


近9000字,【GPT-3学习笔记】公开,可能是全网最全

ChatGPT要收费了,可能很多人跟我一样还搞不灵清什么是ChatGPT、GPT-3等内容,于是我整理了网上关于GPT的内容并写成笔记分享给大家,让还不懂的人学习不绕弯路,从头到尾了解GPT-3。获取原文和完整资料可在公众号【稻香老农民】点击文章最后【阅读原文】或私聊我获取。

笔记结构:

GPT-3概述
简要说明GPT-3是什么,以及它与以前的语言生成模型有何不同。
GPT-3(Generative Pre-trained Transformer 3)是OpenAI开发的一种先进的语言生成模型。GPT-3使用深度学习技术,基于大量经过训练的数据生成类人文本,可以理解和生成各种语言和格式的文本,包括自然语言、代码和结构化数据。
GPT-3使用了一种转换器架构,这是一种在自然语言处理任务中非常有效的神经网络。GPT-3的深度学习神经网络是一个拥有超过1750亿个机器学习参数的模型。该模型是在互联网上的大量文本数据集上预先训练的,这使得它能够理解它生成的文本的上下文和含义。GPT-3可以生成通常与人类书写的文本难以区分的文本。
如何向10岁儿童解释(由GPT-3生成):
GPT-3是一种可以像人一样理解和书写的计算机程序。这就像有一个超级聪明的朋友,可以帮你写故事或回答问题。计算机使用一种叫做“transformer”的东西来理解你给予它的单词,就像你如何用大脑来理解人们对你说的话一样。在你开始使用它之前,它也被教了很多,比如它读了很多书和文章,所以它知道很多不同的主题。它很聪明,能造出听起来像真实的写的句子。它也有很大的“脑力”,有超过1750亿个微小的部分帮助它理解和造句。
GPT-3被认为是最先进的语言生成模型之一,用于多个行业,如客户服务、市场营销和内容创建。GPT-3具有理解和生成自然语言的能力,被认为是各个行业自动化任务和提高效率的强大工具。GPT-3还用于生成富有创意和吸引力的内容,并自动执行客户服务任务,如回答客户问题。

