副本集(Replica Set)是一组MongoDB实例组成的集群,由一个主(Primary)服务器和多个备份(Secondary)服务器构成。通过Replication,将数据的更新由Primary推送到其他实例上,在一定的延迟之后,每个MongoDB实例维护相同的数据集副本。通过维护冗余的数据库副本,能够实现数据的异地备份,读写分离和自动故障转移。
也就是说如果主服务器崩溃了,备份服务器会自动将其中一个成员升级为新的主服务器。使用复制功能时,如果有一台服务器宕机了,仍然可以从副本集的其他服务器上访问数据。如果服务器上的数据损坏或者不可访问,可以从副本集的某个成员中创建一份新的数据副本。
早期的MongoDB版本使用master-slave,一主一从和MySQL类似,但slave在此架构中为只读,当主库宕机后,从库不能自动切换为主。目前已经淘汰master-slave模式,改为副本集,这种模式下有一个主(primary),和多个从(secondary),只读。支持给它们设置权重,当主宕掉后,权重最高的从切换为主。在此架构中还可以建立一个仲裁(arbiter)的角色,它只负责裁决,而不存储数据。此架构中读写数据都是在主上,要想实现负载均衡的目的需要手动指定读库的目标server。
简而言之MongoDB 副本集是有自动故障恢复功能的主从集群,有一个Primary节点和一个或多个Secondary节点组成。类似于MySQL的MMM架构。更多关于副本集的介绍请见官方文档:
官方文档地址:
https://docs.mongodb.com/manual/replication/
副本集架构图:
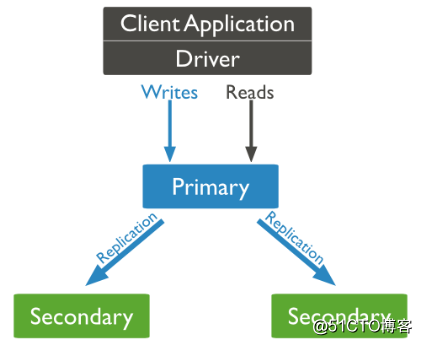
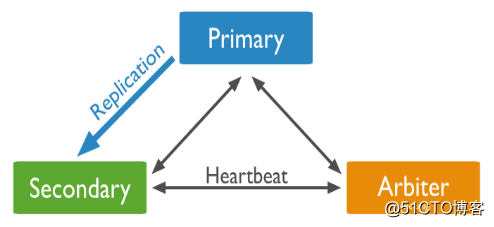
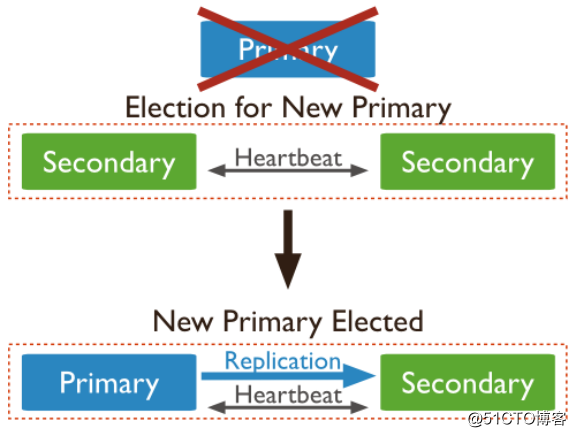
21.34 mongodb副本集搭建
我这里使用了三台机器搭建副本集:
192.168.77.128 (primary)
192.168.77.130 (secondary)
192.168.77.134 (secondary)
这三台机器上都已经安装好了MongoDB。
开始搭建:
1.编辑三台机器的配置文件,更改或增加以下内容:
[root@localhost ~]
replication:
oplogSizeMB: 20
replSetName: zero
注:需要确保每台机器的配置文件中的bindIp都有配置监听自身的内网IP
2.编辑完成后,分别重启三台机器的MongoDB服务:
[root@localhost ~]
[root@localhost ~]
mongod 2578 0.7 8.9 1034696 43592 ? Sl 18:21 0:00 /usr/bin/mongod -f /etc/mongod.conf
root 2605 0.0 0.1 112660 964 pts/0 S+ 18:21 0:00 grep --color=auto mongod
[root@localhost ~]
tcp 0 0 192.168.77.134:27017 0.0.0.0:* LISTEN 2578/mongod
tcp 0 0 127.0.0.1:27017 0.0.0.0:* LISTEN 2578/mongod
[root@localhost ~]
3.关闭三台机器的防火墙,或者清空iptables规则
4.连接主机器的MongoDB,在主机器上运行命令mongo,然后配置副本集:
[root@localhost ~]
> use admin
switched to db admin
> config={_id:"zero",members:[{_id:0,host:"192.168.77.128:27017"},{_id:1,host:"192.168.77.130:27017"},{_id:2,host:"192.168.77.134:27017"}]}
"_id" : "zero",
"members" : [
"_id" : 0,
"host" : "192.168.77.128:27017"
"_id" : 1,
"host" : "192.168.77.130:27017"
"_id" : 2,
"host" : "192.168.77.134:27017"
> rs.initiate(config)
"ok" : 1,
"operationTime" : Timestamp(1515465317, 1),
"$clusterTime" : {
"clusterTime" : Timestamp(1515465317, 1),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
zero:PRIMARY> rs.status()
"set" : "zero",
"date" : ISODate("2018-01-09T02:37:13.713Z"),
"myState" : 1,
"term" : NumberLong(1),
"heartbeatIntervalMillis" : NumberLong(2000),
"optimes" : {
"lastCommittedOpTime"
