|
|
|


求一款能批量自动根据pdf内容固定标题重命名pdf文件名字的软件?
关注者
5
被浏览
10,244
登录后你可以
不限量看优质回答
私信答主深度交流
精彩内容一键收藏

爱好:胡思乱想
——stay young, stay simple
可以尝试结合多个程序来实现。
首先需要准备以下 3 个不同功能的程序:
- OCR 程序:用于直接 PDF 截图中的文字
- PDF 截取程序:用于从给定 Pdzf文件中截取指定区域的截图
- 文件重命名程序:根据前面程序的输出对 PDF 文件进行重命名
最终代码和演示效果在 第四部分 ,不想看中间过程的话可以直接跳转过去。
一、OCR 程序
这里就以 tesseract 命令行工具为例:
它是谷歌开源的 Tesseract-OCR 引擎,支持对多种语言文字的 OCR(识别图像中的文字)。
安装方法:
支持 Windows、macOS、Linux 等多种操作系统
使用方法:
-
安装完成后,可以在命令行中直接调用
tesseract命令来完成对特定图片中文字的识别:
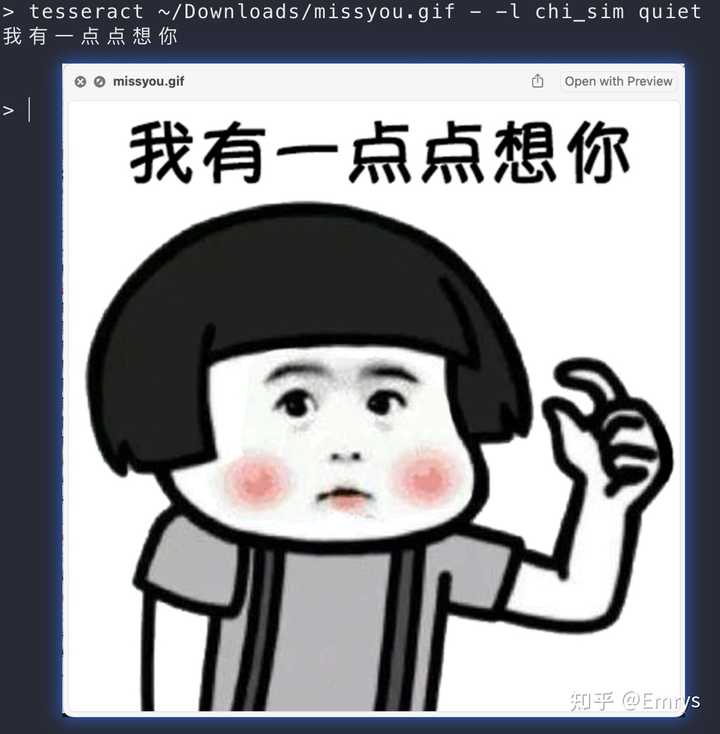
tesseract [要识别的图片文件路径] - -l eng quiet
其中第一个参数
-
表示将识别结果直接显示在命令行里。
-l eng
参数指定了要识别的文字语言是英语。如果图片中同时包含多种语言(如中文和英文),则可以通过
-l eng+chi_sim
来指定以
英文
为
主要
识别语言、
简体中文
为
次要
识别语言。
末尾的
quiet
参数用于禁止程序执行时显示的一些中间日志,从而只会输出最终识别的文字。
执行tesseract --list-langs命令可以查看当前安装程序支持识别的所有语言。
部分语言关键词的含义:chi_sim 表示简体中文,chi_sim_vert 表示竖排的简体中文,chi_tra 和 chi_tra_vert 表示相应的繁体中文。
运行效果:

二、PDF 截取程序 [1]
这里以
pdftk
和
magick
两个命令行工具为例。
-
pdftk只用于处理 PDF 文件存在多页的情况,下面会用此工具将 PDF 文件的特定页单独提取出来。 -
magick用于从单页 PDF 文件中截取指定的区域,并保存为图片。 -
【可选】
pdftoppm也可以用于实现 从单页 PDF 文件中截取指定的区域,并保存为图片的功能。
安装方法:
使用方法:
-
安装完成后,可以在命令行中直接调用
pdftk命令来提取 PDF 文件Pies for Daily.pdf的第一页并保存为新 PDF 文件1st_page_percent_burned_pie.pdf。如果要提取取其他页,只需要修改cat后面的数字即可。