总的来说,GPT-3是一个强大的工具,有可能彻底改变许多行业和我们与计算机交互的方式。它是自然语言处理领域令人兴奋的发展,可以极大地提高许多任务的效率和有效性。
OpenAI发展简史
OpenAI是一家私人人工智能研究实验室,由盈利性OpenAI LP及其母公司非盈利性OpenAI Inc,组成。它于2015年12月由埃隆·马斯克、伊利亚·苏茨凯弗、格雷格·布罗克曼、山姆·奥特曼、沃伊切赫·扎伦巴和约翰·舒尔曼创立,目标是负责任地促进和发展友好的人工智能。该公司成立的目标是以造福全人类的方式开发和推广友好的人工智能。
2016年,OpenAI发布了首个重大AI项目--无监督语言模型GPT-1,可以完成广泛的语言任务。2018年,OpenAI发布了GPT-2,这是一个功能更强大的模型版本,可以生成类人文本。
2020年,OpenAI发布了GPT-3,它是在大得多的数据集上训练的,可以高精度地执行广泛的任务,包括文本生成、语言翻译和问答。
GPT-3之前的语言模型
在GPT-3之前,OpenAI和其他组织创建了其他几种语言生成模型:
- GPT-1和GPT-2:GPT-3是GPT系列机型的第三代,之前是GPT-1和GPT-2。GPT-1和GPT-2也是由OpenAI开发的,使用了与GPT-3类似的trasformer架构。然而,GPT-1和GPT-2是在较小的数据集上训练的,并且比GPT-3具有更少的功能。
- BERT:BERT(Bidirectional Encoder Representations from Transformers)是谷歌开发的一个模型,它是在互联网上的大量文本数据集上训练的。BERT主要用于文本分类、情感分析和问答等自然语言理解任务。
- ELMO:ELMO(Embeddings from Language Models)是由Allen Institute for Artificial Intelligence开发的一个模型,也是在来自互联网的大型文本数据集上训练的。ELMO主要用于文本分类、问答等自然语言理解任务。
- ULMFiT:ULMFiT(Universal Language Model Fine-tuning)是由fast.ai开发的一个模型,它是在来自互联网的大型文本数据集上训练的。ULMFiT主要用于文本分类和情感分析等自然语言理解任务。
- XLNet:XLNet是Google AI开发的一个模型,使用基于排列的训练方法。XLNet主要用于文本分类、情感分析和问答等自然语言理解任务。
- NLG:微软的图灵Natural Language Generation(NLG)模型是由微软研究院开发的最先进的机器学习模型。它基于基于变换器的神经网络架构,称为图灵架构,由微软研究团队于2018年推出。2019年,微软在海量文本数据集上对该模型进行了微调,并将其作为通用自然语言生成模型发布。该模型可以执行诸如文本生成、语言翻译和问题回答等广泛的任务。它广泛应用于聊天机器人、虚拟助手、内容生成和自然语言理解等各种应用中。
GPT-3的工作原理、功能和限制
GPT-3是如何工作的?
GPT-3是一种语言预测模型。这意味着它有一个神经网络机器学习模型,可以接收输入文本并将其转换为它预测的最有用的结果。这是通过在大量的互联网文本上训练系统来完成的,以在一个称为生成性预训练的过程中发现模式。GPT-3是在几个不同权重的数据集上训练的,包括Common Crawl、WebText 2和Wikipedia。
GPT-3首先通过监督测试阶段训练,然后是强化阶段。在训练ChatGPT时,一组训练者会向语言模型提出一个问题,并记住正确的输出。如果模型回答错误,训练者会调整它,教它正确的答案。该模型也可能给予几个答案,训练者从最好到最差排列这些答案。
GPT-3拥有超过1750亿个机器学习参数,比它的前辈--以前的大型语言模型,如来自trasformer的双向编码器表示(BERT)和图灵NLG--要大得多。参数是大型语言模型的组成部分,它定义了语言处理问题(如生成文本)的技巧。大型语言模型的性能通常会随着向模型中添加更多数据和参数而扩展。
当用户提供文本输入时,系统分析语言并使用基于训练的文本预测器来创建最可能的输出。该模型可以进行微调,但不需要太多额外的调整或训练,该模型就可以生成高质量的输出文本,感觉与人类生成的文本相似。
比如向10岁儿童解释(由GPT-3生成):
当你给GPT-3一些单词或句子时,它会用它超级聪明的大脑来弄清楚你想让它接下来说什么。就好像它在猜你想说什么。就像在玩"接下来会发生什么"的游戏?".它利用以前学过的知识来帮助自己猜出正确的单词和短语。即使你不给它太多额外的信息,它仍然可以写出听起来像真人写的句子。但是如果你给它多一点信息,它就能更好地猜测你想让它说什么。这就像给你的超级聪明的朋友更多的信息,帮助他们为你写一个故事。
