


Spark Sql入门实战(上)

一、Spark SQL概述
1、什么是Spark SQL
Spark SQL是Spark用来处理结构化数据的一个模块,它提供了2个编程抽象: DataFrame和DataSet ,并且作为分布式SQL查询引擎的作用。
我们已经学习了Hive,它是将Hive SQL转换成MapReduce然后提交到集群上执行,大大简化了编写MapReduc的程序的复杂性,由于MapReduce这种计算模型执行效率比较慢。所有Spark SQL的应运而生,它是将Spark SQL转换成RDD,然后提交到集群执行,执行效率非常快!
2、Spark SQL的特点
(1)易整合


(2)统一的数据访问方式


(3)兼容Hive


(4)标准的数据连接


3、什么是DataFrame
与RDD类似,DataFrame也是一个分布式数据容器。然而DataFrame更像传统数据库的二维表格,除了数据以外,还记录数据的结构信息,即schema。同时,与Hive类似,DataFrame也支持嵌套数据类型(struct、array和map)。从API易用性的角度上看,DataFrame API提供的是一套高层的关系操作,比函数式的RDD API要更加友好,门槛更低。
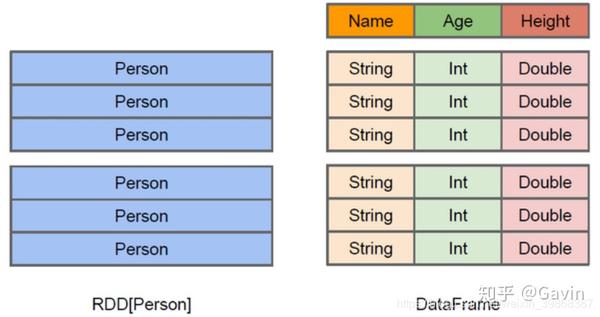
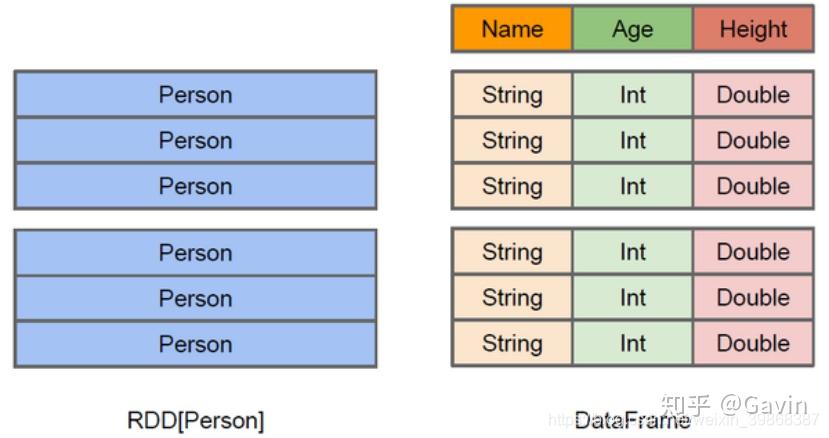
上图直观地体现了DataFrame和RDD的区别。左侧的RDD[Person]虽然以Person为类型参数,但Spark框架本身不了解Person类的内部结构。而右侧的DataFrame却提供了详细的结构信息,使得Spark SQL可以清楚地知道该数据集中包含哪些列,每列的名称和类型各是什么。DataFrame是为数据提供了Schema的视图。可以把它当做数据库中的一张表来对待,DataFrame也是懒执行的。性能上比RDD要高,主要原因:
