|
gam syntax
|
gam(y~s(x,k = , bs =)) / gam(y~te(x,k = , bs =))
Choose.k
: sets up the dimensionality of the smoothing matrix for each term. Penalized regression smoothers. Using a substantially increased k to see if there is pattern in the residuals that could potentially be explained by increasing k. Default任意数字(normally 10 degree of freedom)。
bs
: See smooth.terms for the full list.
tp
– DEFAULT, thin plate regression spline,
cr
– penalized cubic regression spline三次样条,
cs
– shrinkage version of cr,
cc
– cyclic cubic regression spline,
ps
– P-spline,
cp
– cyclic p-spline,
ad
– adaptive smoothing,
fs
– factor smooth interaction.
s
: smooth s(covariate, edf);
te
: tensor product smooth
gam(formula,family=gaussian(),data=list(),weights=NULL,subset=NULL,
na.action,offset=NULL,method="GCV.Cp",
optimizer=c("outer","newton"),control=list(),scale=0,
select=FALSE,knots=NULL,sp=NULL,min.sp=NULL,H=NULL,gamma=1,
fit=TRUE,paraPen=NULL,G=NULL,in.out,...)
offset
: Can be used to supply a model offset for use in fitting. Note that this offset will always be completely ignored when predicting, unlike an offset included in formula.
control
: A list of fit control parameters to replace defaults returned by gam.control.
method
: smoothing parameter estimation method. e.g. "GCV.Cp", "GACV.Cp", "REML", "P-REML", "ML", "P-ML" (ML = maximum likelihood, REML = 约束性最大似然法 restricted maximum likelihood)
fit
: If this argument is TRUE then gam sets up the model and fits it, but if it is FALSE then the model is set up and an object G containing what would be required to fit is returned is returned.
Gamma
: multiplier to inflate the degrees of freedom in the GCV/UBRE/AIC score.
Select
: TRUE means adding an extra penalty to each term so that it can be penalized to zero.
s(x1, by=x2)
e.g. Loc = America, Doy = as.numeric(format(Date,format = "%j")), s(Doy,by = Loc)
|
|
plot
|
plot(mod_gam2, pages=1, residuals=T, shade=T, col='#FF8000')
vis.gam(mod_gam2, type = "response", plot.type = "contour")
vis.gam(mod_gam2, type = "response", plot.type = "persp", border=NA, phi=30, theta=30)
* If the graph looks noise, then the smooth function may be not suitable.
* http://stats.stackexchange.com/questions/14746/what-does-the-dashed-bounds-mean-when-plotting-a-contour-plot-with-r-gam
|
|
Q&A
|
Err: - not meaningful for factors in: Ops.factor(xx, shift[i])
A: smoothing a factor, which isn't supported (`smooth' means that f(x_1) must be close to f(x_2), e.g. if a factor has levels "brick", "sky" and "purple", how far
is it from "brick" to "purple"?)
Err: A term has fewer unique covariate combinations than specified maximum degrees of freedom / basis dimension is larger than number of unique covariates
A: for smoothing function, one independent variables portfolio cannot match to different response variable values.
Q: how to choose a proper smoothing spline (bs='?')
A: 1) use the default; 2) use a tensor product of "cr" smooths for bivariate smoothing, ie. te=(x,bs=”cr”)
|
|
Summary
|
Formula:
LN_Brutto ~ s(agecont, by = Sex) + factor(Sex) + te(Month, Age) +
s(Month, by = Sex)
Parametric coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 4.32057 0.01071 403.34 <2e-16 ***
factor(Sex)m 0.27708 0.01376 20.14 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Approximate significance of smooth terms:
edf Ref.df F p-value
s(agecont):Sexf 8.1611 8.7526 20.170 < 2e-16 ***
s(agecont):Sexm 6.6695 7.5523 32.689 < 2e-16 ***
te(Month,Age) 10.3651 12.7201 6.784 2.19e-12 ***
s(Month):Sexf 0.9701 0.9701 0.641 0.430
s(Month):Sexm 1.3750 1.6855 0.193 0.787
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Rank: 60/62
R-sq.(adj) = 0.781 Deviance explained = 78.7%
GCV = 0.048221 Scale est. = 0.046918 n = 1093
|


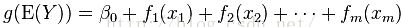
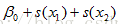
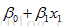
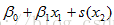
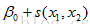 , allow for interactions between two predictor
, allow for interactions between two predictor