


ScratchDet加强小目标检测——攻略一

一种从零开始训练的目标探测器 ScratchDet,充分利用原始图像信息的 Root-ResNet,结合 ResNet 与 VGGNet 加强对小目标的检测
京东 AI 研究院、中国科学院、中山大学
ScratchDet: Training Single-Shot Object Detectors from Scratch
Rui Zhu, Shifeng Zhang, Xiaobo Wang, Longyin Wen, Hailin Shi, Liefeng Bo, Tao Me
作者发布的开源代码是基于Caffe的,我这里没有使用这个版本,选择了另一个Tensorflow版本的算法,链接在此:
从主页可以看出该版本的代码是从其他两个原始版本演变过来的,所以遇到问题可以先去两个原始版本链接里找找答案,接下来我主要说明我自己在使用过程中遇到的问题及解决办法。
想要运行训练代码trainmodel.py文件之前需要完成数据集格式转换问题,我们一般使用的是VOCdeckit的原始形式,这里需要用dataset文件夹下的pascalvoc_to_tfrecords.py进行转化。
首先准备好VOC原始数据,按照步骤下载并依次放置好。主文件夹下新建data/voc文件夹,并依次创建2007_train、2007_test、2012_train。将下载的原始数据放入对应的文件夹下。这里建议下载一个放置一个,不要全部下载完成后放置,这样会造成test文件和 train文件交叉。
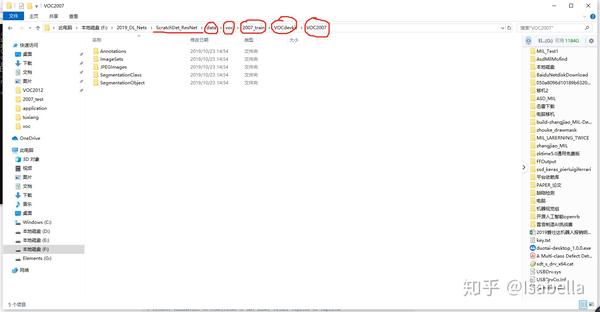
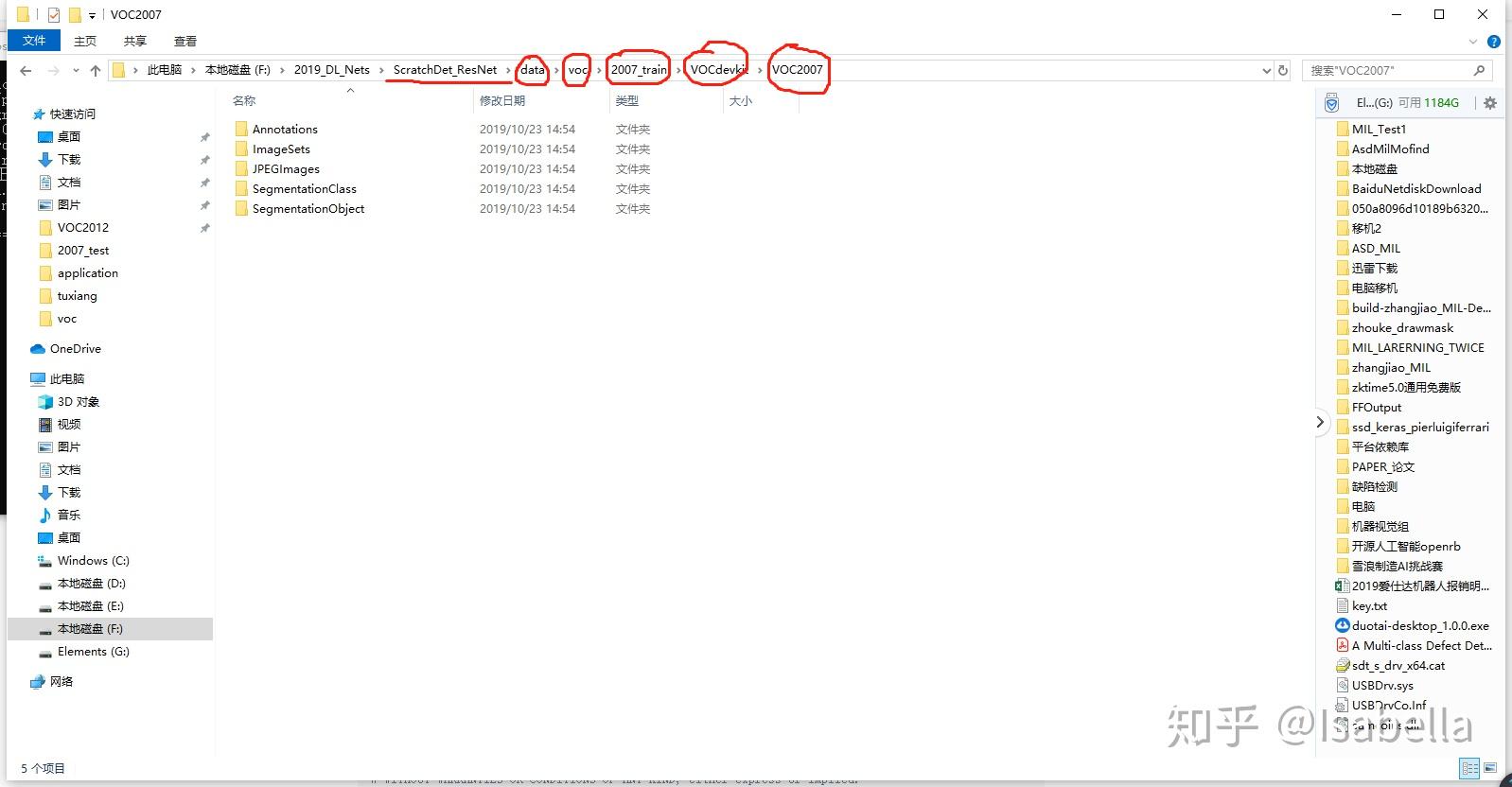
然后准备dataset_utils.py文件,因为原dataset文件并没有提供改py文件,我从作者提供的先前链接中找到了此文件,大家可以直接在dataset文件夹下新建dataset_utils.py文件,然后粘贴一下内容并保存即可。
#from datasets.dataset_utils import int64_feature, float_feature, bytes_feature
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
# http://www.apache.org/licenses/LICENSE-2.0
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""Contains utilities for downloading and converting datasets."""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import os
import sys
import tarfile
from six.moves import urllib
import tensorflow as tf
LABELS_FILENAME = 'labels.txt'
def int64_feature(value):
"""Wrapper for inserting int64 features into Example proto.
if not isinstance(value, list):
value = [value]
return tf.train.Feature(int64_list=tf.train.Int64List(value=value))
def float_feature(value):
"""Wrapper for inserting float features into Example proto.
if not isinstance(value, list):
value = [value]
return tf.train.Feature(float_list=tf.train.FloatList(value=value))
def bytes_feature(value):
"""Wrapper for inserting bytes features into Example proto.
if not isinstance(value, list):
value = [value]
return tf.train.Feature(bytes_list=tf.train.BytesList(value=value))
def image_to_tfexample(image_data, image_format, height, width, class_id):
return tf.train.Example(features=tf.train.Features(feature={
'image/encoded': bytes_feature(image_data),