优化的执行计划:查询计划通过Spark catalyst optimiser进行优化。
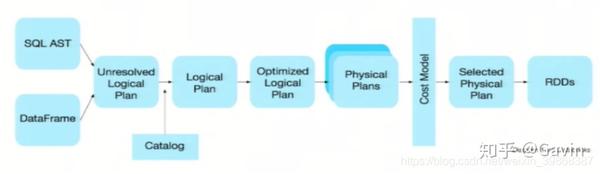
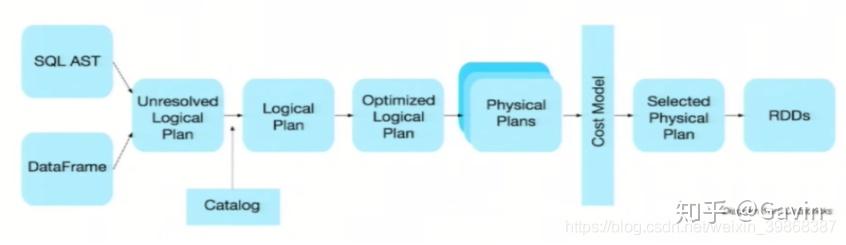
比如下面一个例子:


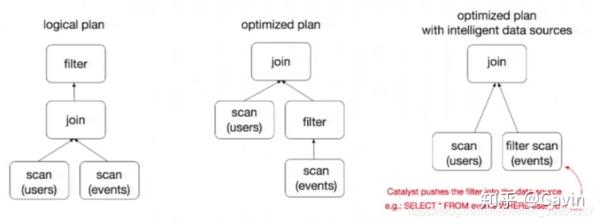
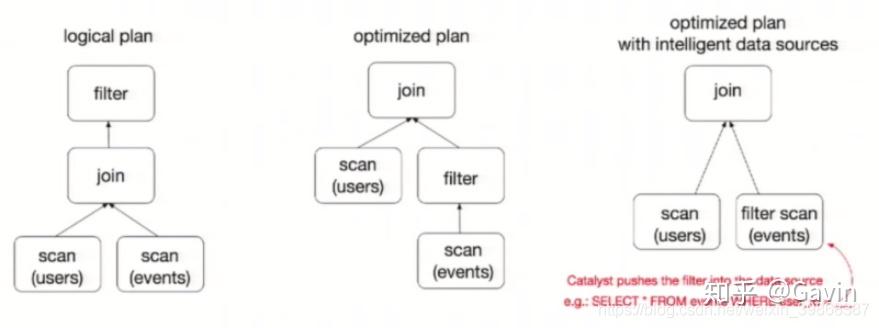
为了说明查询优化,我们来看上图展示的人口数据分析的示例。图中构造了两个DataFrame,将它们join之后又做了一次filter操作。如果原封不动地执行这个执行计划,最终的执行效率是不高的。因为join是一个代价较大的操作,也可能会产生一个较大的数据集。如果我们能将filter下推到 join下方,先对DataFrame进行过滤,再join过滤后的较小的结果集,便可以有效缩短执行时间。而Spark SQL的查询优化器正是这样做的。简而言之,逻辑查询计划优化就是一个利用基于关系代数的等价变换,将高成本的操作替换为低成本操作的过程。
4、什么是DataSet
(1)是Dataframe API的一个扩展,是Spark最新的数据抽象。
(2)用户友好的API风格,既具有类型安全检查也具有Dataframe的查询优化特性。
(3)Dataset支持编解码器,当需要访问非堆上的数据时可以避免反序列化整个对象,提高了效率。
(4)样例类被用来在Dataset中定义数据的结构信息,样例类中每个属性的名称直接映射到DataSet中的字段名称。
(5) Dataframe是Dataset的特列,DataFrame=Dataset[Row] ,所以可以通过as方法将Dataframe转换为Dataset。Row是一个类型,跟Car、Person这些的类型一样,所有的表结构信息我都用Row来表示。
(6)DataSet是强类型的。比如可以有Dataset[Car],Dataset[Person].
