


实例28_在Excel表格中将上下行相同内容的单元格自动合并

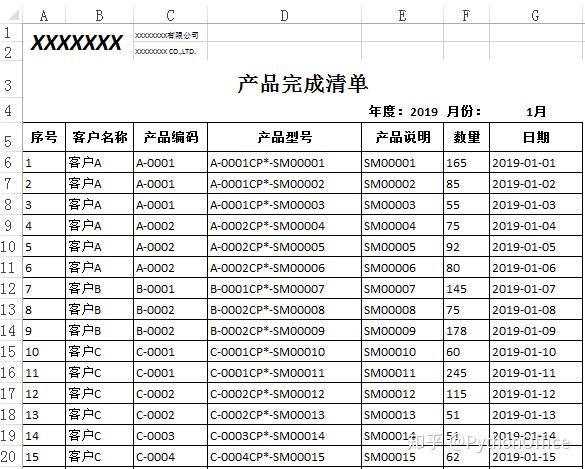
从汇总统计的角度,合并单元格非常不友好。单元格一旦合并,使用数据透视表,分类汇总都无法得到正确的结果。所以,对于原始数据,最好别随意合并单元格。但在日常的工作中,部分Excel打印档要求将某列上下内容相同的单元格合并,以便看起来清爽。比如下面这样的表格:
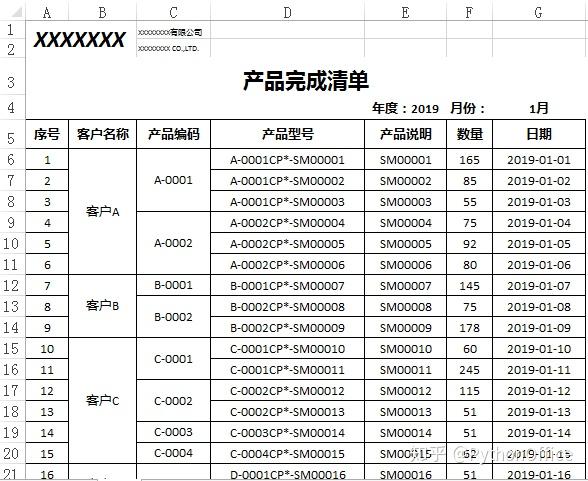
老板一般会要求在打印之前将B,C列上下相邻单元格内容相同的合并成如下这样的:
如果表格少,一个一个手动合并也未尝不可,但若遇到大量的表格,就得做好手软的准备了。现在用Python,一键批量处理Excel工作簿中的所有工作表的单元格合并,解放您的手指。
#定义合并单元格的函数
def Merge_cells(ws,target_list,start_row,col):
ws: 是需要操作的工作表
target_list: 是目标列表,即含有重复数据的列表
start_row: 是开始行,即工作表中开始比对数据的行(需要将标题除开)
col: 是需要处理数据的列
start = 0 #开始行计数,初试值为0,对应列表中的第1个元素的位置0
end = 0 #结束行计数,初试值为0,对应列表中的第1个元素的位置0
reference = target_list[0] #设定基准,以列表中的第一个字符串开始
for i in range(len(target_list)): #遍历列表
if target_list[i] != reference: #开始比对,如果内容不同执行如下
reference = target_list[i] #基准变成列表中下一个字符串
end = i - 1 #列计数器
ws.merge_cells(col + str(start + start_row) + ":"+col + str(end + start_row))
start = end + 1
if i == len(target_list) - 1: #遍历到最后一行,按如下操作
end = i
ws.merge_cells(col + str(start + start_row) + ":"+ col + str(end + start_row))
由于合并单元格是一个重复动作,一张工作表的B列和C列都需要使用。对于这种需要重复使用的功能,定义成函数,每用一次调用一次,最为方便。此处,我们先定义一个函数
Merge_cells
,方便后续调用。这个函数包含四个参数,
ws
指需要操作的工作表,
target_list
指目标列表,即B列所有客户名称的列表,或者C列所有产品编码的列表,这些列表中有很多重复项。我们就根据这些重复项的重复次数为依据来判断单元格合并的起始行。
我们以“2月”的工作表中客户名称为例,前2个是“客户HH”,后面3个是“客户R”。在调用
Merge_cells
函数的时候,传入的参数中,
ws
是
wb["2月]
这个工作表;
target_list
是就是
customer_list
,其内容为
['客户HH', '客户HH', '客户R', '客户R', '客户R']
;最后一个参数是
“B”
,指这个合并的操作是针对B列的。
customer_list
['客户HH', '客户HH', '客户R', '客户R', '客户R']
我们使用
Merge_cells(ws,customer_list,start_row,"B")
调用函数,并传入4个参数。然后进入到函数内部,看每一步是怎样运行的。首先开始行和结束行的计数都设置为0,然后设置一个比较基准
reference
,其值为列表中的第一个元素,此处为
客户HH
。然后用
for
循环遍历列表,用
if
语句来开始逐个调出列表中的元素与基准比对。现在,
i
的值是0,
target_list[0]
的值是
客户HH
,与基准
reference
的值相同,那么第一个
if
下面的语句就不会执行,直接跳到第二个
if
语句。第二个
if
语句是判断是否遍历到列表的最后一个元素,此处,
i
的值是0,
len(customer_list)-1
是4,所以二者显然不等,那也跳过下面的语句。
所以第一轮循环,因不满足操作条件,没有合并单元格。然后第二轮循环,此时
i
的值是1。
