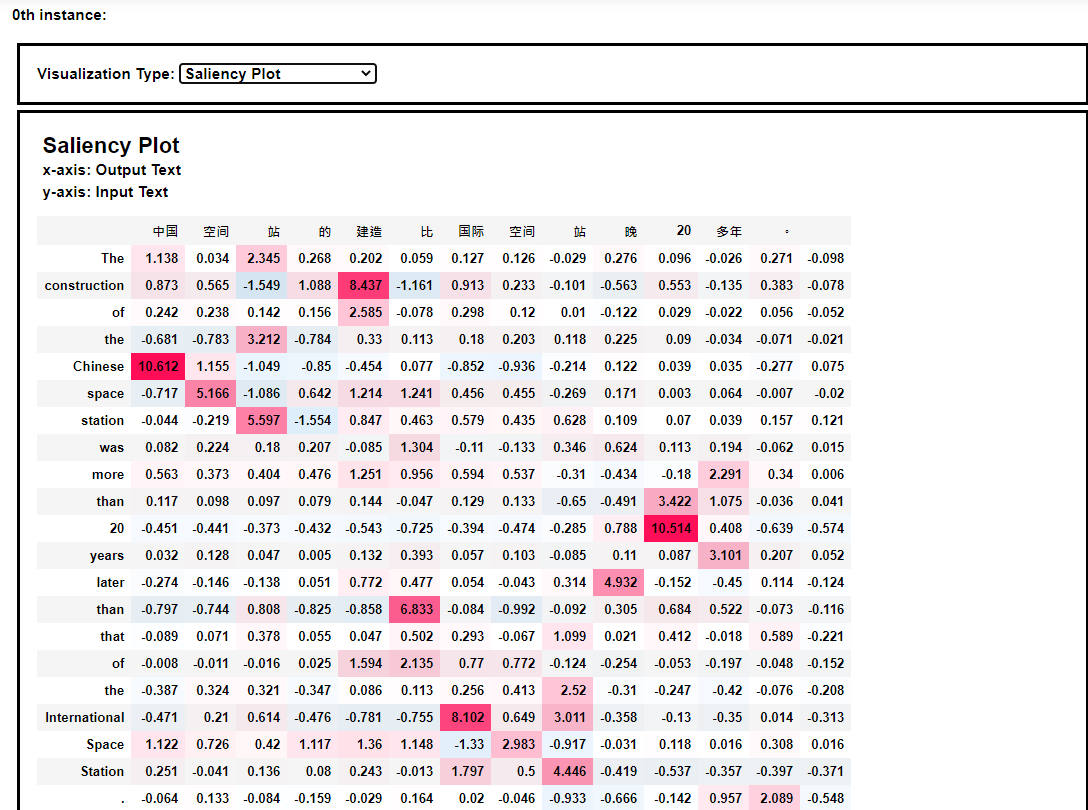
从热力图中我们可以发现,空间站这个词语被翻译成space station。
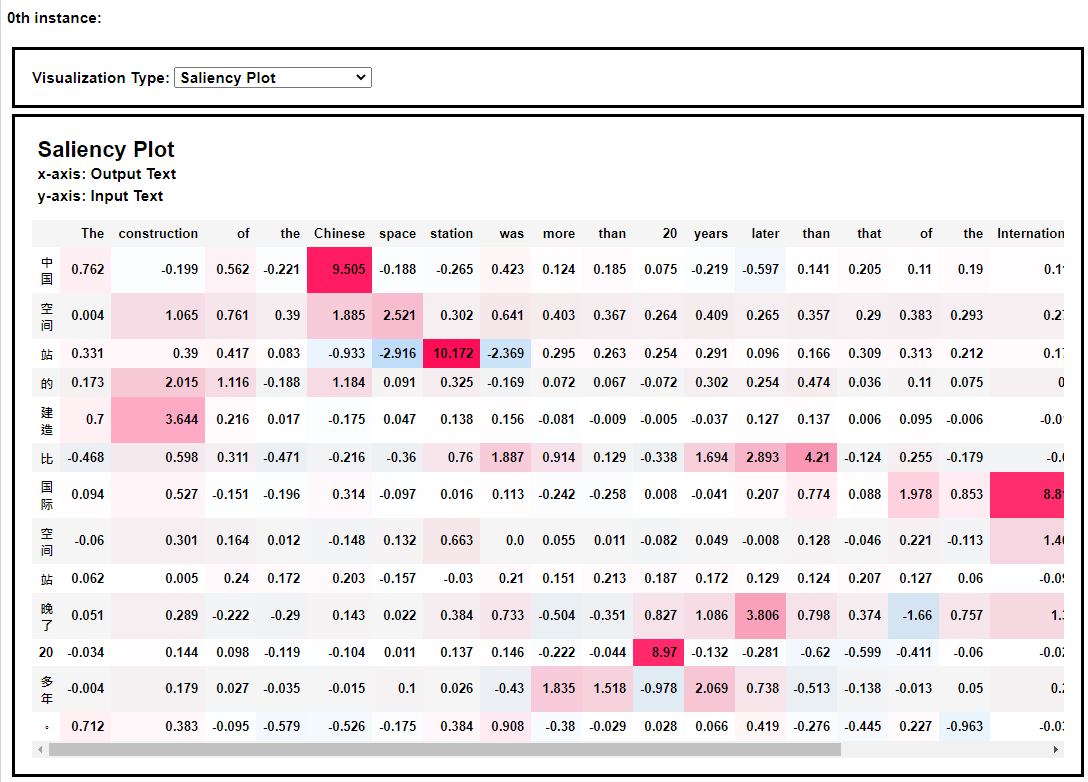
同样,我们可以看到英译中模型的热力图解释效果,如下:
本次分享到此结束,感谢大家阅读~
2021年3月10日于上海浦东~
- HuggingFace translation model: https://huggingface.co/models?filter=zh&pipeline_tag=translation
- Text to Text Explanation: Machine Translation Example: https://shap.readthedocs.io/en/latest/example_notebooks/text_examples/translation/Machine%20Translation%20Explanation%20Demo.html
加载模型页面为:https://huggingface.co/liam168/trans-opus-mt-zh-en
文章目录整理文件跑通程序,测试预训练模型拆解Pipeline,逐步进行翻译任务
首先下载模型所需的全部文件:https://huggingface.co/liam168/trans-opus-mt-zh-en/tree/main,将文件全部下载到本地,命名为trans_model
然后创建一个调用模型的python程序文件:use_translate.py
整个文件结构如下:
训练Opus-MT型号
该软件包包括用于使用MarianNMT和OPUS数据训练NMT模型的脚本。 中提供了更多详细信息,但文档需要改进。 此外,目标需要特定的环境,并且目前仅在芬兰的CSC HPC集群上运行良好。
预训练模型
子目录包含有关可以从该项目下载的预训练模型的信息。 它们散发了许可证。
git clone https://github.com/Helsinki-NLP/OPUS-MT-train.git
git submodule update --init --recursive --remote
make install
训练多语言NMT模型(芬兰语和爱沙尼亚语到丹麦语,瑞典语和英语):
make SRCLANGS="fi et" TRGLANGS="da sv en" train
make SRCLANGS="fi et" TRGLANGS="da
Sequence-to-Sequence(Seq2Seq)作为一种深度学习模型,在机器翻译、文本摘要、描述图像等任务中取得了诸多进展。谷歌翻译于 2016 年底开始在实际生产中使用该类模型。在 Sutskever et al., 2014 和 Cho et al., 2014 的两篇开创性论文中对这些模型进行了解释。然而,要充分理解模型并实践,一个跟一个的概念会让人望而却步,以视觉化的表达则更容易让人理解。
DL翻译
基于深度学习的翻译库,基于Huggingface transformers和Facebook的mBART-Large
:laptop: :books: / :snake: :test_tube: /
用pip安装库:
pip install dl-translate
要翻译一些文本:
import dl_translate as dlt
