

Python-正则表达式

槐夏

正则表达式是记录文本规则的代码,用来匹配符合某些规则的字符串数据
1. 正则表达式的特点
正则表达式通用性强,能够适用于很多编程语言
2. re模块
python中使用正则表达式,可以导入re模块,使用re.match()函数根据正则表达式匹配数据
# 1. 导入re模块
import re
# 2. 根据正则表达式匹配数据操作
# 匹配对象 = re.match(正则表达式, 要匹配的字符串):根据正则表达式从头开始匹配字符串数据
match_obj = re.match('py', "python")
# 3. 使用group()方法提取匹配到的数据
result = match_obj.group()
print(result)运行结果:


3. 匹配单个字符
| 字符 | 说明 |
|---|---|
| . | 匹配任意1个字符(除了\n) |
| [] | 匹配[]中列举的字符 |
| \d | 匹配数字,即:0-9 |
| \D | 匹配非数字,即:不是数字 |
| \s | 匹配空白,即:空格、Tab键 |
| \S | 匹配非空白 |
| \w | 匹配非特殊字符,即:a-z,A-Z,0-9,_,汉字 |
| \W | 匹配特殊字符,即:非字母,非数字,非_,非汉字 |
import re
# 获取正则表达式匹配返回来的结果
def my_match(pattern, string):
match_obj = re.match(pattern, string)
if match_obj:
# 获取匹配的结果
result = match_obj.group()
print(result)
else:
print("匹配失败")
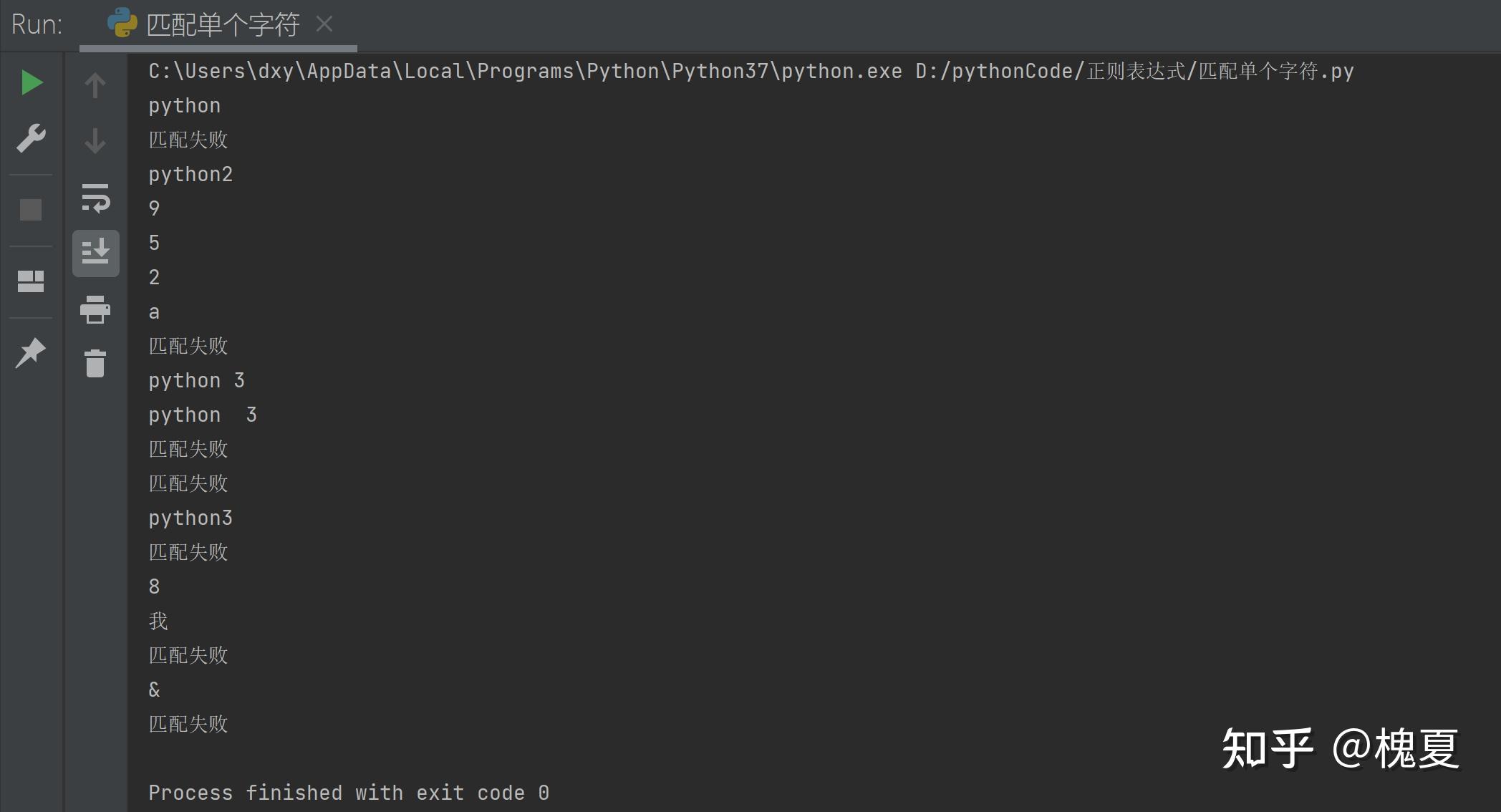
# 1. .:匹配任意一个字符,除了\n
my_match("p.thon", "python")
my_match("python.", "python\n")
# 2. []:匹配[]中列举的字符
my_match("python[1234]", "python2")
# 3. \d:匹配数字,0~9
# \d == [0-9] == [1234567890]
my_match("[1234567890]", "9")
my_match("[0-9]", "5")
my_match("\d", "2")
# 4. \D:匹配一个非数字字符
my_match("\D", "a")
