

时间序列分解1

关于时间序列分解,之前提到过gbdt的外推能力差,对于强趋势型序列数据建模能力不足的问题,除了差分或者增长率变换(这两个不一定有效,可能做完差分或者增长率之后还是趋势性的,即加速度都是不断增大的,并且差分和增长率在工程上的设计比较麻烦,因为你最终是要预测真实的标签,所以还需要根据某个时间点对差分进行累计计算,同时可能会出现预测出来的标签为负数的情况就很坑爹了)
时间序列模式(pattern)
趋势
当数据长期增加或减少的情况存在的时候我们认为这个数据有趋势,趋势它不必是线性的。有时,当趋势从上升趋势变为下降趋势时,我们将其称为“变化方向”。下图是抗糖尿病药物的销售数据的趋势。
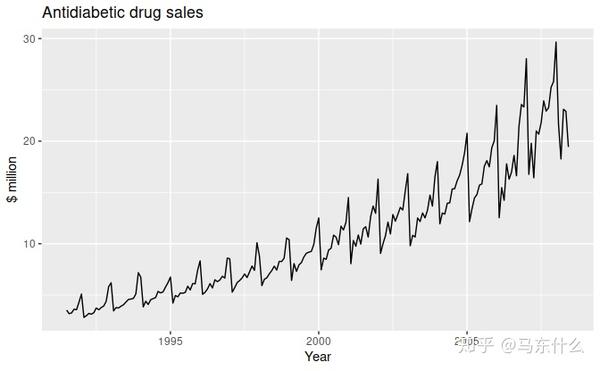
现实数据常常存在多趋势叠加,尤其是长期的股票指数数据,很难用单个趋势分量来描述原始的数据。
季节性:
时间序列受季节性因素影响,如一年的12个月或者4个季度,或者一周中的5个工作日和两个周末, 季节性总是具有固定的已知频率 。上述抗糖尿病药物的月度销售显示出季节性,这部分是由于日历年末药物成本的变化引起的。
周期性:
周期性和季节性是比较容易混淆的两个概念,我们前面提到过,季节性的频率是固定的,如果数据波动的频率不是固定的,则属于周期性,通常,周期的平均长度比季节性样式的长度长,因为周期的频率不是固定的,所以周期的大小常常是变动的;
下面给出4个图:
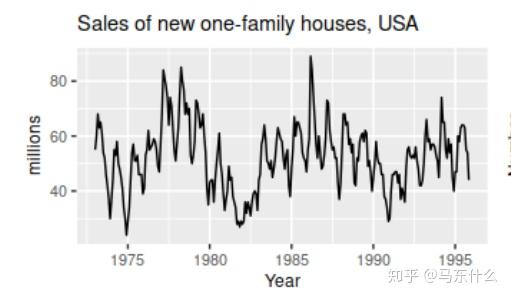
1、美国的每月的房屋销售量数据的plot,可以看到,上述数据在每年显示出明显的的季节性, 并表现出一些明显的周期性行为,周期约为6-10年 。在此期间,数据没有明显的趋势。
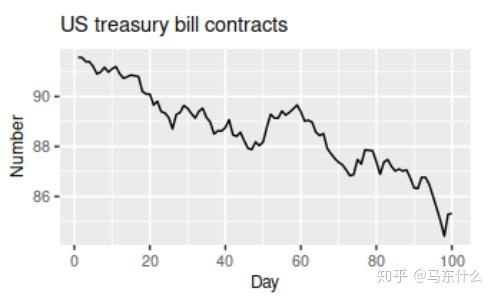
2、美国国库券合同数量,上图显示了1981年芝加哥市场连续100个交易日的结果,这里就没有季节性,但有明显的下降趋势。如果我们有更长的序列,我们会看到这种下降趋势实际上是一个长周期的一部分,但是当仅观察100天时,它似乎是一个趋势。
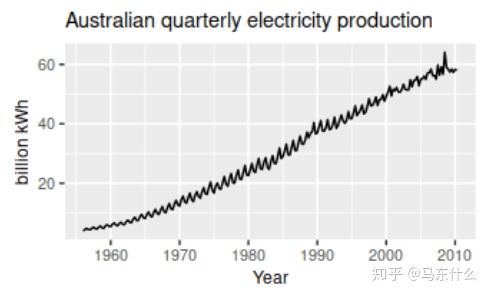
3、澳大利亚的季度电力产量,可以看到上图显示出强劲的增长趋势,并且具有很规律的季节性, 注意这里没有任何周期性 。
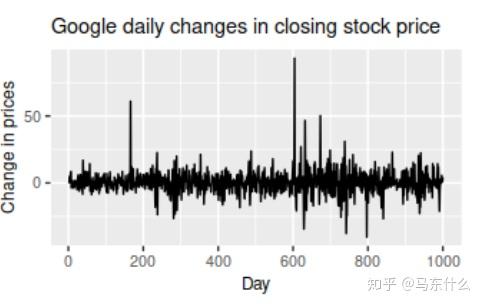