'image/format': bytes_feature(image_format),
'image/class/label': int64_feature(
class_id),
'image/height': int64_feature(height),
'image/width': int64_feature(width),
def download_and_uncompress_tarball(tarball_url, dataset_dir):
"""Downloads the `tarball_url` and uncompresses it locally.
Args:
tarball_url: The URL of a tarball file.
dataset_dir: The directory where the temporary files are stored.
filename = tarball_url.split('/')[-1]
filepath = os.path.join(dataset_dir, filename)
def _progress(count, block_size, total_size):
sys.stdout.write('\r>> Downloading %s %.1f%%' % (
filename, float(count * block_size) / float(total_size) * 100.0))
sys.stdout.flush()
filepath, _ = urllib.request.urlretrieve(tarball_url, filepath, _progress)
print()
statinfo = os.stat(filepath)
print('Successfully downloaded', filename, statinfo.st_size, 'bytes.')
tarfile.open(filepath, 'r:gz').extractall(dataset_dir)
def write_label_file(labels_to_class_names, dataset_dir,
filename=LABELS_FILENAME):
"""Writes a file with the list of class names.
Args:
labels_to_class_names: A map of (integer) labels to class names.
dataset_dir: The directory in which the labels file should be written.
filename: The filename where the class names are written.
labels_filename = os.path.join(dataset_dir, filename)
with tf.gfile.Open(labels_filename, 'w') as f:
for label in labels_to_class_names:
class_name = labels_to_class_names[label]
f.write('%d:%s\n' % (label, class_name))
def has_labels(dataset_dir, filename=LABELS_FILENAME):
"""Specifies whether or not the dataset directory contains a label map file.
Args:
dataset_dir: The directory in which the labels file is found.
filename: The filename where the class names are written.
Returns:
`True` if the labels file exists and `False` otherwise.
return tf.gfile.Exists(os.path.join(dataset_dir, filename))
def read_label_file(dataset_dir, filename=LABELS_FILENAME):
"""Reads the labels file and returns a mapping from ID to class name.
Args:
dataset_dir: The directory in which the labels file is found.
filename: The filename where the class names are written.
