添加数据
有了上面查询数据的基础,我们再来看下插入数据, 我们同样以正常的mysql语句再结合aiomysql中的query语句进行对比。
1. 插入单条语句
经过表的修改,目前我们的表字段如下
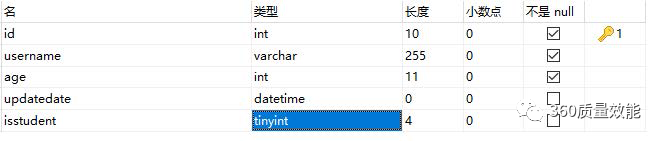
其中id为主键自增,新添加的时候可以不用传参数,mysql会自动添加, username和age是不能为空的,添加的时候必须要传
INSERT INTO `user` (username, age) VALUES ("aaa", 24);
使用aiomysql来添加
async with conn.cursor() as cur:
count = await cur.execute("insert into user (username, age, updatedate) VALUES(%s, %s, %s)", ("ccc", 33, datetime.datetime.now())) await conn.commit()
print(count) if count:
r = await cur.fetchall() for i in r: print(i) print("#########")
count = await cur.execute("select * from user") if count:
r = await cur.fetchall() for i in r: print(i) else: print("no user")
对于日期类型的数据,我们也无需进行处理,直接传入参数即可
2. 插入多条语句
async with conn.cursor() as cur:
users = [
("eee", 26, datetime.datetime(2019, 10, 23)),
("fff", 28, datetime.datetime(2018, 11, 13)),
("ggg", 27, datetime.datetime(2016, 9, 15)),
count = await cur.executemany("insert into user ( username, age, updatedate) VALUES(%s, %s, %s)", users) print(count) if count:
r = await cur.fetchall() for i in r: print(i) print("#########")
count = await cur.execute("select * from user") if count:
r = await cur.fetchall() for i in r: print(i) else: print("no user")
for arg in args:
await self.execute(query, arg)
rows += self._rowcountself._rowcount = rows
如何处理插入失败
插入失败常有,比如主键重复,数据类型不对等,我们需要去抓住这些异常来进行处理
count = await cur.execute("insert into user (id, username, age, updatedate) VALUES(%s, %s, %s, %s)",(1, "ddd", 34, datetime.datetime.now()))
pymysql.err.IntegrityError: (1062, "Duplicate entry '1' for key 'PRIMARY'")
async with conn.cursor() as cur: try:
count = await cur.execute("insert into user (id, username, age, updatedate) VALUES(%s, %s, %s, %s)", (1, "ddd", 34, datetime.datetime.now())) print(count) except pymysql.err.IntegrityError as e: print(e) except Exception as e: raise e
cursor 类型
(1, 'yanyanxin', 18, datetime.datetime(2020, 10, 31, 16, 43, 8), 0)
(2, 'yyx', 28, datetime.datetime(2020, 11, 1, 21, 44, 35), 2)
(3, 'aaa', 24, None, None)
(8, 'ccc', 33, datetime.datetime(2020, 11, 2, 17, 59, 38), None)
(27, 'aaa', 16, None, None)
可以使用 aiomysql.cursors.DictCursor 类初始化
conn.cursor(aiomysql.cursors.DictCursor) as cur
获取到的结果将以字典的形式返回
{'id': 1, 'username': 'yanyanxin', 'age': 18, 'updatedate': datetime.datetime(2020, 10, 31, 16, 43, 8), 'isstudent': 0}
{'id': 2, 'username': 'yyx', 'age': 28, 'updatedate': datetime.datetime(2020, 11, 1, 21, 44, 35), 'isstudent': 2}
{'id': 3, 'username': 'aaa', 'age': 24, 'updatedate': None, 'isstudent': None}
{'id': 8, 'username': 'ccc', 'age': 33, 'updatedate': datetime.datetime(2020, 11, 2, 17, 59, 38), 'isstudent': None}
{'id': 27, 'username': 'aaa', 'age': 16, 'updatedate': None, 'isstudent': None}
连接池的使用
之前我们一直使用 aiomysql.connect() 方法来连接到数据库,aiomysql 还提供了连接池的接口,有了连接池的话,不必频繁打开和关闭数据库连接。
上面的代码,我们都是执行一个函数就创建一个连接,我们知道,客户端在与服务端创建连接也是一个比较耗时耗资源的操作,所以我们会通过连接池来减少与mysql数据库的频繁打开和关闭连接。
loop = asyncio.get_event_loop()async def test():
conn = await aiomysql.connect(
host='127.0.0.1',
port=3306,