my_match("\D", "2")
# 5. \s:匹配一个空白字符,空格或者tab键
# 要匹配的字符串有一个空格,匹配成功
my_match("python\s[1234]", "python 3")
# 要匹配的字符串有tab键,匹配成功
my_match("python\s[1234]", "python\t3")
# 要匹配的字符串没有空格,匹配失败
my_match("python\s[1234]", "python3")
# 要匹配的字符串有两个空格,匹配失败
my_match("python\s[1234]", "python 3")
# 6. \S:匹配一个非空白字符串
# 要匹配的字符串没有空格,匹配成功
my_match("pytho\S[1234]", "python3")
# 要匹配的字符串有空格,匹配失败
my_match("pytho\S[1234]", "pytho 3")
# 7. \w:匹配一个非特殊字符(a-z,A-Z,0-9,_,汉字)
my_match("[a-zA-Z0-9_]", "8")
my_match("\w", "我")
# 匹配特殊字符,失败
my_match("\w", "&")
# 8. \W:匹配一个特殊字符:非(a-z,A-Z,0-9,_,汉字)
# 匹配特殊字符
my_match("\W", "&")
# 匹配非特殊字符
my_match("\W", "我")运行结果:

4. 匹配多个字符
| 字符 | 说明 |
|---|---|
| * | 匹配前一个字符出现0次或者无限次,即可有可无 |
| + | 匹配前一个字符出现1次或者无限次,即至少有1次 |
| ? | 匹配前一个字符出现1次或者0次,即最多1次 |
| {m} | 匹配前一个字符出现m次 |
| {m,n} | 匹配前一个字符出现从m到n次 |
import
re
# 获取正则表达式返回来的结果
def my_match(pattern, string):
match_obhj = re.match(pattern, string)
if match_obhj:
result = match_obhj.group()
print(result)
else:
print("匹配失败")
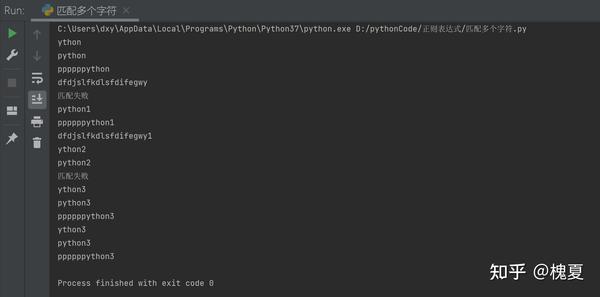
# 1. *:匹配前一个字符出现0次或者无限次,即可有可无
# 出现0次
my_match("p*ython", "ython")
# 出现1次
my_match("p*ython", "python")