Returns:
A map from a label (integer) to class name.
labels_filename = os.path.join(dataset_dir, filename)
with tf.gfile.Open(labels_filename, 'rb') as f:
lines = f.read()
lines = lines.split(b'\n')
lines = filter(None, lines)
labels_to_class_names = {}
for line in lines:
index = line.index(b':')
labels_to_class_names[int(line[:index])] = line[index+1:]
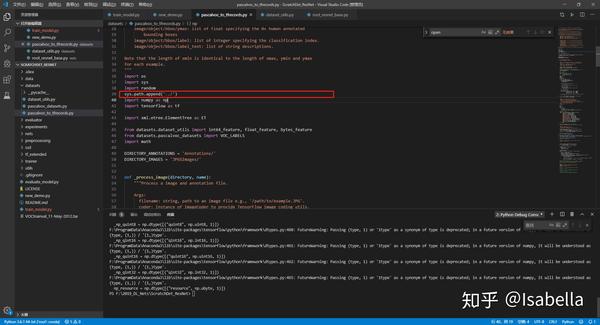
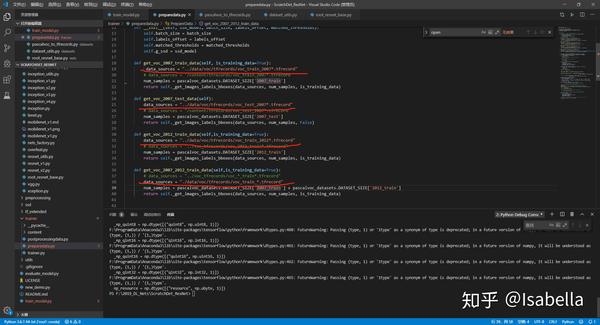