mt = dlt . TranslationModel () # Slow when you load it for the first time
text_hi = "संयुक्त राष्ट्र के प्रमुख का कहना है कि सीरिया में कोई सैन्य समाधान नहीं है"
mt . translate ( text_hi , source = dlt . lang . HINDI , target = dlt . lang .
BERT (from Google) released with the paper BERT: Pre-training of Deep Bidirectional Transformers for Language Understandi.
在线翻译,一般是指在线翻译工具,如百度翻译、阿里翻译1688或Google翻译等。这类翻译工具的作用是利用计算机程序将一种自然语言(源语言)转换为另一种自然语言(目标语言)。其原理是依托海量的互联网数据资源和自然语言处理技术,在数百万篇文档中查找各种模式,以求解最佳翻译。这种在大量文本中查找各种范例的过程称为“统计机器翻译”。由于译文是由机器生成的,因此并不是所有的译文都是完美的。这就是为什么翻译的准确性有时会因语言的不同而有所差异。
对预先训练过的模特进行微调
使用预先训练过的模型有很大的好处。它降低了计算成本,你的碳足印,并允许你使用最先进的模型,而不必从头开始训练一个。Transformer提供了数以千计的预先训练的模型,广泛的任务。当你使用一个预先训练好的模型时,你会在一个特定于你任务的数据集上训练它。他的作品被称为微调,一种非常强大的训练技巧。在本教程中,您将使用自己选择的深度学习框架对一个预先训练好的模型进行微调:
微调一个预先训练的模式与变形金刚训练机。
用 Keras 微调 TensorFlow 中的预训练模型。
前言:目前翻译都是在线的,要在C#开发的程序上做一个可以实时翻译的功能,好像不是那么好做(其实主要是第三方的都要AppID或者授权,太不友好了)。而且大多数处于局域网内,所以访问在线的api也显得比较尴尬。于是,就有了以下这篇文章,自己搭建一套简单的离线翻译系统(当然,你也可以部署到有外网的云服务器上,那就可以变成在线的翻译系统了)。以下内容采用python提供基础翻译服务+ C#访问服务的功能,欢迎围观。
简单的说,Helsinki-NLP/opus-mt-en-zh是一个机器翻译模型,可以进行英语和中文之间的翻译,而Facebook/nllb-200-distilled-600M是一个自然语言处理模型,适用于多种NLP任务,如分类、命名实体识别和情感分析等。Helsinki-NLP/opus-mt-en-zh和Facebook/nllb-200-distilled-600M是两种截然不同的模型,它们的结构也完全不同。这种情况,所以建议还是使用Helsinki-NLP/opus-mt-zh。
Huggingface里面的模型封装的很好,想要直接修改代码并非容易的事,但是如果看文档,它有很多参数,能把你想到的大部分结果取出来,下面我就以一次经历来讲讲我如何在T5模型上面加一个featurefusion层。复制下来查看,发现可以直接用T5.encoder对input_ids进行编码,然后把encoder_outputs直接输入T5ForConditionalGeneration,就可以了。查看文档,可以直接把模型的输入参数输入generate函数里面。...