(7)DataFrame只是知道字段,但是不知道字段的类型,所以在执行这些操作的时候是没办法在编译的时候检查是否类型失败的,比如你可以对一个String进行减法操作,在执行的时候才报错,而DataSet不仅仅知道字段,而且知道字段类型,所以有更严格的错误检查。就跟JSON对象和类对象之间的类比。
二、SparkSQL编程
1、SparkSession新的起始点
在老的版本中,SparkSQL提供两种SQL查询起始点:一个叫SQLContext,用于Spark自己提供的SQL查询;一个叫HiveContext,用于连接Hive的查询。
SparkSession是Spark最新的SQL查询起始点,实质上是SQLContext和HiveContext的组合,所以在SQLContext和HiveContext上可用的API在SparkSession上同样是可以使用的。SparkSession内部封装了sparkContext,所以计算实际上是由sparkContext完成的。
2、DataFrame
创建
在Spark SQL中SparkSession是创建DataFrame和执行SQL的入口,创建DataFrame有三种方式:通过Spark的数据源进行创建;从一个存在的RDD进行转换;还可以从Hive Table进行查询返回。
从Spark数据源进行创建
(1)查看Spark数据源进行创建的文件格式
scala> spark.read.
csv format jdbc json load option options orc parquet schema table text textFile准备数据
json编辑内容:
[root@hadoop105 datas]# vim 2.json
{"name":"zhangsan","age":20}
{"name":"lisi","age":24}
{"name":"wangwu","age":27}(2)读取json文件创建DataFrame
//读取json文件创建DataFrame
scala> spark.read.json("file:///usr/local/hadoop/module/datas/2.json")
res24: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
//创建一个DataFrame
scala> val df=spark.read.json("file:///usr/local/hadoop/module/datas/2.json")
df: org.apache.spark.sql.DataFrame = [age: bigint, name: string](3)结果展示
scala> df.show
+---+--------+
|age| name|
+---+--------+
| 20|zhangsan|
| 24| lisi|
| 27| wangwu|
+---+--------+由于我们当前没有数据表,但我们可以这样执行:
//创建一张student表的视图(对DataFrame创建一个临时表)
scala> df.createTempView("student")
//即可直接查询student数据表(数据是通过SQL语句实现查询全表)
scala> spark.sql("select * from student").show
+---+--------+
|age| name|
+---+--------+
| 20|zhangsan|
| 24| lisi|
| 27| wangwu|
+---+--------+
//条件查询
scala> spark.sql("select age from student").show
+---+
|age|
+---+
| 20|
| 24|
| 27|
+---+
//查询年龄取平均值
scala> spark.sql("select avg(age) from student").show
