01 前言
1.1 想要说
这篇博客,其实我想了很久要不要写,因为关于如何去预处理FY4A产品我已经花了很久的时间去收集和整理资料,花费的时间和精力其实不少。这方面数据的处理教程本来就少(包括我自己去搜集资料都是困难重重),我自己去处理产品也有受益于其它博客的影响。还有很多想说,暂且憋着吧。
另外,由于博客参考了部分其它博客和资料,时间跨度有点长,若有遗漏很抱歉。
1.2 Requirements
很抱歉我并没有放到Github上,因为时间和精力,所以需要大家自行安装以下模块,版本仅供参考,若你进行处理出现问题,请查看是否是因为版本更新问题所致.
numpy 1.23.5
h5py 3.9.0
gdal 3.3.3
scipy 1.8.1
猜测gdal比较难以安装, 因为它因为一些原因被放到osgeo模块,如果实在难以安装,可以尝试直接下载.whl文件进行安装,这里不再解释,自行搜索。若无法安装,也可以使用rasterio等模块,人不能在一棵树上吊死,但是你需要付出代价 ==> 修改部分代码。
1.3 程序适用数据集
你的数据集或许也是FY4A L1产品,但是需要注意,FY4A有很多产品,你需要注意自己的产品是否可以进行当前处理,如果不能,请查阅其它方法,本博客仅供参考。
DISK(全圆盘)文件示例
FY4A-_AGRI–_N_DISK_1047E_L1-_FDI-_MULT_NOM_20200601000000_20200601001459_4000M_V0001.HDF
形如AGRI*DISK*FDI*MULT*NOM*4000M*.HDF
解释如下:




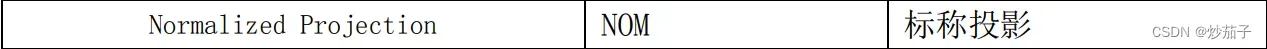

其中,全圆盘很重要,如果你的文件非DISK,那么你需要考虑当前程序是否适用这些方法;另外是MULT多通道,对于我的文件,一共有14个通道,形如下:
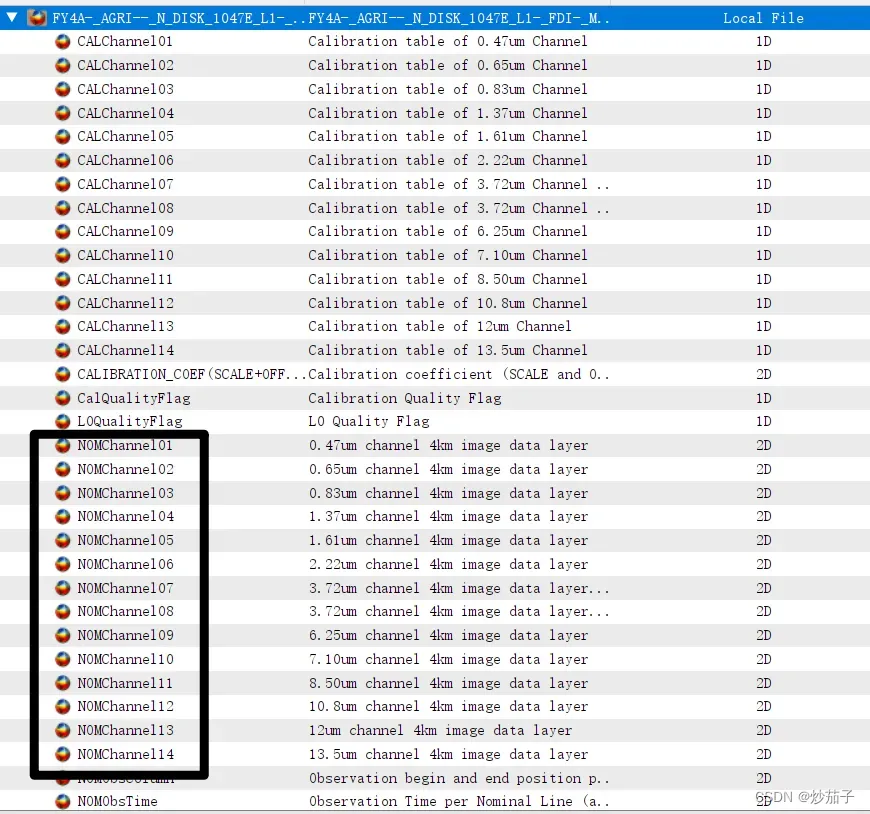
若你的文件不存在多个波段,你需要了解你的文件属性,或许它并非一级产品;
最后,当前程序仅仅适用于4000M分辨率的产品,若你的产品非4000M产品,你可参考本程序,但是在关键代码中我将提醒你替换关键参数(参数从官方文档中查找)。
REGC(中国区域)文件示例
FY4A-_AGRI–_N_REGC_1047E_L1-_FDI-_MULT_NOM_20200601003000_20200601003417_4000M_V0001.HDF
形如:*AGRI*REGC*FDI*MULT*NOM*4000M*.HDF
对于DISK的GLT校正,需要使用到官方地理对照表;对于REGC的GLT校正,需要使用到官方的*GEO*.HDF定位配准文件.(后续会详细说明,请勿用担心)
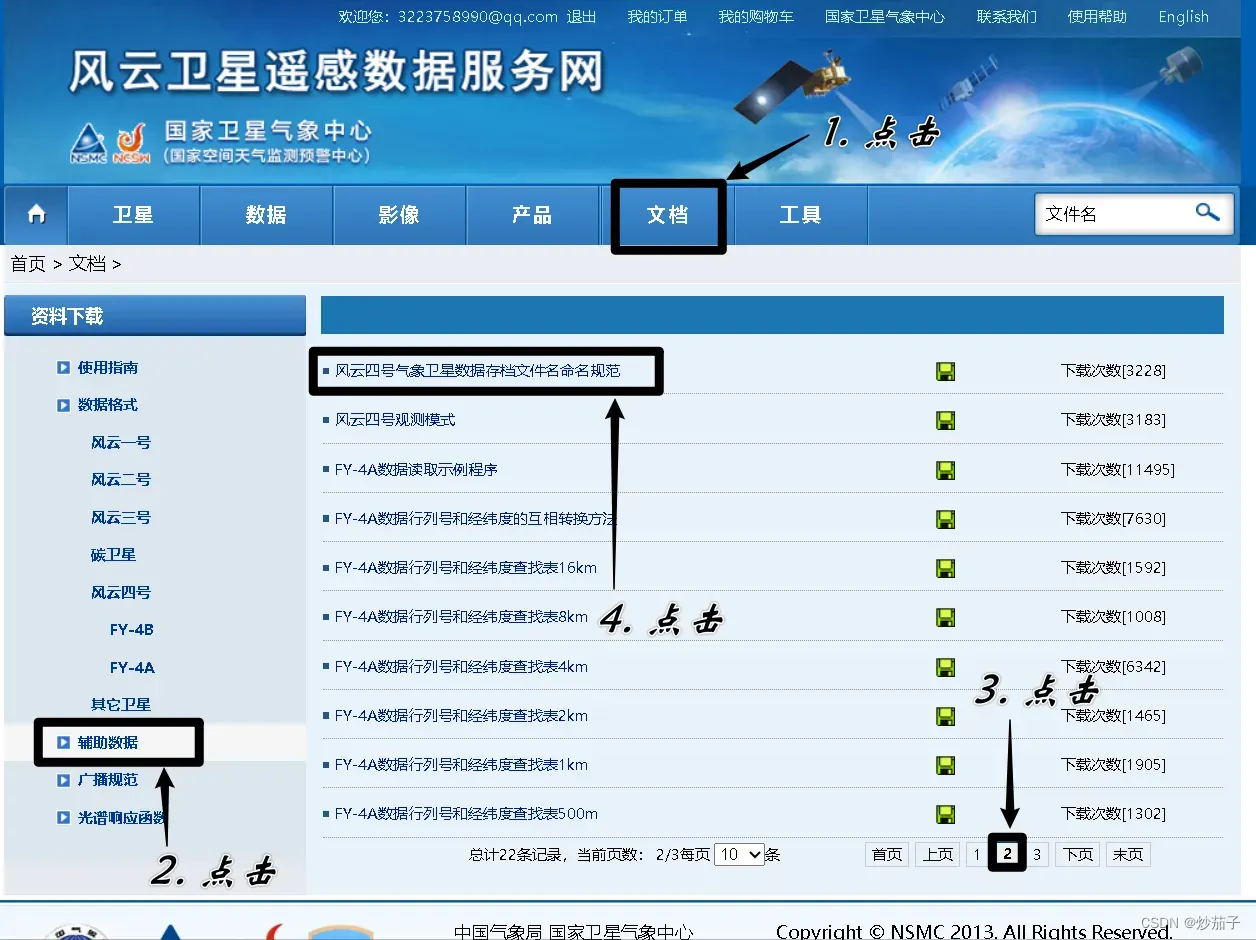
关于FY4A数据集的下载请参考官方文档: 风云四号气象卫星数据存档文件名命名规范_20170509.pdf
如打不开,请参照如下步骤:
02 函数说明
在这些自定义函数上我会参杂一些官方文档等供大家理解;函数内可能会调用其它函数,为了确保程序正常运行,请将理解所有函数尽管有时候它很简单。另外,我并没有把函数进行提炼写成类,因为我认为这会增加阅读的困难,不方便大家直观的理解其中的原理。
2.1 读取HDF5文件某一数据集
# 读取HDF5文件数据集
def h5_data_get(hdf_path, dataset_name):
读取HDF5文件中的数据集
:param hdf_path: HDF5文件的路径
:param dataset_name: HDF5文件中数据集的名称
:return: 数据集
with h5py.File(hdf_path, 'r') as f:
dataset = f[dataset_name][:]
return dataset
对于数据集名称,你需要通过HDFExp,Panoply等软件查看会更为方便,如下:

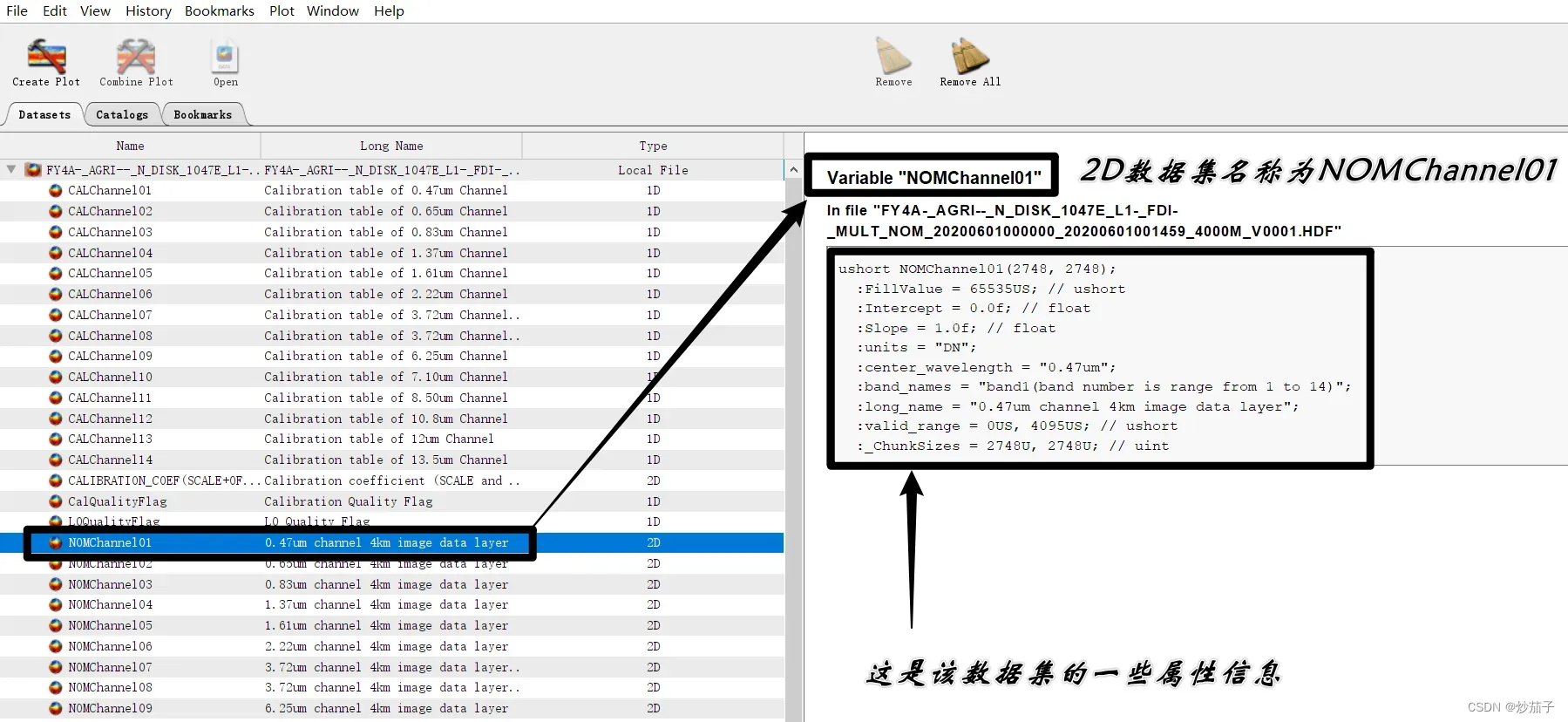
当然,你也可以通过h5py模块进行查看,这里不再详细说明。
2.2 读取HDF5文件数据集属性
# 读取HDF5文件数据集属性
def h5_attr_get(hdf_path, dataset_name, attr_name):
获取HDF5文件数据集的属性
:param hdf_path: HDF5文件的路径
:param dataset_name: HDF5文件中数据集的名称
:param attr_name: HDF5文件中数据集属性的名称
:return: 数据集属性
with h5py.File(hdf_path, 'r') as f:
attr = f[dataset_name].attrs[attr_name]
return attr
2.3 对FY4A数据集进行辐射定标
# 对FY4A数据集进行辐射定标
def fy4a_calibration(hdf_path, nom_channel_name, cal_channel_name):
获取FY4A数据集并对其进行辐射定标
:param hdf_path: HDF5文件的路径
:param nom_channel_name: 待定标的数据集名称
:param cal_channel_name: 用于定标的数据集名称
:return: 辐射定标后的数据集
# 读取数据集
nom_channel = h5_data_get(hdf_path, nom_channel_name)
cal_channel = h5_data_get(hdf_path, cal_channel_name)
# 读取数据集属性
nom_min, nom_max = h5_attr_get(hdf_path, nom_channel_name, 'valid_range')
cal_min, cal_max = h5_attr_get(hdf_path, cal_channel_name, 'valid_range')
nom_fill_value = h5_attr_get(hdf_path, nom_channel_name, 'FillValue')[0]
cal_fill_value = h5_attr_get(hdf_path, cal_channel_name, 'FillValue')[0]
# 数据集掩码和填充值预准备
nom_mask = (nom_channel > nom_min) & (nom_channel < nom_max) & (nom_channel != nom_fill_value)
cal_mask = (cal_channel > cal_min) | (cal_channel < cal_max)
cal_channel[cal_channel == cal_fill_value] = int(cal_min - 10)
# 辐射定标
target_channel = np.zeros_like(nom_channel, dtype=np.float32)
target_channel[nom_mask] = cal_channel[cal_mask][nom_channel[nom_mask]]
# 无效值处理(包括不在范围及填充值)
target_channel[~nom_mask] = np.nan
target_channel[target_channel == int(cal_min - 10)] = np.nan
return target_channel
我认为有必要对这一段代码进行解释方便大家的理解。
首先请让我说明常规的辐射定标:

对于Landsat部分系列有如下公式:

那么对于FY4A L1数据集,它是如何进行辐射定标的呢?
首先,他主要给定两种数据集,其一是波段影像:
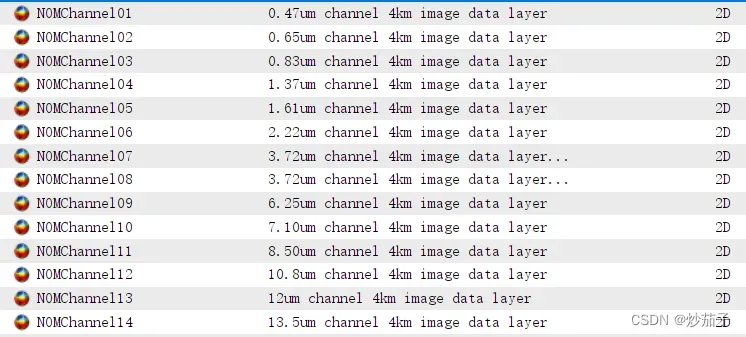
以及对应各个波段的辐射定标文件(每一个文件均为一维,类似列表):
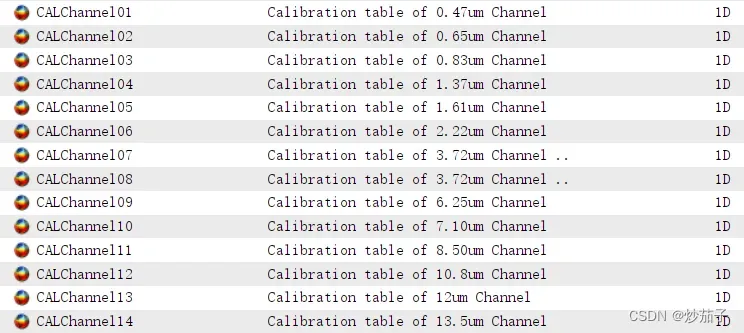
他们的关系是:由于NOMChannel中DN值为整数,因此将NOMChannel中DN值作为CALChannel的索引值,通过索引值在CALChannel可查找到该DN值对应的辐射定标之后的值。
因此实际上辐射定标后的值已经在CALChannel已经计算出来,需要自行查找。
当然,我的程序中进行了很多填充值和有效值范围的限定,这看起来并不清晰,对于为什么最后进行np.nan的赋值是因为原始的DN值为整数,而nan为浮点数因此需要预先创建mask掩码。
当然,如果你的文件存在辐射定标的参数数据集,如下:
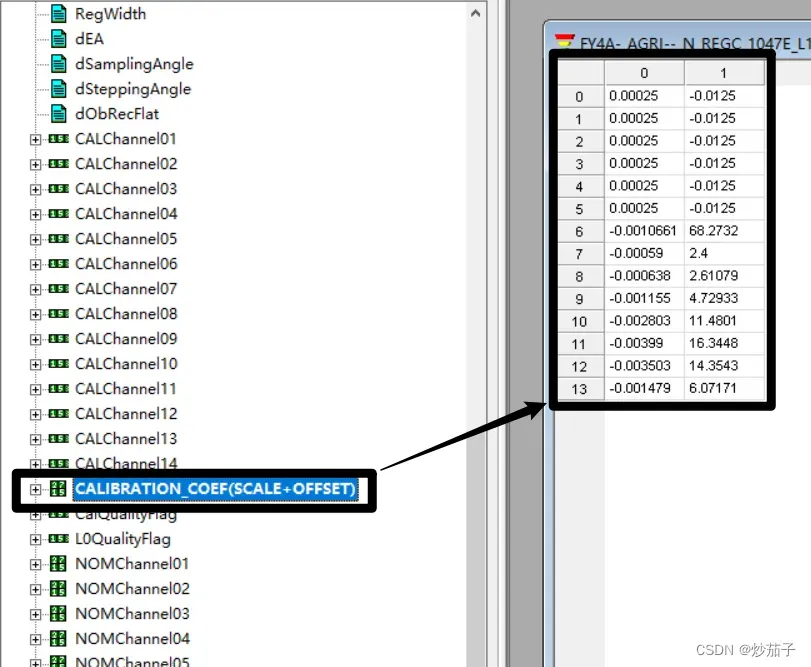
第0列为前文的Gain增益系数,第1列为偏置Offset;不同的行代表不同的波段,第0行通常代表NOMChannel01数据集。
为什么在一个HDF5文件中存在两种辐射定标的方法呢?于是我尝试通过两种方法(CALchannel和CALIBRATION_COEF(SCALE+OFFSET))去对同一数据集进行辐射定标,对于辐射定标后的数据集进行相关系数的计算以及目视查看,发现相关系数达到0.9999987,目视查看发现二者完全一致。因此认为两种方法没有任何区别,可能在早期的产品并没有提供CALIBRATION_COEF(SCALE+OFFSET)数据集,因为我在早前的博客中查找CALChannel的解释但是似乎没有关于CALIBRATION_COEF(SCALE+OFFSET)的说明。
由于基于CALIBRATION_COEF(SCALE+OFFSET)的辐射定标较为简单,代码我也没有保存,因此这里就不贴了,需要注意辐射定标时顺便考虑填充值和有效值范围。
2.4 基于官方地理对照表获取经纬度数据(仅适用DISK)
# 读取地理对照表(.raw, FY4A)
def read_glt(raw_path, shape):
该函数用于读取地理对照表
:param raw_path: 地理查找表的路径
:param shape: 地理查找表的形状
:return: 二维数组(lon, lat)
# 读取二进制数据,将其转换为两个2D数组(经度和纬度)
with open(raw_path, 'rb') as f:
raw_data = np.fromfile(f, dtype=np.float64) # 读取二进制数据, '<f8'表示小端模式,8字节浮点数
raw_lat = raw_data[::2].reshape(shape)
raw_lon = raw_data[1::2].reshape(shape)
raw_lat[(raw_lat < -90.0) | (raw_lat > 90.0)] = np.nan
raw_lon[(raw_lon < -180.0) | (raw_lon > 180.0)] = np.nan
官方文档中的说明:文件从北向南按行(从西到东)填写,每个网格对应 16 字节,前8字节为经度值,后 8 字节为纬度值,double 类型,高字节在前
-----------------------------------------------------------------------------------------------------------------
| 通过查看输出的lon, lat发现, lon的范围为[-90, 90], lat的范围为[-180, 180];
| 通过读取二进制流时,如果以高字节在前(Big-Endian/小端模式)的方式(dtype=‘<f8’, , <表示小, 若填入np.float64等价于'<f8'
| 即默认是小端模式)读取数据时,会出现错误的结果;
-----------------------------------------------------------------------------------------------------------------
综上所述, 官方文档的说明存在错误: 应该为前8字节为纬度值,后 8 字节为经度值,double 类型,低字节在前;
参考: https://blog.csdn.net/modabao/article/details/83834580
return raw_lon, raw_lat
在了解上方的代码前,我们需要了解地理查找表,在早期的博客中,我曾经写过:
ENVI: 如何创建GLT文件并基于GLT对图像进行几何校正?
但是其实那时候我还是不太能理解地理查找表(地理对照表,或者它就是GLT文件因为地理位置查找表文件 (Geographic Lookup Table, GLT) )的含义。
我所下载的地理对照表文件(.raw后缀)为:
FullMask_Grid_4000.raw
现在我们来查看官方文档对于地理对照表的原理诠释:

但是需要注意是,官方文档存在勘误(代码中也有详细说明)。这是在经过反复确认得到的结论,当然也参考加以确认:
Python3.FY-4A标称(NOM)数据提取
正确说明应当是:每一个像元值(网格值)共16个字节,前8字节是纬度值,后8字节是经度值,double类型,低字节在前(np默认即是小端模式即低字节在前);
但是4KM影像的行列数是没有问题的,为2748×2748.
至此,我基本理解地理对照表中含有什么信息了,我之前一直认为地理对照表含有经纬度、投影等诸多信息,现在看来仅仅只有经纬度信息。上述代码就是将地理对照表转换为两个2748×748的数据集包括经度和纬度。
关于地理对照表的下载:FullMask_Grid_4000.raw
2.5 依据行列号计算经纬度数据(仅适用DISK)
需要说明的是,依据行列号计算经纬度数据与前文基于官方地理对照表获取经纬度数据 功能都是一致的,都是要获取经纬度数据集。
这里仅仅是从更底层去探讨经纬度的获取(当然如果你的数据集已经有经纬度数据集那么这些处理对于你来说都是无需的)。
参考:FY-4A建立中国区域图像行列号转经纬度的经纬度查找表进行几何校正
但是上文是关于REGC(中国区域) 而且是基于*GEO*HDF获取中国区域的行列号数据集。并不适用DISK,因此我尝试以类似的思路去进行DISK的经纬度数据集计算。经过和前文的基于官方地理对照表获取经纬度数据相比,二者的相关性系数在0.95上下波动,所以还是不错的。
def get_lon_lat(dataset):
FY4A数据集经纬度计算(基于FY4A数据格式说明书的公式)
:param dataset: FY4A数据集
:return: 经纬度
# 行列号 ==> 经纬度, 公式由FY4A数据格式说明书给出
# 获取数据集的行列号
rows, cols = dataset.shape
# 生成行列号矩阵
col_mesh, row_mesh = np.meshgrid(np.arange(cols), np.arange(rows))
# 基本参数(均只用于FY4A 4000m分辨率, 其它分辨率需要依据官方说明修改参数)
ea = 6378.137 # 地球长半轴, 单位km
eb = 6356.7523 # 地球短半轴, 单位km
h = 42164 # 卫星高度, 单位km, 即地心到卫星质心的距离
lon0 = 104.7 # 投影中心经度, 单位度, 也即卫星星下点所在的经度
coff = 1373.5 # 列偏移
cfac = 10233137 # 列比例因子
loff = 1373.5 # 行偏移
lfac = 10233137 # 行比例因子
# step1. 求x, y
x = (pi * (col_mesh - coff)) / (180 * (2 ** (-16)) * cfac)
y = (pi * (row_mesh - loff)) / (180 * (2 ** (-16)) * lfac)
# step2. 求sd, sn, s1, s2, s4, sxy
sd = sqrt(
power(h * cos(x) * cos(y), 2) - (power(cos(y), 2) + power(ea / eb, 2) * power(sin(y), 2)) * (h ** 2 - ea ** 2)
sn = (h * cos(x) * cos(y) - sd) / (power(cos(y), 2) + power(ea / eb, 2) * power(sin(y), 2))
s1 = h - sn * cos(x) * cos(y)
s2 = sn * sin(x) * cos(y)
s3 = -sn * sin(y)
sxy = sqrt(power(s1, 2) + power(s2, 2))
# step3. 求lon, lat
lon = lon0 + arctan(s2 / s1) * 180 / pi
lat = arctan(power(ea / eb, 2) * s3 / sxy) * 180 / pi
return lon, lat
(若上述参数与官方文档存在不符 ,请一定告知我)
行列号数据集我并非如REGC数据集获取*GEO*HDF中的行列号数据集,而是直接由波段NOMChannel的行列数生成行列号数据集,这是由于官方文档说明行列转换经纬度说明书的附录说明4KM范围的行列号范围为0~2747,这与DISK数据集的行列数2748完全匹配,因此我尝试如此操作具有一定的依据,事实上两种方法的区别差异比较小,也有一定的说服力。这是二者生成的图像对比查看:


上述代码仅适用于4KM分辨率。关于参数的选择和计算公式(由行列计算经纬度)请查阅官方文档:
这贴出当前部分参数说明:


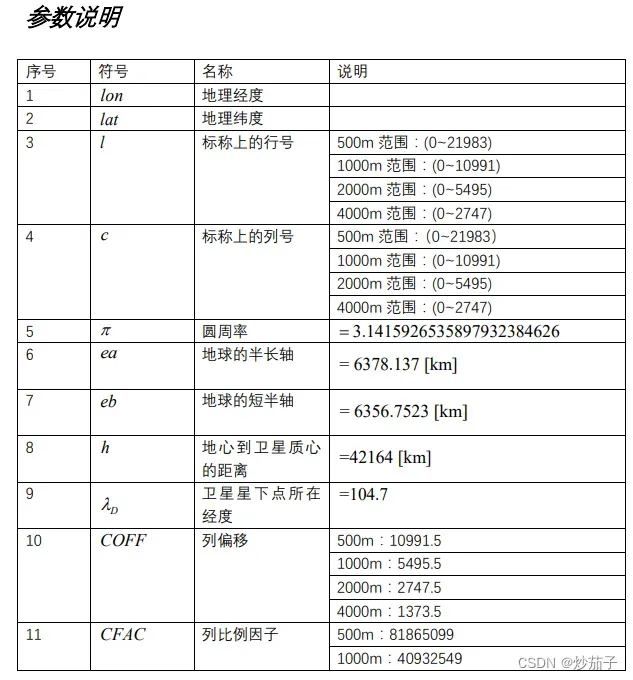
官方文档的下载查阅:FY4A成像仪标称上行列号和经纬度的互相转换方法.V2.pdf
2.6 基于*GEO*.HDF获取行列号数据集以计算经纬度数据(仅适用REGC)
关于*GEO*.HDF的示例:
FY4A-_AGRI–_N_REGC_1047E_L1-_GEO-_MULT_NOM_20200606194500_20200606194917_4000M_V0001.HDF
其中GEO表示定位配准产品:

适用Panoply打开如下:
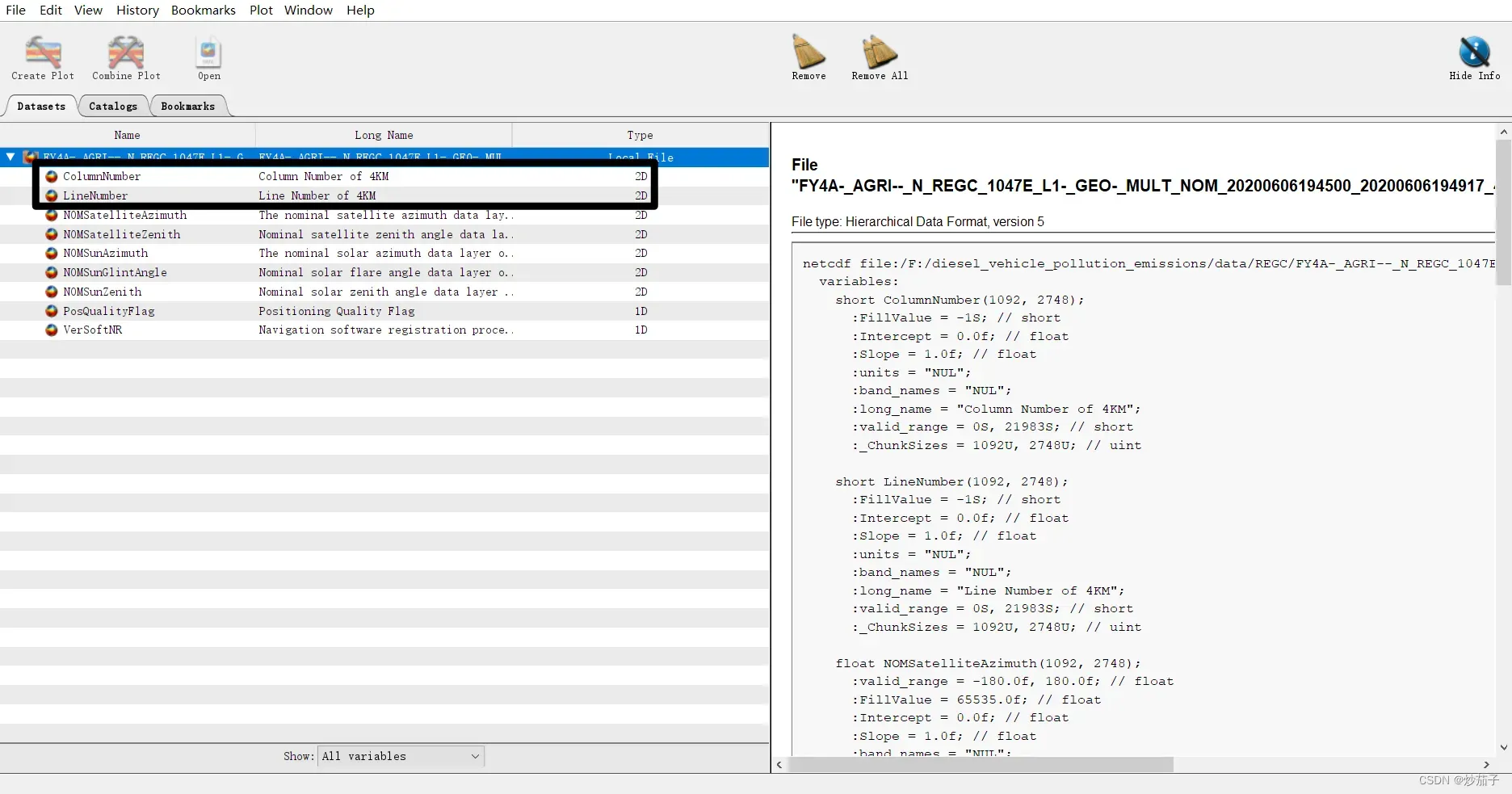
或许你已经发现,其中包含行列号数据集(二维),而且*GEO*.HDF还包含具体的时间,说明应当是对应不同*REGC*.HDF文件,有不同的*GEO*.HDF文件。但是我通过多幅影像查看,发现似乎所有的REGC的行列号数据集是没有区别的,因此在后续的script中我对于所有REGC均适用同一GEO文件的行列号数据集。至于存在不同时间的GEO文件,大概存在于其它数据集例如其中不仅包含行列号数据集还包含NOMSatelliteAzimuth卫星方位角、NOMSunGlintAngle太阳高度角等,这些应该与大气校正有关。所以很明显,因为能力有限,我并没有对数据集进行大气校正,这是非常遗憾。
def read_geo(geo_path, row_name, col_name):
基于FY4A的GEO文件(定位配准产品中的对地图像定位产品)获取像元级的行列号矩阵, 并通过公式计算获取对应的经纬度数据集
:param geo_path: FY4A的GEO文件路径
:param row_name: 行号数据集名称
:param col_name: 列号数据集名称
:return: 经纬度数据集, 形式(lon, lat)
# 读取数据集及其属性
original_row_mesh = h5_data_get(geo_path, row_name)
original_col_mesh = h5_data_get(geo_path, col_name)
row_fill_value = h5_attr_get(geo_path, col_name, 'FillValue')[0]
col_fill_value = h5_attr_get(geo_path, row_name, 'FillValue')[0]
# 有效值掩码
mask = (original_row_mesh != row_fill_value) & (original_col_mesh != col_fill_value)
# 有效值
row_mesh = original_row_mesh[mask]
col_mesh = original_col_mesh[mask]
# 基本参数(均只用于FY4A 4000m分辨率, 其它分辨率需要依据官方说明修改参数)
ea = 6378.137 # 地球长半轴, 单位km
eb = 6356.7523 # 地球短半轴, 单位km
h = 42164 # 卫星高度, 单位km, 即地心到卫星质心的距离
lon0 = 104.7 # 投影中心经度, 单位度, 也即卫星星下点所在的经度
coff = 1373.5 # 列偏移
cfac = 10233137 # 列比例因子
loff = 1373.5 # 行偏移
lfac = 10233137 # 行比例因子
# step1. 求x, y
x = (pi * (col_mesh - coff)) / (180 * (2 ** (-16)) * cfac)
y = (pi * (row_mesh - loff)) / (180 * (2 ** (-16)) * lfac)
# step2. 求sd, sn, s1, s2, s4, sxy
sd = sqrt(
power(h * cos(x) * cos(y), 2) - (power(cos(y), 2) + power(ea / eb, 2) * power(sin(y), 2)) * (h ** 2 - ea ** 2)
sn = (h * cos(x) * cos(y) - sd) / (power(cos(y), 2) + power(ea / eb, 2) * power(sin(y), 2))
s1 = h - sn * cos(x) * cos(y)
s2 = sn * sin(x) * cos(y)
s3 = -sn * sin(y)
sxy = sqrt(power(s1, 2) + power(s2, 2))
# step3. 求lon, lat
lon = lon0 + arctan(s2 / s1) * 180 / pi
lat = arctan(power(ea / eb, 2) * s3 / sxy) * 180 / pi
out_lon = np.zeros_like(original_row_mesh, dtype=np.float32)
out_lat = np.zeros_like(original_row_mesh, dtype=np.float32)
out_lon[mask] = lon
out_lat[mask] = lat
out_lon[~mask] = np.nan
out_lat[~mask] = np.nan
return out_lon, out_lat
此处的代码处理与此前DISK的依据行列号数据集计算经纬度数据集一致,所用文档也是一致的,仅仅在于行列号数据集的获取不同,DISK是通过波段的行列数自行计算的每像元行列号数据集,而此处是REGC没法如此处理(因为REGC为DISK范围的子集),因此我们需要通过GEO文件获取行列号数据集。
2.7 裁剪
这一步的裁剪很关键,在大多数博客的GLT校正中,或多或少都是通过代码或者ENVI生成GLT地理查找表,然后适用ENVI IDL二次打开接口或者ENVI现有工具实现GLT校正。大多数博客都提及GLT校正中在创建GLT文件前需要经纬度数据集进行裁剪,因为DISK全圆盘的缘故,如下圆外均为NoData值。

(源: FY-4A 静止卫星圆盘数据几何校正)
如果直接进行GLT校正会导致GLT校正失败,因此我们需要对经纬度数据集进行选定。
例如博客:FY-4A建立中国区域图像行列号转经纬度的经纬度查找表进行几何校正
def clip(original_band, original_lon, original_lat, lon_lat_range=None):
裁剪, 非常规意义的矩形裁剪, 而是基于经纬度范围的裁剪并进行重组
:param original_band: 原始数据集
:param original_lon: 对应的经度矩阵
:param original_lat: 对应的纬度矩阵
:param lon_lat_range: 经纬度范围, 默认为中国区域(形式:[lon_min, lon_max, lat_min, lat_max])
:return: 裁剪并重组好的数据集, 包括(band, lon, lat)
if lon_lat_range is None:
lon_lat_range = [73, 136, 18, 54] # 中国区域(为兼容REGC, 仅南至海南省主岛屿)
lon_min, lon_max, lat_min, lat_max = lon_lat_range
# 获取经纬度范围内的掩码
mask = (original_lon >= lon_min) & (original_lon <= lon_max) & (original_lat >= lat_min) & (original_lat <= lat_max)
valid_lon = original_lon[mask]
valid_lat = original_lat[mask]
valid_band = original_band[mask]
valid_num = np.sum(mask) # True为1, False为0
valid_num_sqrt = int(sqrt(valid_num))
# 重组数据
reform_lon = valid_lon[:valid_num_sqrt ** 2].reshape(valid_num_sqrt, valid_num_sqrt)
reform_lat = valid_lat[:valid_num_sqrt ** 2].reshape(valid_num_sqrt, valid_num_sqrt)
reform_band = valid_band[:valid_num_sqrt ** 2].reshape(valid_num_sqrt, valid_num_sqrt)
return reform_band, reform_lon, reform_lat
此处的裁剪并不与其它博客裁剪一致,而是指定裁剪的经纬度范围(默认为中国区域),而非指定矩形范围(即类似行列号的裁剪) 。另外,为方便进行GLT校正,我将裁剪后的经纬度数据集和波段数据集进行重组,这部分理解较为困难,与后面的校正函数相关联,这里不予解释。
2.8 GLT校正
def glt_warp(original_dataset, original_lon, original_lat, out_res, method='nearest'):
基于地理查找表的校正
:param original_dataset: 待校正的数据
:param original_lon: 原始数据的经度
:param original_lat: 原始数据的纬度
:param out_res: 输出数据的分辨率
:param method: 插值方法, 默认为最近邻插值('linear', 'nearest', 'cubic')
:return: 校正后的数据
# 校正数据的最大最小经纬度
lon_min, lon_max = np.nanmin(original_lon), np.nanmax(original_lon)
lat_min, lat_max = np.nanmin(original_lat), np.nanmax(original_lat)
# 生成目标数据的经纬度矩阵
grid_lon, grid_lat = np.meshgrid(
np.arange(lon_min, lon_max, out_res),
np.arange(lat_max, lat_min, -out_res),
interp_dataset = griddata(
(original_lon.ravel(), original_lat.ravel()), # 原始数据的经纬度, ravel()将多维数组转换为一维数组
original_dataset.ravel(), # 原始数据
(grid_lon, grid_lat), # 目标数据的经纬度
method=method, # 插值方法
fill_value=np.nan, # 用于填充超出边界的点
return interp_dataset
此GLT校正思路参考某IDL思路,由于IDL代码并非我写且并未询问公开,这里不展示。(IDL生成的影像与Python实现的影像的相关性系数在0.96,不同时间点有差异,差异可能在于插值算法的具体实现有关)。
其思路为通过传入的经纬度数据集获取最大最小的经纬度值,并通过传入的输出分辨率进行输出经纬度数据集的创建(例如最大最小经度为100, 90,而输出分辨率为1°,那么每一行的纬度均为90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100;对于纬度亦是如此。其实类似于前文的行列号数据集的创建)。创建好输出经纬度数据集,接下来就是依据原始经纬度数据集(传入的)以及对应的波段数据集将波段中每一个像元的值填入输出经纬度数据集对应的位置,对于缺失位置的像元通过插值进行填充。
为了方便理解,这里贴出未进行插值但是已经将输入的波段数据集填入输出经纬度数据集对应位置的区域的输出影像:

2.9 输出TIFF文件
# 输出TIF
def write_tiff(out_path, dataset, transform, nodata=np.nan):
输出TIFF文件
:param out_path: 输出文件的路径
:param dataset: 待输出的数据
:param transform: 坐标转换信息(形式:[左上角经度, 经度分辨率, 旋转角度, 左上角纬度, 旋转角度, 纬度分辨率])
:param nodata: 无效值
:return: None
# 创建文件
driver = gdal.GetDriverByName('GTiff')
out_ds = driver.Create(out_path, dataset[0].shape[1], dataset[0].shape[0], len(dataset), gdal.GDT_Float32)
# 设置基本信息
out_ds.SetGeoTransform(transform)
out_ds.SetProjection('WGS84')
# 写入数据
for i in range(len(dataset)):
out_ds.GetRasterBand(i + 1).WriteArray(dataset[i]) # GetRasterBand()传入的索引从1开始, 而非0
out_ds.GetRasterBand(i + 1).SetNoDataValue(nodata)
out_ds.FlushCache()
由于此处的输出TIFF函数进行了改写方便多波段影像的输出,因此如果你是单波段的输出,应该传入[band]而非单波段band数据集,因为我们的形式为[band1, band2, band3,···]。详细信息查看后文主程序。
另外需要说明的是,由于输出的数据集中所有像元值的范围普遍小于1,因此当你使用ArcGIS打开进行显示可能会出现全灰色的情况:

拉伸方法如下:
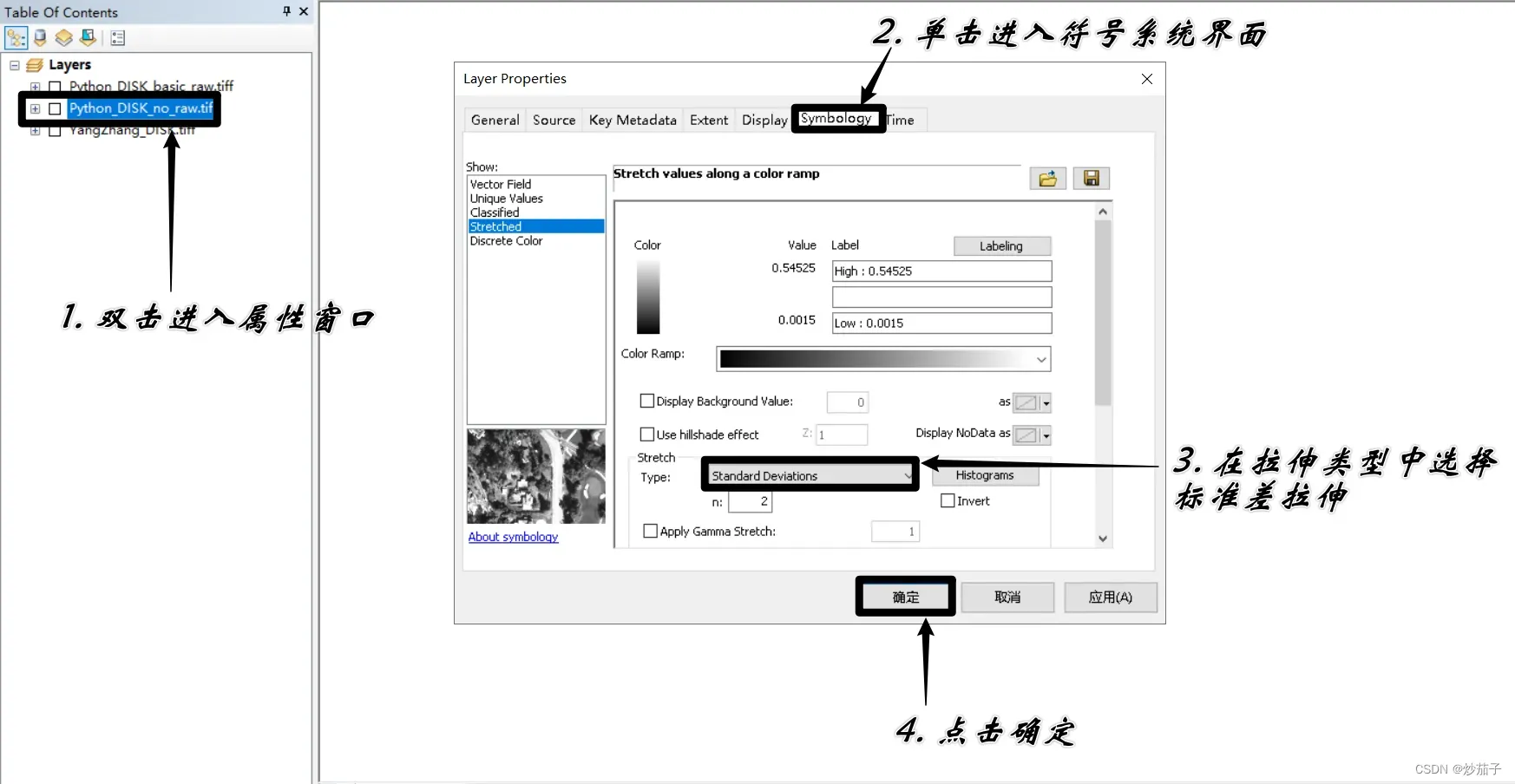
如果在ENVI中打开,则可以正常显示,因为其会默认进行2%线性拉伸。
03 完整程序
为避免错误,对于不同的处理我均将函数搬运在同一个脚本中,为了规范和后续代码的维护,我建议你将函数专门放置于专门的位置,例如:
然后再行调用。
3.1 基于官方地理对照表的DISK(全圆盘)FY4A L1产品的批量预处理
# @炒茄子 2023-07-04
当前脚本用于处理FY4A数据,包括辐射定标、基于地理查找表(.raw文件)的校正、GeoTIFF文件的创建等, 最后输出为GeoTIFF文件(WGS84)
--批量处理
# @炒茄子 2023-07-09
import os
import glob
import h5py
import numpy as np
from numpy import sqrt, sin, cos, power, arctan, pi
from osgeo import gdal
from scipy.interpolate import griddata
# 读取HDF5文件数据集
def h5_data_get(hdf_path, dataset_name):
读取HDF5文件中的数据集
:param hdf_path: HDF5文件的路径
:param dataset_name: HDF5文件中数据集的名称
:return: 数据集
with h5py.File(hdf_path, 'r') as f:
dataset = f[dataset_name][:]
return dataset
# 读取HDF5文件数据集属性
def h5_attr_get(hdf_path, dataset_name, attr_name):
获取HDF5文件数据集的属性
:param hdf_path: HDF5文件的路径
:param dataset_name: HDF5文件中数据集的名称
:param attr_name: HDF5文件中数据集属性的名称
:return: 数据集属性
with h5py.File(hdf_path, 'r') as f:
attr = f[dataset_name].attrs[attr_name]
return attr
# 对FY4A数据集进行辐射定标
def fy4a_calibration(hdf_path, nom_channel_name, cal_channel_name):
获取FY4A数据集并对其进行辐射定标
:param hdf_path: HDF5文件的路径
:param nom_channel_name: 待定标的数据集名称
:param cal_channel_name: 用于定标的数据集名称
:return: 辐射定标后的数据集
# 读取数据集
nom_channel = h5_data_get(hdf_path, nom_channel_name)
cal_channel = h5_data_get(hdf_path, cal_channel_name)
# 读取数据集属性
nom_min, nom_max = h5_attr_get(hdf_path, nom_channel_name, 'valid_range')
cal_min, cal_max = h5_attr_get(hdf_path, cal_channel_name, 'valid_range')
nom_fill_value = h5_attr_get(hdf_path, nom_channel_name, 'FillValue')[0]
cal_fill_value = h5_attr_get(hdf_path, cal_channel_name, 'FillValue')[0]
# 数据集掩码和填充值预准备
nom_mask = (nom_channel > nom_min) & (nom_channel < nom_max) & (nom_channel != nom_fill_value)
cal_mask = (cal_channel > cal_min) | (cal_channel < cal_max)
cal_channel[cal_channel == cal_fill_value] = int(cal_min - 10)
# 辐射定标
target_channel = np.zeros_like(nom_channel, dtype=np.float32)
target_channel[nom_mask] = cal_channel[cal_mask][nom_channel[nom_mask]]
# 无效值处理(包括不在范围及填充值)
target_channel[~nom_mask] = np.nan
target_channel[target_channel == int(cal_min - 10)] = np.nan
return target_channel
def get_lon_lat(dataset):
FY4A数据集经纬度计算(基于FY4A数据格式说明书的公式)
:param dataset: FY4A数据集
:return: 经纬度
# 行列号 ==> 经纬度, 公式由FY4A数据格式说明书给出
# 获取数据集的行列号
rows, cols = dataset.shape
# 生成行列号矩阵
col_mesh, row_mesh = np.meshgrid(np.arange(cols), np.arange(rows))
# 基本参数(均只用于FY4A 4000m分辨率, 其它分辨率需要依据官方说明修改参数)
ea = 6378.137 # 地球长半轴, 单位km
eb = 6356.7523 # 地球短半轴, 单位km
h = 42164 # 卫星高度, 单位km, 即地心到卫星质心的距离
lon0 = 104.7 # 投影中心经度, 单位度, 也即卫星星下点所在的经度
coff = 1373.5 # 列偏移
cfac = 10233137 # 列比例因子
loff = 1373.5 # 行偏移
lfac = 10233137 # 行比例因子
# step1. 求x, y
x = (pi * (col_mesh - coff)) / (180 * (2 ** (-16)) * cfac)
y = (pi * (row_mesh - loff)) / (180 * (2 ** (-16)) * lfac)
# step2. 求sd, sn, s1, s2, s4, sxy
sd = sqrt(
power(h * cos(x) * cos(y), 2) - (power(cos(y), 2) + power(ea / eb, 2) * power(sin(y), 2)) * (h ** 2 - ea ** 2)
sn = (h * cos(x) * cos(y) - sd) / (power(cos(y), 2) + power(ea / eb, 2) * power(sin(y), 2))
s1 = h - sn * cos(x) * cos(y)
s2 = sn * sin(x) * cos(y)
s3 = -sn * sin(y)
sxy = sqrt(power(s1, 2) + power(s2, 2))
# step3. 求lon, lat
lon = lon0 + arctan(s2 / s1) * 180 / pi
lat = arctan(power(ea / eb, 2) * s3 / sxy) * 180 / pi
return lon, lat
def read_geo(geo_path, row_name, col_name):
基于FY4A的GEO文件(定位配准产品中的对地图像定位产品)获取像元级的行列号矩阵, 并通过公式计算获取对应的经纬度数据集
:param geo_path: FY4A的GEO文件路径
:param row_name: 行号数据集名称
:param col_name: 列号数据集名称
:return: 经纬度数据集, 形式(lon, lat)
# 读取数据集及其属性
original_row_mesh = h5_data_get(geo_path, row_name)
original_col_mesh = h5_data_get(geo_path, col_name)
row_fill_value = h5_attr_get(geo_path, col_name, 'FillValue')[0]
col_fill_value = h5_attr_get(geo_path, row_name, 'FillValue')[0]
# 有效值掩码
mask = (original_row_mesh != row_fill_value) & (original_col_mesh != col_fill_value)
# 有效值
row_mesh = original_row_mesh[mask]
col_mesh = original_col_mesh[mask]
# 基本参数(均只用于FY4A 4000m分辨率, 其它分辨率需要依据官方说明修改参数)
ea = 6378.137 # 地球长半轴, 单位km
eb = 6356.7523 # 地球短半轴, 单位km
h = 42164 # 卫星高度, 单位km, 即地心到卫星质心的距离
lon0 = 104.7 # 投影中心经度, 单位度, 也即卫星星下点所在的经度
coff = 1373.5 # 列偏移
cfac = 10233137 # 列比例因子
loff = 1373.5 # 行偏移
lfac = 10233137 # 行比例因子
# step1. 求x, y
x = (pi * (col_mesh - coff)) / (180 * (2 ** (-16)) * cfac)
y = (pi * (row_mesh - loff)) / (180 * (2 ** (-16)) * lfac)
# step2. 求sd, sn, s1, s2, s4, sxy
sd = sqrt(
power(h * cos(x) * cos(y), 2) - (power(cos(y), 2) + power(ea / eb, 2) * power(sin(y), 2)) * (h ** 2 - ea ** 2)
sn = (h * cos(x) * cos(y) - sd) / (power(cos(y), 2) + power(ea / eb, 2) * power(sin(y), 2))
s1 = h - sn * cos(x) * cos(y)
s2 = sn * sin(x) * cos(y)
s3 = -sn * sin(y)
sxy = sqrt(power(s1, 2) + power(s2, 2))
# step3. 求lon, lat
lon = lon0 + arctan(s2 / s1) * 180 / pi
lat = arctan(power(ea / eb, 2) * s3 / sxy) * 180 / pi
out_lon = np.zeros_like(original_row_mesh, dtype=np.float32)
out_lat = np.zeros_like(original_row_mesh, dtype=np.float32)
out_lon[mask] = lon
out_lat[mask] = lat
out_lon[~mask] = np.nan
out_lat[~mask] = np.nan
return out_lon, out_lat
# 读取地理对照表(.raw, FY4A)
def read_glt(raw_path, shape):
该函数用于读取地理对照表
:param raw_path: 地理查找表的路径
:param shape: 地理查找表的形状
:return: 二维数组(lon, lat)
# 读取二进制数据,将其转换为两个2D数组(经度和纬度)
with open(raw_path, 'rb') as f:
raw_data = np.fromfile(f, dtype=np.float64) # 读取二进制数据, '<f8'表示小端模式,8字节浮点数
raw_lat = raw_data[::2].reshape(shape)
raw_lon = raw_data[1::2].reshape(shape)
raw_lat[(raw_lat < -90.0) | (raw_lat > 90.0)] = np.nan
raw_lon[(raw_lon < -180.0) | (raw_lon > 180.0)] = np.nan
官方文档中的说明:文件从北向南按行(从西到东)填写,每个网格对应 16 字节,前8字节为经度值,后 8 字节为纬度值,double 类型,高字节在前
-----------------------------------------------------------------------------------------------------------------
| 通过查看输出的lon, lat发现, lon的范围为[-90, 90], lat的范围为[-180, 180];
| 通过读取二进制流时,如果以高字节在前(Big-Endian/小端模式)的方式(dtype=‘<f8’, , <表示小, 若填入np.float64等价于'<f8'
| 即默认是小端模式)读取数据时,会出现错误的结果;
-----------------------------------------------------------------------------------------------------------------
综上所述, 官方文档的说明存在错误: 应该为前8字节为纬度值,后 8 字节为经度值,double 类型,低字节在前;
参考: https://blog.csdn.net/modabao/article/details/83834580
return raw_lon, raw_lat
def clip(original_band, original_lon, original_lat, lon_lat_range=None):
裁剪, 非常规意义的矩形裁剪, 而是基于经纬度范围的裁剪并进行重组
:param original_band: 原始数据集
:param original_lon: 对应的经度矩阵
:param original_lat: 对应的纬度矩阵
:param lon_lat_range: 经纬度范围, 默认为中国区域(形式:[lon_min, lon_max, lat_min, lat_max])
:return: 裁剪并重组好的数据集, 包括(band, lon, lat)
if lon_lat_range is None:
lon_lat_range = [73, 136, 18, 54] # 中国区域(为兼容REGC, 仅南至海南省主岛屿)
lon_min, lon_max, lat_min, lat_max = lon_lat_range
# 获取经纬度范围内的掩码
mask = (original_lon >= lon_min) & (original_lon <= lon_max) & (original_lat >= lat_min) & (original_lat <= lat_max)
valid_lon = original_lon[mask]
valid_lat = original_lat[mask]
valid_band = original_band[mask]
valid_num = np.sum(mask) # True为1, False为0
valid_num_sqrt = int(sqrt(valid_num))
# 重组数据
reform_lon = valid_lon[:valid_num_sqrt ** 2].reshape(valid_num_sqrt, valid_num_sqrt)
reform_lat = valid_lat[:valid_num_sqrt ** 2].reshape(valid_num_sqrt, valid_num_sqrt)
reform_band = valid_band[:valid_num_sqrt ** 2].reshape(valid_num_sqrt, valid_num_sqrt)
return reform_band, reform_lon, reform_lat
def glt_warp(original_dataset, original_lon, original_lat, out_res, method='nearest'):
基于地理查找表的校正
:param original_dataset: 待校正的数据
:param original_lon: 原始数据的经度
:param original_lat: 原始数据的纬度
