|
|
|
相关文章推荐

|
爱笑的木瓜 · 适用荣耀magicb...· 2 月前 · |
|
|
长情的充电器 · L%E3%80%90%E8%81%94%E7 ...· 2 年前 · |
|
|
彷徨的小虾米 · 【项目经验】——Axure团队项目问题集锦_ ...· 2 年前 · |

install.packages("astsa")
library(astsa)
e1x2 <- ts(scan("C:/Users/l/Desktop/e1x2.dat")) #数据导入
plot(e1x2, type="b") #画时序图
绘制自相关图和偏自相关图
acf(e1x2)
pacf(e1x2)
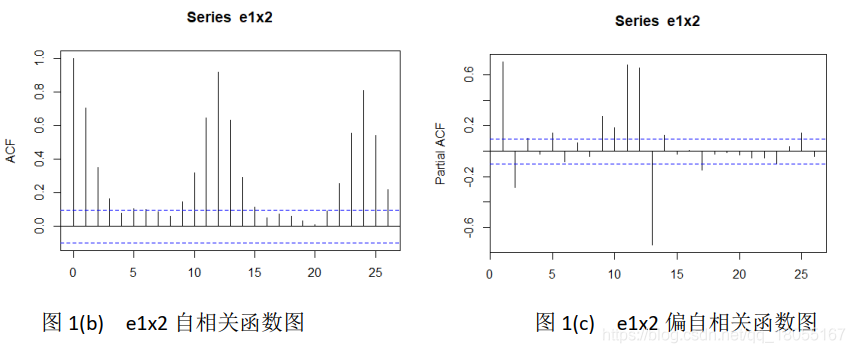
通过对相同数据的分析,可尝试S=12为季度周期。
进行季节差分
#计算月度均值
e1x2m = matrix(e1x2, ncol=12,byrow=TRUE)
col.means=apply(e1x2m,2,mean)
plot(col.means,type="b", main="Monthly Means Plot for e1x2", xlab="Month",
ylab="Mean")
diffe12=diff(e1x2,12)#进行季节 s=12 差分
plot(diffe12)
acf2(diffe12,48)
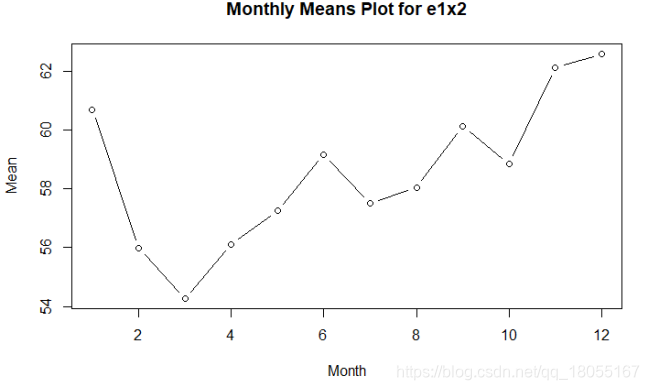
对每个月的数据进行平均之后,可以看出数据已经没有了周期性。
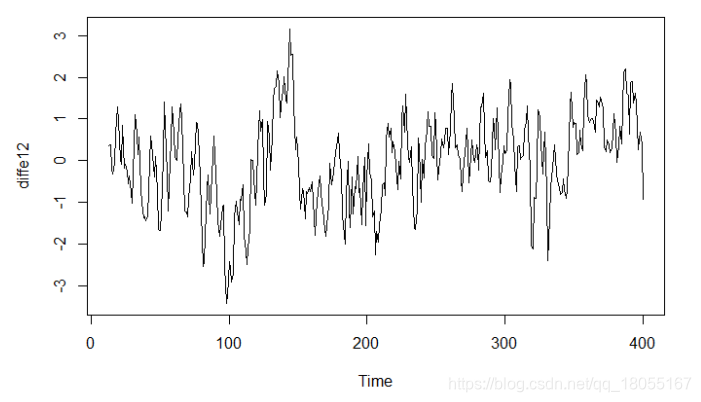
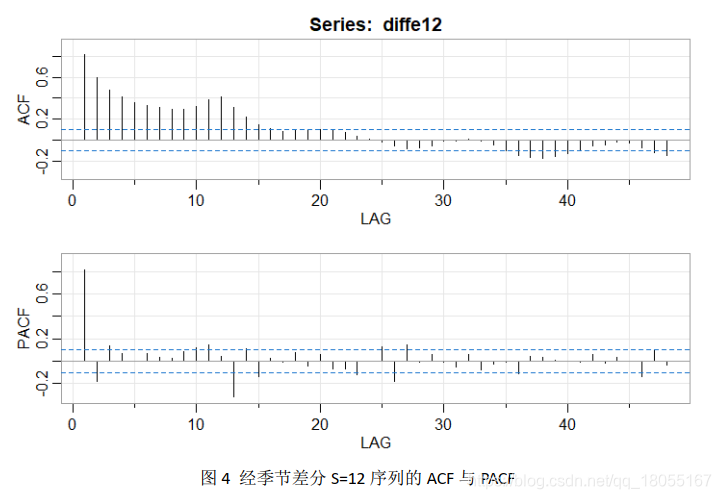
经过S=12的季节差分之后,数据的周期性几乎已经除去。图4中,偏自相关图1阶结尾,而自相关图拖尾,因此可以考虑p=1, q=0。另外,偏自相关图似乎具有以12为周期的拖尾现象,故可以考虑Q=1。总之,可以从模型ARIMA(1,0,0)
sarima(e1x2, 1,0,1,0,1,1,12)#****
sarima(e1x2, 1,0,1,1,1,1,12)#12 阶以后小于 0.05***
sarima(e1x2, 1,0,1,1,1,0,12)#**
sarima(e1x2, 1,0,0,0,1,1,12)#***
sarima(e1x2, 1,0,1,1,0,1,12)#****
通过对残差序列的检验,可知残差已经没有相关性,并且数据分布接近于正态。
文章目录读取数据并绘制时序图绘制自相关图和偏自相关图进行季节差分模型拟合读取数据并绘制时序图install.packages("astsa")library(astsa)e1x2 <- ts(scan("C:/Users/l/Desktop/e1x2.dat")) #数据导入plot(e1x2, type="b") #画时序图绘制自相关图和偏自相关图acf(e1x2)pacf(e1x2)通过对相同数据的分析,可尝试S=12为季度周期。进行季节差分#计算月度均值e1x2m
按照后期进行数据分析的需求,对数据进行预处理。
-描述性统计:选择合适的方法对数据进行统计分析。包括对数值型和类别型属性的统计,并对分析结果进行图形化的展示(使用ggplot2或者lattice包)。
-推断性统计:选择合适的假设检验方法,分析属性间的相关性、两组数据间是否具有显著性差异,分析结果并给出结论及必要的图形展示。
- 数据挖掘
根据数据特征及需求,利用分类、聚类或时间序列方法挖掘蕴含在数据中的模式及必要的图形展示,用回归模型预测走势
注意:对聚类结果分析聚簇特征
对分类结果计算准确性。
使用时间序列分析方法可判断数据是否存在趋势、周期性等特征,或对数据进行预测。
(分类、聚类、时间序列,回归模型至少使用2种方法)
二、GM(1,1)模型
2.1 GM(1,1)模型概述
灰色预测经常用来解决数据量较少且不能直接发现规律的数据。对于包含不确定信息的序列,灰色预测方法通过对原始数据进行处理,使之转化为灰色序列,并建立微分方程模型模型
GM(1,1)模型是灰色预测理论的基本模型,也是灰色系统理论中运用最广泛的一种动态预测模型,模型由一个单变量的一阶微分方程构成。GM(1,1)模型适合对“少数据,贫信息”的对象进行中短期预测
2.2 GM(1,1)数据处理方法
在灰色系统中,能获得的信息非常有限,且不易发现内部规律,因此我们需
时间序列的小波分析
时间序列(Time Series)是地学研究中经常遇到的问题。在时间序列研究中,时域和频域是常用的两种基本形式。其中,时域分析具有时间定位能力,但无法得到关于时间序列变化的更多信息;频域分析(如Fourier变换)虽具有准确的频率定位功能,但仅适合平稳时间序列分析。然而,地学中许多现象(如河川径流、地震波、暴雨、洪水等)随时间的变化往往受到多种因素的综合影响,大都属于非平稳序列,它们不但具有趋势性、周期性等特征,还存在随机性、突变性以及“多时间尺度”结构,具有多层次演变规律。对于这类非平稳时间序列的研究,通常需要某一频段对应的时间信息,或某一时段的频域信息。显然,时域分析和频域分析对此均无能为力。
20世纪80年代初,由Morlet提出的一种具有时-频多分辨功能的小波分析(Wavelet Analysis)为更好的研究时间序列问题提供了可能,它能清晰的揭示出隐藏在时间序列中的多种变化周期,充分反映系统在不同时间尺度中的变化趋势,并能对系统未来发展趋势进行定性估计。
目前,小波分析理论已在信号处理、图像压缩、模式识别、数值分析和大气科学等众多的非线性科学领域内得到了广泛的应。在时间序列研究中,小波分析主要用于时间序列的消噪和滤波,信息量系数和分形维数的计算,突变点的监测和周期成分的识别以及多时间尺度的分析等。
在双周期域上求解二维湍流方程。
LesHouches2017/notebooks文件夹包含:
三个代码(python,julia,matlab)以与笔记本中相同的方式在双周期域上求解二维湍流方程。
julia代码的优化版本。
在beta平面上求解方程的代码。
UNCW流体力学课
北卡罗莱纳州威尔明顿,2018年3月
UNCW2018/part1文件夹包含一个演示的IJulia笔记本
网格上函数的离散化,
使用有限差分和频谱方法对周期性一维函数进行微分,
使用频谱方法区分周期性2D函数。
UNCW2018/part2文件夹包含:
关于2D不可压缩的Navier-Stokes的注释
一个IJulia笔记本,可在双周期域上求解2D
Navier-Stokes
包含Julia,Matlab和P
滞后差分:滞后项一般是指该变量的前一期的值,而差分则是当期值与前一期的值之差(一阶)。
例如:存在向量C(x1,x2,x3,x4,x5),若为一阶(滞后一阶是前一期的值),滞后差则是当前项与前一项的差,如:x2-x1,x3-x2。
若为二阶(滞后二阶是前两期的值),滞后差则是当前项与前二项的差。如:x3-x1,x4-x2。
其次介绍diff()函数:
diff(x , lag , differences)
# x 指输入的数据,可以是向量,也可以是矩阵 。
# lag 指为
季节性的ARIMA模型可以预测含有季节性,趋势性的时间序列。他的形式如下
这里m是每一季节的周期值。季节项与非季节项的模型非常相近。但是季节项中包含了季节周期性。例如对于ARIMA(1,1,1)(1,1,1)4模型能够写成:
ACF与PACF
对于AR与MA模型的季节项,我们将会在ACF和PACF的lags上看到差异。例如,ARIMA(0,0,0)(0,0,1)12模型,我们将会在ACF的la...