+------------------+
| avg(age)|
+------------------+
|23.666666666666668|
+------------------+2.1、SQL风格语法(主要)
(1)创建一个会话注意事项
//创建一个会话sql
scala> spark.newSession.sql("select age from student").show报错信息:
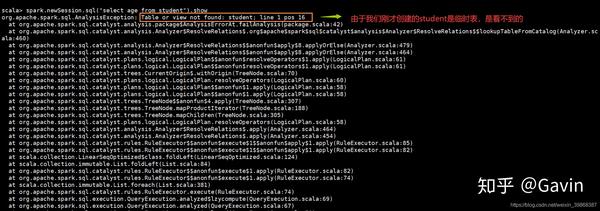
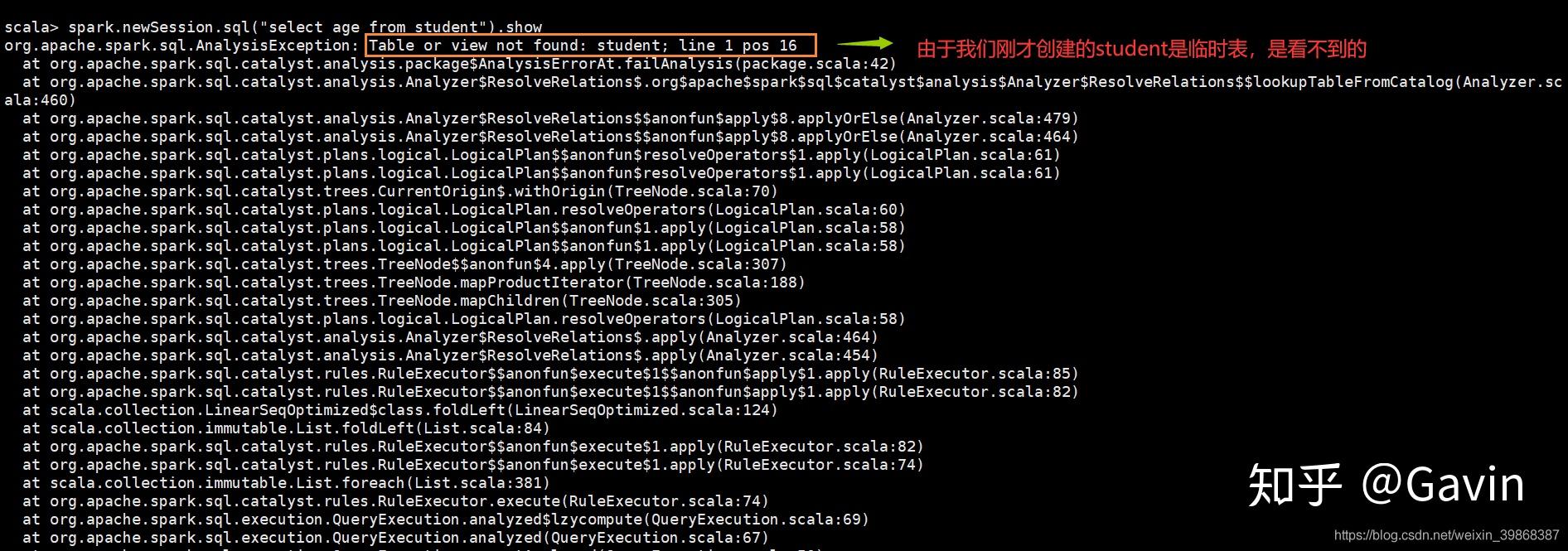
尝试再次执行:
//回车键查看
scala> df
res32: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
//Tab键查看
scala> df.create
createGlobalTempView createOrReplaceTempView createTempView
//对于DataFrame创建一个全局表
scala> df.createGlobalTempView("emp")
scala> spark.sql("select * from emp").show报错信息:
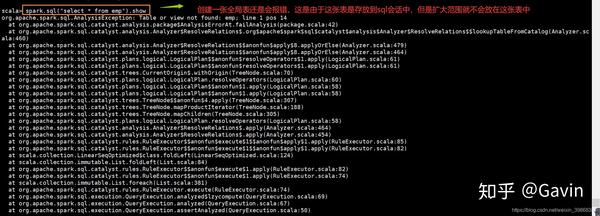
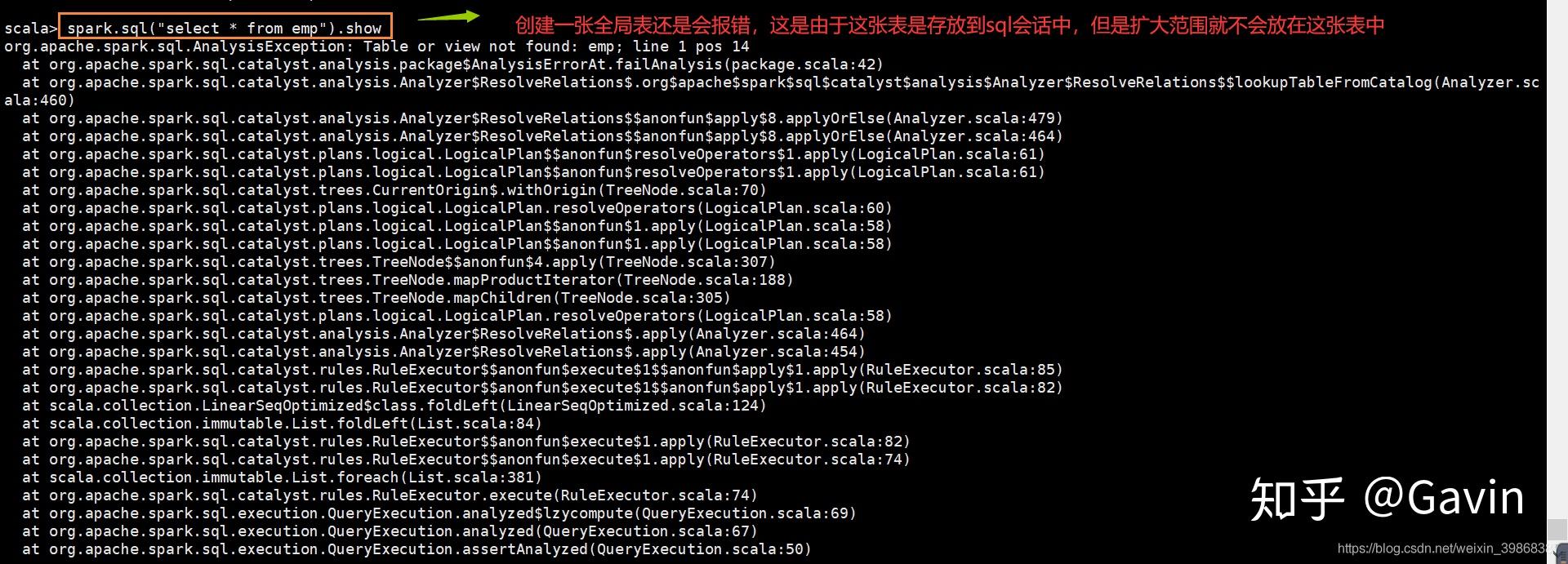
正确写法,执行如下:
scala> spark.sql("select * from global_temp.emp").show
+---+--------+
|age| name|
+---+--------+
| 20|zhangsan|
| 24| lisi|
| 27| wangwu|
+---+--------+
注意:
临时表是Session范围内的,Session退出后,表就失效了。如果想应用范围内有效,可以使用全局表。注意使用全局表时需要全路径访问,如:global_temp.emp
若遵守以上规则,我们尝试换另一种写法,照样可以获取:
scala
> spark.newSession.sql("select * from global_temp.emp").show
+---+--------+
|age| name|
+---+--------+
| 20|zhangsan|
| 24| lisi|
| 27| wangwu|
+---+--------+
2.2、 DSL风格语法(次要)
(1)查看DataFrame的Schema信息
//回车键
scala> df.printSchema
|-- age: long (nullable = true)
|-- name: string (nullable = true)(2)只查看”name”列数据
scala> df.select("name").show()
+--------+
| name|
+--------+
|zhangsan|
| lisi|
| wangwu|
+--------+(3)查看”name”列数据以及”age+1”数据
//只查看年龄
scala> df.select("age").show()
+---+
|age|
+---+
| 20|
| 24|
| 27|
+---+
//若查看年龄都加1,这样执行会报错
scala> df.select("age"+1).show()报错信息:
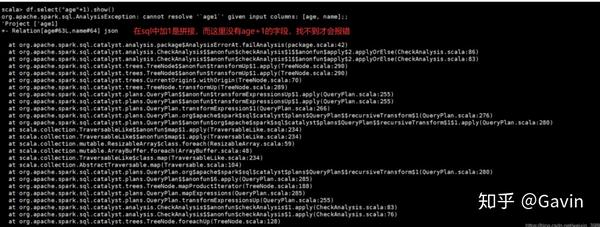
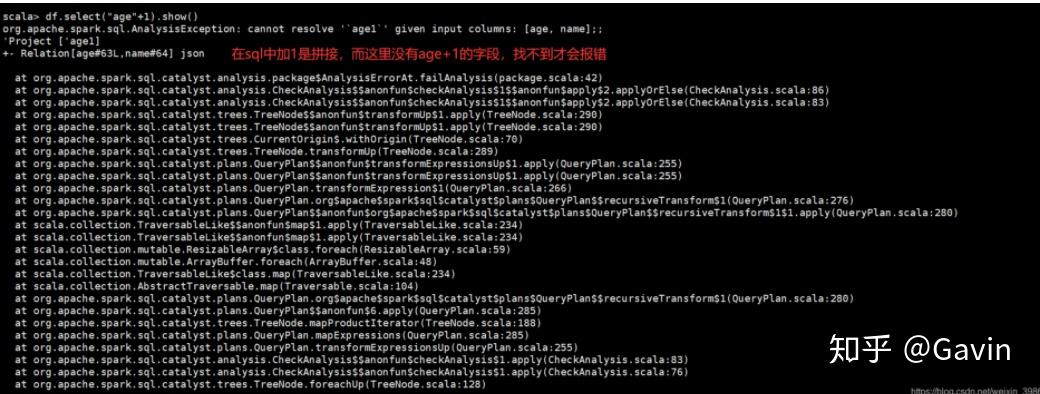
正确执行:
//需要添加“$”符号
scala> df.select($"age"+1).show()
+---------+
|(age + 1)|
+---------+
| 21|
| 25|
| 28|
+---------+(3)查看”age”大于”21”的数据