user='root',
password='123456',
db='mytest', loop=loop
) async def get_user(): async with conn.cursor() as cur:
count = await cur.execute("select * from user") if not count: return
r = await cur.fetchall() print("get data from user") for i in r: print(i) async def get_jobs(): async with conn.cursor() as cur:
count = await cur.execute("select * from jobs") if not count: return
r = await cur.fetchall() print("get data from jobs......") for i in r: print(i) await asyncio.gather(get_jobs(), get_user())loop.run_until_complete(test())
我们在test() 函数里写了两个子函数,get_user和get_jobs分别从user表和jobs表中获取数据,当然我们可以使用
await get_user()await get_jobs()
来分别执行,但是这种方式是同步的,并没有异步去执行,我们想要这两个函数异步进行,所以我们使用
await asyncio.gather(get_jobs(), get_user())
这种方式调用,让这两个协程并行执行, 但是这样写就会报错
RuntimeError: readexactly() called while another coroutine is already waiting for incoming data
所以这里我们需要用两个不同的连接, 当然可以在每个函数中都重新对mysql数据进行连接,在执行完查询操作以后再关闭,但是这样就会造成之前说有频繁的创建连接会造成一些资源的浪费,同时网站的性能也会受到影响。
所以这时我们需要使用连接池,连接池会保存一定数量的连接对象,每个函数在需要使用的时候从池子中拿一个连接对象, 使用完以后再将连接对象放到池子中, 这样避免了频繁的和mysql数据库进行打开关闭操作,同时也避免出现上面的同个连接在不同的协程对象中使用而出现的异常。
loop = asyncio.get_event_loop()async def test():
pool = await aiomysql.create_pool(
host='127.0.0.1',
port=3306,
user='root',
password='123456',
db='mytest',
minsize=1,
maxsize=2,
echo=True,
autocommit=True,
loop=loop
)async def get_user():
async with pool.acquire() as conn: print(id(conn), 'in get user') async with conn.cursor() as cur:
count = await cur.execute("select * from user") if not count: return
r = await cur.fetchall() print("get data from user") for i in r: print(i)async def get_jobs():
async with pool.acquire() as conn: print(id(conn), 'in get jobs') async with conn.cursor() as cur:
count = await cur.execute("select * from jobs") if not count: return
r = await cur.fetchall() print("get data from jobs......") for i in r: print(i)async def get_email():
async with pool.acquire() as conn: print(id(conn), 'in get email') async with conn.cursor() as cur:
count = await cur.execute("select * from email") if not count: return
r = await cur.fetchall() print("get data from email......") for i in r: print(i)await asyncio.gather(get_jobs(), get_user(), get_email())
loop.run_until_complete(test())
连接池的初始化函数 aiomysql.create_pool 和 aiomysql.connect 参数差不多,数据库的基本信息, 这里多了两个参数 minsize,maxsize, 最少连接数和最大连接数,我这里为了实验,将最大连接数设置为2,然后下面用了三个函数来获取连接池,我们将连接对象conn的id信息打印出来看下
2977786527496 in get jobs2977786527496 in get user2977786590984 in get email
上面的脚本也不再报错,并且可以正常的获取到数据库里的信息,且都是异步的进行查询
我们也要注意一下,由于是演示代码,我们在开发过程中,不太会写这样的代码,更多的时候,我们是写web程序,比如用tornado 写个web程序, 不同的接口需要进行不同的查询操作,为了保证查询同时进行,此时我们就需要用连接池了。
事务的处理
关于事务的介绍,网上有好多,关于数据库事务具有ACID这4个特性:原子性,一致性,隔离性,持久性以及不同的隔离级别所带来的脏读、不可重复读、幻读等问题,推荐廖雪峰的sql教程, 讲的很清晰。
这里介绍一下在aiomysql中事务的处理,
之前我们在初始化连接或者连接池的时候,都加上了autocommit=True, 这个设置, autocommit=True
async with pool.acquire() as conn: async with conn.cursor() as cur: await cur.execute("insert into user(username, age) values(%s, %s)", ("aaa", 16)) # 不调用conn.commit()
c = await cur.execute("select * from user")