: {
"ts" : Timestamp(1515465429, 1),
"t" : NumberLong(1)
"readConcernMajorityOpTime" : {
"ts" : Timestamp(1515465429, 1),
"t" : NumberLong(1)
"appliedOpTime" : {
"ts" : Timestamp(1515465429, 1),
"t" : NumberLong(1)
"durableOpTime" : {
"ts" : Timestamp(1515465429, 1),
"t" : NumberLong(1)
"members" : [
"_id" : 0,
"name" : "192.168.77.128:27017",
"health" : 1,
"state" : 1,
"stateStr" : "PRIMARY",
"uptime" : 527,
"optime" : {
"ts" : Timestamp(1515465429, 1),
"t" : NumberLong(1)
"optimeDate" : ISODate("2018-01-09T02:37:09Z"),
"infoMessage" : "could not find member to sync from",
"electionTime" : Timestamp(1515465327, 1),
"electionDate" : ISODate("2018-01-09T02:35:27Z"),
"configVersion" : 1,
"self" : true
"_id" : 1,
"name" : "192.168.77.130:27017",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 116,
"optime" : {
"ts" : Timestamp(1515465429, 1),
"t" : NumberLong(1)
"optimeDurable" : {
"ts" : Timestamp(1515465429, 1),
"t" : NumberLong(1)
"optimeDate" : ISODate("2018-01-09T02:37:09Z"),
"optimeDurableDate" : ISODate("2018-01-09T02:37:09Z"),
"lastHeartbeat" : ISODate("2018-01-09T02:37:13.695Z"),
"lastHeartbeatRecv" : ISODate("2018-01-09T02:37:13.661Z"),
"pingMs" : NumberLong(0),
"syncingTo" : "192.168.77.128:27017",
"configVersion" : 1
"_id" : 2,
"name" : "192.168.77.134:27017",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 116,
"optime" : {
"ts" : Timestamp(1515465429, 1),
"t" : NumberLong(1)
"optimeDurable" : {
"ts" : Timestamp(1515465429, 1),
"t" : NumberLong(1)
"optimeDate" : ISODate("2018-01-09T02:37:09Z"),
"optimeDurableDate" : ISODate("2018-01-09T02:37:09Z"),
"lastHeartbeat" : ISODate("2018-01-09T02:37:13.561Z"),
"lastHeartbeatRecv"
: ISODate("2018-01-09T02:37:13.660Z"),
"pingMs" : NumberLong(0),
"syncingTo" : "192.168.77.128:27017",
"configVersion" : 1
"ok" : 1,
"operationTime" : Timestamp(1515465429, 1),
"$clusterTime" : {
"clusterTime" : Timestamp(1515465429, 1),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
zero:PRIMARY>
以上我们需要关注三台机器的stateStr状态,主机器的stateStr状态需要为PRIMARY,两台从机器的stateStr状态需要为SECONDARY才是正常。
如果出现两个从上的stateStr状态为"stateStr" : "STARTUP", 则需要进行如下操作:
> config={_id:"zero",members:[{_id:0,host:"192.168.77.128:27017"},{_id:1,host:"192.168.77.130:27017"},{_id:2,host:"192.168.77.134:27017"}]}
> rs.reconfig(config)