:param out_res: 输出数据的分辨率
:param method: 插值方法, 默认为最近邻插值('linear', 'nearest', 'cubic')
:return: 校正后的数据
# 校正数据的最大最小经纬度
lon_min, lon_max = np.nanmin(original_lon), np.nanmax(original_lon)
lat_min, lat_max = np.nanmin(original_lat), np.nanmax(original_lat)
# 生成目标数据的经纬度矩阵
grid_lon, grid_lat = np.meshgrid(
np.arange(lon_min, lon_max, out_res),
np.arange(lat_max, lat_min, -out_res),
interp_dataset = griddata(
(original_lon.ravel(), original_lat.ravel()), # 原始数据的经纬度, ravel()将多维数组转换为一维数组
original_dataset.ravel(), # 原始数据
(grid_lon, grid_lat), # 目标数据的经纬度
method=method, # 插值方法
fill_value=np.nan, # 用于填充超出边界的点
return interp_dataset
# 输出TIF
def write_tiff(out_path, dataset, transform, nodata=np.nan):
输出TIFF文件
:param out_path: 输出文件的路径
:param dataset: 待输出的数据
:param transform: 坐标转换信息(形式:[左上角经度, 经度分辨率, 旋转角度, 左上角纬度, 旋转角度, 纬度分辨率])
:param nodata: 无效值
:return: None
# 创建文件
driver = gdal.GetDriverByName('GTiff')
out_ds = driver.Create(out_path, dataset[0].shape[1], dataset[0].shape[0], len(dataset), gdal.GDT_Float32)
# 设置基本信息
out_ds.SetGeoTransform(transform)
out_ds.SetProjection('WGS84')
# 写入数据
for i in range(len(dataset)):
out_ds.GetRasterBand(i + 1).WriteArray(dataset[i]) # GetRasterBand()传入的索引从1开始, 而非0
out_ds.GetRasterBand(i + 1).SetNoDataValue(nodata)
out_ds.FlushCache()
# 准备工作
in_path = r'===>\DISK' # FY4A L1(DISK全圆盘)产品所在文件夹
raw_path = r'===>\FullMask_Grid_4000.raw' # 地理对照表(地理查找表)文件路径
out_path = r'===>\output' # 输出文件夹
out_res = 0.036 # 0.036为输出的分辨率(°/度), 约为4km
# 检索HDF5文件
paths = glob.iglob(in_path + r'\*DISK*FDI*.HDF')
# 读取地理查找表
lon, lat = read_glt(raw_path, (2748, 2748)) # 地理查找表的shape与band的shape相同,或可从官方文档中获取((2748, 2748))
# 循环处理每一个HDF5文件
for path in paths:
# HDF5文件的文件名
hdf_name = os.path.basename(path).split('.')[0]
# 读取HDF5文件
hdf = h5py.File(path, 'r')
nom_channels_name = [key for key in hdf.keys() if 'NOMChannel' in key] # 读取各个波段的通道名
cal_channels_name = [key for key in hdf.keys() if 'CALChannel' in key] # 读取对应各个波段的辐射定标通道名
channel_names = zip(nom_channels_name, cal_channels_name)
# 循环处理每一个通道
bands = []
transform = None
for nom_channel_name, cal_channel_name in channel_names:
# 辐射定标
band = fy4a_calibration(path, nom_channel_name, cal_channel_name)
clip_band, clip_lon, clip_lat = clip(band, lon, lat)
# GLT校正
processed_band = glt_warp(clip_band, clip_lon, clip_lat, out_res, method='linear')
# 仿射变换参数
transform = (
np.nanmin(clip_lon), # 左上角经度
out_res, # x方向分辨率
0, # 旋转角度
np.nanmax(clip_lat), # 左上角纬度
0, # 旋转角度
-out_res, # y方向分辨率, 由于自左上角开始(纬度往下逐渐减小), 因此为负;
bands.append(processed_band)
# 将处理后的数据和地理查找表的信息写入GeoTIFF文件
hdf_out_path = out_path + '\\' + hdf_name + '.tif'
write_tiff(hdf_out_path, bands, transform)
3.2 基于GEO文件的REGC(中国区域)的FY4A L1产品的批量预处理
# @炒茄子 2023-07-08
当前脚本用于对FY4A L1(REGC中国区域)产品进行辐射定标, 基于FY4A的定位配准产品(*GEO*.HDF)进行地理查找表的校正, 最后输出为GeoTIFF文件(WGS84)
--批量处理
# @炒茄子 2023-07-09
import glob
import os
import h5py
import numpy as np
from numpy import sqrt, sin, cos, power, arctan, pi
from osgeo import gdal
from scipy.interpolate import griddata
# 读取HDF5文件数据集
def h5_data_get(hdf_path, dataset_name):
读取HDF5文件中的数据集
:param hdf_path: HDF5文件的路径
:param dataset_name: HDF5文件中数据集的名称
:return: 数据集
with h5py.File(hdf_path, 'r') as f:
dataset = f[dataset_name][:]
return dataset
# 读取HDF5文件数据集属性
def h5_attr_get(hdf_path, dataset_name, attr_name):
获取HDF5文件数据集的属性
:param hdf_path: HDF5文件的路径
:param dataset_name: HDF5文件中数据集的名称
:param attr_name: HDF5文件中数据集属性的名称
:return: 数据集属性
with h5py.File(hdf_path, 'r') as f:
attr = f[dataset_name].attrs[attr_name]
return attr
# 对FY4A数据集进行辐射定标
def fy4a_calibration(hdf_path, nom_channel_name, cal_channel_name):
获取FY4A数据集并对其进行辐射定标
:param hdf_path: HDF5文件的路径
:param nom_channel_name: 待定标的数据集名称
:param cal_channel_name: 用于定标的数据集名称
:return: 辐射定标后的数据集
# 读取数据集
nom_channel = h5_data_get(hdf_path, nom_channel_name)
cal_channel = h5_data_get(hdf_path, cal_channel_name)
# 读取数据集属性
nom_min, nom_max = h5_attr_get(hdf_path, nom_channel_name, 'valid_range')
cal_min, cal_max = h5_attr_get(hdf_path, cal_channel_name, 'valid_range')
nom_fill_value = h5_attr_get(hdf_path, nom_channel_name, 'FillValue')[0]
cal_fill_value = h5_attr_get(hdf_path, cal_channel_name, 'FillValue')[0]
# 数据集掩码和填充值预准备
nom_mask = (nom_channel > nom_min) & (nom_channel < nom_max) & (nom_channel != nom_fill_value)
cal_mask = (cal_channel > cal_min) | (cal_channel < cal_max)
cal_channel[cal_channel == cal_fill_value] = int(cal_min - 10)
# 辐射定标
target_channel = np.zeros_like(nom_channel, dtype=np.float32)
target_channel[nom_mask] = cal_channel[cal_mask][nom_channel[nom_mask]]
# 无效值处理(包括不在范围及填充值)
target_channel[~nom_mask] = np.nan
target_channel[target_channel == int(cal_min - 10)] = np.nan
return target_channel
def get_lon_lat(dataset):
FY4A数据集经纬度计算(基于FY4A数据格式说明书的公式)
:param dataset: FY4A数据集
:return: 经纬度
# 行列号 ==> 经纬度, 公式由FY4A数据格式说明书给出
# 获取数据集的行列号
rows, cols = dataset.shape
# 生成行列号矩阵
col_mesh, row_mesh = np.meshgrid(np.arange(cols), np.arange(rows))
# 基本参数(均只用于FY4A 4000m分辨率, 其它分辨率需要依据官方说明修改参数)
ea = 6378.137 # 地球长半轴, 单位km
eb = 6356.7523 # 地球短半轴, 单位km
h = 42164 # 卫星高度, 单位km, 即地心到卫星质心的距离
lon0 = 104.7 # 投影中心经度, 单位度, 也即卫星星下点所在的经度
coff = 1373.5 # 列偏移
cfac = 10233137 # 列比例因子
loff = 1373.5 # 行偏移
lfac = 10233137 # 行比例因子
# step1. 求x, y
x = (pi * (col_mesh - coff)) / (180 * (2 ** (-16)) * cfac)
y = (pi * (row_mesh - loff)) / (180 * (2 ** (-16)) * lfac)
# step2. 求sd, sn, s1, s2, s4, sxy
sd = sqrt(
power(h * cos(x) * cos(y), 2) - (power(cos(y), 2) + power(ea / eb, 2) * power(sin(y), 2)) * (h ** 2 - ea ** 2)
sn = (h * cos(x) * cos(y) - sd) / (power(cos(y), 2) + power(ea / eb, 2) * power(sin(y), 2))
s1 = h - sn * cos(x) * cos(y)
s2 = sn * sin(x) * cos(y)
s3 = -sn * sin(y)
sxy = sqrt(power(s1, 2) + power(s2, 2))
# step3. 求lon, lat
lon = lon0 + arctan(s2 / s1) * 180 / pi
lat = arctan(power(ea / eb, 2) * s3 / sxy) * 180 / pi
return lon, lat
def read_geo(geo_path, row_name, col_name):
基于FY4A的GEO文件(定位配准产品中的对地图像定位产品)获取像元级的行列号矩阵, 并通过公式计算获取对应的经纬度数据集
:param geo_path: FY4A的GEO文件路径
:param row_name: 行号数据集名称
:param col_name: 列号数据集名称
:return: 经纬度数据集, 形式(lon, lat)
# 读取数据集及其属性
original_row_mesh = h5_data_get(geo_path, row_name)
original_col_mesh = h5_data_get(geo_path, col_name)
row_fill_value = h5_attr_get(geo_path, col_name, 'FillValue')[0]
col_fill_value = h5_attr_get(geo_path, row_name, 'FillValue')[0]
# 有效值掩码
mask = (original_row_mesh != row_fill_value) & (original_col_mesh != col_fill_value)
# 有效值
row_mesh = original_row_mesh[mask]
col_mesh = original_col_mesh[mask]
# 基本参数(均只用于FY4A 4000m分辨率, 其它分辨率需要依据官方说明修改参数)
ea = 6378.137 # 地球长半轴, 单位km
eb = 6356.7523 # 地球短半轴, 单位km
h = 42164 # 卫星高度, 单位km, 即地心到卫星质心的距离
lon0 = 104.7 # 投影中心经度, 单位度, 也即卫星星下点所在的经度
coff = 1373.5 # 列偏移
cfac = 10233137 # 列比例因子
loff = 1373.5 # 行偏移
lfac = 10233137 # 行比例因子
# step1. 求x, y
x = (pi * (col_mesh - coff)) / (180 * (2 ** (-16)) * cfac)
y = (pi * (row_mesh - loff)) / (180 * (2 ** (-16)) * lfac)
# step2. 求sd, sn, s1, s2, s4, sxy
sd = sqrt(
power(h * cos(x) * cos(y), 2) - (power(cos(y), 2) + power(ea / eb, 2) * power(sin(y), 2)) * (h ** 2 - ea ** 2)
sn = (h * cos(x) * cos(y) - sd) / (power(cos(y), 2) + power(ea / eb, 2) * power(sin(y), 2))
s1 = h - sn * cos(x) * cos(y)
s2 = sn * sin(x) * cos(y)
s3 = -sn * sin(y)
sxy = sqrt(power(s1, 2) + power(s2, 2))
# step3. 求lon, lat
lon = lon0 + arctan(s2 / s1) * 180 / pi
lat = arctan(power(ea / eb, 2) * s3 / sxy) * 180 / pi
out_lon = np.zeros_like(original_row_mesh, dtype=np.float32)
out_lat = np.zeros_like(original_row_mesh, dtype=np.float32)