# 出现多次
my_match("p*ython", "ppppppython")
# 任意字符出现无限次
my_match("d.*y", "dfdjslfkdlsfdifegwy")
# 2. +:匹配前一个字符出现1次或者无限次
# 出现0次
my_match("p+ython1", "ython1")
# 出现1次
my_match("p+ython1", "python1")
# 出现多次
my_match("p+ython1", "ppppppython1")
# 任意字符出现无限次
my_match("d.+y1", "dfdjslfkdlsfdifegwy1")
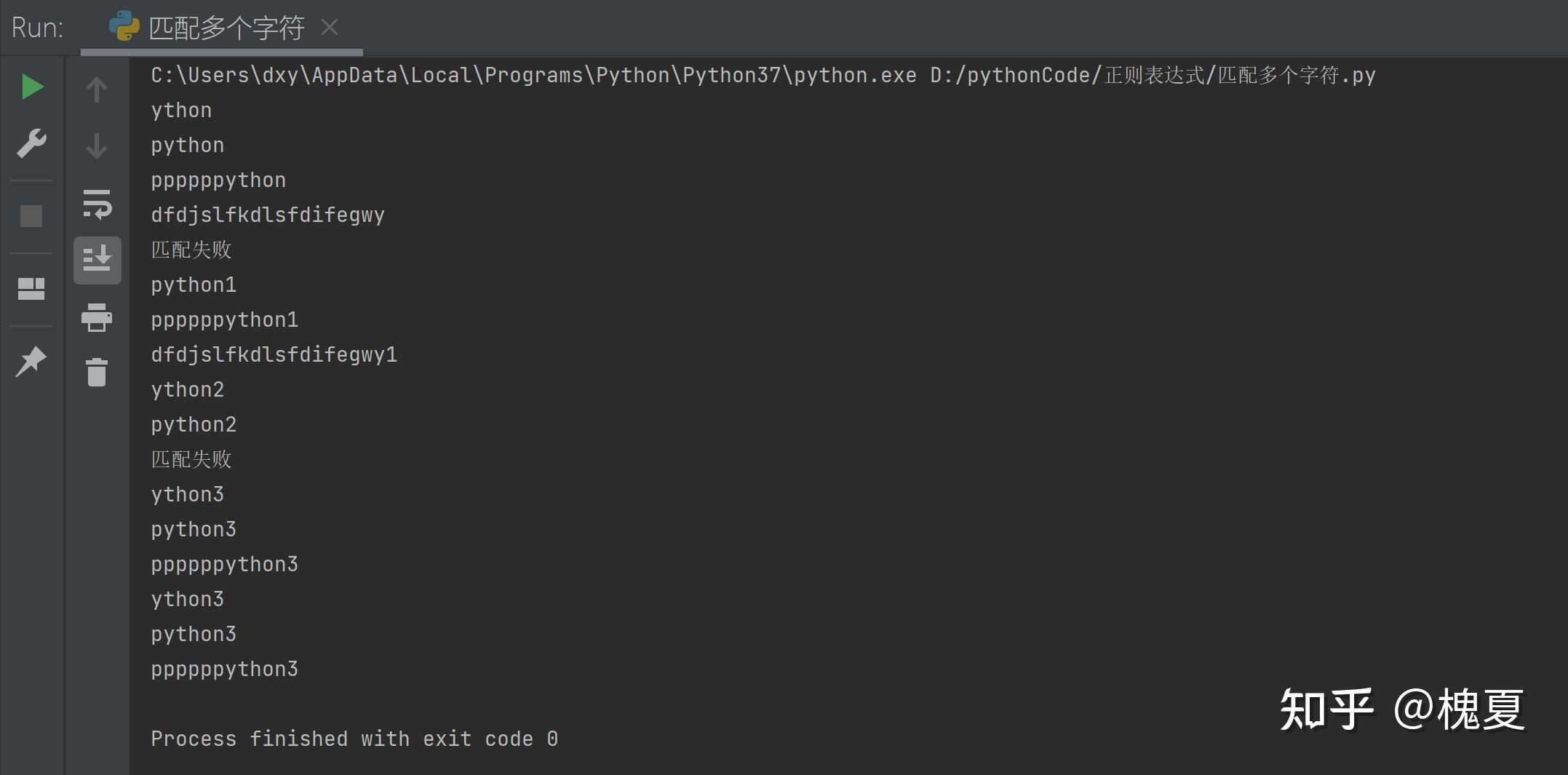
# 3. ?:匹配前一个字符出现0次或者1次,即最多出现1次
# 出现0次
my_match("p?ython2", "ython2")
# 出现1次
my_match("p?ython2", "python2")
# 出现多次
my_match("p?ython2", "ppppppython2")
# 4. {m}:匹配前一个字符出现m次
# 出现0次
my_match("p{0}ython3", "ython3")
# 出现1次
my_match("p{1}ython3", "python3")
# 出现指定次
my_match("p{6}ython3", "ppppppython3")
# 5. {m,n}:匹配前一个字符出现m到n次,n不指定的话就是:至少出现m次
# 出现0次
my_match("p{0,3}ython3", "ython3")
# 出现1次
my_match("p{0,2}ython3", "python3")
# 出现指定次
my_match("p{2,}ython3", "ppppppython3")运行结果:
5. 匹配开头和结尾
| 字符 | 说明 |
|---|---|
| ^ | 匹配字符串开头 |
| $ | 匹配字符串结尾 |
import re
# 获取正则表达式匹配返回来的结果
def my_match(pattern, string):
match_obj = re.match(pattern, string)
if match_obj:
# 获取匹配的结果
result = match_obj.group()
print(result)
else:
print("匹配失败")
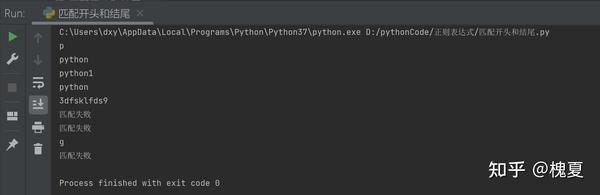