然后再次查看状态:rs.status(),确保从的状态变为SECONDARY。
21.35 mongodb副本集测试
1.在主机器上创建库以及创建集合:
zero:PRIMARY> use testdb
switched to db testdb
zero:PRIMARY> db.test.insert({AccountID:1,UserName:"zero",password:"123456"})
WriteResult({ "nInserted" : 1 })
zero:PRIMARY> show dbs
admin 0.000GB
config 0.000GB
local 0.000GB
testdb 0.000GB
zero:PRIMARY> show tables
zero:PRIMARY>
2.然后到从机器上查看是否有同步主机器上的数据:
[root@localhost ~]
zero:SECONDARY> show dbs
2018-01-09T18:46:09.959+0800 E QUERY [thread1] Error: listDatabases failed:{
"operationTime" : Timestamp(1515466399, 1),
"ok" : 0,
"errmsg" : "not master and slaveOk=false",
"code" : 13435,
"codeName" : "NotMasterNoSlaveOk",
"$clusterTime" : {
"clusterTime" : Timestamp(1515466399, 1),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
_getErrorWithCode@src/mongo/shell/utils.js:25:13
Mongo.prototype.getDBs@src/mongo/shell/mongo.js:65:1
shellHelper.show@src/mongo/shell/utils.js:813:19
shellHelper@src/mongo/shell/utils.js:703:15
@(shellhelp2):1:1
zero:SECONDARY> rs.slaveOk()
zero:SECONDARY> show dbs
admin 0.000GB
config 0.000GB
local 0.000GB
testdb 0.000GB
zero:SECONDARY> use testdb
switched to db testdb
zero:SECONDARY> show tables
zero:SECONDARY>
如上可以看到数据已经成功同步到从机器上了。
副本集更改权重模拟主宕机
使用rs.config()命令可以查看每台机器的权重:
zero:PRIMARY> rs.config()
"_id" : "zero",
"version" : 1,
"protocolVersion" : NumberLong(1),
"members" : [
"_id" : 0,
"host" : "192.168.77.128:27017",
"arbiterOnly" : false,
"buildIndexes" : true,
"hidden" : false,
"priority"
: 1,
"tags" : {
"slaveDelay" : NumberLong(0),
"votes" : 1
"_id" : 1,
"host" : "192.168.77.130:27017",
"arbiterOnly" : false,
"buildIndexes" : true,
"hidden" : false,
"priority" : 1,
"tags" : {
"slaveDelay" : NumberLong(0),
"votes" : 1
"_id" : 2,
"host" : "192.168.77.134:27017",
"arbiterOnly" : false,
"buildIndexes" : true,
"hidden" : false,
"priority" : 1,
"tags" : {
"slaveDelay" : NumberLong(0),
"votes" : 1
"settings" : {
"chainingAllowed" : true,
"heartbeatIntervalMillis" : 2000,
"heartbeatTimeoutSecs" : 10,
"electionTimeoutMillis" : 10000,
"catchUpTimeoutMillis" : -1,
"catchUpTakeoverDelayMillis" : 30000,
"getLastErrorModes" : {
"getLastErrorDefaults" : {
"w" : 1,
"wtimeout" : 0
"replicaSetId" : ObjectId("5a542a65e491a43160eb92f0")
zero:PRIMARY>
priority的值表示该机器的权重,默认都为1。
增加一条防火墙规则来阻断通信模拟主机器宕机:
[root@localhost ~]
然后到从机器上查看状态:
zero:SECONDARY> rs.status()
"set" : "zero",
"date" : ISODate("2018-01-09T14:06:24.127Z"),
"myState" : 1,
"term" : NumberLong(4),
"heartbeatIntervalMillis" : NumberLong(2000),
"optimes" : {
"lastCommittedOpTime" : {
"ts" : Timestamp(1515506782, 1),
"t" : NumberLong(4)
"readConcernMajorityOpTime" : {
"ts" : Timestamp(1515506782, 1),
"t" : NumberLong(4)
"appliedOpTime" : {
"ts" : Timestamp(1515506782, 1),
"t" : NumberLong(4)
"durableOpTime" : {
"ts" : Timestamp(1515506782, 1),
"t" : NumberLong(4)
"members" : [
"_id" : 0,
"name" : "192.168.77.128:27017",
"health" : 0,
"state" : 8,
"stateStr" : "(not reachable/healthy)"
,
"uptime" : 0,
"optime" : {
"ts" : Timestamp(0, 0),
"t" : NumberLong(-1)
"optimeDurable" : {
"ts" : Timestamp(0, 0),
"t" : NumberLong(-1)
"optimeDate" : ISODate("1970-01-01T00:00:00Z"),
"optimeDurableDate" : ISODate("1970-01-01T00:00:00Z"),
"lastHeartbeat" : ISODate("2018-01-09T14:06:20.243Z"),
"lastHeartbeatRecv" : ISODate("2018-01-09T14:06:23.491Z"),
"pingMs" : NumberLong(0),
"lastHeartbeatMessage" : "Couldn't get a connection within the time limit",
"configVersion" : -1
"_id" : 1,
"name" : "192.168.77.130:27017",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 1010,
"optime" : {
"ts" : Timestamp(1515506782, 1),
"t" : NumberLong(4)
"optimeDurable" : {
"ts" : Timestamp(1515506782, 1),
"t" : NumberLong(4)
"optimeDate" : ISODate("2018-01-09T14:06:22Z"),
"optimeDurableDate" : ISODate("2018-01-09T14:06:22Z"),
"lastHeartbeat" : ISODate("2018-01-09T14:06:23.481Z"),
"lastHeartbeatRecv" : ISODate("2018-01-09T14:06:23.178Z"),
"pingMs" : NumberLong(0),
"syncingTo" : "192.168.77.134:27017",
"configVersion" : 1
"_id" : 2,
"name" : "192.168.77.134:27017",
"health" : 1,
"state" : 1,
"stateStr" : "PRIMARY",
"uptime" : 1250,
"optime" : {
"ts" : Timestamp(1515506782, 1),
"t" : NumberLong(4)
"optimeDate" : ISODate("2018-01-09T14:06:22Z"),
"electionTime" : Timestamp(1515506731, 1),
"electionDate" : ISODate("2018-01-09T14:05:31Z"),
"configVersion" : 1,
"self" : true
"ok" : 1,
"operationTime" : Timestamp(1515506782, 1),
"$clusterTime" : {
"clusterTime" : Timestamp(1515506782, 1),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
zero:PRIMARY>
如上,可以看到 192.168.77.128 的 stateStr 的值变成 not reachable/healthy 了,而 192.168.77.134 自动切换成主了,也可以看到192.168.77.134 的 stateStr 的值变成 了PRIMARY。因为权重是相同的,所以切换是有一定的随机性的。