target_list[1]
的值还是
客户HH
,与基准
reference
的值仍然相同,所以第一个
if
下面的语句继续跳过,到第二个
if
语句。此时
i
的值还是不等于
len(customer_list)-1
的值4,第二个
if
后的也跳过。
接下来进入第三轮循环,此时
i
的值是2。
target_list[2]
的值还是
客户R
,与基准
reference
的值不同了,所以第一个
if
下面的语句会执行。因为已经出现了不同值,需要将基准做改变,变成了
target_list[2]
,即
客户R
,后续都用新的基准来比对了。第一轮比较完成后,需要确定结束行计数器即
end
的值,令它等于
i-1
,即2-1=1,对应的是列表中的第二个元素所在位置。然后开始第一次激动人心的合并单元格,通过观察我们看到应该合并B6到B7共两个单元格。
ws.merge_cells(col + str(start + start_row) + ":"+col + str(end + start_row))
此时为
ws.merge_cells("B6":"B7")
。合并完单元格后,开始行计数器
start
也需要前进几位, 这取决于结束行计数器
end
。结束行计数器基础上加1就是下一个开始,此时
start
为2,对应列表中的第三个元素所在的位置。现在程序来到第二个
if
语句,此时
i
的值是2,还不等于
len(customer_list)-1
的值4,第二个
if
后的继续跳过。
然后进入第四轮循环,此时
i
的值是3。
target_list[3]
的值还是
客户R
,与基准
reference
的值相同,所以第一个
if
下面的语句跳过,到第二个
if
语句。此时
i
的值3,不等于
len(customer_list)-1
的值4,第二个
if
后的也跳过。
然后进入第五轮循环,此时
i
的值是4。
target_list[4]
的值还是
客户R
,与基准
reference
的值相同,所以第一个
if
下面的语句跳过,到第二个
if
语句。此时
i
的值4,等于
len(customer_list)-1
的值4,说明已经循环到列表中的最后一个元素了。那第二个
if
后程序将执行。通过观察,此时应该合并B8到B10共3个单元格。
ws.merge_cells(col + str(start + start_row) + ":"+ col + str(end + start_row))
应该为
ws.merge_cells("B8":"B10")
。那么,
start + start_row
需要等于8,
end + start_row
需要等于10。而在上一个循环结束,start的值为2, end的值为1。end此时应该对应列表的最后一个元素的位置,所以要令结束行计数器
end
的值为i,即为4。然后执行合并单元格操作。
以上比较难理解的是第一个
if
语句中的
end = i - 1
和
start = end + 1
,以及第二个
if
语句中的
end = i
。请只需要记住,start和end始终对应列表中元素的开始和结束位置,以此为依据来合并单元格。这个函数来源于其他人,我们不用深究其原理,只要会使用,用来解决问题就行。像这种经典程序,可以单独记录起来,以便在需要的时候直接拿过来使用。当遇到难理解的程序时,可以代入相应的值,逐步逐步看结果,就能逐步理解了。
#获取Excel表格中的数据
from openpyxl import load_workbook #用于读取Excel中的信息
wb = load_workbook('产品清单.xlsx')
sheet_names = wb.get_sheet_names()
for sheet_name in sheet_names: #遍历每个工作表,抓取数据,并根据要求合并单元格
ws = wb[sheet_name]
customer_list = [] #客户名称
pn_list = [] #产品编码
for row in range(6,ws.max_row-2):
customer = ws['B' + str(row)].value
pn = ws['C' + str(row)].value
customer_list.append(customer)
pn_list.append(pn)
#调用以上定义的合并单元格函数`Merge_cells`做单元格合并操作