return labels_to_class_names然后在pascalvoc_to_tfrecords.py需要改动两处地方:
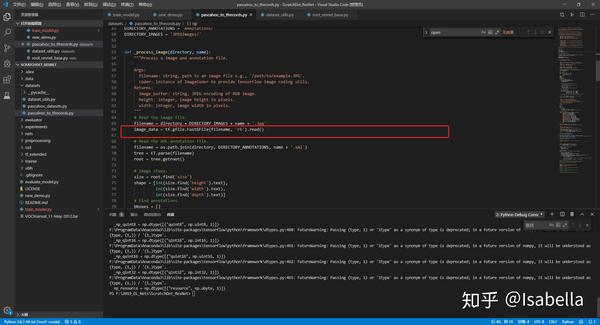
- 增加系统环境路径,不然会提示 no module named dataset
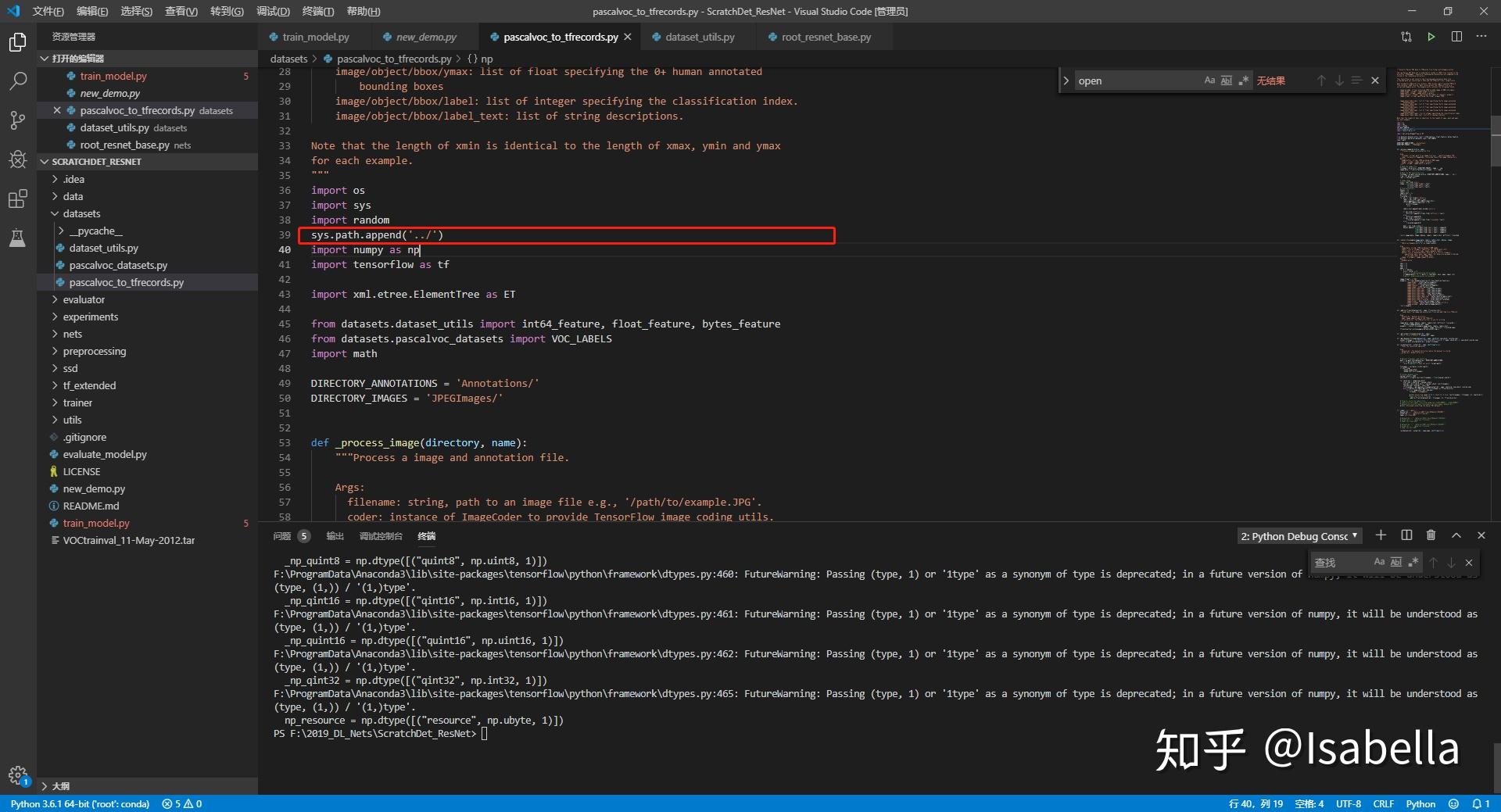
2. 改读取方式,“r”变“rb”,以免提示error UnicodeDecodeError: 'utf-8' codec can't decode byte 0xff in position 0: invalid start byte
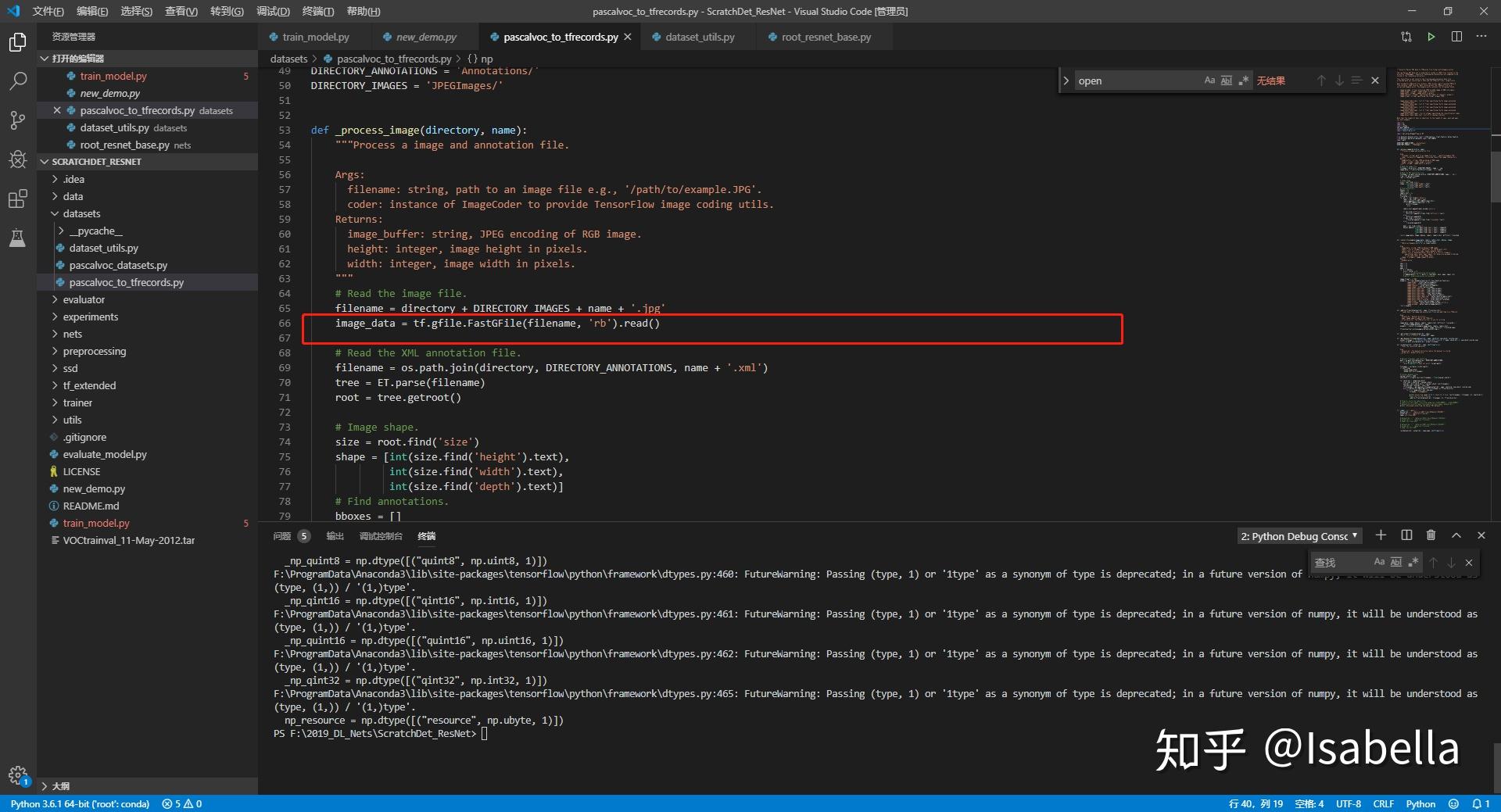
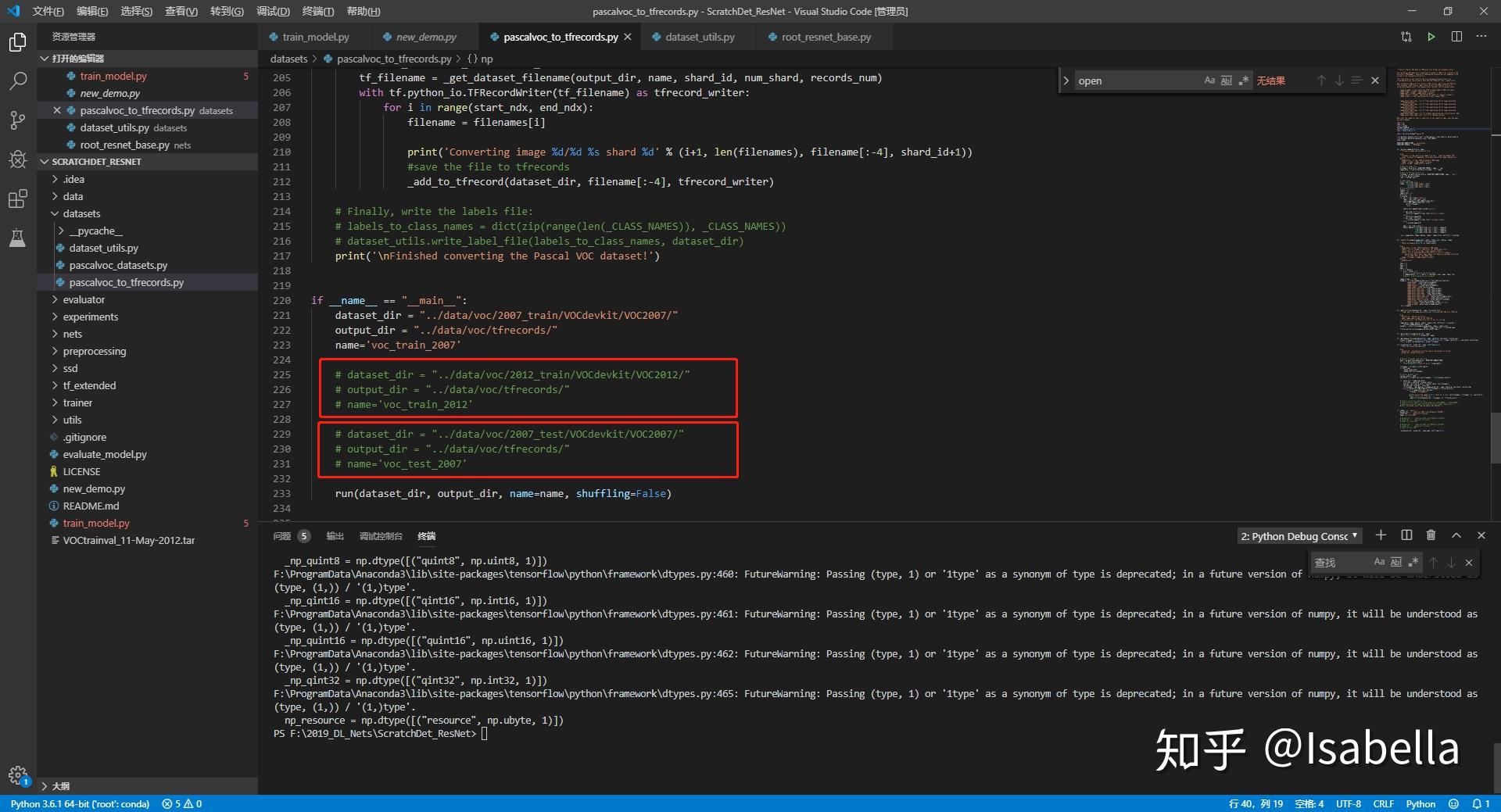
最后在转换格式时需要对2007train、2007test和2012train依次转换,即转换其中一个时需要屏蔽另两个。
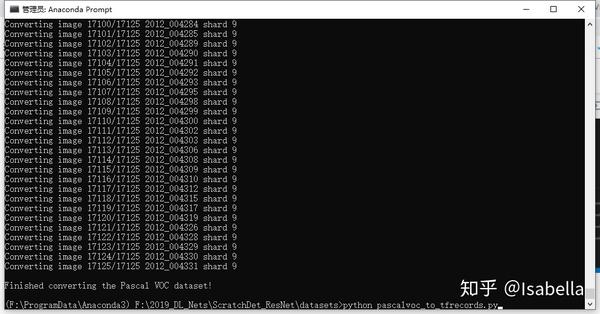
