|
|
|
相关文章推荐

|
失望的篮球 · java中文本框的事件_mob64ca12f ...· 1 年前 · |
|
|
活泼的椅子 · js合并两个map_js ...· 1 年前 · |
|
|
逆袭的汉堡包 · SpringCloud : yml文件配置 ...· 1 年前 · |
|
|
傲视众生的铁板烧 · electron打印方法总结 - 掘金· 1 年前 · |

火山引擎首页
全站搜索
R
创建一个具有字典数组的表:
如何在clickHouse中将字典数组拆分成多列?
如何在clickHouse中将字典数组拆分成多列?
在clickHouse中,有一个 函数 可以将字典数组拆分成多列。具体实现步骤如下:
CREATE TABLE test_dict_array
id Int32,
dict_array Array(String)
) ENGINE = Memory;
插入一些数据到表中:
INSERT INTO test_dict_array (id, dict_array) VALUES
(1, ['{"key1": "value1", "key2": "value2"}', '{"key1": "value3", "key2": "value4"}']),
(2, ['{"key1": "value5", "key2": "value6"}', '{"key1": "value7", "key2": "value8"}']);
使用“arrayElement”函数将字典数组拆分成多列:
SELECT
arrayElement(dict_array, 1)['key1'] AS dict_key1_col1,
arrayElement(dict_array, 1)['key2'] AS dict_key2_col1,
arrayElement(dict_array, 2)['key1'] AS dict_key1_col2,
arrayElement(dict_array, 2)['key2'] AS dict_key2_col2
FROM test_dict_array;
| id | dict_key1_col1 | dict_key2_col1 | dict_key1_col2 | dict_key2_col2 |
|----|----------------|----------------|----------------|----------------|
| 1 | value1 | value2 | value3 | value4 |
| 2 | value5 | value6 | value7 | value8 |
在以上示例中,“arrayElement”函数接收两个参数:一个是需要拆分的数组,另一个是需要访问的数组元素的索引。使用此函数可以将字典数组拆分成多列,并访问数组元素中的每个键。
本文内容通过AI工具匹配关键字智能整合而成,仅供参考,火山引擎不对内容的真实、准确或完整作任何形式的承诺。如有任何问题或意见,您可以通过联系
service@volcengine.com
进行反馈,火山引擎收到您的反馈后将及时答复和处理。
展开更多
 社区干货
社区干货
社区干货
干货|
ClickHouse
在
UBA系统中的
字典
编码优化实践
干货|
ClickHouse
在
UBA系统中的
字典
编码优化实践
>
ClickHouse
UBA版本是字节跳动内部在开源版本基础上为火山引擎增长分析专门深度定制优化的版本。本篇文章介绍
在字典
编码方向上的优化实践。专门深度定制优化的版本。本篇文章介绍
在字典
编码方向上的优化实践。时,数据可以直接在内存中进行局部操作,而不需要频繁地...
大数据
20000字详解大厂实时数仓建设 | 社区征文
20000字详解大厂实时数仓建设 | 社区征文
在活动进行过程中,我们发现 60~70% 的需求是计算页面里的信息,如:- 这个页面来了多少人,或者有多少人
点击
进入这个页面;- 活动一共来了多少人;- 页面里的某一个挂件,获得了多少
点击
、产生了多少曝光。_1.2 方... 存放在同一个 Segment 上,计算全局 TopN 只能是近似值,所以我们选择了最近两年大火的 MPP 数据库引擎
ClickHouse
。#### 2) 设计目标与设计难点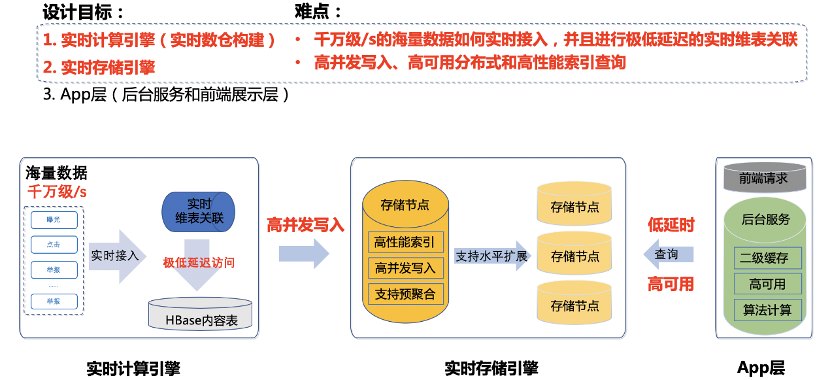...
