


让chatGPT帮我找bug 一个MultiPart文件流读取bug记录-java.io.FileInputStream和Tomcat ServletInputStream 差异


背景
为了极致减少内存使用(参考系列文章: # Tomcat 性能调优过程记录系列 - 00 - 关于图片上传Multipart性能和Thrift流式传输 ), 我对我的服务进行了内存使用优化与改造. 以期能够减少内存压力.
有bug的代码
最开始,我对thrift的大对象传输进行了改造. 使用异步调用的方式能够极大的减小内存的占用时间. (此坑待填,目前还未整理出文章). 当时是先做了异步改造.这样可以在使用过程中减短内存的使用生命周期.
原理: 由于同步阻塞调用响应时间过长的时候无法及时释放到参数对象. 而使用异步调用后. 参数在调用完成后就完成了使命. 因此,在等待结果的时候不需要这些参数了.
同时我们也针对servlet的图片输入也在改造接口后, 使用上了内存池化技术来减少内存占用. 我们为了能够方便的控制输入内存. 我们使用了最原始的
httpbody
来传输图片. 这样我们可以从最原始的
HttpServletInputStream
中读取数据.以下是我们的代码.
private ImageFile getImageFromRequestBody(HttpServletRequest request) throws Exception {
ServletInputStream fileInputStream = request.getInputStream();
String contentLength = StringUtils.trimToEmpty(request.getHeader("Content-Length"));
if (StringUtils.isBlank(contentLength) || !StringUtils.isNumeric(contentLength)) {
throw new BadRequestException("请求非法.内容不完整.");
int imgLen = Integer.parseInt(contentLength);
if (imgLen > 1024 * 1024) {
throw new BadRequestException("image too large");
ImageFile imageFile = new ImageFile(imgLen, ImageBytesBufferPool.borrowObject(imgLen));
// Important: 这里把获取到的内存池对象放到线程上线文中. 方便在请求完成的时候进行统一检查释放. 防止内存泄露.
LeoReqContext.set(KEY_IMG_BYTE_BUF, imageFile.getImgBytesBuf());
try {
int nRead = 0;
int loopCnt = 0;
long timeStart = System.currentTimeMillis();
// 循环次数计数
loopCnt++;
int total =(int) imageFile.getImgRealSize();
int offset = (int) imageFile.getSize();
int remaining = (int) (total - offset);
nRead = fileInputStream.read(imageFile.getBytes(), offset, remaining);
if (nRead >= 0) {
imageFile.setSize(imageFile.getSize() + nRead);
} while (nRead != -1);
if (request.getParameter("debug") != null) {
long timeUsed = System.currentTimeMillis();
LOG.info("syncReadImg:loopCnt={},bytePerLoop={},time={}ms",
loopCnt, imgLen / loopCnt, timeUsed - timeStart);
} catch (Exception e) {
LOG.error("读取文件失败......", e);
// 尝试释放和归还上下文中的 池化对象 (防止可能出现的内存泄露)
BufferPoolHelper.tryReleaseBytesBufferFromThreadLocal();
throw new BadRequestException("文件内容错误,接收失败");
return imageFile;
这个代码的核心就是流的读取. 这里使用了一个read到指定内存的指定偏移,且指定了读取数量.
do {
// 循环次数计数
loopCnt++;
// Fixed: 修改为适配池化对象的版本 (done)
int total =(int) imageFile.getImgRealSize();
int offset = (int) imageFile.getSize();
int remaining = (int) (total - offset);
nRead = fileInputStream.read(imageFile.getBytes(), offset, remaining);
if (nRead >= 0) {
imageFile.setSize(imageFile.getSize() + nRead);
} while (nRead != -1);
这个代码在servlet的流的读取一点问题都没有. 线上一直运行得非常畅快. 但是把fileInputStream换成了
java.io.FileInputStream
却导致了bug.
起初并不知道这是什么bug, 因为原始的代码是这样的:
protected ImageFile adaptFrom(MultipartFile file) throws IOException {
if (file == null) {
return null;
ImageFile imageFile = null;
try {
// 这里直接从 MultipartFile 获取的 inputstream.
imageFile = getImageFromFileInputStream(file.getInputStream(), (int) file.getSize());
// some other code
return imageFile;
} catch (Exception e) {
LOG.error("adaptFrom error", e);
LeoMonitor.recordException(e);
LeoMonitor.recordOne("adaptFromMultipartError");
throw new RuntimeException(e);
具体的表现是线上的机器CPU占到了 100%. 如下图:


我使用
async-profiler
(
git 地址
)进行采样进行了分析.
注: async-profrofiler是一个零侵入的线上性能诊断工具. 不需要JDK进行额外的配置. 非常方便. 强烈安利推荐.
得到了如下的图, 这样大概就可以定位到代码是在哪出了问题.