如果提取的 PDF 页中文字方向旋转了 90 度,则可以将cat 1参数改为cat 1right或cat 1left来旋转整个 PDF 页,使得文字为正常方向。
pdftk "Pies for Daily.pdf" cat 1 output ~/Downloads/1st_page.pdf-
接着,在命令行中调用
magick命令来完成对 PDF 文件的指定区域的截图。
下面例子中
-crop 640x480+50+100
参数指定了截取图片区域大小为
宽640 × 高480
,并且矩形区域到页面左边缘的距离为
50
, 到页面顶部的距离为
100
。
-density 200
参数指定了渲染 PDF 文件时采用的 DPI,数值越大清晰度越高,但相应的文件体积也越大。
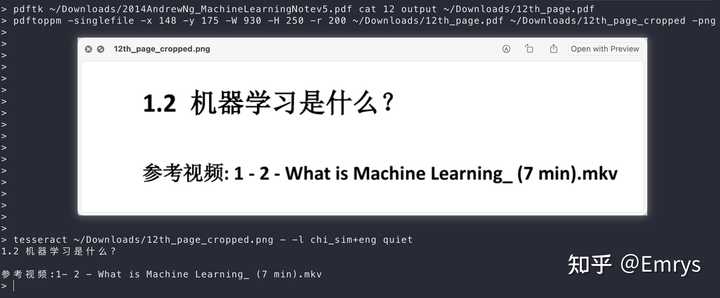
magick -density 200 ~/Downloads/1st_page.pdf -crop 930x250+148+175 +repage ~/Downloads/1st_page_cropped.pdf
magick -density 600 ~/Downloads/1st_page_cropped.pdf -quality 100 -background white -alpha background -alpha off -colorspace RGB ~/Downloads/1st_page_cropped.png
# 【可选】以下命令实现的效果与上面等价
pdftoppm -singlefile -x 148 -y 175 -W 930 -H 250 -r 200 ~/Downloads/1st_page.pdf ~/Downloads/1st_page_cropped -png【注】在安装好magick工具包之后,可以通过附带的identify命令来查看 PDF 文件的页面大小信息:
identify -format "%[pdf:HiResBoundingBox]" 1st_page.pdf
输出格式类似于:595.32x841.92+0+0
需要注意的是,这里输出的数值是在默认 density 为 72×72 的情况下计算的,因此当我们手动指定新的 density(如-density 200)时,需要将相应的WxH+X+Y格式串中的 W、H、X、Y 的数值乘以相应的倍数(如 200 / 72 ≈ 2.78 倍)。
确定要截取的 PDF 区域通常需要手动进行尝试和调整,也可以利用文末【附录】中的方法利用代码配合 PDF 标注功能来快速定位。
运行效果:



三、文件重命名程序