scala> df.filter($"age" > 21).show()
+---+------+
|age| name|
+---+------+
| 24| lisi|
| 27|wangwu|
+---+------+(4)按照”age”分组,查看数据条数
scala> df.groupBy("age").count().show()
+---+-----+
|age|count|
+---+-----+
| 27| 1|
| 20| 1|
| 24| 1|
+---+-----+
2.3、RDD转换为DateFrame
注意:如果需要RDD与DF或者DS之间操作,那么都需要引入 import spark.implicits._ 【spark不是包名,而是sparkSession对象的名称】
前置条件:导入隐式转换并创建一个RDD
通过手动确定转换
//导入隐式转换
scala> import spark.implicits._
import spark.implicits._
//创建RDD
scala> val rdd =sc.makeRDD(List(1,2,3,4))
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[98] at makeRDD at <console>:27
//创建DataFrame(结构)
scala> rdd.toDF("id")
res45: org.apache.spark.sql.DataFrame = [id: int]
//修改一下DataFrame
scala> val df= rdd.toDF("id")
df: org.apache.spark.sql.DataFrame = [id: int]
//主键(将普通数据增加结构化信息,有了含义就灵活查询sql)
scala> df.show
+---+
| id|
+---+
| 1|
| 2|
| 3|
| 4|
+---+案例:
//创建一个RDD
scala> val rdd = sc.makeRDD(List((1,"zhangsan",20),(2,"lisi",25),(3,"wangwu",28)))
rdd: org.apache.spark.rdd.RDD[(Int, String, Int)] = ParallelCollectionRDD[102] at makeRDD at <console>:27
//把刚才创建的指定一下结构(字段)
scala> rdd.toDF("id","name","age")
res47: org.apache.spark.sql.DataFrame = [id: int, name: string ... 1 more field]
scala> val df = rdd.toDF("id","name","age")
df: org.apache.spark.sql.DataFrame = [id: int, name: string ... 1 more field]
scala> df.show
+---+--------+---+
| id| name|age|
+---+--------+---+
| 1|zhangsan| 20|
| 2| lisi| 25|
| 3| wangwu| 28|
+---+--------+---+如这张图:
RDD可以转换DataFrame
2.4、 DataSet
通过反射确定(需要用到样例类)
//创建一个样例类
scala> case class People(name:String, age:Int)
defined class People
//创建一个RDD
scala> val rdd = sc.makeRDD(List(("zhangsan",23),("lisi",27),("wangwu",29)))