由于这个是从一个复杂的multipart返回的inputstream. 而multipart又是不确定的对象. 展开说就是:Multipart由于是Spring的封装, 不地的场景下给到的实现可能不一样. 比如有可能是:


而Multipart在不同的场景下, 返回的inputstream又会有所不同. 如果这个multipart使用了内存缓存,并且实际并没有落盘.那最终返回的就是:
java.io.ByteArrayInputStream


这两者在不同的环境中都分别出现了. 在我的实际调试的本地环境, 并没有抓取到
FileInputStream
而是:
ByteArrayInputStream
; 但是我使用线上诊断得到的堆栈确实是
FileInputStream
, 而且使用
ByteArrayInputStream
在本地调试的时候并没有复现这个bug.
因此,我问了chatGPT; 我首先是问了其如果要在multipart中进行标准的inputstream流读取. 那一般的样例代码是怎样的. 或许我的代码有什么bug我也拿不准. 因为这个multipart到底是何方神圣,返回的又是什么inputStream,在编程场景下都无法得知.
注: 因为我并不确认我的代码会有什么问题, 上面的代码是直接从读取servletInputStream直接切换到读取从Multipart中获取到的流.
它给了我这样的答案:
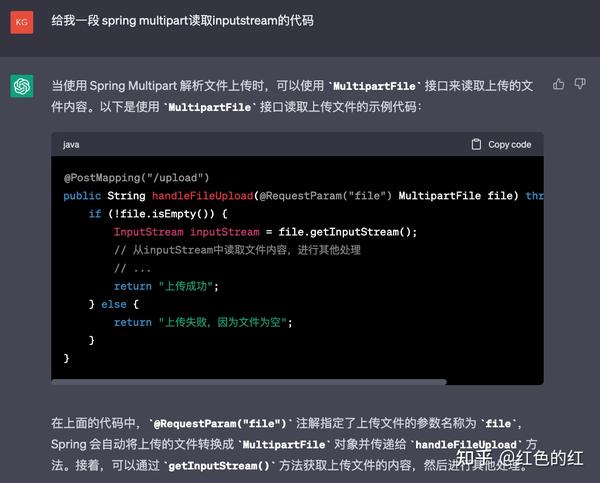

看起来是有模有样. 但是却把我要看的关键的IO读取的代码给省略了. 好吧,我再引导一下它.看看他能不能给我正确的答案.:
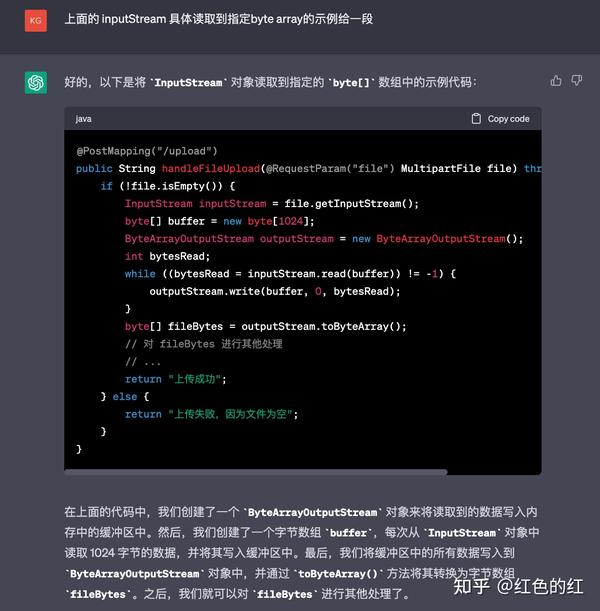