有了上一步 OCR 的识别结果,我们只需要将识别结果存放到临时变量中,然后利用系统自带的文件重命名命令就可以完成操作。
① Windows(PowerShell)
pdftk "\文件路径\要处理的文件名称.pdf" cat 1 output ~\Downloads\1st_page.pdf
magick -density 200 ~\Downloads\1st_page.pdf -crop 930x250+148+175 +repage ~\Downloads\1st_page_cropped1.pdf
magick -density 600 ~\Downloads\1st_page_cropped1.pdf -quality 100 -background white -alpha background -alpha off -colorspace RGB ~\Downloads\1st_page_cropped1.png
# 【可选】以下命令实现的效果与上面等价
pdftoppm -singlefile -x 148 -y 175 -W 930 -H 250 -r 200 ~\Downloads\1st_page.pdf ~\Downloads\1st_page_cropped1 -png
$name_ocr_result = $(tesseract ~\Downloads\1st_page_cropped1.png - -l chi_sim+eng quiet)
magick -density 200 ~\Downloads\1st_page.pdf -crop 430x180+190+200 +repage ~\Downloads\1st_page_cropped2.pdf
magick -density 600 ~\Downloads\1st_page_cropped2.pdf -quality 100 -background white -alpha background -alpha off -colorspace RGB ~\Downloads\1st_page_cropped2.png
# 【可选】以下命令实现的效果与上面等价
pdftoppm -singlefile -x 148 -y 175 -W 930 -H 250 -r 200 ~\Downloads\1st_page.pdf ~\Downloads\1st_page_cropped2 -png
$number_ocr_result = $(tesseract ~\Downloads\1st_page_cropped2.png - -l chi_sim+eng quiet)