4、Google收盘价的每日变化,没有趋势,季节性或周期性行为。
当然,我觉得分析或建模的时候其实也不用做这么文绉绉的区分,直接就用周期性来指代就好了。
同样,现实世界中的多周期叠加是非常常见的情况,比如销量问题,既有节假日的周期性效应,也有季节性的周期行效应,多周期叠加是一个比较费劲解决的问题。
分解模式
一般来说我们是假定时间序列由 趋势,周期性以及剩余的其它部分组成(例如重大事件等) ,只不过不同的时间序列其占比不同,比如随机波动可能完全是由残差构成的;
我们认为时间序列包含三个部分:趋势性部分,周期性性部分和其它部分(包含时间序列中的任何其他内容)。
一般来说,做事件序列分解有两种方式,加性和乘性:
yt=St+Tt+Rt 加性
yt=St×Tt×Rt 乘性
S代表了season 季节,我觉得用周期更好理解一点。。。,t代表了trend 趋势,r代表了residual 其它部分。
如果周期性波动的幅度或趋势性的强弱不随着时间的推移而发生变化则使用加法分解比较合适,如果季节性波动的幅度或者趋势性的强弱随着时间推移而发生变化(比如销量增长越来越快,销量增长曲线的斜率越来越大)则使用乘法分解比较合适,乘法分解的方式在经济学序列中很常见。
当然我们也可以先对数变换之后再分解:
yt=St×Tt×Rtis 也可以是 log(yt)=logSt+logTt+logRt.
经典的时间序列分解方法
也是比较常见的一种方法:
import os
import numpy as np
from test_stationarity import *
from statsmodels.tsa.seasonal import seasonal_decompose
from statsmodels.tsa.arima_model import ARIMA
from datetime import timedelta
filename = 'api_access_fix.csv'
data = pd.read_csv(filename)
data = data.set_index('date')
data.index = pd.to_datetime(data.index)
ts = data['count']
draw_ts(ts)
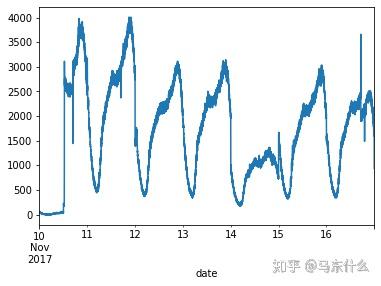
这是原始的时间序列数据:
decomposition = seasonal_decompose(data, freq=5, two_sided=False, model='Additive')
trend = decomposition.trend
seasonal = decomposition.seasonal
residual = decomposition.resid
from pylab import rcParams
rcParams['figure.figsize'] = 11, 9
decomposition = seasonal_decompose(data, period=5, two_sided=False, model='Additive')
fig = decomposition.plot()
plt.show()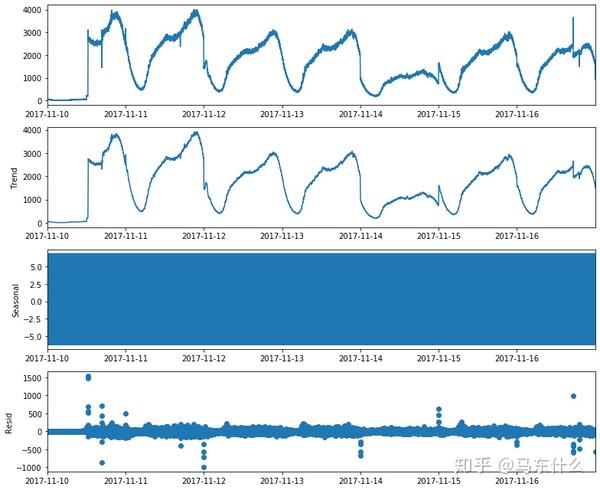
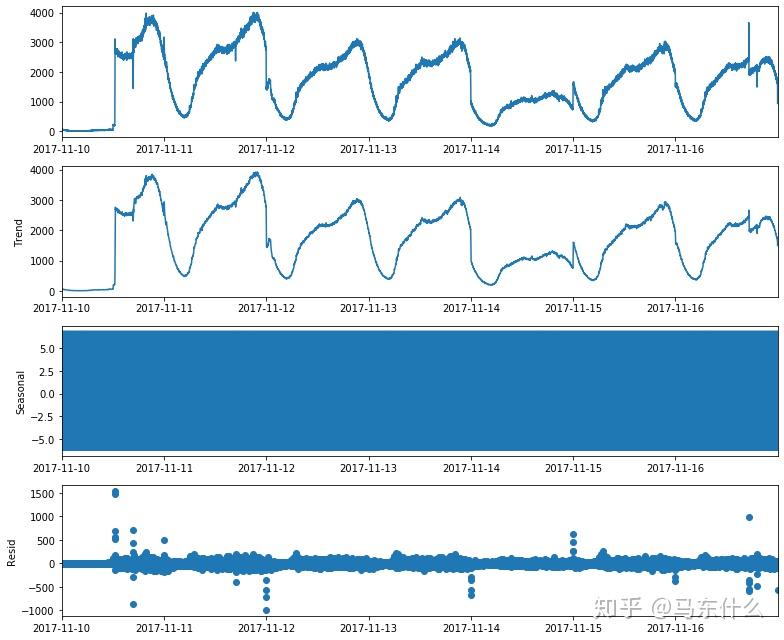
进行分解之后,注意,这里我是随便分解的,可以看到残差的值远大于季节性的值,显然这样的分解是不太好的,置于如何衡量分解效果的好坏后面说。
需要注意,statsmodels的这个season_decompose不是stl分解,statsmodels的api里面包含了STL分解,但是这个season_decompose是经典分解法 ;
首先是trend部分,trend部分很简单就是 简单的移动平均 :
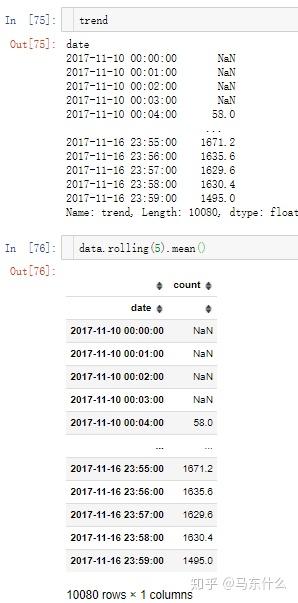
filt 参数用于指定权重,也就是通过filt可以实现人工的加权平均,否则默认的权重是,比如 period 设置为5,则权重分配默认为1/5=0.2,另外就是trend是否进行插值,这个和extrapolate_trend这个参数有关,因为extrapolate_trend涉及到STL分解所以这里暂时不展开了。
然后是周期性部分,经典的时序分解方法的季节性直接是计算原始序列数据-趋势值之后的detrend值在周期内的均值.statsmodel实现的核心代码就是这一句:
period_averages = seasonal_mean(detrended, period)其中detrended的值为:

x是原始数据,根据加性和乘性而不同。
而这个核心函数也很简单:
def seasonal_mean(x, period):