这个代码也不能说不对, 但是效果总不是那么高.
- 中间用了一个1k的buffer用于临时读取内容存储.
- 读到了后又用了一个ByteArrayOutputStream来接收读取到的内容.
- 最后再把 ByteArrayOutputStream 中的内容转成一个 byte array.
这个实际上是比较标准的做法, 如果看一下apache的IOUtils.toByteArray的实现实际上跟这个也差不了太多. 但是中间有过多的内存中转, 使用到了过多的数据扩容以及多次拷贝. 这个效果肯定效率高不了. 因此我想再引导他一下:
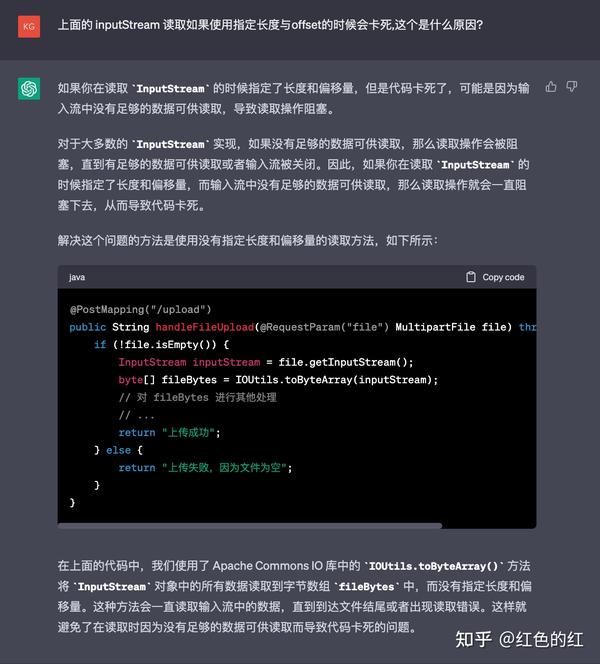

在这里,我并没有先让它把使用直接读取到byte array的代码版本给我. 或者说不要使用这么多次的拷贝和buffer. 可能我有一些心急.
这里明显可能是把ChatGPT给引导偏了. 或者说是我的问法有一些问题. 大家把问题点聚集到了 "阻塞" , 实际这里我们遇到的并不是一个传统的阻塞, 而是一个类似于死循环的 CPU 100%.
而问到这里, 它明显被带偏了, 没有正面给我直接读取到byte中且是指定偏移与长度的版本. 而是把关注点到了
阻塞
上面. 同时给我了一个
IOUtils
的版本. 并且还省略了细节.
在明显把
chatGPT
带偏的情况下, 我也不想再引导它了. 那直接把错误的代码给他看看帮帮改一下BUG吧.:
首先是我的提问:


可以是被我带偏了, 还是在围绕着阻塞在找bug.


说得的确挺有道理. 如果在读取量大. 而且io慢的时候可能会有阻塞. 也就是上面的带偏的卡死. 但是实际上面有1M大小的限定,这个本身不是问题.
而 chatGPT已经陷在这里了, 同时给了我一个优化后的读取方法:
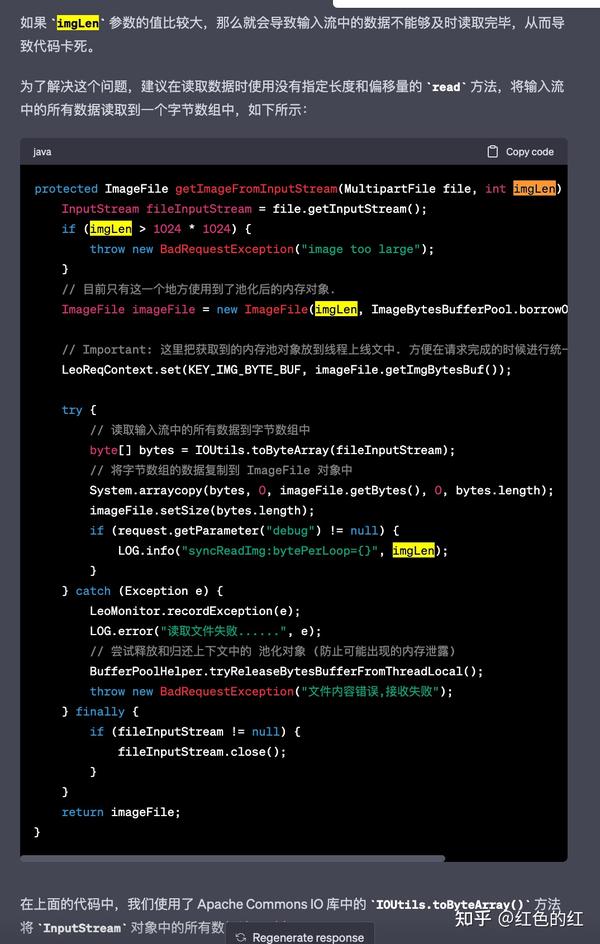