# 替换不能作为文件名的字符\/:*?"<>|
$name_ocr_result = $name_ocr_result -Replace '[|\\/:*?"]', "_" -Replace "<", "(" -Replace ">", ")"
$number_ocr_result = $number_ocr_result -Replace '[|\\/:*?"]', "_" -Replace "<", "(" -Replace ">", ")"
Rename-Item -Path "\文件路径\要处理的文件名称.pdf" -NewName "结构-竣工图(-$number_ocr_result-$name_ocr_result).pdf"② macOS / Linux(Bash)
pdftk "/文件路径/要处理的文件名称.pdf" cat 1 output ~/Downloads/1st_page.pdf
magick -density 200 ~/Downloads/1st_page.pdf -crop 930x250+148+175 +repage ~/Downloads/1st_page_cropped.pdf
magick -density 600 ~/Downloads/1st_page_cropped.pdf -quality 100 -background white -alpha background -alpha off -colorspace RGB ~/Downloads/1st_page_cropped1.png
# 【可选】以下命令实现的效果与上面等价
pdftoppm -singlefile -x 148 -y 175 -W 930 -H 250 -r 200 ~/Downloads/1st_page.pdf ~/Downloads/1st_page_cropped1 -png
name_ocr_result=$(tesseract ~/Downloads/1st_page_cropped1.png - -l chi_sim+eng quiet)
magick -density 200 ~/Downloads/1st_page.pdf -crop 430x180+190+200 +repage ~/Downloads/1st_page_cropped.pdf
magick -density 600 ~/Downloads/1st_page_cropped.pdf -quality 100 -background white -alpha background -alpha off -colorspace RGB ~/Downloads/1st_page_cropped2.png
