


谷歌新作ViT-22B:将视觉Transformer扩展到220亿参数

一句话总结
最大的视觉Transformer模型来了!ViT-22B 包含220亿参数,并提出高效稳定训练方法,还进行了各种实验(分类、分割等),显示出随着规模的增加而性能的提高。
点击关注 @CVer计算机视觉 ,第一时间看到最优质、最前沿的CV、AI工作~
点击进入—> Transformer微信技术交流群
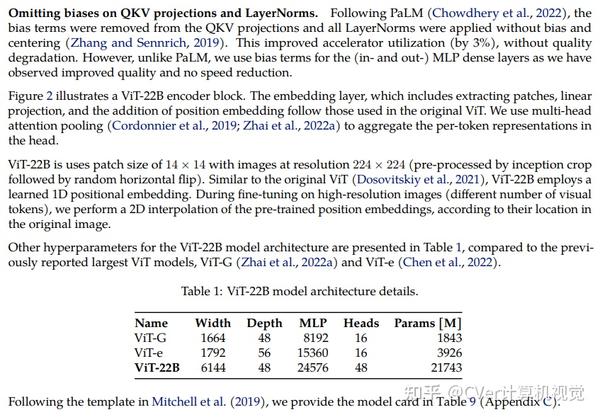
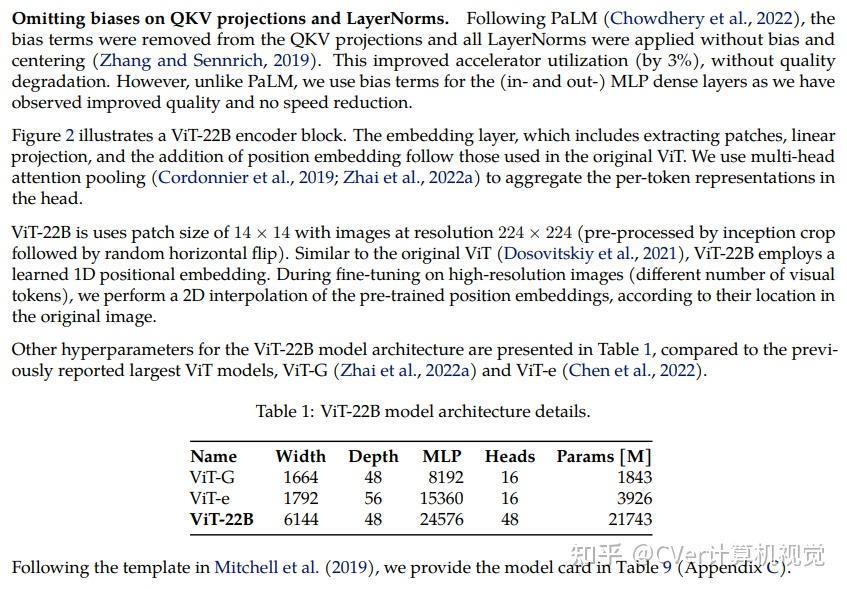