接下来我们指定每台机器权重,让权重高的机器自动切换为主。
1.先删除192.168.77.128上的防火墙规则:
[root@localhost ~]# iptables -D INPUT -p tcp --dport 27017 -j DROP
2.回到192.168.77.134机器上,指定各个机器的权重:
zero:PRIMARY> cfg = rs.conf()
zero:PRIMARY> cfg.members[0].priority = 3
zero:PRIMARY> cfg.members[1].priority = 2
zero:PRIMARY> cfg.members[2].priority = 1
zero:PRIMARY> rs.reconfig(cfg)
"ok" : 1,
"operationTime" : Timestamp(1515507322, 1),
"$clusterTime" : {
"clusterTime" : Timestamp(1515507322, 1),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
zero:PRIMARY>
3.这时候192.168.77.128应该就切换成主了,到192.168.77.128上执行rs.config()进行查看:
zero:PRIMARY> rs.config()
"_id" : "zero",
"version" : 2,
"protocolVersion" : NumberLong(1),
"members" : [
"_id" : 0,
"host" : "192.168.77.128:27017",
"arbiterOnly" : false,
"buildIndexes" : true,
"hidden" : false,
"priority" : 3,
"tags" : {
"slaveDelay" : NumberLong(0),
"votes" : 1
"_id" : 1,
"host" : "192.168.77.130:27017",
"arbiterOnly" : false,
"buildIndexes" : true,
"hidden" : false,
"priority" : 2,
"tags" : {
"slaveDelay" : NumberLong(0),
"votes" : 1
"_id" : 2,
"host" : "192.168.77.134:27017",
"arbiterOnly" : false,
"buildIndexes" : true,
"hidden" : false,
"priority" : 1,
"tags" : {
"slaveDelay" : NumberLong(0),
"votes" : 1
"settings" : {
"chainingAllowed" : true,
"heartbeatIntervalMillis" : 2000,
"heartbeatTimeoutSecs" : 10,
"electionTimeoutMillis" : 10000,
"catchUpTimeoutMillis" : -1,
"catchUpTakeoverDelayMillis" : 30000,
"getLastErrorModes" : {
"getLastErrorDefaults" : {
"w" : 1,
"wtimeout" : 0
"replicaSetId" : ObjectId("5a542a65e491a43160eb92f0")
zero:PRIMARY>
如上,可以看到每个机器权重的变化,192.168.77.128也自动切换回主角色了。如果192.168.77.128再宕掉的话,那么192.168.77.130就会是候选主节点,因为除了192.168.77.128之外它的权重最高。
本文转自 ZeroOne01 51CTO博客,原文链接:http://blog.51cto.com/zero01/2059033,如需转载请自行联系原作者
ELK搭建(十一):搭建MongoDB运行情况监控平台
mongoDB作为基于磁盘的非关系型数据库,JSON格式数据存储方式,具有优秀的查询效率。越来越多的场景使用到了MongoDB。在生产运维中,更需要我们能够实时的掌握mongo的运行情况,以方便我们数据库运行问题做出及时的调整和补救。
玩转MongoDB—搭建MongoDB集群
如题,本次玩转MongoDB我们从搭建集群开始,话说MongoDB一共有三种搭建集群的方式,但是由于版本更新,据说在4.0版本之后第一种方式,也就是主从复制的方式被遗弃掉了,大概是因为这种方式的效率不高吧,因为目前我们使用的是5.x版本,因此就不花时间讲解第一种方式了,在其他的文章上摘录了一下,可供大家参考。重点还是要放在后两种。
MongoDB-通过docker搭建一个用来练习的mongodb数据库
目前所在的公司,有部分数据是存储在MongoDB中的,而且目前今后的工作可能会偏向于验证数据,因此需要掌握对这个数据库的一些基本用法,怕有些操作到时候不敢直接在公司数据库上进行操作,先在自己服务器上学习一下基本的用法。