# 【可选】以下命令实现的效果与上面等价
pdftoppm -singlefile -x 190 -y 200 -W 430 -H 180 -r 200 ~/Downloads/1st_page.pdf ~/Downloads/1st_page_cropped2 -png
number_ocr_result=$(tesseract ~/Downloads/1st_page_cropped2.png - -l chi_sim+eng quiet)
mv "/文件路径/要处理的文件名称.pdf" "/文件路径/结构-竣工图(-${number_ocr_result}-${name_ocr_result}).pdf"四、合并三个程序,实现批量处理
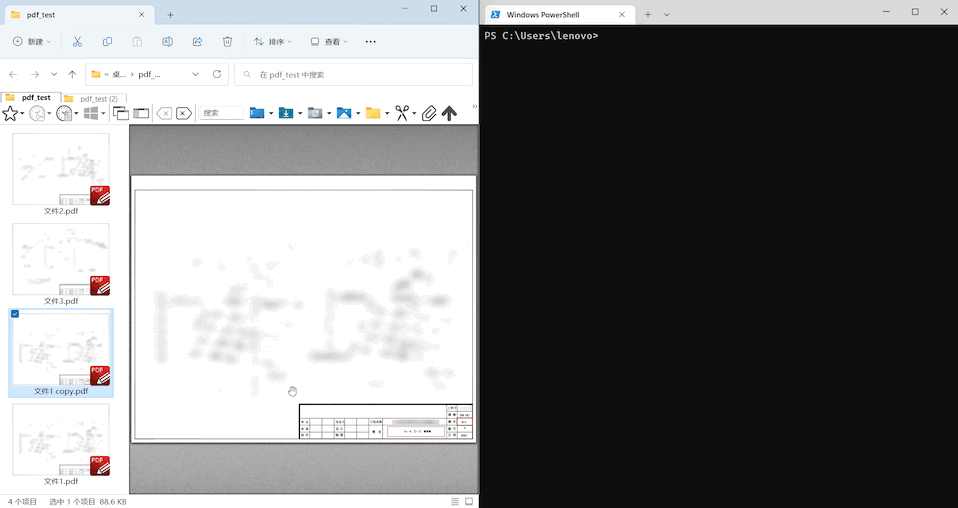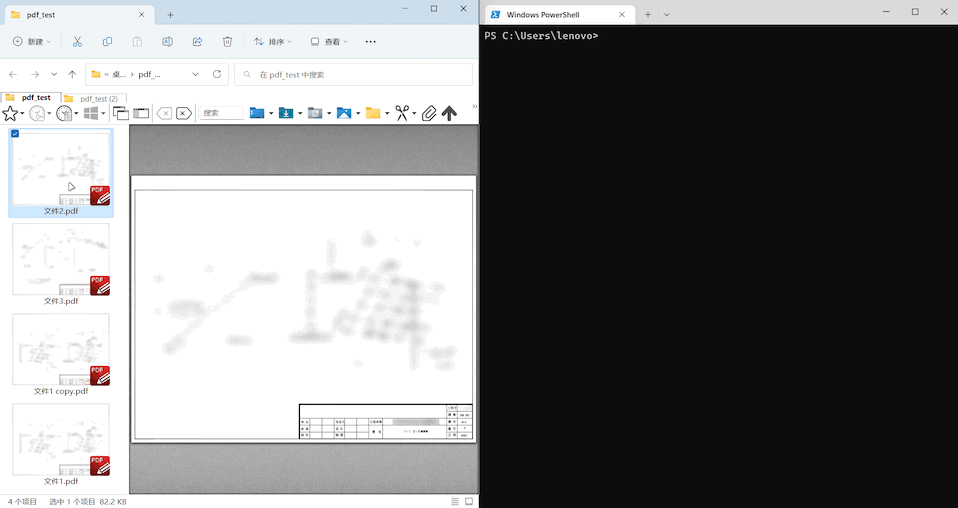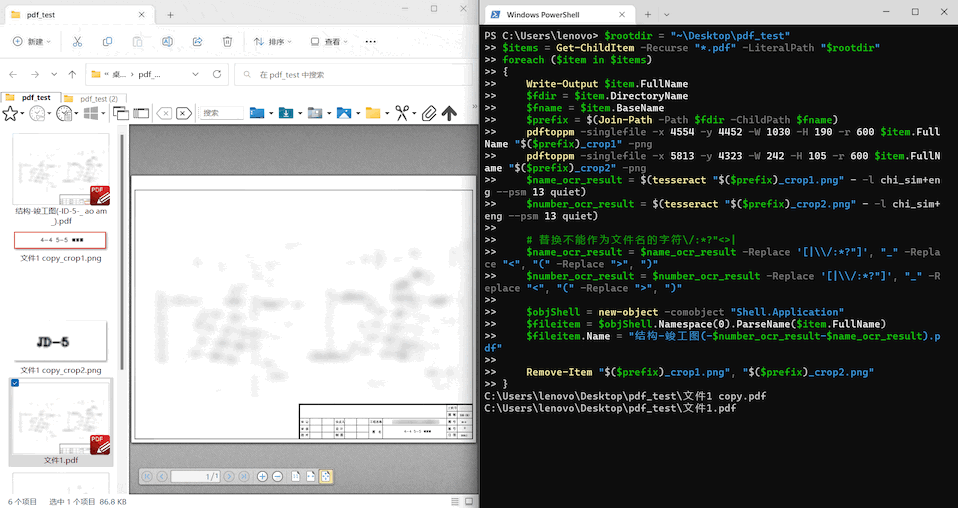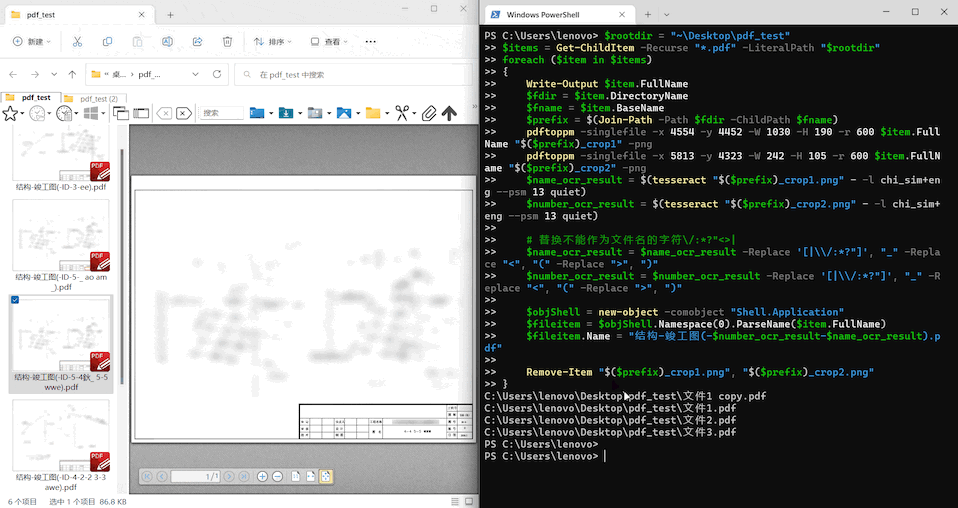
最后,将上面针对单个 PDF 文件进行处理的脚本稍加修改,就能实现批量处理多个文件的效果。
【注】这里假设所有要处理的 PDF 文件中要截取的区域位置一致,否则无法直接批量处理。
① Windows (PowerShell)
【注】使用时需将第一行中的~\Desktop\tmp\pdfs替换为包含所有要处理的 PDF 文件的目录所在路径。
这里跳过了pdftk提取单页 PDF 的步骤, 因为示例中 PDF 文件只有一页。如需添加该操作,只需在$prefix = $(Join-Path-Path $fdir-ChildPath $fname)的下一行插入相应代码即可。
$rootdir = "~\Desktop\tmp\pdfs"
$items = Get-ChildItem -Recurse "*.pdf" -LiteralPath "$rootdir"
foreach ($item in $items)
Write-Output $item.FullName
$fdir = $item.DirectoryName
$fname = $item.BaseName
$prefix = $(Join-Path -Path $fdir -ChildPath $fname)
pdftoppm -singlefile -x 4554 -y 4452 -W 1030 -H 190 -r 600 $item.FullName "$($prefix)_crop1" -png
pdftoppm -singlefile -x 5813 -y 4323 -W 242 -H 105 -r 600 $item.FullName "$($prefix)_crop2" -png