rdd: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[106] at makeRDD at <console>:27
//根据样例类将RDD转换为对象类型
scala> val people =rdd.map(t => {People(t._1,t._2)} )
people: org.apache.spark.rdd.RDD[People] = MapPartitionsRDD[107] at map at <console>:31
//根据样例类将RDD转换为DataFrame
scala> val df = people.toDF
df: org.apache.spark.sql.DataFrame = [name: string, age: int]
scala> df.show
+--------+---+
| name|age|
+--------+---+
|zhangsan| 23|
| lisi| 27|
| wangwu| 29|
+--------+---+
2.5、DateFrame转换为RDD
把有结构的数据转化为无结构
直接调用rdd即可
//将DataFrame转换为RDD
scala> df.rdd
res50: org.apache.spark.rdd.RDD[org.apache.spark.sql.Row] = MapPartitionsRDD[114] at rdd at <console>:36
//打印RDD
scala> df.collect
res51: Array[org.apache.spark.sql.Row] = Array([zhangsan,23], [lisi,27], [wangwu,29])
2.6、DataSet
Dataset是具有强类型的数据集合,需要提供对应的类型信息。
//创建一个样例类
scala> case class Person(name: String, age: Long)
defined class Person
//创建DataSet
scala> val caseClassDS = Seq(Person("Andy", 32)).toDS()
caseClassDS: org.apache.spark.sql.Dataset[Person] = [name: string, age: bigint]
scala> caseClassDS.show
+----+---+
|name|age|
+----+---+
|Andy| 32|
+----+---+
//DataSet
scala> caseClassDS.createTempView("xxx")
scala> spark.sql("select * from xxx").show
+----+---+
|name|age|
+----+---+
|Andy| 32|
+----+---+DataFrame与Dataset结构不同
2.7、RDD转换为DataSet
SparkSQL能够自动将包含有case类的RDD转换成DataFrame,case类定义了table的结构,case类属性通过反射变成了表的列名。
//查看是否有创建过rdd
scala> rdd
res58: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[106] at makeRDD at <console>:27
//打印rdd信息
scala> rdd.collect
res59: Array[(String, Int)] = Array((zhangsan,23), (lisi,27), (wangwu,29))
// 创建一个样例类
scala> case class Person(name: String, age: Long)
defined class Person
//将RDD转化为DataSet
scala> val mapRDD =rdd.map(t => { Person(t._1,t._2) } )