第一章 Oracle入门
一、 数据库概述
数据库(Database)是按照数据结构来组织、存储和管理数据的仓库,它产生于距今五十年前。简单来说是本身可视为电子化的文件柜——存储电子文件的处所,用户可以对文件中的数据运行新增、截取、更新、删除等操作。
常见的数据模型
1. 层次结构模型: 层次结构模型实质上是一种有根结点的定向有序树,IMS(Information Manage-mentSystem)是其典型代表。
2. 网状结构模型:按照网状数据结构建立的数据库系统称为网状数据库系统,其典型代表是DBTG(Data Base Task Group)。
3. 关系结构模型:关系式数据结构把一些复杂的数据结构归结为简单的二元关系(即二维表格形式)。常见的有Oracle、mssql、mysql等
二、 主流数据库
数据库名 公司 特点 工作环境
mssql 微软 只能能运行在windows平台,体积比较庞大,占用许多系统资源, 但使用很方便,支持命令和图形化管理,收费。 中型企业
Mysql 甲骨文 是个开源的数据库server,可运行在多种平台, 特点是响应速度特别快,主要面向中小企业 中小型企业
PostgreSQL 号称“世界上最先进的开源数据库“,可以运行在多种平台下,是tb级数据库,而且性能也很好 中大型企业
oracle 甲骨文 获得最高认证级别的ISO标准安全认证,性能最高, 保持开放平台下的TPC-D和TPC-C的世界记录。但价格不菲 大型企业
db2 IBM DB2在企业级的应用最为广泛, 在全球的500家最大的企业中,几乎85%以上用DB2数据库服务器。收费 大型企业
Access 微软 Access是一种桌面数据库,只适合数据量少的应用,在处理少量 数据和单机访问的数据库时是很好的,效率也很高 小型企业
三、 Oracle数据库概述
ORACLE数据库系统是美国ORACLE公司(甲骨文)提供的以分布式数据库为核心的一组软件产品,是目前最流行的客户/服务器(CLIENT/SERVER)或B/S体系结构的数据库之一。
拉里•埃里森
就业前景
从就业与择业的角度来讲,计算机相关专业的大学生从事oracle方面的技术是职业发展中的最佳选择。
其一、就业面广:全球前100强企业99家都在使用ORACLE相关技术,中国政府机构,大中型企事业单位都能有ORACLE技术的工程师岗位。
其二、技术层次深:如果期望进入IT服务或者产品公司(类似毕博、DELL、IBM等),Oracle技术能够帮助提高就业的深度。
其三、职业方向多:Oracle数据库管理方向、Oracle开发及系统架构方向、Oracle数据建模数据仓库等方向。
四、 如何学习
认真听课、多思考问题、多动手操作、有问题一定要问、多参与讨论、多帮组同学
五、 体系结构
oracle的体系很庞大,要学习它,首先要了解oracle的框架。oracle的框架主要由物理结构、逻辑结构、内存分配、后台进程、oracle例程、系统改变号 (System Change Number)组成
物理结构
物理结构包含三种数据文件:
1) 控制文件
2) 数据文件
3) 在线重做日志文件
逻辑结构
功能:数据库如何使用物理空间
组成:表空间、段、区、块的组成层次
六、 oracle安装、卸载和启动
硬件要求
物理内存:1GB
可用物理内存:50M
交换空间大小:3.25GB
硬盘空间:10GB
1. 安装程序成功下载,将会得到如下2个文件:
解压文件将得到database文件夹,文件组织如下:
点击setup.exe执行安装程序,开始安装。
2. 点击安装程序将会出现如下安装界面,步骤 1/9:配置安全更新
填写电子邮件地址(可以不填),去掉复选框,点击下一步
3. 步骤2/9:选择安装选项
勾选第一个,安装和配置数据库,点击下一步
4. 步骤3/8:选择系统类
勾选第一个:桌面类,点击下一步
5. 步骤4/8:配置数据库安装
选择安装路径,选择数据库版本(企业版),选择字符集(默认值)
填写全局数据库名,管理口令
6. 步骤5/8:先决条件检查
如果你的电脑满足要求但仍然显示检查失败,这时候直接忽略,勾选全部忽略
7. 步骤6/8:概要信息
核对将要安装数据的详细信息,并保存响应文件,以备以后查看。然后点击完成数据库安装
8. 步骤7/8:安装产品
产品安装过程中将会出现以上2个界面
9. 步骤8/8:完成安装
卸载Oracle
1. 在运行services.msc打开服务,停止Oracle的所有服务。
2. oracle11G自带一个卸载批处理\app\Administrator\product\11.2.0\dbhome_1\deinstall\deinstall.bat
3. 运行该批处理程序将自动完成oracle卸载工作,最后手动删除\app文件夹(可能需要重启才能删除)
4. 运行regedit命令,打开注册表窗口。删除注册表中与Oracle相关的内容,具体如下:
删除HKEY_LOCAL_MACHINE/SOFTWARE/ORACLE目录。
删除HKEY_LOCAL_MACHINE/SYSTEM/CurrentControlSet/Services中所有以oracle或OraWeb为开头的键。
删除HKEY_LOCAL_MACHINE/SYSETM/CurrentControlSet/Services/Eventlog/application中所有以oracle开头的键。
删除HKEY_CLASSES_ROOT目录下所有以Ora、Oracle、Orcl或EnumOra为前缀的键。
删除HKEY_CURRENT_USER/SOFTWARE/Microsoft/windows/CurrentVersion/Explorer/MenuOrder/Start Menu/Programs中所有以oracle 开头的键。
删除HKDY_LOCAL_MACHINE/SOFTWARE/ODBC/ODBCINST.INI中除Microsoft ODBC for Oracle注册表键以外的所有含有Oracle的键。
删除环境变量中的PATHT CLASSPATH中包含Oracle的值。
删除“开始”/“程序”中所有Oracle的组和图标。
删除所有与Oracle相关的目录,包括:
C:\Program file\Oracle目录。
ORACLE_BASE目录。
C:\Documents and Settings\系统用户名、LocalSettings\Temp目录下的临时文件。
七、 oracle中的数据库
八、 常用的工具
Sql Plus
Sql Developer
Oracle Enterprise Manager
第二章 用户和权限
一、 用户介绍
ORACLE用户是学习ORACLE数据库中的基础知识,下面就介绍下类系统常用的默认ORACLE用户:
1. sys用户:超级用户,完全是个SYSDBA(管理数据库的人)。拥有dba,sysdba,sysoper等角色或权限。是oracle权限最高的用户,登录时不能用normal。
2. system用户:超级用户,默认是SYSOPT(操作数据库的人),不过它也能以SYSDBA的权限登陆。拥有普通dba角色权限。
3. scott用户:是个演示用户,是让你学习Oracle用的。
二、 常用命令
学习oracle,首先我们必须要掌握常用的基本命令,oracle中的命令比较多,常用的命令如下:
1. 登录命令(sqlplus)
说明:用于登录到oracle数据库
用法:sqlplus 用户名/密码 [as sysdba/sysoper]
注意:当用特权用户登录时,必须带上sysdba或sysoper
普通用户登录
sys用户登录
操作系统的身份登录
2. 连接命令(conn)
说明:用于连接到oracle数据库,也可实现用户的切换
用法:conn 用户名/密码 [as sysdba/sysoper]
注意:当用特权用户连接时,必须带上sysdba或sysoper
3. 断开连接(disc)
说明:断开与当前数据库的连接
用法:disc
4. 显示用户名(show user)
说明:显示当前用户名
用法:show user
5. 退出(exit)
说明:断开与当前数据库的连接并会退出
用法:exit
6. 编辑脚本(edit/ed)
说明:编辑指定或缓冲区的sql脚本
用法:edit [文件名]
7. 运行脚本 (start/@)
说明:运行指定的sql脚本
用法:start/@ 文件名
8. 印刷屏幕 (spool)
说明:将sql*plus屏幕中的内容输出到指定的文件
用法:开始印刷->spool 文件名 结束印刷->spool off
9. 显示宽度 (linesize)
说明:设置显示行的宽度,默认是80个字符
用法:set linesize 120
10. 显示页数 (pagesize)
说明:设置每页显示的行数,默认是14页
用法:set pagesize 20
三、 用户管理
1. 创建用户
说明:Oracle中需要创建用户一定是要具有dba(数据库管理员)权限的用户才能创建,而且创建的新用户不具备任何权限,连登录都不可以。
用法:create user 新用户名 identified by 密码
2. 修改密码
说明:修改用户密码一般有两种方式,一种是通过命令password修改,另一种是通过语句alter user实现,如果要修改他人的密码,必须要具有相关的权限才可以
方式一 password [用户名]
方式二 alert user 用户名 identified by 新密码
修改当前用户(方式一)
修改当前用户(方式二)
修改其他用户(方式一)
修改其他用户(方式二)
3. 用户禁用与启用
说明:Oracle中想要禁用或启用一个账户也同样是使用alter user 命令来完成,只是语法和修改密码有所不同。
禁用 alert user 用户名 account lock
启用 alert user 用户名 account unlock
4. 删除用户
说明:Oracle中要删除一个用户,必须要具有dba的权限。而且不能删除当前用户,如果删除的用户有数据对象,那么必须加上关键字cascade。
用法:drop user 用户名 [cascade]
四、 用户权限与角色
1. 权限
Oracle中权限主要分为两种,系统权限和实体权限。
系统权限:系统规定用户使用数据库的权限。(系统权限是对用户而言)。
DBA: 拥有全部特权,是系统最高权限,只有DBA才可以创建数据库结构。
RESOURCE:拥有Resource权限的用户只可以创建实体,不可以创建数据库结构。
CONNECT:拥有Connect权限的用户只可以登录Oracle,不可以创建实体,不可以创建数据库结构。
对于普通用户:授予connect, resource权限。
对于DBA管理用户:授予connect,resource, dba权限。
授予系统权限
说明:要实现授予系统权限只能由DBA用户授出。
用法:grant 系统权限1[,系统权限2]… to 用户名1[,用户名2]….
系统权限回收:
说明:系统权限只能由DBA用户回收
用法:revoke 系统权限 from 用户名
实体权限:某种权限用户对其它用户的表或视图的存取权限。(是针对表或视图而言的)。主要包括select, update, insert, alter, index, delete, all其中all包括所有权限。
授予实体权限
用法:grant 实体权限1[,实体权限2]… on 表名 to用户名1[,用户名2]….