$name_ocr_result = $(tesseract "$($prefix)_crop1.png" - -l chi_sim+eng --psm 13 quiet)
$number_ocr_result = $(tesseract "$($prefix)_crop2.png" - -l chi_sim+eng --psm 13 quiet)
# 替换不能作为文件名的字符\/:*?"<>|
$name_ocr_result = $name_ocr_result -Replace '[|\\/:*?"]', "_" -Replace "<", "(" -Replace ">", ")"
$number_ocr_result = $number_ocr_result -Replace '[|\\/:*?"]', "_" -Replace "<", "(" -Replace ">", ")"
# 第一种重命名方法,不可撤销
Rename-Item -Path $item.FullName -NewName "结构-竣工图(-$number_ocr_result-$name_ocr_result).pdf"
# 【可选】第二种重命名方法,支持 ctrl+Z 撤销
$objShell = new-object -comobject "Shell.Application"
$fileitem = $objShell.Namespace(0).ParseName($item.FullName)
$fileitem.Name = "结构-竣工图(-$number_ocr_result-$name_ocr_result).pdf"
}② macOS / Linux (Bash)
【注】使用时需将第一行中的~/Desktop/tmp/pdfs替换为包含所有要处理的 PDF 文件的目录所在路径。
这里跳过了pdftk提取单页 PDF 的步骤, 因为示例中 PDF 文件只有一页。如需添加该操作,只需在fname=$(basename"$f" .pdf)的下一行插入相应代码即可。
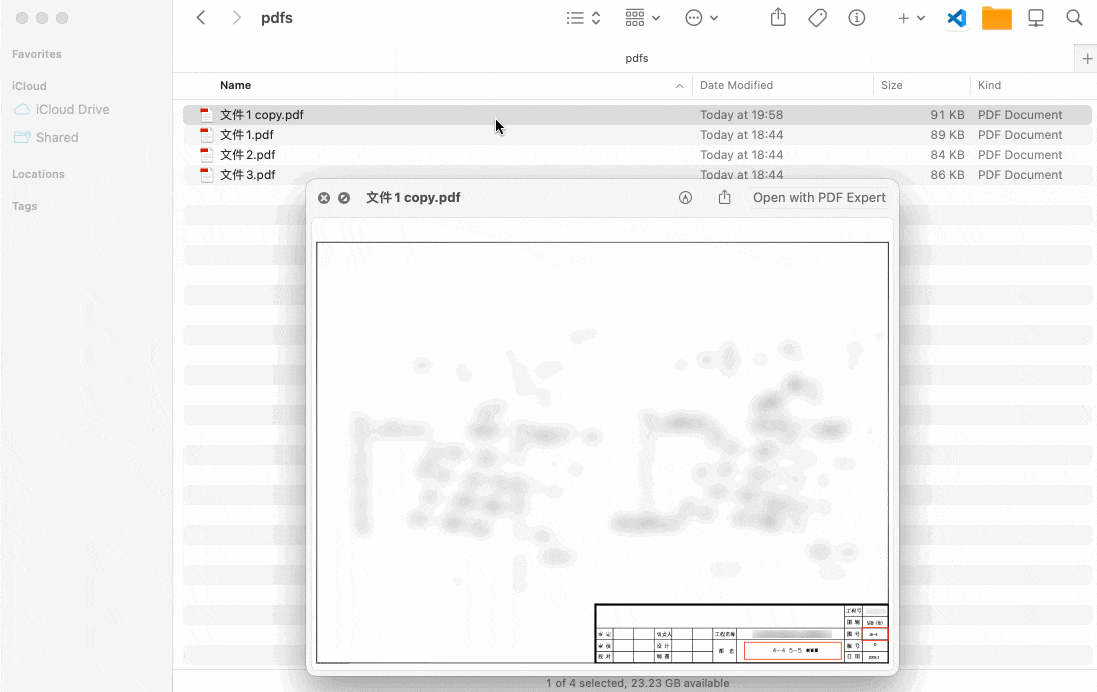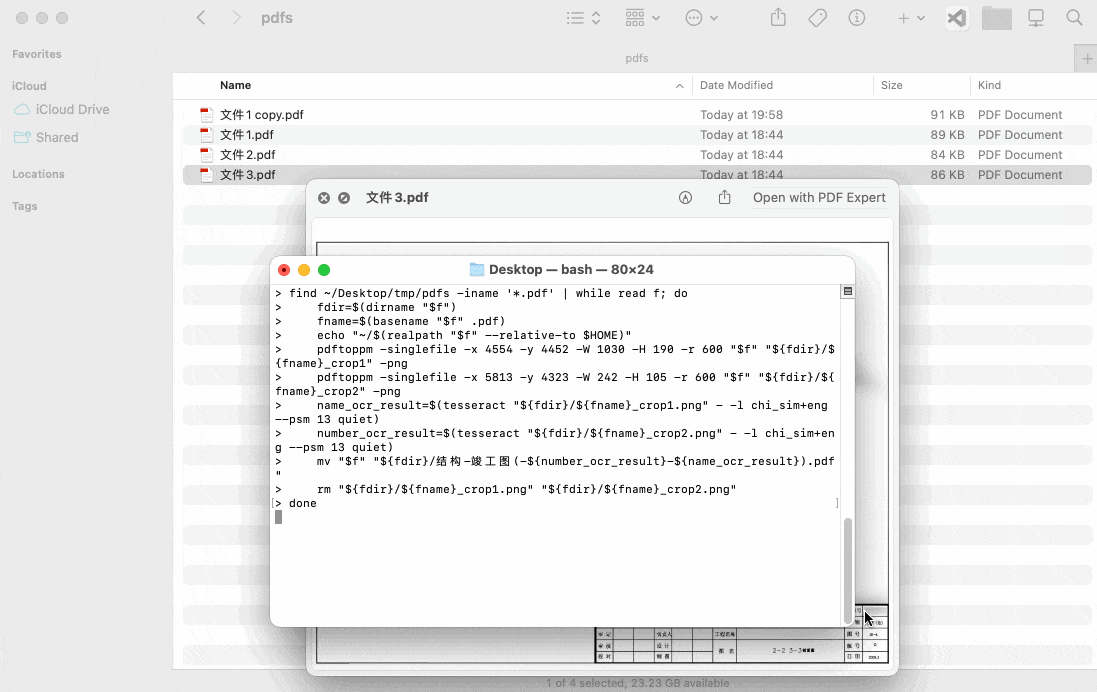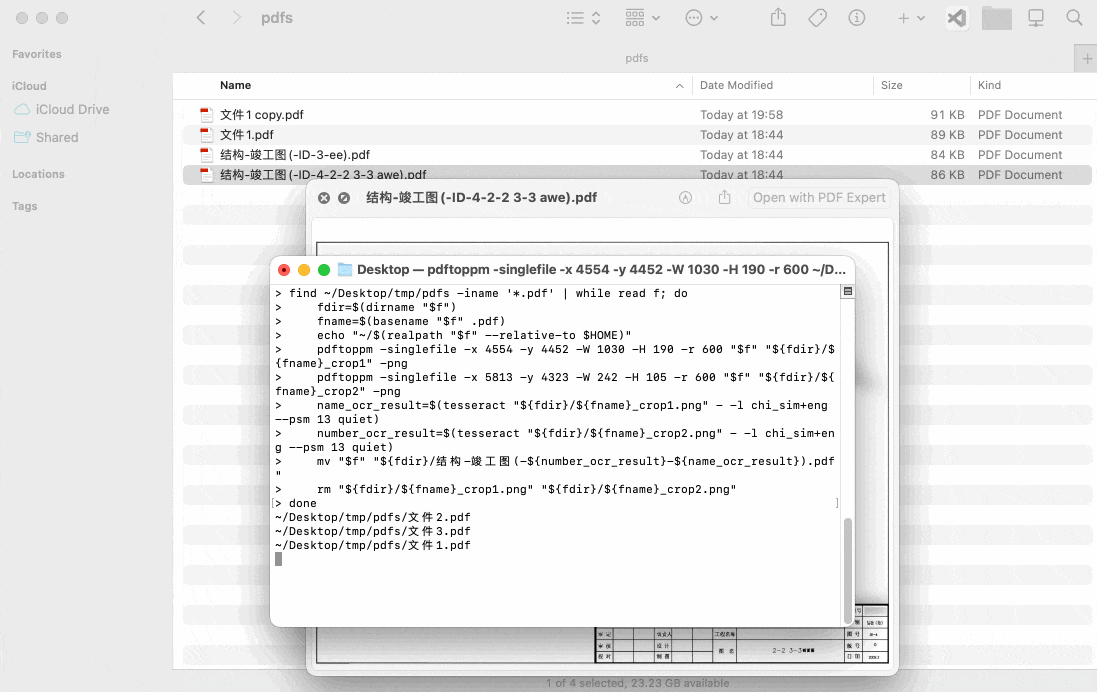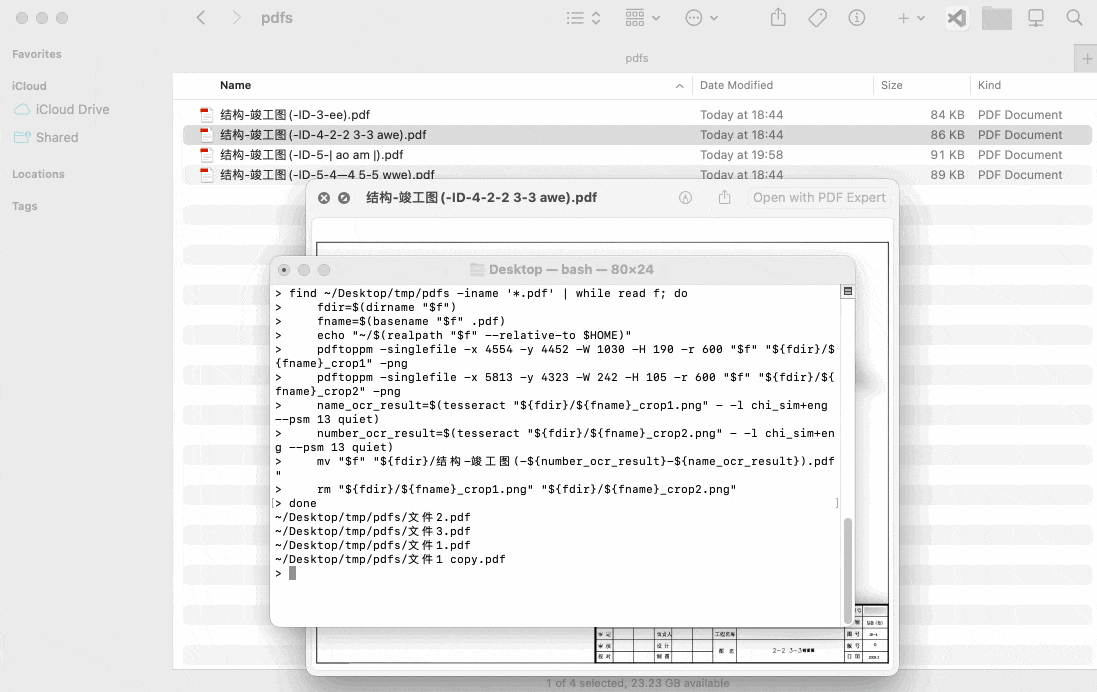
find ~/Desktop/tmp/pdfs -iname '*.pdf' | while read f; do
echo "$f"
fdir=$(dirname "$f")
fname=$(basename "$f" .pdf)