mapRDD: org.apache.spark.rdd.RDD[Person] = MapPartitionsRDD[119] at map at <console>:31
scala> mapRDD.toDS
res60: org.apache.spark.sql.Dataset[Person] = [name: string, age: bigint]
//打印还是有数据
scala> mapRDD.toDS.show
+--------+---+
| name|age|
+--------+---+
|zhangsan| 23|
| lisi| 27|
| wangwu| 29|
+--------+---+2.8、DataSet转换为RDD
调用rdd方法即可。
//查看是Dataset类型
scala> val ds = mapRDD.toDS
ds: org.apache.spark.sql.Dataset[Person] = [name: string, age: bigint]
//调用rdd方法,就转化为rdd
scala> ds.rdd
res62: org.apache.spark.rdd.RDD[Person] = MapPartitionsRDD[124] at rdd at <console>:36
2.9、DataFrame与DataSet的互操作
DataFrame转换为DataSet:
//打印rdd的数据信息
scala> rdd.collect
res63: Array[(String, Int)] = Array((zhangsan,23), (lisi,27), (wangwu,29))
//把RDD转化为DataFrame
scala> val df = rdd.toDF("name","age")
df: org.apache.spark.sql.DataFrame = [name: string, age: int]
//DataFrame转化为Dataset
scala> df.as[Person]
res64: org.apache.spark.sql.Dataset[Person] = [name: string, age: int]Dataset转换为DataFrame
//查看是Dataset类型
scala> val ds =df.as[Person]
ds: org.apache.spark.sql.Dataset[Person] = [name: string, age: int]
//Dataset转换为DataFrame类型
scala> df.toDF
res66: org.apache.spark.sql.DataFrame = [name: string, age: int]这种方法就是在给出每一列的类型后,使用as方法,转成Dataset,这在数据类型是DataFrame又需要针对各个字段处理时极为方便。在使用一些特殊的操作时,一定要加上 import spark.implicits._ 不然toDF、toDS无法使用。
2.10、RDD、DataFrame、DataSet
在SparkSQL中Spark为我们提供了两个新的抽象,分别是DataFrame和DataSet。他们和RDD有什么区别呢?首先从版本的产生上来看:
RDD (Spark1.0) —> Dataframe(Spark1.3) —> Dataset(Spark1.6)
如果同样的数据都给到这三个数据结构,他们分别计算之后,都会给出相同的结果。不同是的他们的执行效率和执行方式。
在后期的Spark版本中,DataSet会逐步取代RDD和DataFrame成为唯一的API接口
2.11、三者的共性
1、RDD、DataFrame、Dataset全都是spark平台下的分布式弹性数据集,为处理超大型数据提供便利
2、三者都有惰性机制,在进行创建、转换,如map方法时,不会立即执行,只有在遇到Action如foreach时,三者才会开始遍历运算。