ViT-22B


Scaling Vision Transformers to 22 Billion Parameters
单位:谷歌(42位作者,含ViT等代表作大佬)
论文: https:// arxiv.org/abs/2302.0544 2
Transformer的扩展推动了语言模型的突破性能力。目前,最大的大型语言模型(LLM)包含超过100B的参数。视觉Transformer(ViT)已经将相同的架构引入到图像和视频建模中,但这些架构尚未成功扩展到几乎相同的程度;最大的ViT包含4B个参数(Chen等人,2022)。
我们提出了一种22B参数ViT(ViT-22B)的高效稳定训练方法,并对所得模型进行了各种实验。
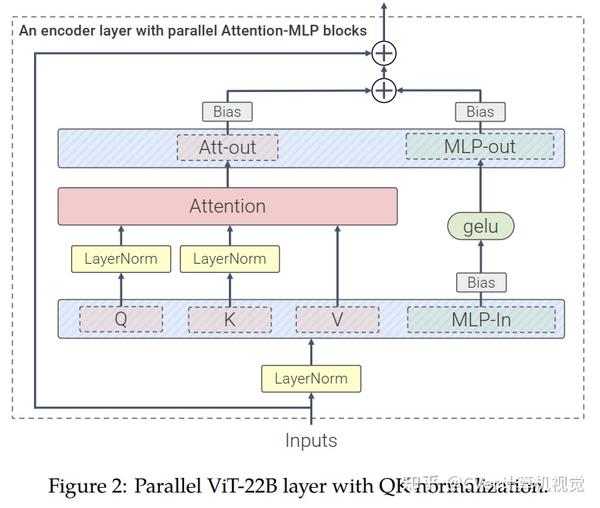
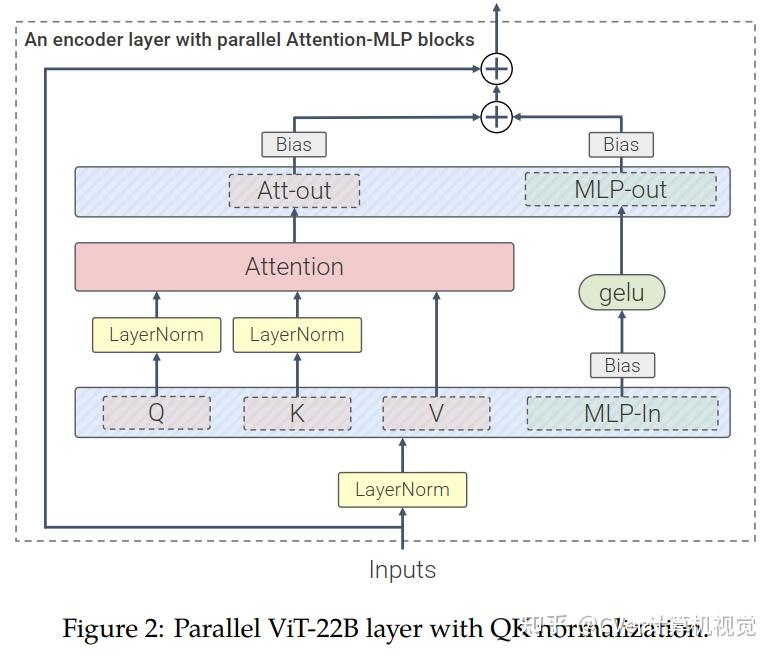
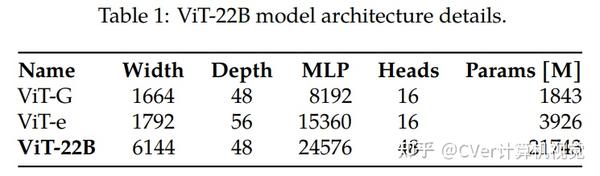
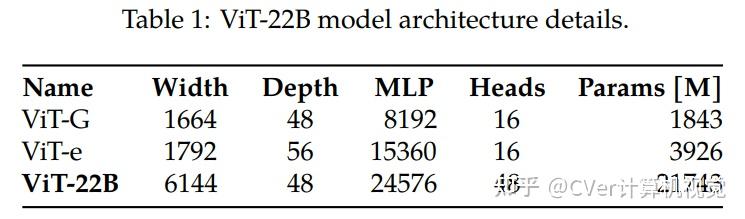
算法细节