实体权限回收
用法:revoke 实体权限 on 表名from 用户名
查询用户拥有哪里权限:
SQL> select * from role_tab_privs;//查询授予角色的对象权限
SQL> select * from role_role_privs;//查询授予另一角色的角色
SQL> select * from DBA_tab_privs;//查询直接授予用户的对象权限
SQL> select * from dba_role_privs;//查询授予用户的角色
SQL> select * from dba_sys_privs;//查询授予用户的系统权限
SQL> select * from role_sys_privs;//查询授予角色的系统权限
SQL> Select * from session_privs;// 查询当前用户所拥有的权限
2. 角色
角色。角色是一组权限的集合,将角色赋给一个用户,这个用户就拥有了这个角色中的所有权限。
系统预定义角色
预定义角色是在数据库安装后,系统自动创建的一些常用的角色。下面我们就简单介绍些系统角色:
CONNECT, RESOURCE, DBA这些预定义角色主要是为了向后兼容。其主要是用于数据库管理。oracle建议用户自己设计数据库管理和安全的权限规划,而不要简单的使用这些预定角色。将来的版本中这些角色可能不会作为预定义角色。
DELETE_CATALOG_ROLE, EXECUTE_CATALOG_ROLE,SELECT_CATALOG_ROLE这些角色主要用于访问数据字典视图和包。
EXP_FULL_DATABASE, IMP_FULL_DATABASE这两个角色用于数据导入导出工具的使用。
自定义角色
Oracle建议我们自定义自己的角色,使我们更加灵活方便去管理用户
创建角色
SQL> create role admin;
授权给角色
SQL> grant connect,resource to admin;
撤销角色的权限
SQL> revoke connect from admin;
删除角色
SQL> drop role admin;
第三章 Sql查询与函数
一、 SQL概述
SQL(Structured Query Language)结构化查询语言,是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统。同时也是数据库脚本文件的扩展名。
SQL语言主要包含5个部分
数据定义语言Data Definition Language(DDL),用来建立数据库、数据对象和定义其列。例如:CREATE、DROP、ALTER等语句。
数据操作语言Data Manipulation Language(DML),用来插入、修改、删除、查询,可以修改数据库中的数据。例如:INSERT(插入)、UPDATE(修改)、DELETE(删除)语句
数据查询语言 (Data Query Language, DQL) 是SQL语言中,负责进行数据查询而不会对数据本身进行修改的语句,这是最基本的SQL语句。例如:SELECT(查询)
数据控制语言Data Controlling Language(DCL),用来控制数据库组件的存取允许、存取权限等。例如:GRANT、REVOKE、COMMIT、ROLLBACK等语句。
事务控制语言(Transactional Control Language,TCL),用于维护数据的一致性,包括COMMIT(提交事务)、ROLLBACK(回滚事务)和SAVEPOINT(设置保存点)3条语句
二、 Oracle的数据类型
类型 参数 描述
字符类型 char 1~2000字节 固定长度字符串,长度不够的用空格补充
varchar2 1~4000字节 可变长度字符串,与CHAR类型相比,使用VARCHAR2可以节省磁盘空间,但查询效率没有char类型高
数值类型 Number(m,n) m(1~38)
n(-84~127) 可以存储正数、负数、零、定点数和精度为38位的浮点数,其中,M表示精度,代表数字的总位数;N表示小数点右边数字的位数
日期类型 date 7字节 用于存储表中的日期和时间数据,取值范围是公元前4712年1月1日至公元9999年12月31日,7个字节分别表示世纪、年、月、日、时、分和秒
二进制数据类型 row 1~2000字节 可变长二进制数据,在具体定义字段的时候必须指明最大长度n
long raw 1~2GB 可变长二进制数据
LOB数据类型 clob 1~4GB 只能存储字符数据
nclob 1~4GB 保存本地语言字符集数据
blob 1~4GB 以二进制信息保存数据
三、 DDL语言
1. Create table命令
用于创建表。在创建表时,经常会创建该表的主键、外键、唯一约束、Check约束等
语法结构
create table 表名(
[字段名] [类型] [约束]
………..
CONSTRAINT fk_column
FOREIGN KEY(column1,column2,…..column_n)
REFERENCES tablename(column1,column2,…..column_n)
例子:
create table student(
stuNo char(32) primary key,--主键约束
stuName varchar2(20) not null,--非空约束
cardId char(20) unique,--唯一约束
sex char(2) check(sex='男' or sex='女'),--检查约束
address varchar2(100) default '地址不详'--默认约束
create table mark(
mid int primary key,--主键约束
stuNo char(32) not null,
courseName varchar2(20) not null,--非空约束
score number(3) not null check(score>=0 and scoreselect * from em--查询所有数据
SQL>select ename,job from em--查询指定的字段数据
SQL> select * from emp where sal>1000--加条件
2. 聚合函数
聚合函数对一组值执行计算并返回单一的值。聚合函数忽略空值。聚合函数经常与 SELECT 语句的 GROUP BY 子句一同使用。不能在 WHERE 子句中使用组函数。
AVG(expression): 返回集合中各值的平均值
--查询所有人都的平均工资
select avg(sal) from emp
COUNT(expression): 以 Int32 形式返回集合中的项数
--查询工资低于2000的人数
select count(*) from emp where sal2000
5. 连接查询
连接查询是关系数据库中最主要的查询,主要包括内连接、外连接和交叉连接等。通过连接运算符可以实现多个表查询。
内连接
内连接也叫连接,是最早的一种连接。还可以被称为普通连接或者自然连接,内连接是从结果表中删除与其他被连接表中没有匹配行的所有行,所以内连接可能会丢失信息。
等值连接:
select * from emp inner join dept on emp.deptno=dept.deptno
select * from emp,dept where emp.deptno=dept.deptno
不等值连接:
select * from emp inner join dept on emp.deptno!=dept.deptno
外连接
外连接分为三种:左外连接,右外连接,全外连接。对应SQL:LEFT/RIGHT/FULL OUTER JOIN。通常我们省略outer 这个关键字。写成:LEFT/RIGHT/FULL JOIN。
左外连接(left join): 是以左表的记录为基础的
select * from emp left join dept on emp.deptno=dept.deptno
右外连接(right join): 和left join的结果刚好相反,是以右表(BL)为基础的
select * from emp right join dept on emp.deptno=dept.deptno
全外连接(full join): 左表和右表都不做限制,所有的记录都显示,两表不足的地方用null 填充
select * from emp full join dept on emp.deptno=dept.deptno
交叉连接
交叉连接即笛卡儿乘积,是指两个关系中所有元组的任意组合。一般情况下,交叉查询是没有实际意义的。
select * from cross full join dept
6. 常用查询
like模糊查询
--查询姓名首字母为S开始的员工信息
select * from emp where ename like 'S%'
--查询姓名第三个字母为A的员工信息
select * from emp where ename like '__A%'
is null/is not null 查询
--查询没有奖金的雇员信息
select * from emp where comm is null
--查询有奖金的雇员信息
select * from emp where comm is not null
in查询
--查询雇员编号为7566、7499、7844的雇员信息
select * from emp where empno in(7566,7499,7844)
exists/not exists查询(效率高于in)
--查询有上级领导的雇员信息
select * from emp e where exists
(select * from emp where empno=e.mgr)
--查询没有上级领导的雇员信息
select * from emp e where not exists
(select * from emp where empno=e.mgr)
all查询
--查询比部门编号为20的所有雇员工资都高的雇员信息
select * from emp where sal > all(select sal from emp where deptno=20)
union合并不重复
select * from emp where comm is not null
union
select * from emp where sal>3000
union all合并重复
select * from emp where comm is not null
union all
select * from emp where sal>3000
7. 子查询
当一个查询是另一个查询的条件时,称之为子查询。子查询是一个 SELECT 语句,它嵌套在一个 SELECT、SELECT...INTO 语句、INSERT...INTO 语句、DELETE 语句、或 UPDATE 语句或嵌套在另一子查询中。
在CREATE TABLE语句中使用子查询
--创建表并拷贝数据
create table temp(id,name,sal) as select empno,ename,sal from emp
在INSERT语句中使用子查询
--当前表拷贝
insert into temp(id,name,sal) select * from temp
--从其他表指定字段拷贝
insert into temp(id,name,sal) select empno,ename,sal from emp
在DELETE语句中使用子查询
--删除SALES部门中的所有雇员
delete from emp where deptno in
(select deptno from dept where dname='SALES')
在UPDATE语句中使用子查询
--修改scott用户的工资和smith的工资一致
update emp set sal=(select sal from emp where ename='SMITH') where ename='SCOTT'
--修改black用户的工作,工资,奖金和scott一致
update emp set(job,sal,comm)=(select job,sal,comm from emp where ename='SCOTT') where ename='BLAKE'
在SELECT语句中使用子查询
--查询和ALLEN同一部门的员工信息
select * from emp where deptno in
(select deptno from emp where ename='ALLEN')
--查询工资大于部门平均工资的雇员信息
select * from emp e
(select avg(sal) asal,deptno from emp group by deptno) t
where e.deptno=t.deptno and e.sal>t.asal
六、 TCL语言
1. COMMIT
commit --提交事务
2. ROLLBACK
rollback to p1 --回滚到指定的保存点
rollback --回滚所有的保存点
3. SAVEPOINT
savepoint p1 --设置保存点
4. 只读事务
只读事务是指只允许执行查询的操作,而不允许执行任何其它dml操作的事务,它的作用是确保用户只能取得某时间点的数据。
set transaction read only
七、 oracle函数
1. 字符串函数
字符串函数是oracle中比较常用的,下面我们就介绍些常用的字符串函数:
concat:字符串连接函数,也可以使用’||’
--将职位和雇员名称显示在一列中
select concat(ename,concat('(',concat(job,')'))) from emp
select ename || '(' || job || ')' from emp
length:返回字符串的长度
--查询雇员名字长度为5个字符的信息
select * from emp where length(ename)=5
lower:将字符串转换成小写
--以小写方式显示雇员名
select lower(ename) from emp
upper:将字符串转换成大写
--以大写方式显示雇员名
select upper (ename) from emp
substr:截取字符串
--只显示雇员名的前3个字母
select substr(ename,0,3) from emp
replace:替换字符串
--将雇员的金额显示为*号
select ename,replace(sal,sal,’*’) from emp
instr:查找字符串
--查找雇员名含有’LA’字符的信息
select * from emp where instr(ename,’LA’)>0
2. 日期函数
sysdate:返回当前session所在时区的默认时间
--获取当前系统时间
select sysdate from dual
add_months:返回指定日期月份+n之后的值,n可以为任何整数
--查询当前系统月份+2的时间
select add_months(sysdate,2) from dual
--查询当前系统月份-2的时间
select add_months(sysdate,-2) from dual
last_day:返回指定时间所在月的最后一天
--获取当前系统月份的最后一天
select last_day(sysdate) from dual
months_between:返回月份差,结果可正可负,当然也有可能为0
--获取入职日期距离当前时间多少天
select months_between(sysdate, hiredate) from emp
trunc:为指定元素而截去的日期值
--获取当前系统年,其他默认
select trunc(sysdate,'yy') from dual
--查询81年2月份入职的雇员
select * from emp
where trunc(hiredate,'mm')=trunc(to_date('1981-02','yyyy-mm'),'mm')
3. 转换函数
to_char:将任意类型转换成字符串
--日期转换
select to_char(sysdate, 'yyyy-mm-dd hh24:mi:ss') from dual
--数字转换
select to_char(-100.789999999999,'L99G999D999') from dual
数字格式控制符
符号 描述
9 代表一位数字,如果当前位有数字,显示数字,否则不显示(小数部分仍然会强制显示)
0 强制显示该位,如果当前位有数字,显示数字,否则显示0
$ 增加美元符号显示
L 增加本地货币符号显示
. 小数点符号显示
, 千分位符号显示
to_date:将字符串转换成日期对象
--字符转换成日期
select to_date('2011-11-11 11:11:11', 'yyyy-mm-dd hh24:mi:ss') from dual
to_number:将字符转换成数字对象
--字符转换成数字对象
select to_number('209.976')*5 from dual
select to_number('209.976', '9G999D999')*5 from dual
4. 数学函数
abs:返回数字的绝对值
select abs(-1999) from dual
ceil:返回大于或等于n的最小的整数值
select ceil(2.48) from dual
floor:返回小于等于n的最大整数值
select floor(2.48) from dual
round:四舍五入
select round(2.48) from dual
select round(2.485,2) from dual
bin_to_num:二进制转换成十进制
select bin_to_num(1,0,0,1,0) from dual
第四章 锁
一、 概述
锁是实现数据库并发控制的一个非常重要的技术。当事务在对某个数据对象进行操作前,先向系统发出请求,对其加锁。加锁后事务就对该数据对象有了一定的控制,在该事务释放锁之前,其他的事务不能对此数据对象进行更新操作。
