

【Pd-07】pandas数据拼接合并concat,merge,join

| 函数 | 使用场景 | 调用方法 | 备注 |
|---|---|---|---|
| concat | 用于2个及以上df的行或列方向进行内联或外联,默认行拼接,取并集,一般是行的纵深方向合并 | res = pd.concat([df1, df2], axis=1) | axis设置方向 |
| merge | 用于2个及以上df的行或列方向进行内联或外联,默认列拼接,取交集,一般是横向扩展 | res = pd.merge([df1, df2], how="left") | 类似SQL数据库,有左联,右联,内联和外联 |
| join | 用于列方向的拼接,默认左列拼接,how="left" | df1.join(df2) | 左联,右联,内联和外联 |
| append | df行方向的拼接 | df1.append(df2) | 纵深方向合并 |
说明 :重点掌握concat和merge即可,大部分情况下都可以使用这两个完成,concat在纵深方向,merge在横向扩展上。join是类似于merge,append是类似于concat。
1、concat
#数据构造
df1 = pd.DataFrame({
"aa":['a1','a2','a3','a4'],
"bb":['b1','b2','b3','b4'],
"cc":['c1','c2','c3','c4'],
"dd":['d1','d2','d3','d4'],
df2= pd.DataFrame({
"aa":['a5','a6','a7','a8'],
"bb":['b5','b6','b7','b8'],
"ee":['e5','e6','e7','e8'],
"ff":['f5','f6','f7','f8'],
)1.1 语法格式
pandas.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, sort=None, copy=True) 1.2 参数说明
- objs:series,dataframe或者是panel对象构成的序列lsit
- axis:指明连接的轴向, {0/’index’(行), 1/’columns’(列)}, 默认为0
- join:指明连接方式 , {‘inner’(交集), ‘outer(并集)’}, 默认为outer
- join_axes:自定义的索引。指明用其他n-1条轴的索引进行拼接, 而非默认join =’ inner’或’outer’方式拼接
- keys:创建层次化索引。可以是任意值的列表或数组、元组数组、数组列表(如果将levels设置成多级数组的话)
- ignore_index=True:重建索引
1.3 核心功能
两个DataFrame通过pd.concat(),既可实现行拼接又可实现列拼接,默认 axis=0,join='outer' 。表df1和df2的行索引(index)和列索引(columns)均可以重复。
1、设置join='outer',只是沿着一条轴,单纯将多个对象拼接到一起,类似数据库中的全连接(union all)。
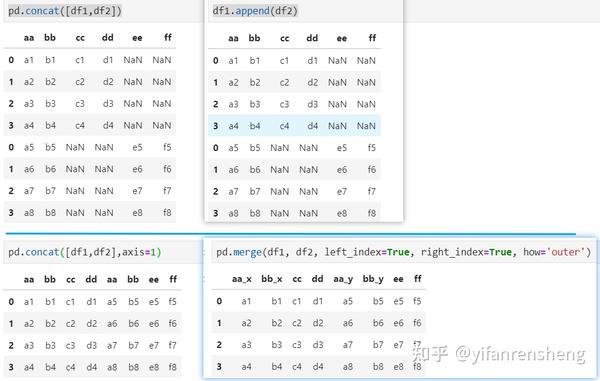
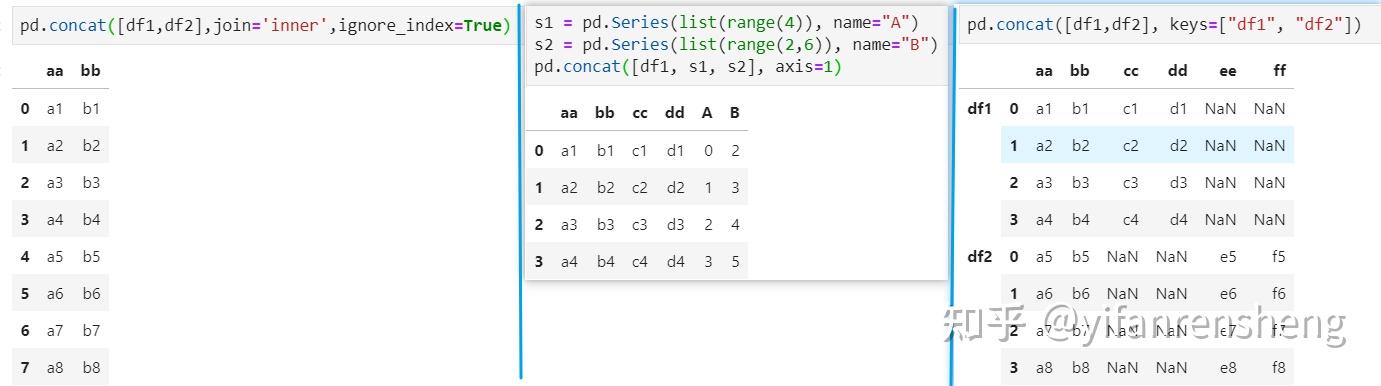