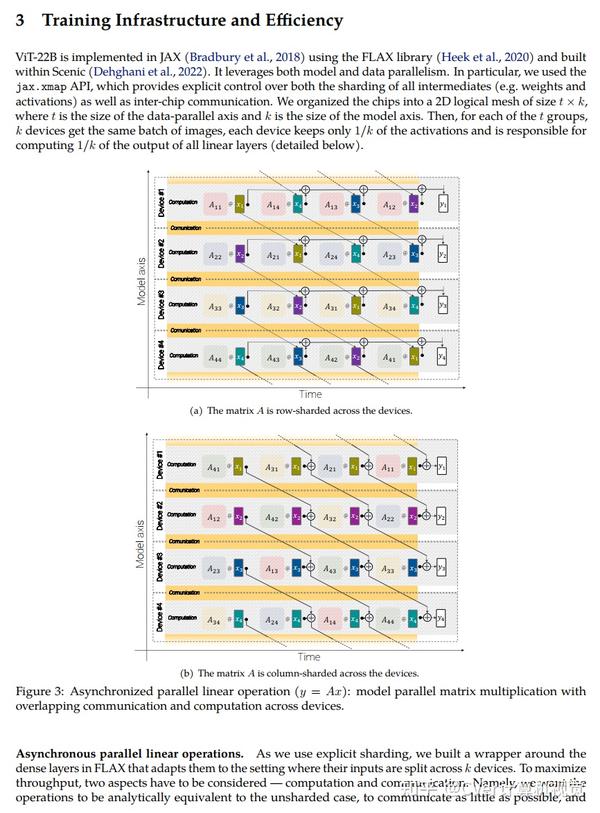
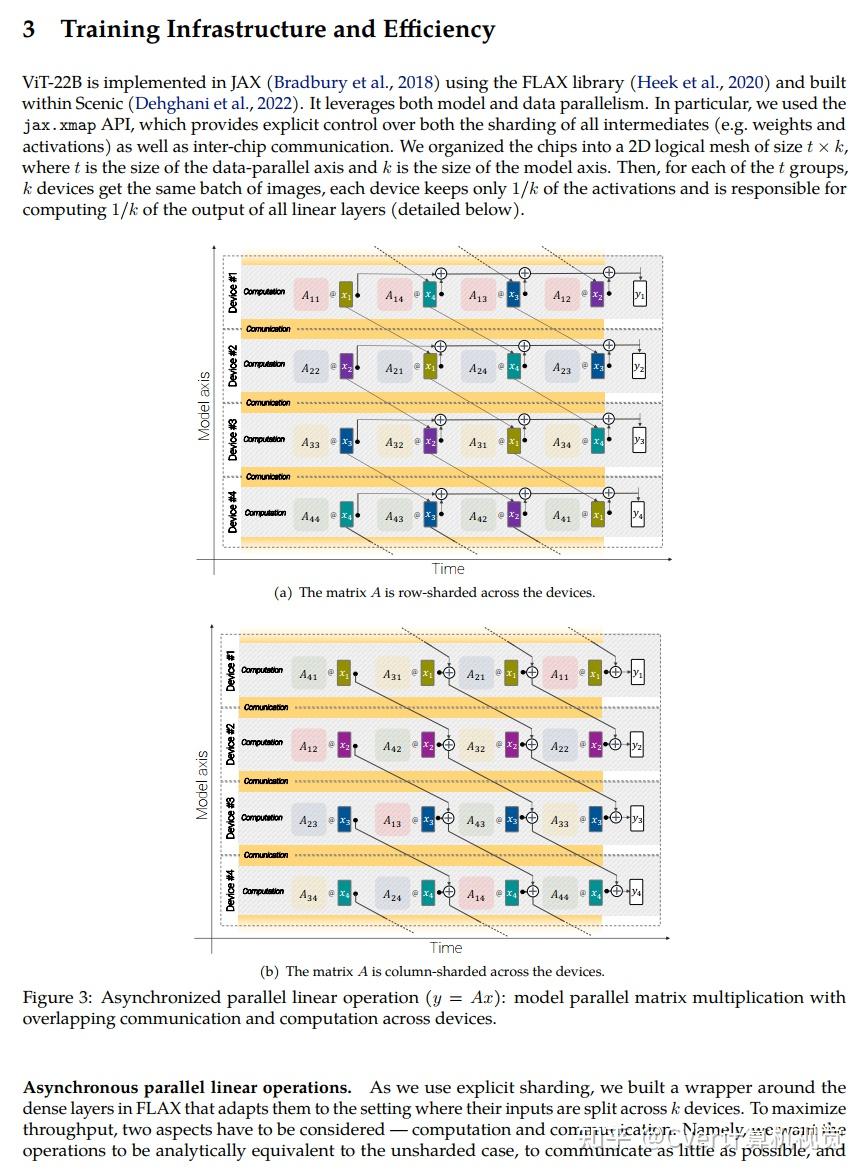


实验结果
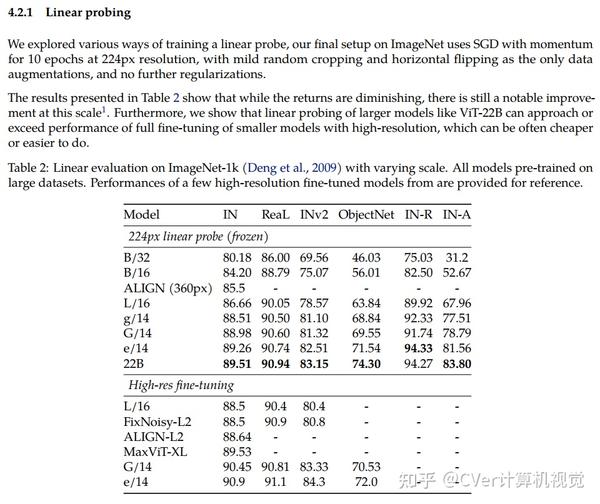
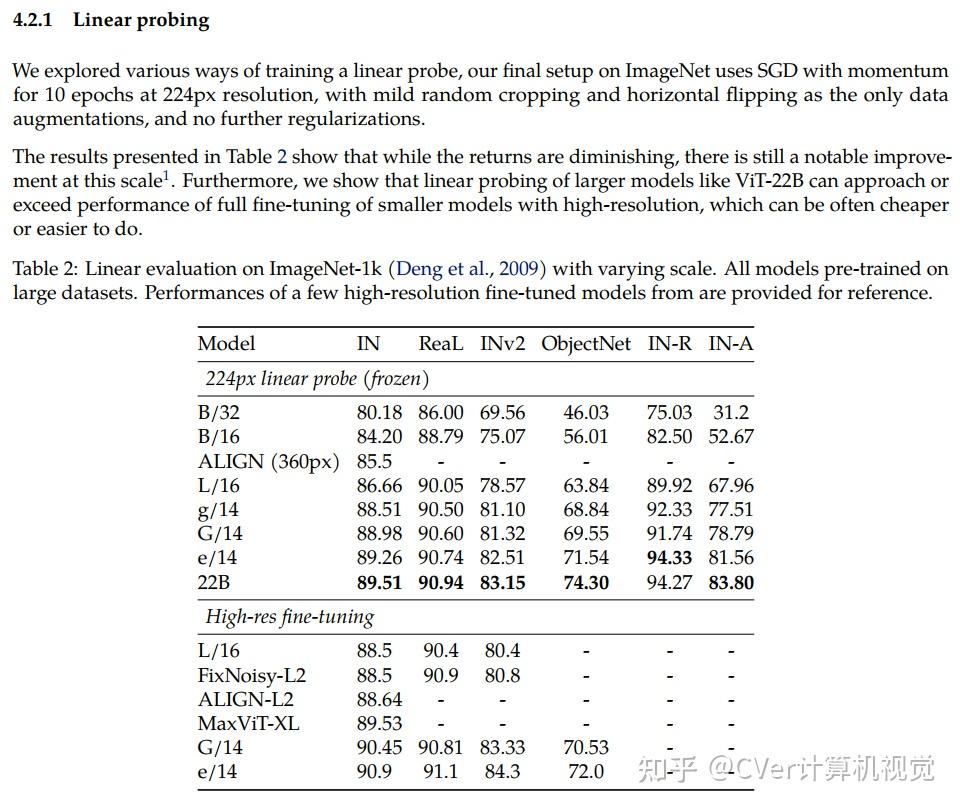
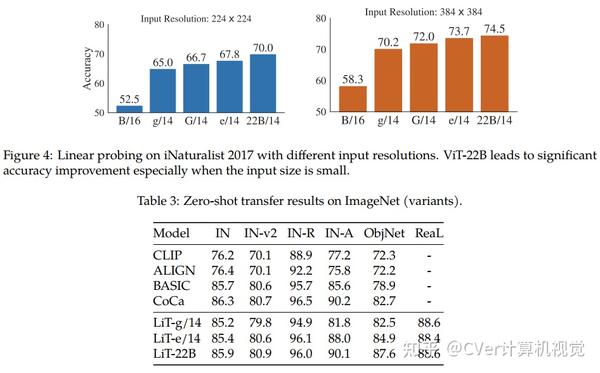
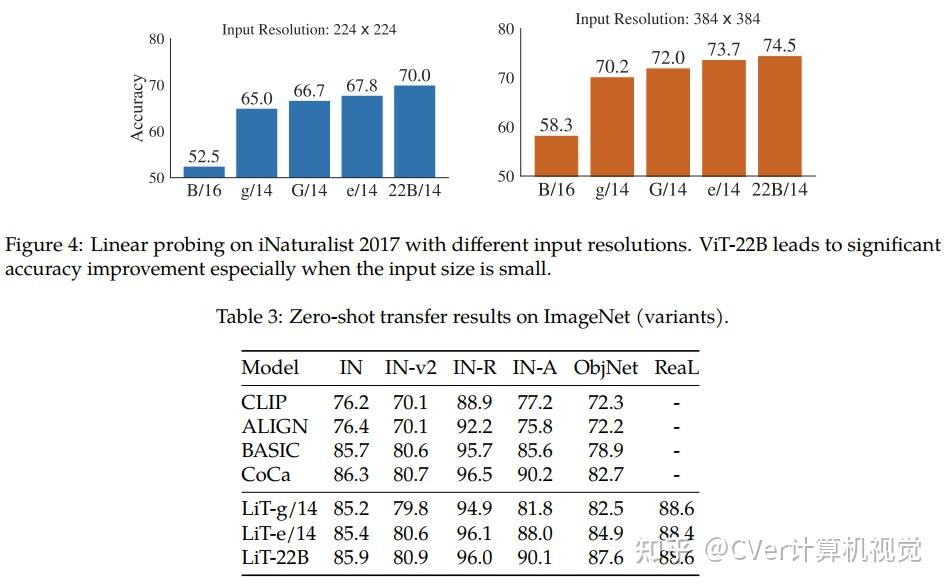
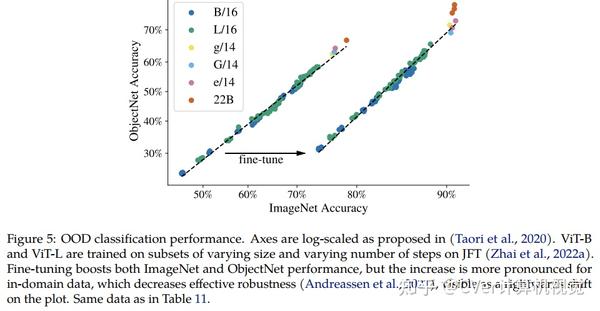