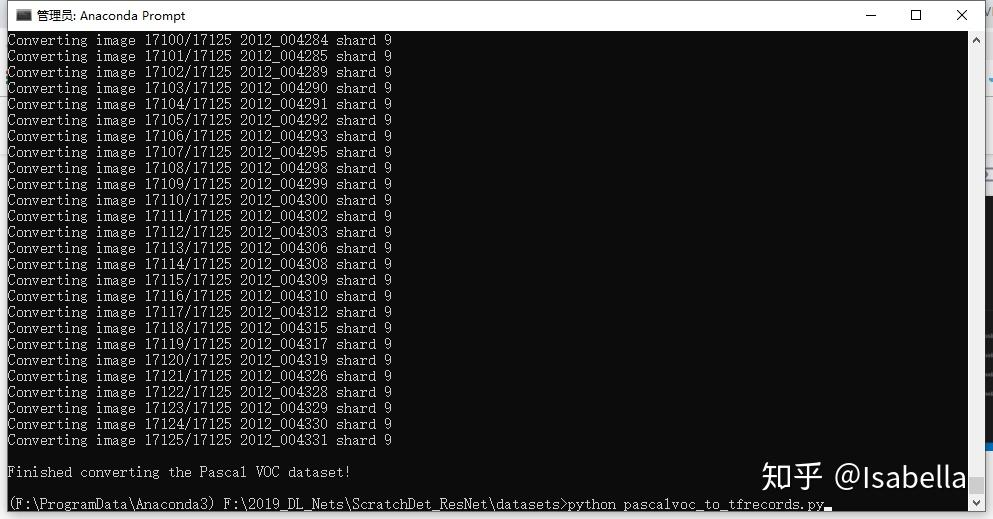
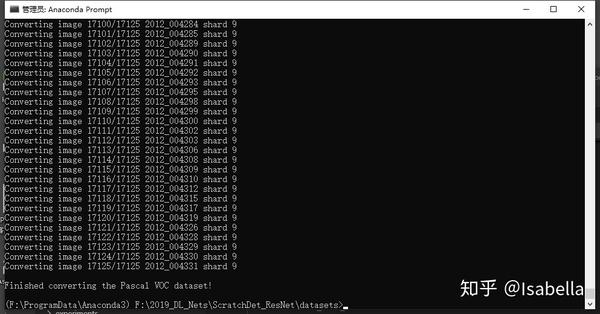
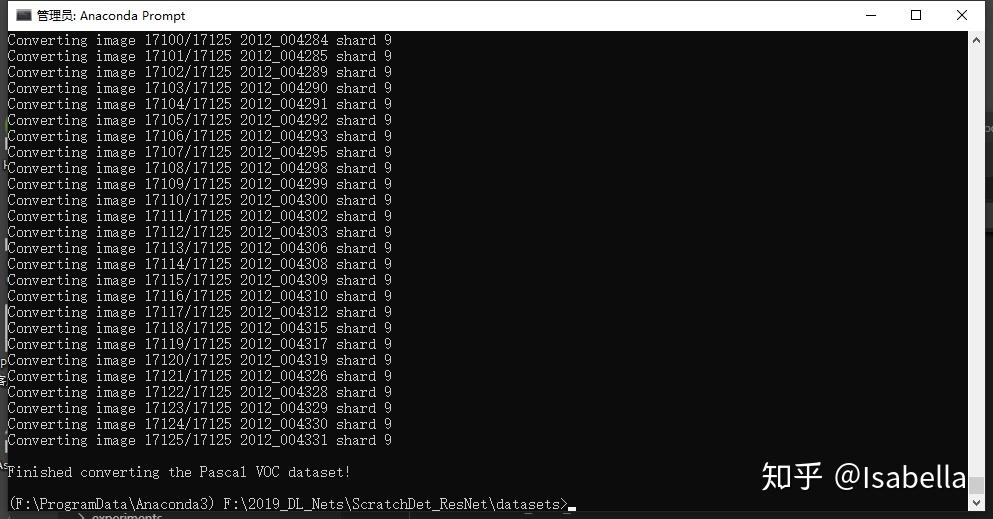

AttributeError: module 'tensorflow' has no attribute 'AUTO_REUSE'
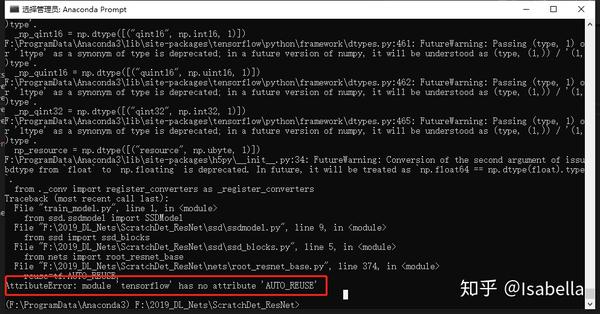
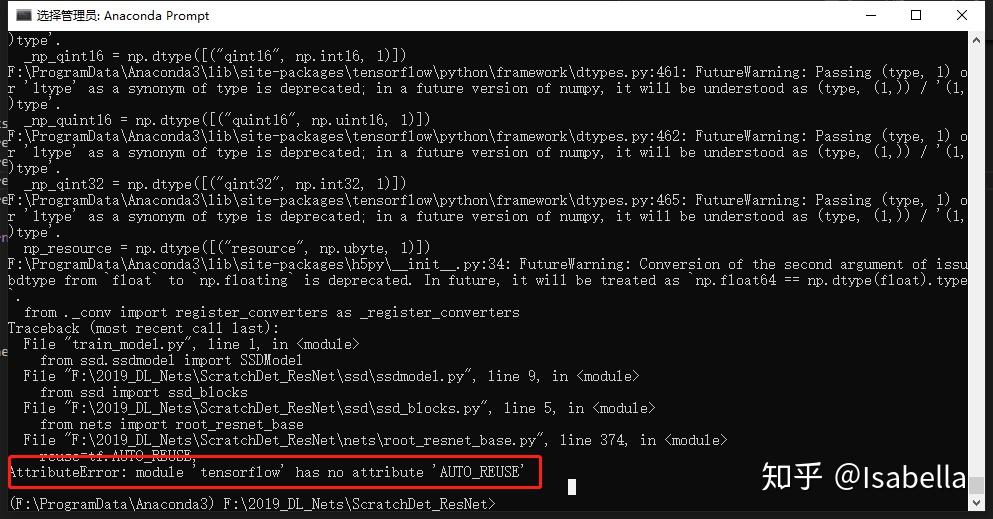
解决方法:
auto属性与tensorflow版本有关,1.4.0是OK的,我的是1.3.0,升级有时会带来很多问题,所以这里我没选择升级,在nets\root_resnet_base.py文件中改几句话:
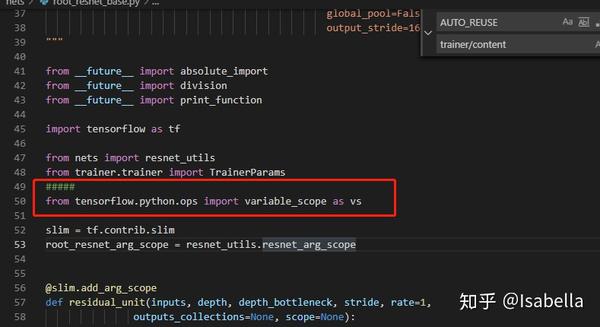
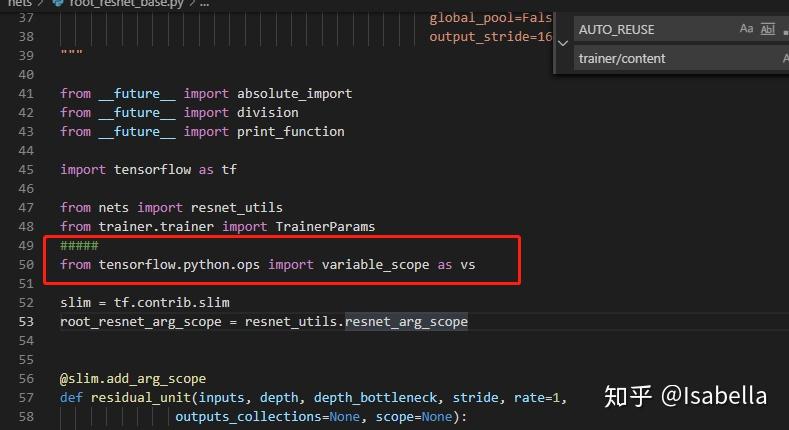