在数据库中有两种基本的锁类型:排它锁(Exclusive Locks,即X锁)和共享锁(Share Locks,即S锁)。当数据对象被加上排它锁时,其他的事务不能对它读取和修改。加了共享锁的数据对象可以被其他事务读取,但不能修改。
根据保护的对象不同,Oracle数据库锁可以分为以下几大类:
DML锁(data locks,数据锁),用于保护数据的完整性
DDL锁(dictionary locks,字典锁),用于保护数据库对象的结构,如表、索引等的结构定义
内部锁和闩(internal locks and latches),保护数据库的内部结构
二、 DML锁
DML锁的目的在于保证并发情况下的数据完整性,在Oracle数据库中,DML锁主要包括TM锁和TX锁,其中TM锁称为表级锁,TX锁称为事务锁或行级锁。
1. 行级锁
当事务执行数据库插入、更新、删除操作时,该事务自动获得操作表中操作行的排它锁
--不允许其他用户对雇员表的部门编号为20的数据进行修改
select * from emp where deptno=20 for update
--不允许其他用户对雇员表的所有数据进行修改
select * from emp for update
--如果已经被锁定,就不用等待
select * from emp for update nowait
--如果已经被锁定,更新的时候等待5秒
select * from emp for update wait 5
2. 锁模式
0(none)
1(null)
2(rs):行共享
3(rx):行排他
4(s):共享
5(srx):共享行排他
6(x):排他
数字越大,锁级别越高
3. 表级锁
当事务获得行锁后,此事务也将自动获得该行的表锁(行排他),以防止其它事务进行DDL语句影响记录行的更新
行共享锁(RS锁):允许用户进行任何操作,禁止排他锁
lock table emp in row share mode
行排他锁(RX锁):允许用户进行任何操作,禁止共享锁
lock table emp in row exclusive mode
共享锁(R锁):其他用户只能看,不能修改
lock table emp in share mode
排他锁(X锁):其他用户只能看,不能修改,不能加其他锁
lock table emp in exclusive mode
共享行排他(SRX锁):比行排他和共享锁级别高,不能添加共享锁
lock table emp in share row exclusive mode
4. 锁兼容性
S X RS RX SRX N/A
S Y N Y N N Y
X N N N N N Y
RS Y N Y Y Y Y
RX N N Y Y N Y
SRX N N Y N N Y
N/Y Y Y Y Y Y Y
5. 死锁
当两个事务需要一组有冲突的锁,而不能将事务继续下去的话,就出现死锁。
1) 用户A修改A表,事务不提交
2) 用户B修改B表,事务不提交
3) 用户A修改B表,阻塞
4) 用户B修改A表,阻塞
Oracle系统能自动发现死锁,并会自动选择工作量最少的事务进行撤销和释放所有锁
6. 悲观锁和乐观锁
数据的锁定分为两种方法,第一种叫做悲观锁,第二种叫做乐观锁
悲观锁:就是对数据的冲突采取一种悲观的态度,也就是说假设数据肯定会冲突,所以在数据开始读取的时候就把数据锁定住。
乐观锁:就是认为数据一般情况下不会造成冲突,所以在数据进行提交更新的时候,才会正式对数据的冲突与否进行检测,如果发现冲突了,则让用户返回错误的信息,让用户决定如何去做。
三、 DDL锁
1. 排它DDL锁
创建、修改、删除一个数据库对象的DDL语句获得操作对象的排它锁。
2. 共享DDL锁
需在数据库对象之间建立相互依赖关系的DDL语句通常需共享获得DDL锁
3. 分析锁
分析锁是一种独特的DDL锁类型,ORACLE使用它追踪共享池对象及它所引用数据库对象之间的依赖关系
四、 内部锁和闩
这是ORACLE中的一种特殊锁,用于顺序访问内部系统结构。当事务需向缓冲区写入信息时,为了使用此块内存区域,ORACLE首先必须取得这块内存区域的闩锁,才能向此块内存写入信息。
第五章 数据库对象
一、 概述
ORACLE数据库主要有如下数据库对象:
tablespace and datafile(表空间和数据文件)
table(表)
constraints(约束)
index(索引)
view(试图)
sequence(序列)
synonyms(同义词)
DB-link(数据库链路)
二、 表空间和数据文件
表空间是数据库的逻辑组成部分,从物理上讲,数据库数据是存放在数据文件中,从逻辑上讲数据库则是存放在表空间中,表空间是由一个或多个数据文件组成。
表空间
某一时刻只能属于一个数据库
由一个或多个数据文件组成
可进一步划分为逻辑存储
表空间主要分为两种
System表空间
随数据库创建
包含数据字典
包含system还原段
非system表空间
用于分开存储段
易于空间管理
控制分配给用户的空间量
数据文件
只能属于一个表空间和一个数据库
是方案对象数据的资料档案库
创建表空间
CREATE TABLESPACE tablespacename
[DATAFILE clause]
[MINIMUM EXTENT integer[k|m]]
[BLOCKSIZE integer[k]]
[LOGGING|NOLOGGING]
[DEFAULT storage_clause]
[ONLINE|OFFLINE]
[PERMANENT|TEMPORARY]
[extent_management_clause]
[segment_management_clause]
--创建本地管理表空间
create tablespace firstSpance
datafile 'e:/firstspance.dbf'size 100M
extent management local uniform size 256k
--修改文件大小
alter database datafile 'e:/firstspance.dbf' resize 110m
--删除表空间
drop tablespace firstSpance INCLUDING CONTENTS and datafiles
--使用数据库表空间
--创建用户指定表空间
create user guest identified by 123456
default tablespace firstSpance
--表中指定表空间
create table account(
accountid number(4),
accountName varchar2(20)
)tablespace firstSpance
--表空间脱机
alter tablespace firstSpance offline
--表空间联机
alter tablespace firstSpance online
--表空间只读,不能进行dml操作
alter tablespace firstSpance read only
三、 同义词
Oracle数据库中提供了同义词管理的功能。同义词是数据库方案对象的一个别名,经常用于简化对象访问和提高对象访问的安全性。Oracle同义词有两种类型,分别是公用Oracle同义词与私有Oracle同义词。
公有同义词
CREATE [OR REPLACE] PUBLIC SYNONYM sys_name FOR [SCHEMA.] object_name
创建(需拥有CREATE PUBLIC SYNONYM权限才可以创建)
--创建同义词
create public synonym syn_emp for scott.emp
--访问同义词
select * from syn_emp
drop public synonym syn_emp
私有同义词
CREATE [OR REPLACE] SYNONYM sys_name FOR [SCHEMA.] object_name
--创建同义词
create synonym syn_pri_emp for emp
--访问同义词
select * from syn_ pri _emp
drop public synonym syn_emp
四、 表分区
当表中的数据量不断增大,查询数据的速度就会变慢,应用程序的性能就会下降,这时就应该考虑对表进行分区。表进行分区后,逻辑上表仍然是一张完整的表,只是将表中的数据在物理上存放到多个表空间(物理文件上),这样查询数据时,不至于每次都扫描整张表。
优点:
改善查询性能:对分区对象的查询可以仅搜索自己关心的分区,提高检索速度。
增强可用性:如果表的某个分区出现故障,表在其他分区的数据仍然可用;
维护方便:如果表的某个分区出现故障,需要修复数据,只修复该分区即可;
均衡I/O:可以把不同的分区映射到磁盘以平衡I/O,改善整个系统性能。
使用场合
表的大小超过2GB
表中包含历史数据,新的数据被增加都新的分区中
常见分区方法:
范围 --- 8
Hash --- 8i
列表 --- 9i
组合 --- 8i
1. 范围分区
范围分区将数据基于范围映射到每一个分区,这个范围是你在创建分区时指定的分区键决定的。这种分区方式是最为常用的,并且分区键经常采用日期。
特点:
最早、最经典的分区算法
Range分区通过对分区字段值的范围进行分区
Range分区特别适合于按时间周期进行数据的存储。日、周、月、年等。
数据管理能力强(数据迁移、数据备份、数据交换)
范围分区的数据可能不均匀
范围分区与记录值相关,实施难度和可维护性相对较差
按值划分
CREATE TABLE book (
bookid NUMBER(5),
bookname VARCHAR2(30),
price NUMBER(8)
)PARTITION BY RANGE (price)--分区字段
PARTITION P1 VALUES LESS THAN (4) TABLESPACE system,
PARTITION P2 VALUES LESS THAN (8) TABLESPACE system,
PARTITION P3 VALUES LESS THAN (maxvalue) TABLESPACE system,
--MAXVALUE代表了一个不确定的值,这个值高于其它分区中的任何分区键的值
按日期划分
CREATE TABLE student (
stuno NUMBER(5),
stuname VARCHAR2(30),
birthday date
)PARTITION BY RANGE (birthday)--分区字段
PARTITION P1990 VALUES LESS THAN (to_date('1990-01-01','yyyy-mm-dd')) TABLESPACE system,
PARTITION P1991 VALUES LESS THAN (to_date('1991-01-01','yyyy-mm-dd')) TABLESPACE system
2. Hash分区(散列分区)
这类分区是在列值上使用散列算法,以确定将行放入哪个分区中。当列的值没有合适的条件时,建议使用散列分区。散列分区为通过指定分区编号来均匀分布数据的一种分区类型。如果你要使用hash分区,只需指定分区的数量即可。建议分区的数量采用2的n次方,这样可以使得各个分区间数据分布更加均匀。
基于分区字段的HASH值,自动将记录插入到指定分区。
分区数一般是2的幂
易于实施
总体性能最佳
适合于静态数据
HASH分区适合于数据的均匀存储
数据管理能力弱
HASH分区对数据值无法控制
CREATE TABLE classes (
clsno NUMBER(5),
clsname VARCHAR2(30)
)PARTITION BY HASH(clsno)--分区字段
PARTITION ph1 tablespace system,
PARTITION ph2 tablespace system
3. List分区(列表分区)
该分区的特点是某列的值只有几个,基于这样的特点我们可以采用列表分区。
List分区通过对分区字段的离散值进行分区
List分区是不排序的,而且分区之间也没有关联
List分区适合于对数据离散值进行控制
List分区只支持单个字段
List分区具有与range分区相似的优缺点
数据管理能力强
各分区的数据可能不均匀
CREATE TABLE users (
userid NUMBER(5),
username VARCHAR2(30),
province char(5)
)PARTITION BY list(province)--分区字段
PARTITION pl1 values('广东') tablespace system,
PARTITION pl2 values('江西') tablespace system,
PARTITION pl3 values('广西') tablespace system,
PARTITION pl4 values('湖南') tablespace system
4. 组合分区
常见的组合分区主要有范围散列分区和范围列表分区
既适合于历史数据,又适合于数据均匀分布
与范围分区一样提供高可用性和管理性
实现粒度更细的操作
组合范围列表分区
这种分区是基于范围分区和列表分区,表首先按某列进行范围分区,然后再按某列进行列表分区,分区之中的分区被称为子分区。
CREATE TABLE student (
stuno NUMBER(5),
stuname VARCHAR2(30),
birthday date,
province char(5)
)PARTITION BY RANGE (birthday) --主分区字段
subpartition BY LIST(province)--子分区字符
PARTITION P1990 VALUES LESS THAN(to_date('1990-01-01','yyyy-mm-dd')) TABLESPACE system
SUBPARTITION pl1 values('广东') tablespace system,
SUBPARTITION pl2 values('江西') tablespace system,
SUBPARTITION pl3 values('广西') tablespace system,
SUBPARTITION pl4 values('湖南') tablespace system
PARTITION P1991 VALUES LESS THAN(to_date('1991-01-01','yyyy-mm-dd')) TABLESPACE system
SUBPARTITION p21 values('广东') tablespace system,
SUBPARTITION p22 values('江西') tablespace system,
SUBPARTITION p23 values('广西') tablespace system,
SUBPARTITION p24 values('湖南') tablespace system
组合范围散列分区
这种分区是基于范围分区和散列分区,表首先按某列进行范围分区,然后再按某列进行散列分区。
CREATE TABLE student (
stuno NUMBER(5),
stuname VARCHAR2(30),
birthday date
)PARTITION BY RANGE(birthday) --主分区字段
SUBPARTITION BY HASH(stuno)--子分区字符
PARTITION P1990 VALUES LESS THAN(to_date('1990-01-01','yyyy-mm-dd')) TABLESPACE system
SUBPARTITION ph12 tablespace system,
SUBPARTITION ph13 tablespace system
PARTITION P1991 VALUES LESS THAN(to_date('1991-01-01','yyyy-mm-dd')) TABLESPACE system
SUBPARTITION ph21 tablespace system,
SUBPARTITION ph22 tablespace system
5. 表分区常用操作
添加分区
--添加主分区
alter table book add partition p4 values less than(maxvalue) tablespace system
--添加子分区
ALTER TABLE student MODIFY PARTITION P1990
ADD SUBPARTITION pl5 values('福建')
删除分区
--删除主分区
ALTER TABLE student DROP PARTITION P1990
--删除子分区
ALTER TABLE student DROP SUBPARTITION p15
重命名表分区
ALTER TABLE student RENAME PARTITION P21 TO P2
显示数据库所有分区表的信息
select * from DBA_PART_TABLES
显示当前用户所有分区表的信息
select * from USER_PART_TABLES
查询指定表分区数据
select * from users partition(pl2)--主分区
select * from users subpartition(phl2)--子分区
删除分区表一个分区的数据
alter table book truncate partition p11
第六章 视图
一、 概述
视图是基于一个表或多个表或视图的逻辑表,本身不包含数据,通过它可以对表里面的数据进行查询和修改。视图基于的表称为基表。视图是存储在数据字典里的一条select语句。 通过创建视图可以提取数据的逻辑上的集合或组合。
为什么使用视图
控制数据访问
简化查询
数据独立性
避免重复访问相同的数据
使用修改基表的最大好处是安全性,即保证那些能被任意人修改的列的安全性
Oracle中视图分类
关系视图
内嵌视图
对象视图
物化视图
二、 关系视图
关系视图是作为数据库对象存在的,创建之后也可以通过工具或数据字典来查看视图的相关信息。关系视图是4种视图中最简单,同时也最常用的视图。
CREATE [OR REPLACE] [FORCE|NOFORCE] VIEW view_name [(alias[, alias]...)]