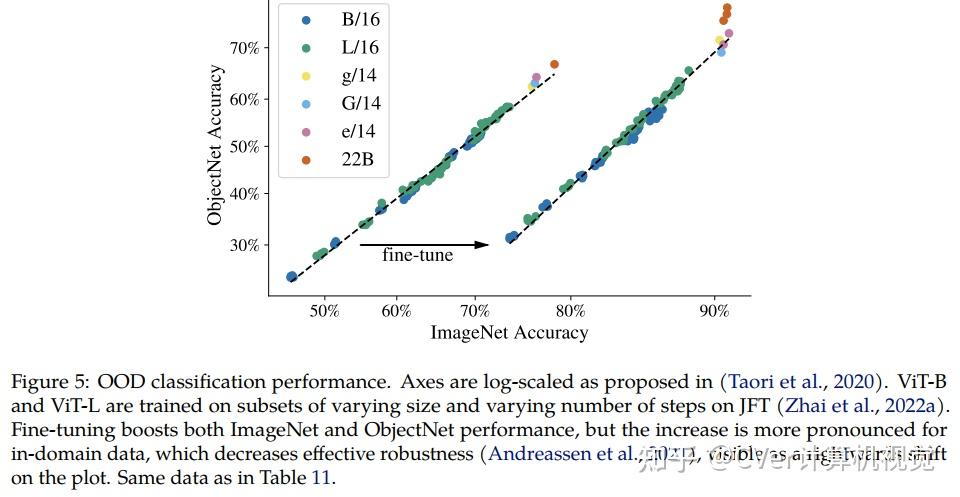
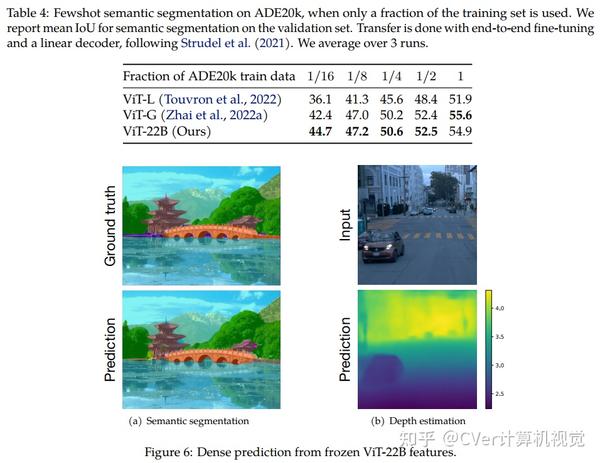
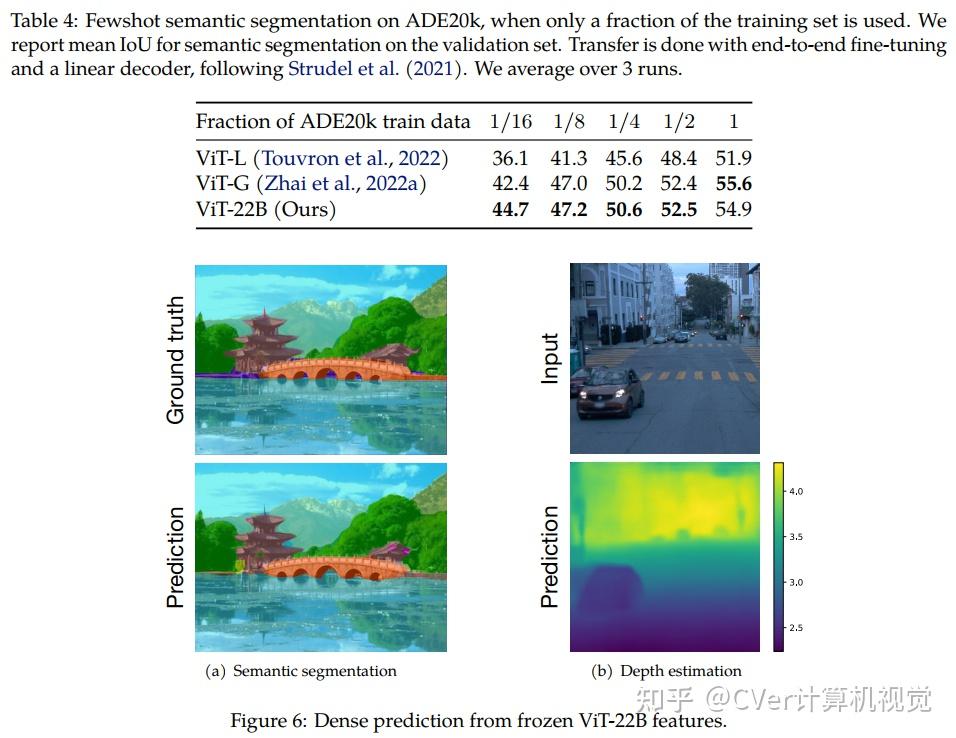
当对下游任务进行评估时(通常使用冻结特征的轻量级线性模型),ViT-22B显示出随着规模的增加性能的提高。我们进一步观察到规模的其他有趣的好处,包括公平性和性能之间的改进权衡,在形状/纹理偏差方面与人类视觉感知的最新对齐,以及改进的鲁棒性。