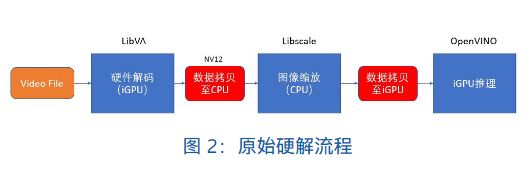
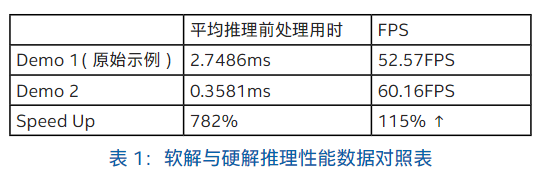
通过利用开源视频处理软件 FFmpeg 可以很容易地进行硬件解码工作。FFmpeg作为市面上比较流行的开源视频处理工具,其后端可以支持 LibVA 或者 MediaSDK 进行硬件解码。
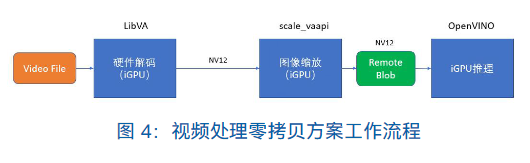
在本文的方案中,选择使用 LibVA 作为处理后端,同时 LibVA也在 iGPU 中提供了名为 scale_vaapi 的滤镜可以用来进行图片的缩放。这样保证了解码和图像缩放的流程是在 iGPU 中进行,同时,我们必须要通过设置好滤镜的相关参数来保证从解码到缩放直接数据的连通性,而不进行任何多余的数据拷贝。第一步优化后的流程如下图所示:

然后,引入 OpenVINO™ 工具套件提供的 Remote Blob 来作为缩放完成的数据与推理引擎之间的数据衔接桥梁。在图像在 iGPU 中完成缩放后,图像数据全部存储与 iGPU 的内存中,构建Remote Blob时可以很轻易地获取到VAAPI给它的输入参数,所以我们只需要使用 Remote Blob 便可以很方便地将数据从 iGPU 内存中输出给 iGPU 进行推理。由于使用硬件解码输出的视频格式是 NV12,图像缩放完成之后图像格式依旧为 NV12,Remote Blob 可以支持的数据输入格式也为 NV12,所以可以无缝衔接 iGPU 内存中的数据发送至Remote Blob。最终避免了数据从 CPU 到 iGPU 的内存拷贝,整体流程如下图所示:
项目整体结构以及软件库之间的所属关系如下图所示:
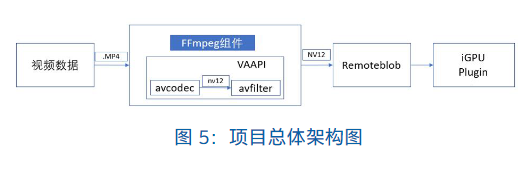
我们的方案将会使用开源软件FFmpeg调用VAAPI,使用VAAPI 提供的硬件解码和硬件缩放,然后将 FFmpeg 的代码集成于 OpenVINO™ 的推理示例中,在使用 iGPU 推理前进行视频解码和缩放,然后利用缩放完成的数据构建 OpenVINO™ 的 Remote Blob。最终目的是将解码、缩放和推理的工作流程都在 iGPU 中完成,减少数据在 CPU 和 iGPU 间无用的拷贝,从而更好地利用 iGPU 的性能的同时减轻 CPU 的负载。
本方案实验环境:
硬件:Intel® Core™ i5-7200U 2.5GHz, HD Graphics 620 (KBL GT2), MEM: 8G DDR4软件版本:Linux 18.04.4 LTS, OpenVINO 2020.3,FFmpeg 4.3.1, LibVA: 2.1.0, VA-API version 1.6.0