AS subquery
[WITH CHECK OPTION [CONSTRAINT constraint]]
[WITH READ ONLY]
1. OR REPLACE:若所创建的试图已经存在,ORACLE自动重建该视图
2. FORCE:不管基表是否存在ORACLE都会自动创建该视图
3. NOFORCE:只有基表都存在ORACLE才会创建该视图
4. Alias:为视图产生的列定义的别名
5. subquery:一条完整的SELECT语句,可以在该语句中定义别名
6. WITH CHECK OPTION:插入或修改的数据行必须满足视图定义的约束
7. WITH READ ONLY:该视图上不能进行任何DML操作
create or replace view view_Account_dept
select * from emp where deptno=10
--只读视图
create or replace view view_Account_dept
select * from emp where deptno=10 order by sal
with read only
--约束视图
create or replace view view_Account_dept
select * from emp where deptno=10
with check option
查询视图
select * from emp where view_Account_dept
修改视图
通过OR REPLACE 重新创建同名视图即可
删除视图
DROP VIEW VIEW_NAME语句删除视图
视图上的DML 操作原则
1. 简单视图可以执行DML操作;
2. 在视图包含GROUP函数,GROUP BY子句,DISTINCT关键字时不能执行delete语句
3. 在视图包含GROUP函数,GROUP BY子句,DISTINCT关键字,ROWNUM为例,列定义为表达式时不能执行update语句
4. 在视图包含GROUP函数,GROUP BY子句,DISTINCT关键字,ROWNUM为例,列定义为表达式,表中非空的列子视图定义中未包括时不能执行insert语句
5. 可以使用WITH READ ONLY来屏蔽DML操作
三、 内嵌视图
内嵌视图是在from语句中的可以把表改成一个子查询。内嵌视图不属于任何用户,也不是对象,内嵌视图是子查询的一种。
Select * from
(select * from emp where deptno=10)
where sal>2000
四、 对象视图
对象类型在数据库编程中有许多好处,但有时,应用程序已经开发完成。为了迎合对象类型而重建数据表是不现实的。对象视图正是解决这一问题的优秀策略。
五、 物化视图
常用于数据库的容灾,不是传统意义上虚拟视图,是实体化视图,和表一样可以存储数据、查询数据。主备数据库数据同步通过物化视图实现,主备数据库通过data link连接,在主备数据库物化视图进行数据复制。当主数据库垮掉时,备数据库接管,实现容灾。
create materialized view materialized_view_name
build [immediate|deferred] --1.创建方式
refresh [complete|fast|force|never] --2.物化视图刷新方式
on [commit|demand] --3.刷新触发方式
start with (start_date) --4.开始时间
next (interval_date) --5.间隔时间
with [primary key|rowid] --默认 primary key
ENABLE QUERY REWRITE --7.是否启用查询重写
as --8.关键字
select statement; --9.基表选取数据的select语句
1. 创建方式
immediate(默认):立即
deferred:延迟,至第一次refresh时,才生效
2. 物化视图刷新方式
force(默认):如果可以快速刷新,就执行快速刷新,否则,执行完全刷新
complete:完全刷新,即刷新时更新全部数据,包括视图中已经生成的原有数据
fast:快速刷新,只刷新增量部分。前提是,需要在基表上创建物化视图日志。该日志记录基表数据变化情况,所以才能实现增量刷新
never:从不刷新
3. 刷新触发方式
on commit:基表有commit动作时,刷新视图,不能跨库执行(因为不知道别的库的提交动作)
on demand,在需要时刷新,根据后面设定的起始时间和时间间隔进行刷新,或者手动调用dbms_mview包中的过程刷新时再执行刷新。
4. 开始时间和间隔时间
4和5即开始刷新时间和下次刷新的时间间隔。如:start with sysdate next sysdate+1/1440表示马上开始,刷新间隔为1分钟。(与 on commit选项冲突)
5. 创建模式
primary key(默认):基于基表的主键创建
rowed:不能对基表执行分组函数、多表连结等需要把多个rowid合成一行的操作
6. 是否启用查询重写
如果设置了初始化参数query_rewrite_enabled=true则默认就会启用查询重写。但是,数据库默认该参数为false。并且,不是什么时候都应该启用查询重写。所以,该参数应该设置为false,而在创建特定物化视图时,根据需要开启该功能。
7. 注意
如果选择使用了上面第4,5选项,则不支持查询重写功能(原因很简单,所谓重写,就是将对基表的查询定位到了物化视图上,而4、5选项会造成物化视图上部分数据延迟,所以,不能重写)。
--创建增量刷新的物化视图时应先创建存储的日志空间
--在scott.emp表中创建物化视图日志
create materialized view log on emp
tablespace users with rowid;
--开始创建物化视图
--方式一
create materialized view mv_emp
tablespace users --指定表空间
build immediate --创建视图时即生成数据
refresh fast --基于增量刷新
on commit --数据DML操作提交就刷新
with rowid --基于ROWID刷新
as select * from emp
--方式二
create materialized view mv_emp2
tablespace users --指定表空间
refresh fast --基于增量刷新
start with sysdate --创建视图时即生成数据
next sysdate+1/1440 /*每隔一分钟刷新一次*/
with rowid --基于ROWID刷新
as select * from emp
--删除物化视图日志
drop materialized view mv_emp
第七章 索引
一、 概述
索引是建立在表上的可选对象,设计索引的目的是为了提高查询的速度。但同时索引也会增加系统的负担,进行影响系统的性能。
索引一旦建立后,当在表上进行DML操作时,Oracle会自动维护索引,并决定何时使用索引。
索引的使用对用户是透明的,用户不需要在执行SQL语句时指定使用哪个索引及如何使用索引,也就是说,无论表上是否创建有索引,SQL语句的用法不变。用户在进行操作时,不需要考虑索引的存在,索引只与系统性能相关。
索引的原理
当在一个没有创建索引的表中查询符合某个条件的记录时,DBMS会顺序地逐条读取每个记录与查询条件进行匹配,这种方式称为全表扫描。全表扫描方式需要遍历整个表,效率很低。
索引的类型
Oracle支持多种类型的索引,可以按列的多少、索引值是否唯一和索引数据的组织形式对索引进行分类,以满足各种表和查询条件的要求。
单列索引和复合索引
B树索引
位图索引
函数索引
创建索引
CREATE [UNIQUE] | [BITMAP] INDEX index_name
ON table_name([column1 [ASC|DESC],column2
[ASC|DESC],…] | [express])
[TABLESPACE tablespace_name]
[PCTFREE n1]
[STORAGE (INITIAL n2)]
[NOLOGGING]
[NOLINE]
[NOSORT]
UNIQUE:表示唯一索引,默认情况下,不使用该选项。
BITMAP:表示创建位图索引,默认情况下,不使用该选项。
PCTFREE:指定索引在数据块中的空闲空间。对于经常插入数据的表,应该为表中索引指定一个较大的空闲空间。
NOLOGGING:表示在创建索引的过程中不产生任何重做日志信息。默认情况下,不使用该选项。
ONLINE:表示在创建或重建索引时,允许对表进行DML操作。默认情况下,不使用该选项。
NOSORT:默认情况下,不使用该选项。则Oracle在创建索引时对表中记录进行排序。如果表中数据已经是按该索引顺序排列的,则可以使用该选项。
二、 单列索引和复合索引
一个索引可以由一个或多个列组成。基于单个列所创建的索引称为单列索引,基于两列或多列所创建的索引称为多列索引。
三、 B树索引
B树索引是Oracle数据库中最常用的一种索引。当使用CREATE INDEX语句创建索引时,默认创建的索引就是B树索引。B树索引就是一棵二叉树,它由根、分支节点和叶子节点三部分构成。叶子节点包含索引列和指向表中每个匹配行的ROWID值。叶子节点是一个双向链表,因此可以对其进行任何方面的范围扫描。
B树索引中所有叶子节点都具有相同的深度,所以不管查询条件如何,查询速度基本相同。另外,B树索引能够适应各种查询条件,包括精确查询、模糊查询和比较查询。
--创建B树索引,属于单列索引
create index idx_emp_job on emp(job)
--创建B树索引,属于复合索引
create index idx_emp_nameorsal on emp(ename,sal)
--创建唯一的B树索引,属于单列索引
create unique index idx_emp_ename on emp(ename)
--删除索引
drop index idx_emp_job
drop index idx_emp_nameorsal
drop index idx_emp_ename
--如果表已存在大量的数据,需要规划索引段
create index idx_emp_nameorsal on emp(ename,sal)
pctfree 30 tablespace system
四、 位图索引
在B树索引中,保存的是经排序过的索引列及其对应的ROWID值。但是对于一些基数很小的列来说,这样做并不能显著提高查询的速度。所谓基数,是指某个列可能拥有的不重复值的个数。比如性别列的基数为2(只有男和女)。
因此,对于象性别、婚姻状况、政治面貌等只具有几个固定值的字段而言,如果要建立索引,应该建立位图索引,而不是默认的B树索引。
--创建位图索引,单列索引
create bitmap index idx_bm_job on emp(job)
--创建位图索引,复合索引
create bitmap index idx_bm_jobordeptno on emp(job,deptno)
--删除位图索引
drop index idx_bm_job
drop index idx_bm_jobordeptno
五、 函数索引
函数索引既可以使用B树索引,也可以使用位图索引,可以根据函数或表达式的结果的基数大小来进行选择,当函数或表达式的结果不确定时采用B树索引,当函数或表达式的结果是固定的几个值时采用位图索引。
--合并索引
alter index idx_emp_ename COALESCE
六、 并和重建索引
表在使用一段时间后,由于用户不断对其进行更新操作,而每次对表的更新必然伴随着索引的改变,因此,在索引中会产生大量的碎片,从而降低索引的使用效率。有两种方法可以清理碎片:合并索引和重建索引。
合并索引就是将B树叶子节点中的存储碎片合并在一起,从而提高存取效率,但这种合并并不会改变索引的物理组织结构。
--创建B树类型的函数索引
create index idx_fun_emp_hiredate on emp(to_char(hiredate,'yyyy-mm-dd'))
--创建位图类型的函数索引
create index idx_fun_emp_job on emp(upper(job))
重建索引相当于删除原来的索引,然后再创建一个新的索引,因此,CREAT INDEX语句中的选项同样适用于重建索引。如果在索引列上频繁进行UPDATE和DELETE操作,为了提高空间的利用率,应该定期重建索引。
七、 管理索引的原则
使用索引的目的是为了提高系统的效率,但同时它也会增加系统的负担,进行影响系统的性能,因为系统必须在进行DML操作后维护索引数据。
在新的SQL标准中并不推荐使用索引,而是建议在创建表的时候用主键替代。因此,为了防止使用索引后反而降低系统的性能,应该遵循一些基本的原则:
1. 小表不需要建立索引。