ViT-22B展示了“类似LLM”的视觉扩展潜力,并提供了实现这一目标的关键步骤。
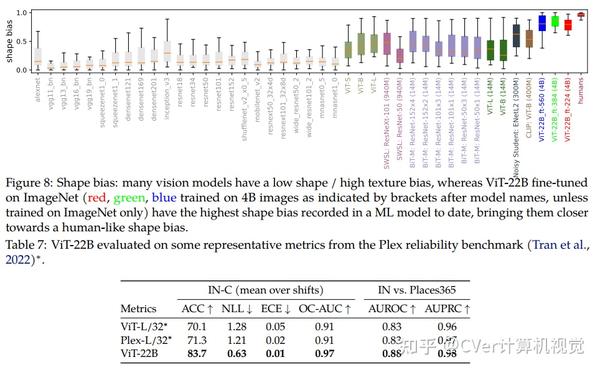
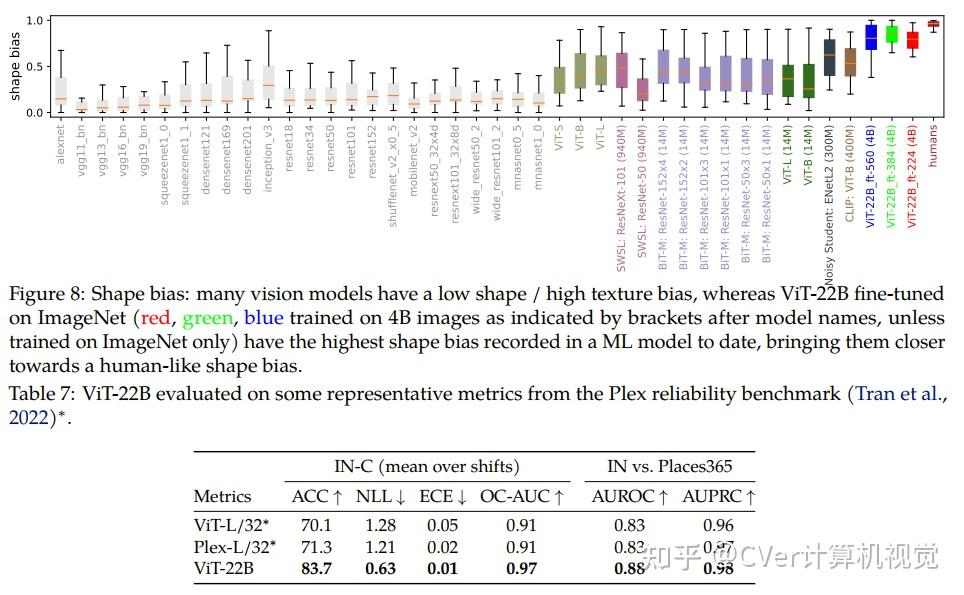
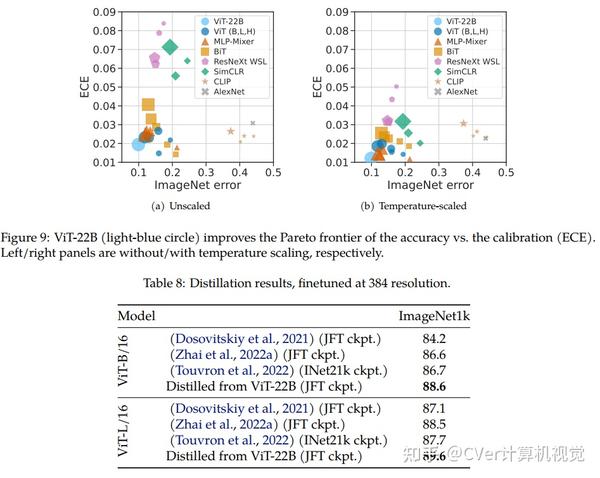
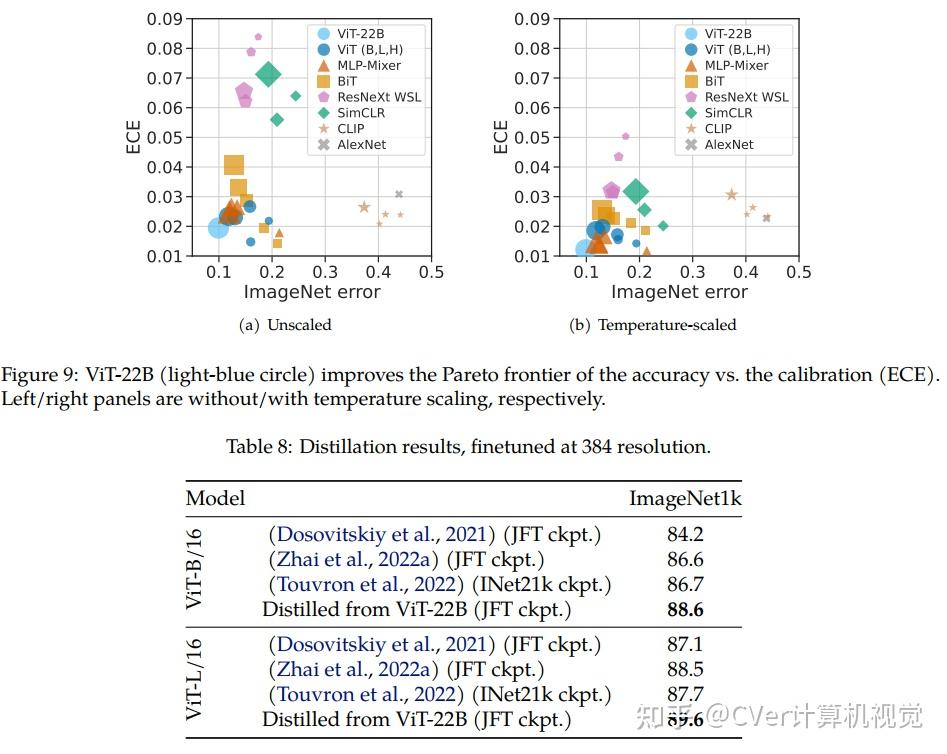
点击进入—> Transformer微信技术交流群
CVer-Transformer交流群
建了CVer-Transformer交流群!想要进Transformer学习交流群的同学,可以直接加微信号: CVer222 。加的时候备注一下: Transformer+学校/公司+昵称+知乎 ,即可。然后就可以拉你进群了。
推荐阅读
ICLR 2023 | 斯坦福提出DDM2:基于生成扩散模型的自监督扩散MRI去噪
BLIP-2:使用冻结图像编码器和大型语言模型的语言-图像预训练
MedSegDiff-V2:基于Transformer和扩散模型的医学图像分割
涨点显著!FAIR提出CutLER:用于无监督目标检测和实例分割的切割和学习
ConvNeXt V2来了!使用MAE共同设计和扩展ConvNet
替换U-Net!DiT:基于Transformer的可扩展扩散模型
NMS(非极大值抑制)的反击!DETA:基于Transformer的新目标检测器
CCF论文列表(2022拟定)大更新!MICCAI空降B类!PRCV空降C类!ICLR继续陪跑...
65.4 AP刷新COCO目标检测新记录!InternImage:探索具有可变形卷积的大规模视觉基础模型
Sea和北大提出新优化器Adan:深度模型都能用!训练ViT和MAE减少一半计算量!