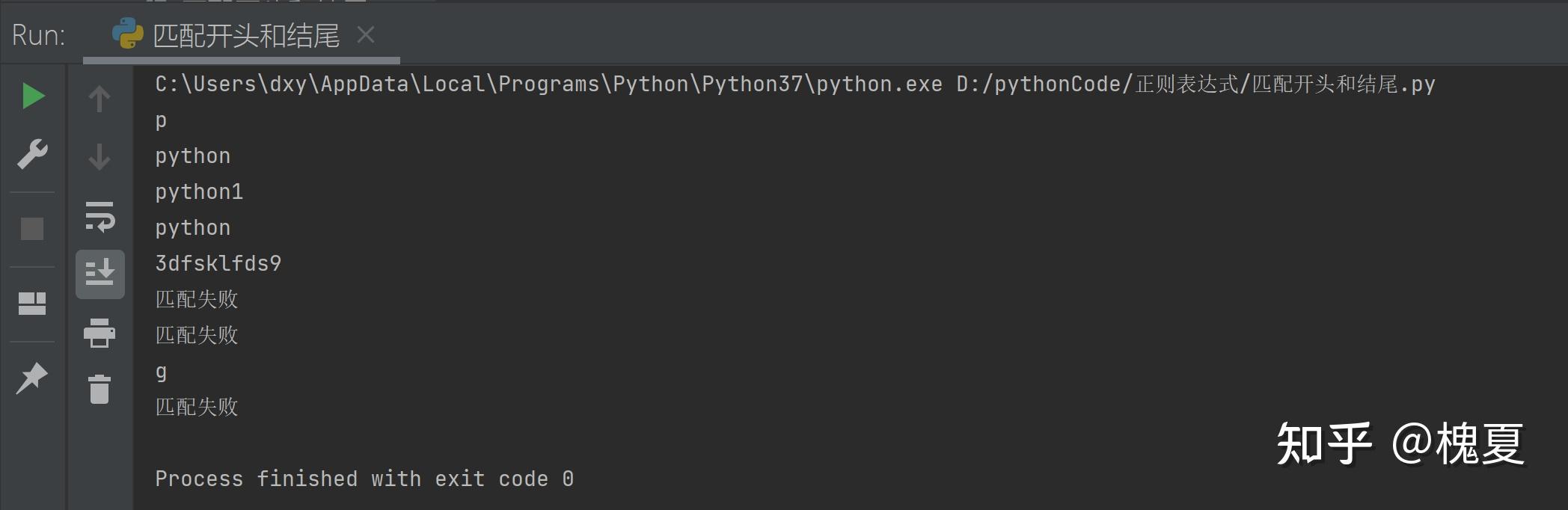
# 1. ^:匹配字符串的开头
my_match("^.", "python")
my_match("^.*", "python")
# 2. $:匹配字符串的结尾
my_match(".*\d$", "python1")
my_match(".*$", "python")
# 3. 开头和结尾都是数字
my_match("^\d.*\d$", "3dfsklfds9")
my_match("^\d.*\d$", "dfsklfds9")
my_match("^\d.*\d$", "3dfsklfds")
# 4. [^指定字符]:除了指定字符以外都匹配
my_match("[^abcd]", "g")
my_match("[^abcd]", "a")运行结果:
6. 匹配分组
| 字符 | 说明 |
|---|---|
| | | 匹配左右任意一个表达式 |
| (ab) | 将括号中字符作为一个分组 |
| \num | 引用分组num匹配到的字符串 |
| (?P<name>) | 分组起别名 |
| (?P=name) | 引用别名为name分组匹配到的字符串 |
- 分组:将括号中字符作为一个分组,出现一个小括就表示一个分组,分组是从1开始的,如果出现多个小括号,分组的顺序是从左到右依次排序
import re
# 城市列表
city_list = ['北京', '上海', '广州', '深圳']
for value in city_list:
# 根据每一个字符使用正则表达式进行匹配
# 1. |:匹配左右任意一个表达式
match_obj = re.match("上海|深圳", value)
if match_obj:
result = match_obj.group()
print("命中:", result)
else:
print("未命中:", value)
# 匹配163、126、qq邮箱
# 2. (ab):将括号中字符作为一个分组,出现一个小括就表示一个分组,分组是从1开始的,如果出现多个小括号,分组的顺序是从左到右依次排序
# 在一个整体数据里面想取一部分数据,可以使用分组
# \.:表示对正则表达式里面的.进行转义,变成一个普通的点,只能匹配.字符
match_obj = re.match("([a-zA-Z0-9_]{4,20})@(163|126|qq)\.com", "dxyan@qq.com")