out_lon[mask] = lon
out_lat[mask] = lat
out_lon[~mask] = np.nan
out_lat[~mask] = np.nan
return out_lon, out_lat
# 读取地理对照表(.raw, FY4A)
def read_glt(raw_path, shape):
该函数用于读取地理对照表
:param raw_path: 地理查找表的路径
:param shape: 地理查找表的形状
:return: 二维数组(lon, lat)
# 读取二进制数据,将其转换为两个2D数组(经度和纬度)
with open(raw_path, 'rb') as f:
raw_data = np.fromfile(f, dtype=np.float64) # 读取二进制数据, '<f8'表示小端模式,8字节浮点数
raw_lat = raw_data[::2].reshape(shape)
raw_lon = raw_data[1::2].reshape(shape)
raw_lat[(raw_lat < -90.0) | (raw_lat > 90.0)] = np.nan
raw_lon[(raw_lon < -180.0) | (raw_lon > 180.0)] = np.nan
官方文档中的说明:文件从北向南按行(从西到东)填写,每个网格对应 16 字节,前8字节为经度值,后 8 字节为纬度值,double 类型,高字节在前
-----------------------------------------------------------------------------------------------------------------
| 通过查看输出的lon, lat发现, lon的范围为[-90, 90], lat的范围为[-180, 180];
| 通过读取二进制流时,如果以高字节在前(Big-Endian/小端模式)的方式(dtype=‘<f8’, , <表示小, 若填入np.float64等价于'<f8'
| 即默认是小端模式)读取数据时,会出现错误的结果;
-----------------------------------------------------------------------------------------------------------------
综上所述, 官方文档的说明存在错误: 应该为前8字节为纬度值,后 8 字节为经度值,double 类型,低字节在前;
参考: https://blog.csdn.net/modabao/article/details/83834580
return raw_lon, raw_lat
def clip(original_band, original_lon, original_lat, lon_lat_range=None):
裁剪, 非常规意义的矩形裁剪, 而是基于经纬度范围的裁剪并进行重组
:param original_band: 原始数据集
:param original_lon: 对应的经度矩阵
:param original_lat: 对应的纬度矩阵
:param lon_lat_range: 经纬度范围, 默认为中国区域(形式:[lon_min, lon_max, lat_min, lat_max])
:return: 裁剪并重组好的数据集, 包括(band, lon, lat)
if lon_lat_range is None:
lon_lat_range = [73, 136, 18, 54] # 中国区域(为兼容REGC, 仅南至海南省主岛屿)
lon_min, lon_max, lat_min, lat_max = lon_lat_range
# 获取经纬度范围内的掩码
mask = (original_lon >= lon_min) & (original_lon <= lon_max) & (original_lat >= lat_min) & (original_lat <= lat_max)
valid_lon = original_lon[mask]
valid_lat = original_lat[mask]
valid_band = original_band[mask]
valid_num = np.sum(mask) # True为1, False为0
valid_num_sqrt = int(sqrt(valid_num))
# 重组数据
reform_lon = valid_lon[:valid_num_sqrt ** 2].reshape(valid_num_sqrt, valid_num_sqrt)
reform_lat = valid_lat[:valid_num_sqrt ** 2].reshape(valid_num_sqrt, valid_num_sqrt)
reform_band = valid_band[:valid_num_sqrt ** 2].reshape(valid_num_sqrt, valid_num_sqrt)
return reform_band, reform_lon, reform_lat
def glt_warp(original_dataset, original_lon, original_lat, out_res, method='nearest'):
基于地理查找表的校正
:param original_dataset: 待校正的数据
:param original_lon: 原始数据的经度
:param original_lat: 原始数据的纬度
:param out_res: 输出数据的分辨率
:param method: 插值方法, 默认为最近邻插值('linear', 'nearest', 'cubic')
:return: 校正后的数据
# 校正数据的最大最小经纬度
lon_min, lon_max = np.nanmin(original_lon), np.nanmax(original_lon)
lat_min, lat_max = np.nanmin(original_lat), np.nanmax(original_lat)
# 生成目标数据的经纬度矩阵
grid_lon, grid_lat = np.meshgrid(
np.arange(lon_min, lon_max, out_res),
np.arange(lat_max, lat_min, -out_res),
interp_dataset = griddata(
(original_lon.ravel(), original_lat.ravel()), # 原始数据的经纬度, ravel()将多维数组转换为一维数组
original_dataset.ravel(), # 原始数据
(grid_lon, grid_lat), # 目标数据的经纬度
method=method, # 插值方法
fill_value=np.nan, # 用于填充超出边界的点
return interp_dataset
# 输出TIF
def write_tiff(out_path, dataset, transform, nodata=np.nan):
输出TIFF文件
:param out_path: 输出文件的路径
:param dataset: 待输出的数据
:param transform: 坐标转换信息(形式:[左上角经度, 经度分辨率, 旋转角度, 左上角纬度, 旋转角度, 纬度分辨率])
:param nodata: 无效值
:return: None
# 创建文件
driver = gdal.GetDriverByName('GTiff')
out_ds = driver.Create(out_path, dataset[0].shape[1], dataset[0].shape[0], len(dataset), gdal.GDT_Float32)
# 设置基本信息
out_ds.SetGeoTransform(transform)
out_ds.SetProjection('WGS84')
# 写入数据
for i in range(len(dataset)):
out_ds.GetRasterBand(i + 1).WriteArray(dataset[i]) # GetRasterBand()传入的索引从1开始, 而非0
out_ds.GetRasterBand(i + 1).SetNoDataValue(nodata)
out_ds.FlushCache()
in_path = r'===>\REGC'
geo_path = r'===>\FY4A-_AGRI--_N_REGC_1047E_L1-_GEO-_MULT_NOM_20200606194500_20200606194917_4000M_V0001.HDF'
out_path = r'===>\output'
row_name = 'LineNumber' # 像元行号矩阵, 来自*GEO*.hdf(上geo_path)
col_name = 'ColumnNumber' # 像元列号矩阵, 同上
out_res = 0.036 # 0.036为输出的分辨率(°/度), 约为4km
# 检索HDF5文件
paths = glob.iglob(in_path + r'\*REGC*FDI*.HDF')
# 通过REGC区域的行列号矩阵计算经纬度矩阵
lon, lat = read_geo(geo_path, row_name, col_name)
for path in paths:
# 获取当前循环文件名
hdf_name = os.path.basename(path).split('.')[0]
# 读取HDF5文件
hdf = h5py.File(path, 'r')
nom_channels_name = [key for key in hdf.keys() if 'NOMChannel' in key]
cal_channels_name = [key for key in hdf.keys() if 'CALChannel' in key]
channels_name = zip(nom_channels_name, cal_channels_name)
bands = []
transform = None
for nom_channel_name, cal_channel_name in channels_name:
# 辐射定标
band = fy4a_calibration(path, nom_channel_name, cal_channel_name)
clip_band, clip_lon, clip_lat = clip(band, lon, lat)
# GLT校正
processed_band = glt_warp(clip_band, clip_lon, clip_lat, out_res, method='linear')
# 仿射变换参数
transform = (
np.nanmin(clip_lon), # 左上角经度
out_res, # 东西向分辨率(经度分辨率)
0, # 旋转角度
np.nanmax(clip_lat), # 左上角纬度
0, # 旋转角度
-out_res # 南北向分辨率(纬度分辨率)
bands.append(processed_band)
write_tiff(os.path.join(out_path, hdf_name + '.tiff'), bands, transform)
3.3 基于行列号计算经纬度数据集(DISK/全圆盘)的FY4A L1产品的单个文件预处理
此处时间精力有限,并没有进行批量处理的改写,函数也是调用的,需要自行修改。
# @炒茄子 2023-07-06
当前脚本用于对FY4A L1(DISK全圆盘)产品进行辐射定标, 通过公式计算经纬度数据集(由行列数计算, 公式见官方文档)进行地理查找表的校正(未使用官方
基于DISK的地理对照表, 但效果一致),最后输出为GeoTIFF文件(WGS84)
from lib.func import write_tiff, glt_warp, fy4a_calibration, get_lon_lat, clip
if __name__ == '__main__':
# 准备工作
in_path = r'===>\FY4A-_AGRI--_N_DISK_1047E_L1-_FDI-_MULT_NOM_20200601010000_20200601011459_4000M_V0001.HDF'
out_path = r'===>\Python_DISK_no_raw.tif'
nom_channel_name = 'NOMChannel02'
cal_channel_name = 'CALChannel02'
# 辐射定标
band = fy4a_calibration(in_path, nom_channel_name, cal_channel_name)
# 依据行列号获取经纬度
lon, lat = get_lon_lat(band)
reform_band, reform_lon, reform_lat = clip(band, lon, lat)
interp_band = glt_warp(reform_band, reform_lon, reform_lat, 0.036) # 0.036°大约是4km
write_tiff(out_path, [interp_band], reform_lon, reform_lat)
以下其它单个文件单个波段的处理,可能存在错误,因为函数进行了一定的修改。
# @炒茄子 2023-07-04
当前脚本用于处理FY4A数据,包括辐射定标、基于地理查找表的校正、GeoTIFF文件的创建等, 最后输出为GeoTIFF文件(WGS84)
in_path = ''
georaw_path = ''
out_path = ''
target_channel_name = 'NOMChannel01'
cal_channel_name = 'CALChannel01'
# 辐射定标
band = fy4a_calibration(in_path, target_channel_name, cal_channel_name)
# 读取地理查找表
glt_shape = band.shape # 地理查找表的shape与band的shape相同,或可从官方文档中获取((2748, 2748))
lon, lat = read_glt(georaw_path, glt_shape)
# 重投影和重采样区域
clip_band, clip_lon, clip_lat = clip(band, lon, lat)
# 基于地理查找表的校正(我认为这实际上可能仅仅是重投影和重采样, 因为我只做了这一些)
data = glt_warp(clip_band, clip_lon, clip_lat, 0.036) # 0.04为输出的分辨率(°/度)
# 将处理后的数据和地理查找表的信息写入GeoTIFF文件
write_tiff(out_path, [data], clip_lon, clip_lat)
# @炒茄子 2023-07-06
当前脚本用于对FY4A L1(REGC中国区域)产品进行辐射定标, 基于FY4A的定位配准产品(*GEO*.HDF)进行地理查找表的校正, 最后输出为GeoTIFF文件(WGS84)
# 准备工作
in_path = r''
geo_path = r'' # 定位配准文件
out_path = r'' # 待输出文件路径
nom_channel_name = 'NOMChannel02' # 通道名, 来自*FDI*.hdf
cal_channel_name = 'CALChannel02' # 通道名, 来自*FDI*.hdf, 用于辐射定标
row_name = 'LineNumber' # 像元行号矩阵, 来自*GEO*.hdf
col_name = 'ColumnNumber' # 像元列号矩阵, 同上
# 辐射定标
band = fy4a_calibration(in_path, nom_channel_name, cal_channel_name)
# 依据行列号获取经纬度
lon, lat = read_geo(geo_path, row_name, col_name)
reform_band, reform_lon, reform_lat = clip(band, lon, lat)
interp_band = glt_warp(reform_band, reform_lon, reform_lat, 0.036) # 0.036°大约是4km
write_tiff(out_path, [interp_band], reform_lon, reform_lat)
04 结果展示
4.1 ArcGIS显示