pdftoppm -singlefile -x 4554 -y 4452 -W 1030 -H 190 -r 600 "$f" "${fdir}/${fname}_crop1" -png
pdftoppm -singlefile -x 5813 -y 4323 -W 242 -H 105 -r 600 "$f" "${fdir}/${fname}_crop2" -png
name_ocr_result=$(tesseract "${fdir}/${fname}_crop1.png" - -l chi_sim+eng --psm 13 quiet)
number_ocr_result=$(tesseract "${fdir}/${fname}_crop2.png" - -l chi_sim+eng --psm 13 quiet)
mv "$f" "${fdir}/结构-竣工图(-${number_ocr_result}-${name_ocr_result}).pdf"
rm "${fdir}/${fname}_crop1.png" "${fdir}/${fname}_crop2.png"
done演示效果:
实际效果取决于多种因素(如采用的 OCR 引擎的准确率、PDF 文件的清晰度等),如果在你的测试中效果不佳,可以考虑换用更强的 OCR 程序,或者尝试改进 PDF 文件的质量。


附录:使用 Python 库来获取 PDF 文件中的矩形标注对应的位置坐标
【注】这里假设已经安装了 Python3 环境并安装 pikepdf 库
首先将下述代码保存为
PDFannotation.py
文件:
import sys
from distutils.version import LooseVersion
from pathlib import Path
from pikepdf import Pdf
if LooseVersion(sys.version) < "3.7":
raise NotImplementedError("pikepdf requires Python 3.7+")
def getAnnotationInfo(pdf_path, page=0):
if not Path(pdf_path).exists():
return f"Error: No such file: {pdf_path}"
with Pdf.open(pdf_path) as pdf:
maxPages = len(pdf.pages)
if page < 0 or page >= maxPages:
return (
f"Error: Invalid page number ({page}), "