3、三者都会根据spark的内存情况自动缓存运算,这样即使数据量很大,也不用担心会内存溢出。
4、三者都有partition的概念
5、三者有许多共同的函数,如filter,排序等
6、在对DataFrame和Dataset进行操作许多操作都需要这个包进行支持import spark.implicits._
7、DataFrame和Dataset均可使用模式匹配获取各个字段的值和类型
DataFrame:
testDF.map{
case Row(col1:String,col2:Int)=>
println(col1);println(col2)
case _=>
}Dataset:
case class Coltest(col1:String,col2:Int)extends Serializable //定义字段名和类型
testDS.map{
case Coltest(col1:String,col2:Int)=>
println(col1);println(col2)
case _=>
}
2.12、三者的区别
1、RDD:
(1)RDD一般和spark mlib同时使用
(2)RDD不支持sparksql操作
2、 DataFrame:
(1)与RDD和Dataset不同,DataFrame每一行的类型固定为Row,每一列的值没法直接访问,只有通过解析才能获取各个字段的值,如:
testDF.foreach{
line =>
val col1=line.getAs[String]("col1")
val col2=line.getAs[String]("col2")
}(2)DataFrame与Dataset一般不与spark mlib同时使用
(3)DataFrame与Dataset均支持sparksql的操作,比如select,groupby之类,还能注册临时表/视窗,进行sql语句操作,如:
(4)DataFrame与Dataset支持一些特别方便的保存方式,比如保存成csv,可以带上表头,这样每一列的字段名一目了然
//保存
val saveoptions = Map("header" -> "true", "delimiter" -> "\t", "path" -> "hdfs://hadoop105:9000/test")
datawDF.write.format("com.atguigu.spark.csv").mode(SaveMode.Overwrite).options(saveoptions).save()
val options = Map("header" -> "true", "delimiter" -> "\t", "path" -> "hdfs://hadoop105:9000/test")
val datarDF= spark.read.options(options).format("com.atguigu.spark.csv").load()利用这样的保存方式,可以方便的获得字段名和列的对应,而且分隔符(delimiter)可以自由指定。
3、 Dataset:
(1)Dataset和DataFrame拥有完全相同的成员函数,区别只是每一行的数据类型不同。
(2)DataFrame也可以叫Dataset[Row],每一行的类型是Row,不解析,每一行究竟有哪些字段,各个字段又是什么类型都无从得知,只能用上面提到的getAS方法或者共性中的第七条提到的模式匹配拿出特定字段。而Dataset中,每一行是什么类型是不一定的,在自定义了case class之后可以很自由的获得每一行的信息
case class Coltest(col1:String,col2:Int)extends Serializable //定义字段名和类型
("a", 1)
("b", 1)
("a", 1)
val test: Dataset[Coltest]=rdd.map{line=>
Coltest(line._1,line._2)