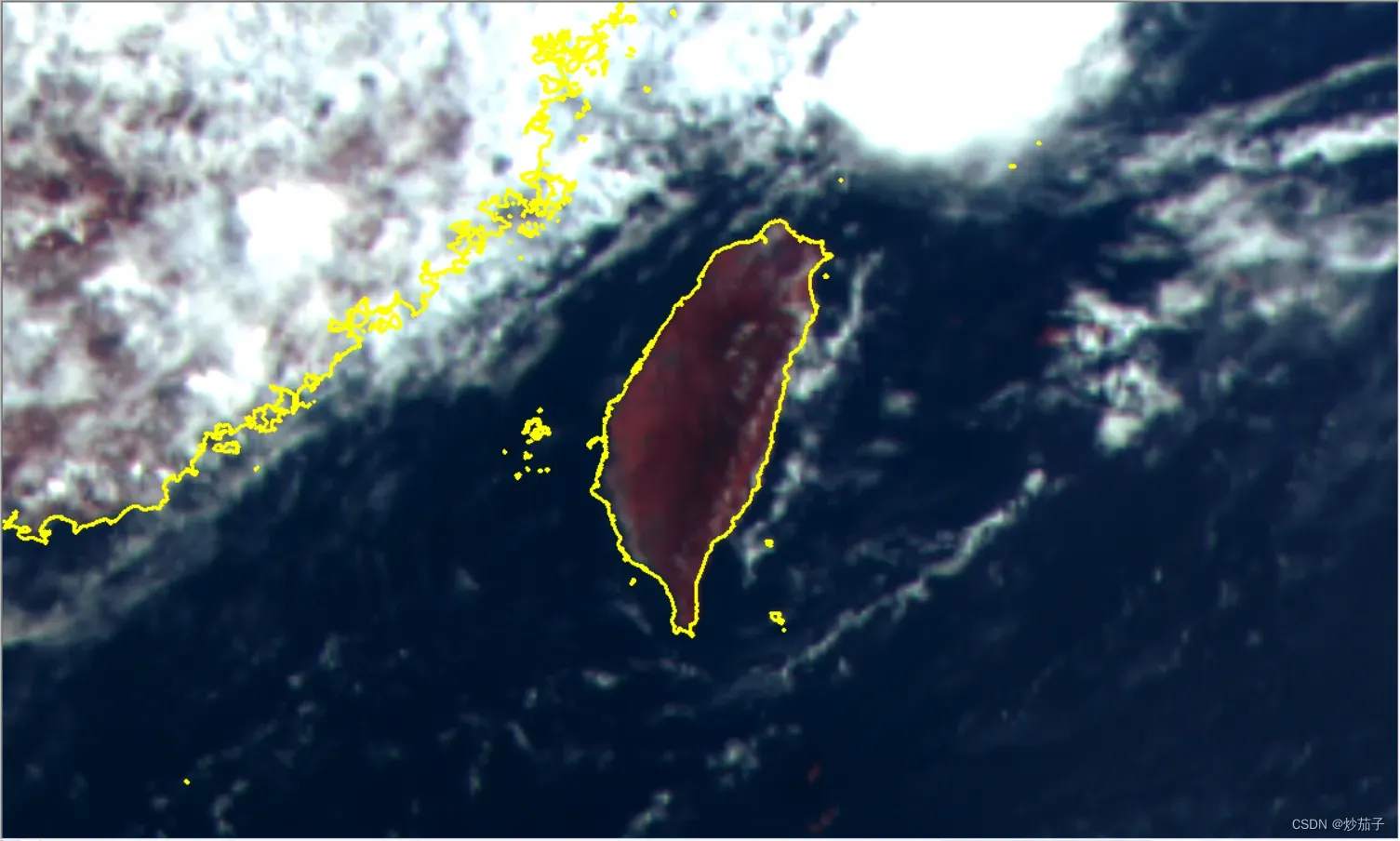 (没有明显的偏移)
(没有明显的偏移)

4.2 ENVI 显示




暂且如此(代码还有很多可以拓展的地方,但时间精力有限),🔜🗣如果你有任何问题、想法或者建议💌💬,欢迎随时向我提出👀!