if match_obj:
# 获取整个匹配的数据,如果使用分组数的话,默认是0
result = match_obj.group(0)
print(result)
print(match_obj.group(1))
print(match_obj.group(2))
else:
print("匹配失败")
# 匹配<html></html>
# 3. \num:引用分组num匹配到的字符串
match_obj1 = re.match("<([a-zA-Z1-6]+)>.*</\\1>", "<html>haha</html>")
match_obj2 = re.match("<([a-zA-Z1-6]+)>.*</\\1>", "<html>haha</h3>")
if match_obj1:
# 获取整个匹配的数据,如果使用分组数的话,默认是0
result = match_obj1.group()
print(result)
print(match_obj1.group(1))
else:
print("匹配失败")
if match_obj2:
# 获取整个匹配的数据,如果使用分组数的话,默认是0
result = match_obj2.group()
print(result)
print(match_obj2.group(1))
else:
print("匹配失败")
# 匹配<html><a href="https:www.baidu.com">百度</a></html>
# 4. (?P<name>):给分组起别名
# 5, (?P=name):引用别名为name分组匹配到的字符串
match_obj1 = re.match("<([a-zA-Z1-6]+)><([a-zA-Z1-6]+)>.*</\\2></\\1>", "<html><h1>百度</h1></html>")
match_obj2 = re.match("<(?P<name1>[a-zA-Z1-6]+)><(?P<name2>[a-zA-Z1-6]+)>.*</(?P=name2)></(?P=name1)>", "<html><h1>百度</h1></html>")
if match_obj1:
# 获取整个匹配的数据,如果使用分组数的话,默认是0
result = match_obj1.group()
print(result)
print(match_obj1.group(1))
print(match_obj1.group(2))
else:
print("匹配失败")