f"expected numbers between 0 and {maxPages - 1}"
# check Section 14.11.2 in PDF 1.7 ISO Specification PDF 32000-1:2008
# https://opensource.adobe.com/dc-acrobat-sdk-docs/standards/pdfstandards/pdf/PDF32000_2008.pdf
x, y, w, h = pdf.pages[page].mediabox
print(f"Page size: {h}x{w}+{x}+{y}")
if "/Annots" not in pdf.pages[page]:
return f"Error: No annotation found in PDF page {page}"
annotations = pdf.pages[page]["/Annots"]
info = []
for i, annot in enumerate(annotations):
# check Section 12.5.2 in PDF 1.7 ISO Specification PDF 32000-1:2008
lower_left_x, lower_left_y, upper_right_x, upper_right_y = annot["/Rect"]
width = upper_right_x - lower_left_x
height = upper_right_y - lower_left_y
left_x = lower_left_x
top_y = h - upper_right_y
pos = (width, height, left_x, top_y)
subtype = str(annot["/Subtype"]).lstrip("/")
info.append((subtype, pos))
return info
if __name__ == "__main__":
args = sys.argv
if len(args) not in (3, 4):
print("Usage: %s [pdf] [page_index] [target_density=72]" % args[0])
elif len(args) == 3:
for name, (w, h, x, y) in getAnnotationInfo(args[1], int(args[2])):
print(f"[{name}] {w}x{h}+{x}+{y}")
else:
# Default density (DPI) in magick is 72
target_density = int(args[3])