2. 对于大表而言,如果经常查询的记录数目少于表中总记录数目的15%时,可以创建索引。这个比例并不绝对,它与全表扫描速度成反比。
3. 对于大部分列值不重复的列可建立索引。
4. 对于基数大的列,适合建立B树索引,而对于基数小的列适合建立位图索引。
5. 对于列中有许多空值,但经常查询所有的非空值记录的列,应该建立索引。
6. LONG和LONG RAW列不能创建索引。
7. 经常进行连接查询的列上应该创建索引。
8. 在使用CREATE INDEX语句创建查询时,将最常查询的列放在其他列前面。
9. 维护索引需要开销,特别时对表进行插入和删除操作时,因此要限制表中索引的数量。对于主要用于读的表,则索引多就有好处,但是,一个表如果经常被更改,则索引应少点。
10. 在表中插入数据后创建索引。如果在装载数据之前创建了索引,那么当插入每行时,Oracle都必须更改每个索引。
八、 ROWID和ROWNUM
1. ROWID
rowid是一个伪列,是用来确保表中行的唯一性,它并不能指示出行的物理位置,但可以用来定位行。rowid是存储在索引中的一组既定的值(当行确定后)。我们可以像表中普通的列一样将它选出来, 利用rowid是访问表中一行的最快方式。rowid的是基于64位编码的18个字符显示(数据对象编号(6)+文件编号(3) +块编号(6)+行编号(3)=18位)
select rowid from emp
ROWID的使用
--快速删除重复的记录
delete from temp t where rowid not in(
select max(rowid) from temp
where t.id=id and t.name=name and t.sal = sal
2. ROWNUM
ROWNUM是一个序列,是oracle数据库从数据文件或缓冲区中读取数据的顺序。它取得第一条记录则rownum值为1,第二条为2,依次类推。
select rownum,emp.* from emp
ROWID的使用
--取前3条记录
select * from emp where rownum<=3--方式一
select * from emp where rownum!=4--方式二
select * from emp where empno not in(
select empno from emp where rownum<5--方式一
) and rownum <4
第八章 PL/SQL编程
一、 介绍
PL/SQL是oracle在标准sql语言上的扩展,PL/SQL不仅允许嵌入sql语言,还可以定义变量和常量,允许使用例外处理各种错误,这样使它的功能变得更加强大。
PL/SQL也是一种语言,叫做过程化sql语言(procedural language/sql),通过此语言可以实现复杂功能或者复杂的计算。
1. 提高应用程序的运行性能
2. 模块化的设计思想
3. 减少网络传输量
4. 提高安全性
1. 可移植性差
2. 违反MVC设计模式
3. 无法进行面向对象编程
4. 无法做成通用的业务逻辑框架
5. 代码可读性差,相当难维护
二、 PL/SQL基础
1. 编写规范
1) 注释
--单行注释
/*块注释*/
2) 标识符的命名规范
定义变量:建议用v_作为前缀v_price
定义常量:建议用c_作为前缀c_pi
定义游标:建议用_cursor作为后缀emp_cursor
定义例外:建议用e_作为前缀e_error
2. 块结构
PL/SQL块由三个部分组成:定义部分、执行部分、例外处理部分
Declare
定义部分(可选):定义常量、变量、游标、例外,复杂数据类型
begin
执行部分(必须):要执行的PL/SQL语句和SQL语句
exception
/*例外部分(可选):处理运行各种错误*/
案例一 :只定义执行部分
begin
dbms_output是oracle提供的包(类似java开发包)
该包包含一些过程,put_line就是其一个过程
dbms_output.put_line('HELLO WORLD'); --控制台输出
案例二 :定义声明部分和执行部分
declare
--声明变量
v_name varchar2(20);
v_sal number(7,2);
begin
--执行查询
select ename,sal into v_name,v_sal
from emp where rownum=1;
--控制台输出
dbms_output.put_line('用户名:' || v_name);
dbms_output.put_line('工资:' || v_sal);
案例三 :定义声明部分、执行部分和例外部分
declare
--声明变量
v_name varchar2(20);
v_sal number(7,2);
begin
--执行查询,条件中的&表示从控制接受数据
select ename,sal into v_name,v_sal
from emp where empno=&no;
--控制台输出
dbms_output.put_line('用户名:' || v_name);
dbms_output.put_line('工资:' || v_sal);
exception
--例外处理(no_data_found)
when no_data_found then
dbms_output.put_line('执行查询没有结果');
3. 预定义例外
1) case_not_found预定义例外
在开发pl/sql块中编写case语句时,如果在when子句中没有包含必须的条件分支,就会触发case_not_found例外。
2) cursor_already_open预定义例外
当重新打开已经打开的游标时,会隐含的触发cursor_already_open例外。
3) dup_val_on_index预定义例外
在唯一索引所对应的列上插入重复的值时,会隐含的触发例外
4) invalid_cursorn预定义例外
当试图在不合法的游标上执行操作时,会触发该例外
5) invalid_number预定义例外
当输入的数据有误时,会触发该例外
6) no_data_found预定义例外
当执行select into没有返回行,就会触发该例外
7) too_many_rows预定义例外
当执行select into语句时,如果返回超过了一行,则会触发该例外
8) zero_divide预定义例外
当执行2/0语句时,则会触发该例外
9) value_error预定义例外
当在执行赋值操作时,如果变量的长度不足以容纳实际数据,则会触发该例外value_error
10) others
4. 变量类型分类
在编写PL/SQL时,可以定义变量和常量,常用的类型主要有:
标量类型(scalar)
复合类型(composite)
参照类型(reference)
lob(large object)
5. 标量类型:常用类型
declare
--定义一个变长字符串
v_name varchar2(20);
--定义小数,并赋值
v_sal number(7,2) :=9.8;
--定义整数
v_num number(4);
--定义日期
v_birthday date;
--定义布尔类型,不能为空,初始值为false
v_flg boolean not null default false;
--使用%type类型
v_job emp.job%type;
begin
v_flg := true;
v_birthday :=sysdate;
dbms_output.put_line('当前时间:' || v_birthday);
6. 复合类型:可以存放多个值。主要包括PL/SQL记录、PL/SQL表、嵌入表和varray这四种类型
记录类型:类似于c中的结构体
declare
--定义记录类型
type emp_record_type is record(
empno emp.empno%type,
ename emp.ename%type,
sal emp.sal%type
--定义变量引用记录类型
v_record emp_record_type;
begin
--使用记录类型
select empno,ename,sal into v_record from emp where rownum=1;
--控制台输出
dbms_output.put_line('雇员编号:' || v_record.empno);
dbms_output.put_line('雇员姓名:' || v_record.ename);
dbms_output.put_line('雇员工资:' || v_record.sal);
表类型:类似于java语言中的数组
declare
--声明表类型
type emp_table_type is table of varchar2(20)
index by PLS_INTEGER;--表示表按整数来排序
v_enames emp_table_type;--定义变量引用表类型
begin
select ename into v_enames(0) from emp where rownum=1;
select ename into v_enames(1) from emp where empno=7499;
select ename into v_enames(2) from emp where empno=7698;
dbms_output.put_line('下标0:' || v_enames(0));
dbms_output.put_line('下标1:' || v_enames(1));
dbms_output.put_line('下标2:' || v_enames(2));
varray类型:可变长数组
declare
--定义varray类型
type varray_list is varray(20) of number(4);
--定义变量引用varray类型
v_list varray_list:=varray_list(7369,7499,7566);
begin
--for i in v_list.first..v_list.last
for i in 1..v_list.count
dbms_output.put_line(v_list(i));
end loop;
PL/SQL集合方法
1) exists():用于确定特定集合元素是否存在
2) count:用于返回集合变量的元素总个数
3) limit:用于返回varray变量所允许的最大元素个数
4) first:用于返回集合变量中的一个元素的下标
5) last:用于返回集合变量中最后一个元素的下标
6) prior():返回当前元素前一个元素的下标
7) next():返回当前元素后一个元素的下标
8) extend:为集合变量添加元素,此方法适合用于嵌套表和varray
9) trim:从集合变量尾部删除元素,此方法适用于嵌套表和varray
10) delete:从集合变量中删除特定的元素,此方法适用于嵌套表和index-by表
7. 参照类型:类似c语言中的指针,oracle的游标
三、 PL/SQL控制语句
1. 条件分支语句
1) if—then
declare
--声明变量
v_empno emp.empno%type;
v_sal emp.sal%type;
begin
--根据雇员编号查询工资
select empno,sal into v_empno,v_sal from emp where empno=&no;
--如果工资小于2000就加100
if v_sal<2000
--工资加100
update emp set sal = sal+100 where empno=v_empno;
commit;
end if;
2) if—then—else
declare
--声明变量
v_loginname varchar2(10);
v_password varchar2(10);
begin
--从控制台接收数据
v_loginname := '&ln';
v_password := '&pw';
if v_loginname = 'admin' and v_password = '123456'
dbms_output.put_line('用户登录成功!');
dbms_output.put_line('用户登录失败!');
end if;
3) if—then—elsif—else
declare
--声明变量
v_empno emp.empno%type;
v_job emp.job%type;
begin
--根据雇员编号查询职位
select empno,job into v_empno,v_job from emp where empno=&no;
/*如果雇员所属职位是manager工资加1000
职位是salesman工资加500
其他职位加200
if v_job = 'MANAGER' then
--MANAGER职位工资加1000
update emp set sal = sal+1000 where empno=v_empno;