a. 当axis=0(行拼接)时,使用pd.concat([df1,df2]),拼接表的index=index(df1) + index(df2),拼接表的columns=columns(df1) ∪ columns(df2),缺失值填充NaN。 等价于 :df1.append(df2)
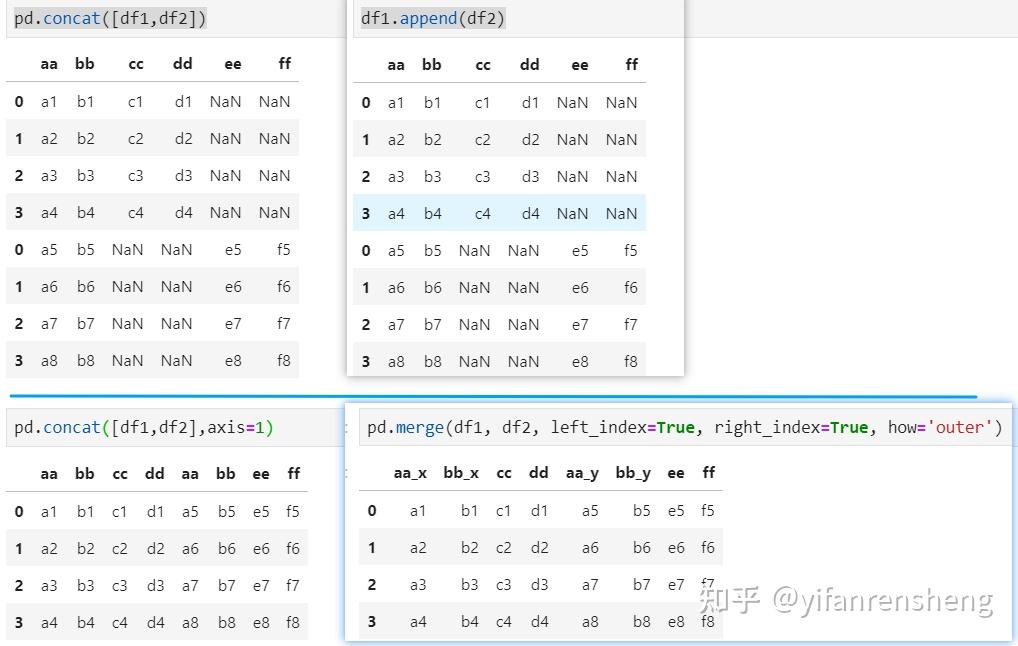
b. 当axis=1(列拼接)时,使用pd.concat([df1,df2],axis=1),拼接表的index=index(df1) ∪ index(df2),拼接表的columns=columns(df1) + columns(df2),缺失值填充NaN。 类似与:pd.merge(obj1, obj2, left_index=True, right_index=True, how='outer')
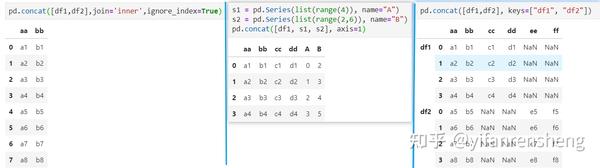
2、设置join='inner',拼接方式为“交联”,即:行拼接时,仅保留df1和df2列索引重复的列;列拼接时,仅保留df1和df2行索引重复的行。
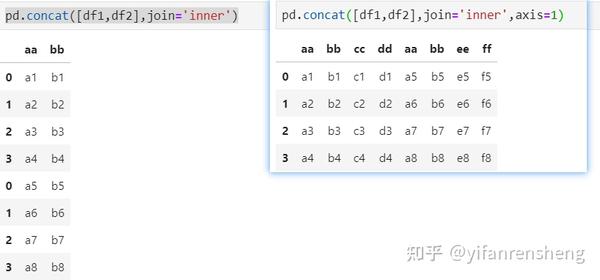
a. 当axis=0(行拼接)时,使用pd.concat([df1,df4],join='inner'),拼接表的index=index(df1) + index(df2),拼接表的columns=columns(df1) ∩ columns(df2);
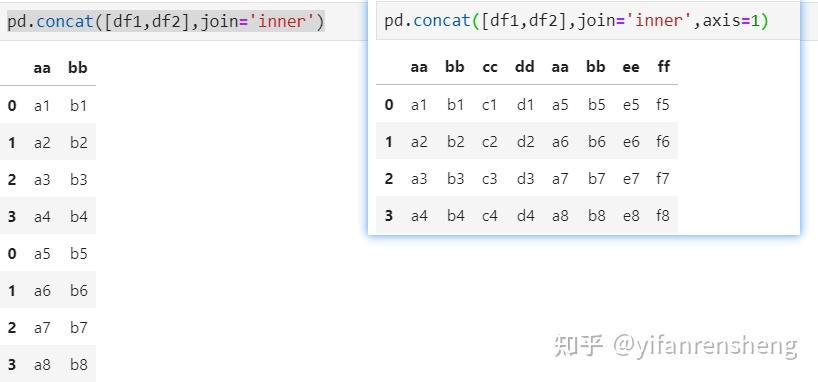
b. 当axis=1(列拼接)时,pd.concat([df1,df4],axis=1,join='inner'),拼接表的index=index(df1) ∩ index(df2),拼接表的columns=columns(df1) + columns(df2);
1.4 其他的参数
- ignore_index=True可以忽略原来的索引
- 添加一列Series,也可以添加多列Series
- keys参数作用:可以用来给合并后的表增加key来区分不同的表数据来源
1.5 常见的一个报错信息
TypeError: first argument must be an iterable of pandas objects, you passed an object of type "DataFrame"
出错原因就是,在使用pandas.concat (a,b) 进行合并的时候,需要是list的形式。因此改成pandas.concat( [a,b] ),就可以成功合并。
2、merge
数据构造
df1 = pd.DataFrame({
"aa":['a1','a1','a2','a3'],
"bb":['b1','b2','b2','b4'],
"cc":['c1','c2','c3','c4'],
"dd":['d1','d2','d3','d4'],
df2= pd.DataFrame({
"aa":['a1','a1','a3','a4'],
"bb":['b1','b2','b3','b4'],
"ee":['e5','e6','e7','e8'],
"ff":['f5','f6','f7','f8'],