这个代码虽然是围绕阻塞, 但是实际他确实能够解决我的bug. 后面再说为什么. 只是这个版本又回到了使用IOUtils的版本. 中间的拷贝方法实际就是上面的最开始的样例代码那样. 必然会有很多的数组的扩容和最后的拷贝操作. 这样内存操作使用的内存最实际上也会非常大. 这里节约内存的目的显示就没有达到了.
真正的BUG以及原因
我的原始代码中的bug实际上是产生了死循环, 由于读取一直没有退出才会导致CPU 100%. 我们再看一下这段代码:
do {
// 循环次数计数
loopCnt++;
// Fixed: 修改为适配池化对象的版本 (done)
int total =(int) imageFile.getImgRealSize();
int offset = (int) imageFile.getSize();
int remaining = (int) (total - offset);
nRead = fileInputStream.read(imageFile.getBytes(), offset, remaining);
if (nRead >= 0) {
imageFile.setSize(imageFile.getSize() + nRead);
} while (nRead != -1);
这段代码是要以读取结束(即:
EOF
) 为标记, 也就是这里判定的
-1
来判定读取结束的. 这段代码也是当时读取异步servelt的body的时候得到的大概样例代码.
这里有一个潜在的bug. 如果上一次读取到了文件的结束. 那在上一次读取的结果的时候
nRead
就不为
-1
就会再一次的进行读取. 但是这个时候要
读取的字节数为0
; 也就是说如果IO的实现在读取0字节的时候.且是已经到了io输入流的结束的时候. 这个时候优先返回的是
-1
, 即结束标记. 那上面的代码就没有问题.
如果, 在遇到了文件末尾. 但是又是一次0字节的读取. 这个时候如果不先判定是否文件已经结束. 而是先看读取的字节数. 那就有可能返回
0
. 那这个时候就会:
永远读取0字节.且判定没有结束,下次再读取0字节,以此往复.最后产生死循环.
这个想法也比较好验证. 直接读取0字节.且在文件结束的时候看会返回什么:
public class FileReadZeroTest {
@Test
public void testReadFileEndWithZero() throws IOException {
URL resource = this.getClass().getClassLoader().getResource("img_math_02.jpg");
System.out.println(resource);
if (resource != null) {
System.out.println(resource.getFile());
File aFile = new File(resource.getFile());
if (aFile.exists() && aFile.isFile()) {
// 202523
// 模拟申请大于原内存 64字节
byte[] buffer = new byte[(int) aFile.length() + 64];
System.out.println(aFile.length());
FileInputStream fileInputStream = new FileInputStream(aFile);
int realSize = (int) aFile.length();
int curSize = 0;
try {
int nRead = 0;
int loopCnt = 0;
long timeStart = System.currentTimeMillis();
// 循环次数计数
loopCnt++;
// Fixed: 修改为适配池化对象的版本 (done)
int total = (int) realSize;
int offset = (int) curSize;
int remaining = (int) (total - offset);
System.out.println("remaining:"+remaining);
// Fixed: 修改为适配池化对象的版本 (done)
nRead = fileInputStream.read(buffer, offset, remaining);
if (remaining == 0) {
Assert.assertEquals(0, nRead);
return;
if (nRead >= 0) {
curSize += nRead;
System.out.println("nRead:" + nRead);
} while (nRead != -1);
} catch (Exception e) {
System.out.println(e);
}finally {
if (fileInputStream != null) {
fileInputStream.close();