elsif v_job = 'SALESMAN' then
--SALESMAN职位工资加500
update emp set sal = sal+500 where empno=v_empno;
--其他职位工资加200
update emp set sal = sal+200 where empno=v_empno;
end if;
commit;
4) case
declare
--声明变量
v_mark number(4);
v_outstr varchar2(40);
begin
--从控制台接收成绩
v_mark := &m;
when v_mark=90 then
v_outstr := '优秀';
when v_mark=80 then
v_outstr := '良好';
when v_mark=70 then
v_outstr := '中等';
when v_mark=60 then
v_outstr := '及格';
when v_mark=0 then
v_outstr := '不及格';
v_outstr := '成绩输入有误';
end case;
--控制台输出
dbms_output.put_line(v_outstr);
2. 循环语句
1) loop
LOOP 要执行的语句;
EXIT WHEN /*条件满足,退出循环语句*/
END LOOP;
其中:EXIT WHEN 子句是必须的,否则循环将无法停止。
declare
v_num number(4):=1;
begin
--从控制台接收数据并插入到account表中
insert into account values(v_num,'&name');
exit when v_num =10;
v_num :=v_num+1;
end loop;
2) while
WHILE LOOP要执行的语句;END LOOP;
循环语句执行的顺序是先判断的真假,如果为真则循环执行,否则退出循环
在WHILE循环语
1.MCS—51单片机引脚信号中,信号名称带上划线的表示该信号
或 有效。
2.通过堆栈操作实现子程序调用,首先要把 的内容入栈,以进行断点保护。调用返回时再进行出栈操作,把保护的断点送回 。
3.某程序初始化时使(SP)=40H,则此堆栈地址范围为 ,若使(SP)=50H,则此堆栈深度为 。
4.在相对寻址方式中,“相对”两字是指相对于 ,寻址得到的结果是 。在寄存器寻址方式中,指令中指定寄存器的内容就是 。在变址寻址方式中,以 作变址寄存器,以 或 作基址寄存器。
5.假定累加器(A)=49H,执行指令:
201AH: MOVC A,@A+PC
后,送入A的是程序存储器 单元的内容。
6.若(DPTR)=5306H,(A)=49H,执行下列指令:
MOVC A,@A+DPTR
后,送入A的是程序存储器 单元的内容。
7.假定(SP)=45H,(ACC)=46H,(B)=47H,执行下列指令:
PUSH ACC
PUSH B
后,(SP)= ,(46H)= ,(47H)= 。
8.假定(SP)=47H,(46H)=46H,(47H)=47H。执行下列指令:
POP DPH
POP DPL
后,(DPTR)= ,(SP)= 。
9.若(A)=56H,(R0)=56H,(56H)=56H。执行指令:
ADD A,@R0
后,(A)= ,(CY)= ,(AC)= ,(OV)= 。
10.若(A)=0FFH,(R0)=46H,(46H)=0FFH,(CY)=1。
执行指令:
ADDC A,@R0
后,(A)= ,(CY)= ,(AC)= ,(OV)= 。
11.假定(A)=45H,(B)=67H。执行指令:
MUL AB
后,寄存器(B)= ,累加器(A)= ,(CY)= ,(OV)= 。
12.假定(A)=0FCH,(B)=35H。执行指令:
DIV AB
后,累加器(A)= ,寄存器(B)= ,(CY)= ,(OV)= 。
13.执行如下指令序列:
MOV C,P1.0
ANL C,P1.1
OR C,/P1.2
MOV P1.3,C
后,所实现的逻辑运算式为 。
14.假定addr11=00100011001B,标号MN的地址为2099H。执行指令:
MN:AJMP addr11
后,程序转移到地址 去执行。
15.假定标号MN的地址为2000H,标号XY值为2022H。应执行指令:
MN:SJMP XY
该指令的相对偏移量为 。
16.累加器A中存放着一个其值小于63的8位无符号数,CY清“0”后执行指令:
RLC A
RLC A
则A中数变为原来的 倍。
17.在MCS—51单片机系统中,采用的编址方式是 。MCS—51可提供 和 两种存储器,其编址方式为 ,扩展后其最大存储空间分别为 和 。对80C51而言,片内ROM和片外ROM的编址方式为 ,片外ROM的地址从 开始;片内RAM和片外RAM的编址方式为 ,片外RAM的地址从 开始。
18.为实现内外程序存储器的衔接,应使用 信号进行控制,对8031, EA= ,CPU对 进行寻址;对80C51, EA=1,CPU对 寻址。
19.访问内部RAM使用 指令,访问外部RAM使用 指令,访问内部ROM使用 指令,访问外部ROM使用 指令。
20.当计数器产生记数溢出时,定时器/记数器的TF0(TF1)位= 。对记数溢出的处理,在中断方式时,该位作为 位使用;在查询方式时,该位作为 位使用。
21.在定时器工作方式0下,计数器的宽度为 位,其记数范围为 ,如果系统晶振频率为6MHZ,则最大定时时间为 。
22.利用定时器/计数器产生中断时,应把定时器/计数器设置成 工作状态,当计数器设置成方式0时,记数初值应为 ;设置成方式1时,记数初值应为 ;设置成方式2或方式3时,记数初值应为 。
23.对单片机而言,连接到数据总线上的输出口应具有 功能,连接到数据总线上的输入口应具有 功能。
24.在多位LED显示器接口电路的控制信号中,必不可少的是 控信号和 控信号。
25.与8255比较,8155的功能有所增强,主要表现在8155具有 单元的 和一个 位的 。
26.单片机实现数据通讯时,其数据传送方式有 和 两种。串行数据传送方式分为 和 两种。
27.专用寄存器“串行发送数据缓冲寄存器”,实际上是 寄存器和 寄存器的总称。
28.在串行通讯中,若发送方的波特率为1200bps,则接收方的波特率为 。
29.D/A转换电路之前必须设置数据锁存器,这是因为
30.对于由8031构成的单片机应用系统,EA脚应接 ,中断响应并自动生成长调用指令LCALL后,应转向 去执行中断服务程序。
1.80C51与8031的区别在于
内部ROM的容量不同
内部RAM的容量不同
内部ROM的类型不同
80C51使用EEPROM,而8031使用EPROM
2.PC的值是
A.当前指令前一条指令的地址 B.当前正在执行指令的地址
C.下一条指令的地址 D.控制器中指令寄存器的地址
3.假定(SP)=37H,在进行子程序调用时把累加器A和断点地址进栈保护后,SP的值为
A.3AH B.38H C.39H D.40H
4.在80C51中,可使用的堆栈最大深度为
A.80个单元 B.32个单元 C.128个单元 D.8个单元
5.在相对寻址方式中,寻址的结果体现在
A.PC中 B.累加器A中
C.DPTR中 D.某个存储单元中
6.在寄存器间接寻址方式中,指定寄存器中存放的是
A.操作数 B.操作数地址
C.转移地址 D.地址偏移量
7.执行返回指令时,返回的断点是
A.调用指令的首地址 B.调用指令的末地址
C.返回指令的末地址 D.调用指令下一条指令的首地址
8.可以为访问程序存储器提供或构成地址的有
A.只有程序计数器PC
B.只有PC和累加器A
C.只有PC、A和数据指针DPTR
D.PC、A、DPTR和堆栈指针SP
9.若原来工作寄存器0组为当前寄存器组,现要改2组为当前寄存器组,不能使用指令
A.SETB PSW.3 B.SETB D0H.4
C.MOV D0H,#10H D.CPL PSW.4
10.执行以下程序段
MOV SP,#40H
MOV B,#30H
MOV A,#20H
PUSH B
PUSH ACC
POP B
POP ACC
后,B和A的内容分别为
A.20H,30H B.30H,20H
C.40H,30H D.40H,20H
11.执行以下程序段
MOV R0,#70H
MOV A,R0
RL A
MOV R1,A
RL A
RL A
ADD A,R1
MOV @R0,A
后,实现的功能是
A.把立即数70H循环左移3次 B.把立即数70H×10
C.把70H单元的内容循环左移3次 D.把70H单元的内容×10
12.下列叙述中,不属于单片机存储器系统特点的是
A.扩展程序存储器与片内程序存储器存储空间重叠
B.扩展数据存储器与片内数据存储器存储空间重叠
C.程序和数据两种类型的存储器同时存在
D.芯片内外存储器同时存在
13.如在系统中只扩展两片Intel2764,其地址范围分别为0000H~1FFFH、8000H~9FFFH,除应使用P0口的8条口线外,至少还应使用P2口的口线
A.6条 B.7条 C.5条 D.8条
14.下列有关MCS—51中断优先级控制的叙述中,错误的是
A.低优先级不能中断高优先级,但高优先级能中断低优先级
B.同级中断不能嵌套
C.同级中断请求按时间的先后顺序响应
D.同级中断按CPU查询次序响应中断请求
15.执行中断返回指令,要从堆栈弹出断点地址,以便去执行被中断了的主程序。从堆栈弹出的断点地址送给
A.A B.CY C.PC D.DPTR
16.中断查询确认后,在下列各种单片机运行情况中,能立即进行响应的是
A.当前指令是ORL A,Rn指令
B.当前正在执行RETI指令
C.当前指令是MUL指令,且正处于取指令机器周期
D.当前正在进行1优先级中断处理
下列功能中不是由I/O接口实现的是
A.数据缓冲和锁存 B.数据暂存
C.速度协调 D.数据转换
18.为给扫描法工作的键盘提供接口电路,在接口电路中需要
A.一个输入口 B.一个输出口
C.一个输入口和一个输出口 D.两个输入口
19.下列理由中,能说明MCS—51的I/O编址是统一编址方式而非独立编址方式的理由是
用存储器指令进行I/O操作
有专用的I/O指令
有区分存储器和I/O的控制信号
I/O和存储器的地址可以重叠
20.把8155的A2、A1、A0分别与80C51的P0.2、P0.1、P0.0连接,则8155的PA、PB、PC口的地址可能是
A.××00H~××03H B.00××H~03××H
C.××01H~××03H D.××00H~××02H
21.调制解调器(MODEM)的功能是
A.串行数据与并行数据的转换
B.数字信号与模拟信号的转换
C.电平信号与频率信号的转换
D.基带传送方式与频带传送方式的转换
22.通过串行口发送数据时,在程序中应使用
A.MOVX SBUF,A B.MOVC SUBF,A
C.MOV SUBF,A D.MOV A,SUBF
23.通过串行口接收数据时,在程序中应使用
A.MOVX A,SBUF B.MOVC A,SUBF
C.MOV SUBF,A D.MOV A,SUBF
24.在多机通讯中,有关第9数据位的说明中,正确的是
A.接收到的第9数据位送SCON寄存器的TB8中保存
B.帧发送时使用指令把TB8位的状态送入移位寄存器的第9位
C.发送的第9数据位内容在SCON寄存器的RB8中预先准备好
D.帧发送时使用指令把TB8位的状态送入发送SBUF中
25.在使用多片DAC0832进行D/A转换,并分时输入数据的应用中,它的两级数据锁存结构可以
A.提高D/A转换速度 B.保证各模拟电压能同时输出
C.提高D/A转换精度 D.增加可靠性
26.8279芯片与80C51接口电路时,其内部时钟信号是由外部输入的时钟信号经过分频产生的。如80C51的fosc=6MHz,8279为取得100KHz的内部时钟信号,则其定时值为
A.20D B.10D C.20H D.10H
分析程序后,回答问题。
若(A)=80H,R0=17H,(17H)=34H,执行下段程序后,(A)=?
ANL A,#17H
ORL 17H,A
XRL A,@R0
CPL A
写出程序执行后有关寄存器和RAM中有关单元的内容:
MOV 30H,#A4H
MOV A,#0D6H
MOV R0,#30H
MOV R2,#47H
ANL A,R2
ORL A,R0
SWAP A
CPL A
XRL A,#0FFH
ORL 30H,A
下列程序执行后,(SP)=? (A)=? (B)=?
ORG 2000H
MOV SP,#40H
MOV A,#30H
LCALL 2500H
ADD A,#10H
MOV B,A
SJMP $
ORG 2500H
MOV DPTR,#200AH
PUSH DPL
PUSH DPH
在程序存储器中,数据表格为:
1010H:02H
1011H:04H
1012H:06H
1013H:08H
1000H:MOV A,#0DH
1002H:MOVC A,@A+PC
1003H:MOV R0,A
问结果:(A)=? (R0)=? (PC)=?