from tensorflow.python.ops import variable_scope as vs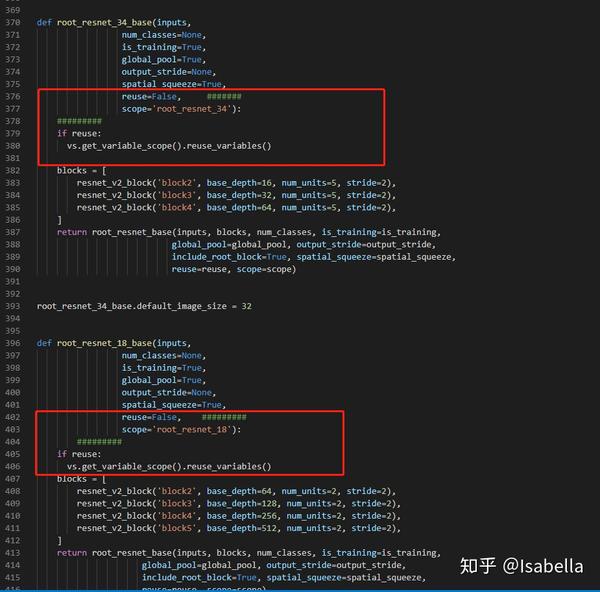
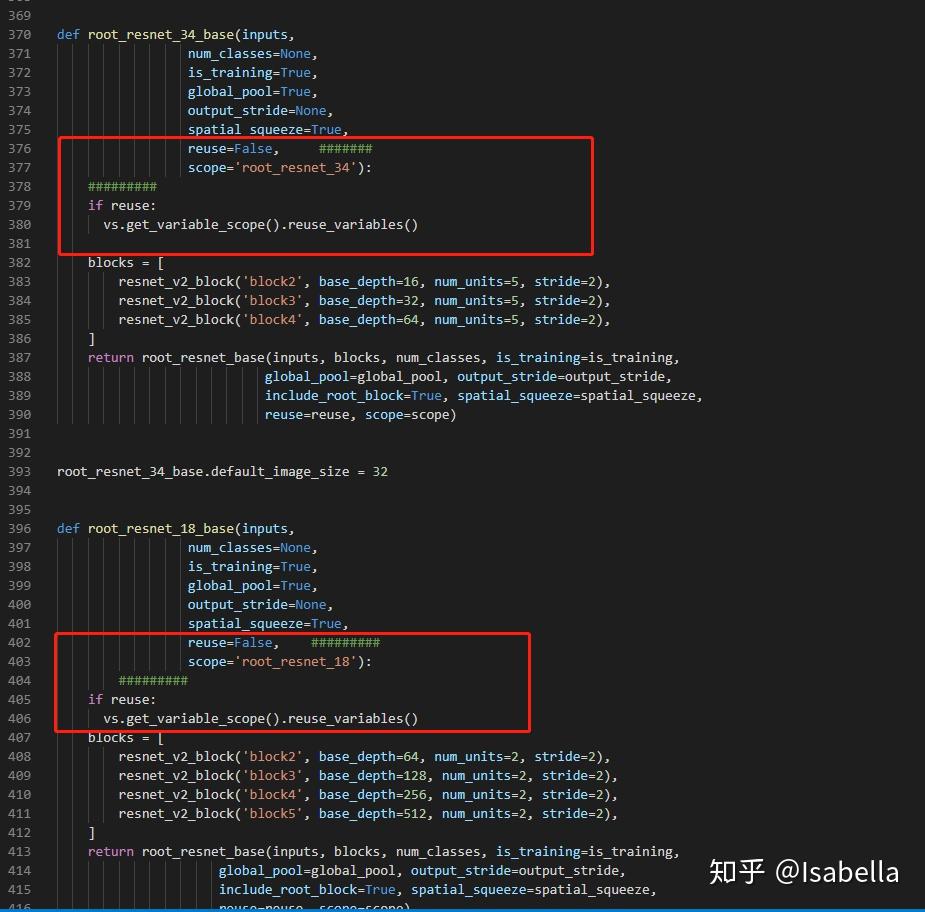
def root_resnet_34_base(inputs,
num_classes=None,
is_training=True,
global_pool=True,
output_stride=None,
spatial_squeeze=True,
reuse=False, #######
scope='root_resnet_34'):
#########
if reuse:
vs.get_variable_scope().reuse_variables()
blocks = [
resnet_v2_block('block2', base_depth=16, num_units=5, stride=2),
resnet_v2_block('block3', base_depth=32, num_units=5, stride=2),
resnet_v2_block('block4', base_depth=64, num_units=5, stride=2),
return root_resnet_base(inputs, blocks, num_classes, is_training=is_training,
global_pool=global_pool, output_stride=output_stride,
include_root_block=True, spatial_squeeze=spatial_squeeze,
reuse=reuse, scope=scope)
root_resnet_34_base.default_image_size = 32
def root_resnet_18_base(inputs,
num_classes=None,
is_training=True,
global_pool=True,
output_stride=None,
spatial_squeeze=True,
reuse=False, #########
scope='root_resnet_18'):
#########
if reuse:
vs.get_variable_scope().reuse_variables()
blocks = [
resnet_v2_block('block2', base_depth=64, num_units=2, stride=2),
resnet_v2_block('block3', base_depth=128, num_units=2, stride=2),
resnet_v2_block('block4', base_depth=256, num_units=2, stride=2),
resnet_v2_block('block5', base_depth=512, num_units=2, stride=2),