大数据
 特惠活动
特惠活动
特惠活动
 如何在clickHouse中将字典数组拆分成多列?
-优选内容
如何在clickHouse中将字典数组拆分成多列?
-优选内容
如何在clickHouse中将字典数组拆分成多列?
-优选内容
干货|
ClickHouse
在
UBA系统中的
字典
编码优化实践
>
ClickHouse
UBA版本是字节跳动内部在开源版本基础上为火山引擎增长分析专门深度定制优化的版本。本篇文章介绍
在字典
编码方向上的优化实践。专门深度定制优化的版本。本篇文章介绍
在字典
编码方向上的优化实践。时,数据可以直接在内存中进行局部操作,而不需要频繁地...
20000字详解大厂实时数仓建设 | 社区征文
在活动进行过程中,我们发现 60~70% 的需求是计算页面里的信息,如:- 这个页面来了多少人,或者有多少人
点击
进入这个页面;- 活动一共来了多少人;- 页面里的某一个挂件,获得了多少
点击
、产生了多少曝光。_1.2 方... 存放在同一个 Segment 上,计算全局 TopN 只能是近似值,所以我们选择了最近两年大火的 MPP 数据库引擎
ClickHouse
。#### 2) 设计目标与设计难点...
 如何在clickHouse中将字典数组拆分成多列?
-相关内容
如何在clickHouse中将字典数组拆分成多列?
-相关内容
如何在clickHouse中将字典数组拆分成多列?
-相关内容
干货 | ELT in ByteHouse 实践与展望
干货 | ELT in ByteHouse 实践与展望
火山引擎ByteHouse 是一款基于开源
ClickHouse
推出的云原生数据仓库,本篇文章将介绍 ByteHouse 团队
如何在
ClickHouse
的基础上,构建并优化 ELT 能力,具体包括四部分: **●** ByteHouse 在字节的应... 典型的数据链路如下:我们将行为数据、日志、
点击
流等通过 MQ/Kafka/Flink 将其接入存储系统当中,存储系统又可分为域内的**HDFS**和云上的**OSS&S3**这种远程储存系统,然后进行一系列的数仓的**ETL**操作,提供...
来自:
开发者社区
ELT in ByteHouse 实践与展望
ELT in ByteHouse 实践与展望
在ByteHouse内部进行数据转换,而无需依赖独立的ETL系统及资源。 火山引擎ByteHouse是一款基于开源
ClickHouse
推出的云原生数据仓库,本篇文章将介绍ByteHouse团队
如何在ClickHouse
的基础上,构建并优化ELT能力,... 典型的数据链路如下:我们将行为数据、日志、
点击
流等通过MQ/Kafka/Flink将其接入存储系统当中,存储系统又可分为域内的HDFS和云上的OSS&S3这种远程储存系统,然后进行一系列的数仓的ETL操作,提供给OLAP系统完成分析查...
来自:
开发者社区
玩转Apache Iceberg|如何0-1提升查询性能 ?
玩转Apache Iceberg|如何0-1提升查询性能 ?
如何加速查询性能,使其尽可能接近专门的分布式数仓(如
ClickHouse
等),是需要思考和探究的问题。 **索引是业界常用的提高查询性能的手段之一,针对Iceberg我们也采用了增加索引的方式。**对常用的列字... `"
array
": [{` `"key": 1,` `"value": "\u0006\u0000\u0000\u0000"` `}, {` `"key": 2,` `"value": "diamond"` `}, {` `"key": 3,` `"value": "\u0000\u0004�ŷ\u0005\u0000"` `}]` `}...
来自:
开发者社区
干货|从MySQL到ByteHouse,抖音精准推荐存储架构重构解读
干货|从MySQL到ByteHouse,抖音精准推荐存储架构重构解读
底层存储架构从MySQL到ByteHouse的重构,将抖音精准推荐的查询效率平均提升了近百倍。**
点击
阅读原文可下载《云原生数据仓库ByteHouse技术白皮书》。** 
白皮书
白皮书
推荐文章
|
|
傲视众生的铁板烧 · electron打印方法总结 - 掘金 1 年前 |