在程序存储器中,数据表格为:
7010H:02H
7011H:04H
7012H:06H
7013H:08H
1004H:MOV A,#10H
1006H:MOV DPTR,#7000H
1009H:MOVC A,@A+DPTR
问结果:(A)=? (PC)=?
程序如下:
CLR RS1
CLR RS0
MOV A,#38H
MOV R0,A
MOV 29H,R0
SETB RS0
MOV C,RS0
MOV R1,A
MOV 26H,A
MOV 28H,C
ADDC A,26H
试问:(1)区分哪些是位操作指令?哪些是字节操作指令?
(2)写出程序执行后有关寄存器和RAM中有关单元的内容。
设单片机采用6MHz晶振,计算如下一段程序的执行时间,并说明这段程序的作用。
MOV R0,#20H
MOV R3,#05H
MOV A,@ R0
CPL A
ADD A,#01H
MOV @ R0,A
NEXT: INC R0,
MOV A,@ R0
CPL A
ADDC A,#00H
MOV @ R0,A
DJNZ R3,NEXT
SJMP $
用80C51单片机的P1端口作输出,经驱动电路接8只发光二极管,如图,输出位是“1”时,发光二极管点亮,输出“0”时为暗。试分析下述程序执行过程及发光二极管点亮的工作规律。
LP:MOV P1,#81H
LCALL DELAY
MOV P1,#42H
LCALL DELAY
MOV P1,#24H
LCALL DELAY
MOV P1,#18H
LCALL DELAY
MOV P1,#24H
LCALL DELAY
MOV P1,#42H
LCALL DELAY
SJMP LP
DELAY:MOV R2,#0FAH
L1:MOV R3,#0FAH
L2:DJNZ R3,L2
DJNZ R2,L1
把在R4和R5中的两字节数取补(高位在R4中):
CLR C
MOV A,R5
CPL A
INC A
MOV R5,A
MOV A,R4
CPL A
ADDC A,#00H
MOV R4,A
SJMP $
单片机MCS—51系列产品80C51/87C51/80C31三种单片机的区别是什么?如何选用?
试说明MCS—51单片机内部程序存储器中6个特殊功能单元(5个中断源和1个复位)的作用及在程序编制中如何使用?
内部RAM低128单元划分为哪3个主要部分?说明各部分的使用特点。
堆栈有哪些功能?堆栈指示器(SP)的作用是什么?在程序设计时,为什么还要对SP重新赋值?如果CPU在操作中要使用两组工作寄存器,你认为SP的初值应为多大?
开机复位后,CPU使用的是哪组工作寄存器?它们的地址是什么?CPU如何确定和改变当前工作寄存器组?
MCS—51单片机运行出错或程序进入死循环,如何摆脱困境?
在MCS—51单片机系统中,外接程序存储器和数据存储器共用16位地址线和8位数据线,为什么不会发生冲突?
一个定时器的定时时间有限,如何实现两个定时器的串行定时,以满足较长定时时间的要求?
使用一个定时器,如何通过软硬件结合的方法,实现较长时间的定时?
10.MCS—51单片机属哪一种I/O编址方式?有哪些特点可以证明。
11.多片D/A转换器为什么必须采用双缓冲接口方式?
12.说明利用MCS-51单片机的串行口进行多机通信的原理,应特别指出第9数据位在串行通信中的作用及在多机通信时必须采用主从式的原因。
单片机的fosc=12MHZ,要求用T0定时150μs,分别计算采用定时方式0、定时方式1和定时方式2时的定时初值。
单片机的fosc=6MHZ,问定时器处于不同工作方式时,最大定时范围分别是多少?
程序实现c=a2+b2。设a、b均小于10,a存在31H单元,b存在32H单元,把c存入33H单元。
软件延时方法实现变调振荡报警:用P1.0端口输出1KHz和2KHz的变调音频,每隔1s交替变换一次。
使用定时器中断方法设计一个秒闪电路,让LED显示器每秒钟有400ms点亮。假定晶振频率为6MHz,画接口图并编写程序。
以80C51串行口按工作方式1进行串行数据通信。假定波特率为1200bps,以中断方式传送数据,请编写全双工通信程序。
以80C51串行口按工作方式3进行串行数据通信。假定波特率为1200bps,以中断方式传送数据,请编写全双工通信程序。
甲乙两台单片机利用串行口方式1通讯,并用RS—232C电平传送,时钟为6MHz,波特率为1.2K,编制两机各自的程序,实现把甲机内部RAM50H~5FH的内容传送到乙机的相应片内RAM单元。
设计一个80C51单片机的双机通信系统,并编写程序将甲机片外RAM3400H~3500H的数据块通过串行口传送到乙机的片外RAM4400H~4500H单元中去。
求8个数的平均值,这8个数以表格形式存放在从table开始的单元中。
在外部RAM首地址为table的数据表中,有10个字节的数据。编程将每个字节的最高位无条件地置“1”。
单片机用内部定时方法产生频率为100KHz等宽矩形波,假定单片机的晶振频率为12MHz,请编写程序。
假定单片机晶振频率为6MHz,要求每隔100ms,从外部RAM以data开始的数据区传送一个数据到P1口输出,共传送100个数据。要求以两个定时器串行定时方法实现。
用定时器T1定时,使P1.2端电平每隔1min变反一次,晶振为12MHz。
设定时器/计数器T0为定时工作方式,并工作在方式1,通过P1.0引脚输出一周期为2ms的方波,已知晶振频率为6MHZ,试编制程序。
若80C51单片机的fosc=6MHZ,请利用定时器T0定时中断的方法,使P1.0输出如图所示的矩形脉冲。
80C51单片机P1端口上,经驱动器接有8只发光二极管,若晶振频率为6MHZ,试编写程序,使这8只发光管每隔2s由P1.0~P1.7输出高电平循环发光。
从片外RAM2000H地址单元开始,连续存有200D个补码数。编写程序,将各数取出处理,若为负数则求补,若为正数则不予处理,结果存入原数据单元。
80C51单片机接口DAC0832D/A变换器,试设计电路并编制程序,使输出如图所示的波形。
PC/XT的D/A接口使用DAC0832。其有关信号接线如图所示,其输出电压V0和输入数字量DI7-DI0之间呈线性且如表所示。现要求V0从零开始按图示波形周期变化(周期可自定)。试用汇编语言编写其控制部分程序。
七、画接口电路图:
1.以两片Intel2716给80C51单片机扩展一个4KB的外部程序存储器,要求地址空间与80C51的内部ROM相衔接,请画出接口图。
2.微型机PC的RS-232接口与MCS-51单片机程序通信接口的电路原理图。
3.MCS-51单片机系统中外部扩展程序存储器和数据存储器共用16位地址线和8位数据线,如何处理不会发生冲突?试画出MCS-51单片机外扩展ROM(2732EPROM)和RAM(6116)的系统接线原理图,并说明其工作过程。
一片6116芯片(2K×8)和一片27128芯片(16K×8)构成存储器系统,要求存储器的起始地址为0000H,且两存储器芯片的地址号连续,试画出连线原理图,并说明每一芯片的地址范围。
用74LS138设计一个译码电路,利用80C51单片机的P0口和P2口译出地址为2000H ~ 3FFFH的片选信号CS 。
用一片74LS138译出两片存储器的片选信号,地址空间分别为1000H~1FFFH,3000H~3FFFH。试画出译码器的接线图。
80C31单片机要扩展4K字节外部RAM,要求地址范围为1000H~1FFFH,请画出完整的电路图。
1. 普通的时间序列:年、月、季
1 myserises<-ts(data,start=,end=,frequency=)#其中frequency=1代表年;frequency=12代表月;frequency=4代表季度数据
2. 如果以天为单位的时间序列
1 t<-ts(1:365,frequency=1,start=as.Date("201...
### 回答1:
《时间序列分析及运用r语言》电子课本是一本非常有价值的书籍,它通过详细的讲解和大量的实例,为读者提供了关于时间序列分析方面的知识和技能,以及如何运用r语言进行时间序列分析。通过学习该书籍,读者能够掌握处理时间序列的基础知识,了解时间序列分析的较新的理论和方法,同时,还能够了解不同类型的时间序列,并通过r语言进行实际分析和模型构建。
该书籍主要分为两部分:时间序列基础和时间序列分析在r语言中的实际应用。时间序列基础涵盖了时间序列的概念和基础知识,如时序图、周期性和趋势等。在该部分,作者还介绍了不同类型的时间序列,如ARIMA模型、GARCH模型和指数平滑模型等。读者还可以学习如何使用r语言进行时间序列的可视化和模型构建。
在后一部分,作者通过实际案例,向读者展示了如何使用r语言处理实际的时间序列数据,如股票价格、GDP等。作者还介绍了一些在时间序列分析中常用的r包,如ggplot2、forecast和tseries等。在每一个案例中,作者为读者提供了详细的指导和代码,使得读者可以轻松地跟随实例进行实践操作。
总之,该书籍是一本非常实用和全面的时间序列分析教材,尤其适合那些想要学习时间序列分析的初学者和使用r语言进行时间序列分析的人员。它不仅包含了基础知识和理论,同时也提供了实际的数据集和代码示例,使得读者能够从实践中掌握实际应用技能。
### 回答2:
《时间序列分析及运用r语言》电子课本涵盖了时间序列分析的基本理论和实践应用,以及R语言在时间序列分析中的应用。该教材内容十分丰富,主要分为三个部分:
第一部分介绍了时间序列分析的基本概念和常用方法,如平稳性检验、时间序列模型建立和选择、指数平滑法和ARIMA模型等。并通过丰富的案例应用,深入阐述了这些方法的实际应用和解决问题的能力。
第二部分详细介绍了R语言在时间序列分析中的应用,包括R语言基础知识、时间序列数据的读取和处理、常见时间序列分析函数、R语言中的绘图函数等,通过大量的代码实现和案例应用,帮助读者熟练掌握R语言在时间序列分析中的使用,进而提升分析水平。
第三部分结合实例,深入介绍了时间序列分析在金融、经济和其他领域中的应用,如股票价格预测、宏观经济数据分析等,并通过具体实例的讲解,让读者更好地掌握时间序列分析的实战能力。
通过学习该电子课本,读者不仅可以掌握时间序列分析的基本理论和实践应用,更可以深入了解R语言在时间序列分析中的使用,并在实践中不断提升分析水平。值得一提的是,虽然该教材内容较为深入,但是编写风格简明易懂,适合广大读者使用。
### 回答3:
《时间序列分析及运用R语言》电子课本是一本介绍时间序列分析和使用R语言进行分析的指导书。该书以理论和实践相结合的方式,深入浅出地介绍了时间序列的基本概念、数据探索、预处理、模型建立和应用等内容。
该课本第一章为读者介绍了时间序列的基本概念,包括时间序列的定义、性质及其产生过程。接下来的章节讲解了时间序列数据采集和预处理技术,如平稳性检验、季节性检验和白噪声检验等。同时,该课本还介绍了时间序列模型的建立和评估,包括ARIMA模型、GARCH模型、扩展卡尔曼滤波器等。
该书还利用R语言实现时间序列的分析,包括时间序列对象、数据组织、图形显示等基本的数据操作。同样,R语言实现了时间序列模型的研究和应用,如实践中的平稳性检验以及建立ARIMA模型的过程。
总的来说,《时间序列分析及运用R语言》电子课本的优点是系统性、实用性、通俗易懂;它为读者提供了时间序列分析的基本理论、数据预处理技术和模型建立方法,并且利用R语言实现了这些理论和方法的具体应用。不仅适用于时间序列专业领域的学生和研究者,也适用于需要分析时间序列数据的实际工作者。
推荐文章
|
|
爱笑的木瓜 · 适用荣耀magicb... 2 月前 |