用于训练GPT-3的大量数据使模型能够以多种方式理解和生成类似人类的文本:
- 词汇表:用于训练GPT-3的大量文本数据允许模型学习大量的单词、短语和习语词汇表。这使得模型能够理解和生成更接近于人类文本的文本。
- 语言结构:通过在如此大的文本数据集上进行训练,GPT-3学习了人类语言的结构和模式。这允许模型理解并生成语法正确且连贯的文本。
- 背景理解:用于训练GPT-3的大量文本数据允许模型学习单词和短语的上下文。这使得模型能够理解并生成任务或上下文的适当文本。
- 特定领域知识:GPT-3的训练数据包括来自不同领域的各种文本,如科学、技术、艺术和政治。这允许模型获取特定领域的知识并为特定领域生成适当的文本。
- 微调:GPT-3对这样一个大数据集的预训练允许对特定任务或域的模型进行微调。这种微调使GPT-3能够生成特定于任务或域的文本,使其对某些应用程序更有效。
GPT-3功能
每当需要根据少量的文本输入从计算机生成大量文本时,GPT-3提供了一个很好的解决方案。大型语言模型,如GPT-3,可以在给定少量训练示例的情况下提供不错的输出。
GPT-3还拥有广泛的人工智能应用。这是不可知的任务,意味着它可以执行大量任务而不需要微调。
与任何自动化程序一样,GPT-3能够快速处理重复的任务,使人类能够处理需要更高程度的批判性思维的更复杂的任务。在许多情况下,让人输出内容是不实用或效率低下的。可能需要自动生成看起来像人类的内容。例如,客户服务中心可以使用GPT-3来回答客户问题或支持聊天机器人;销售团队可以使用它与潜在客户联系。市场营销团队可以使用GPT-3编写文案。这类内容还需要快速制作,而且风险较低,这意味着如果复制中出现错误,后果相对较小。
一些主要功能包括:
- 文本生成:GPT-3可以针对各种主题生成像人话的文本,从创意写作到新闻稿和技术文档。它还可以生成不同风格的内容,如诗辞歌赋。
- 语言翻译:GPT-3可以准确地将文本从一种语言翻译成另一种语言。它可以在多种语言之间进行翻译,并处理习惯表达和口语。
- 文本摘要:GPT-3可以将长文本摘要为更短、更简洁的版本,这对文档摘要和关键短语提取非常有用。
- 文本填写:GPT-3可以根据上下文和提供的信息完成给定的文本。这对于写邮件和聊天机器人自动会话非常有用。
- 文本分类:GPT-3可以将文本分为不同的类别,例如情感分析和主题分类。
- 问题解答:GPT-3可以根据提供的文本回答问题,这对于搜索引擎和虚拟助手等可能很有用。
- 文本转语音、语音转文本:GPT-3可以非常准确地将文本转换为语音以及语音转换为文本。这对于语音控制助理和自动转录等任务非常有用。
- 代码生成:GPT-3可以用多种编程语言编写代码,并对代码错误提出更正建议。
- 图像字幕:GPT-3可以为图像生成标题,这对于图像搜索和自动图像标记等任务非常有用。
- 对话生成:GPT-3可以为不同的场景生成对话,比如客户服务对话,这对聊天机器人和虚拟助手可能很有用。
更多场景阅读-
以下是GPT-3在不同行业中的应用示例:
- 医疗保健:GPT-3可用于生成医疗报告、摘要和患者笔记。它还可以通过提出假设和科学论文摘要来协助研究。
- 财务:GPT-3可用于生成财务报告、摘要和预测。它还可以通过生成公司报告和金融新闻摘要来协助投资研究。
- 教育:GPT-3可用于生成教育内容,如教科书章节摘要、学习指南和练习题。
- 营销:GPT-3可用于生成营销内容,如产品描述、社交媒体帖子和电子邮件活动。
- 零售:GPT-3可用于为电子商务网站生成产品描述、客户评论和聊天机器人响应。
- 媒体和娱乐:GPT-3可用于生成脚本和故事构思、新闻稿摘要,甚至生成完整的新闻稿或评论。
- 软件开发:GPT-3可用于生成代码和文档,甚至可以回答技术问题。
- 法律:GPT-3可用于生成法律合同、法庭案例摘要和法律研究。
- 这些只是如何使用GPT-3的几个示例。由于GPT-3能够理解和生成类似人类的文本,因此它有可能自动执行许多基于语言的任务,并提高各个行业的效率。
GPT-3的局限性
GPT-3的一些主要限制包括:
- 偏见:GPT-3是在来自互联网的大量文本数据集上训练的。这可能导致模型在其生成的文本中出现偏见。
- 对上下文的理解有限:GPT-3擅长理解单个单词和短语的含义,但可能很难理解它们所使用的上下文。这可能导致模型生成不适合任务或上下文的内容。
- 缺乏常识:GPT-3可以生成连贯且语法正确的文本,但它缺乏人类对世界的常识性理解。
- 缺乏创造力:GPT-3可以生成连贯且语法正确的文本,但它缺乏人人话的创造性。这会使模型难以生成有趣或引人入胜的文本。
- 处理结构化数据的能力有限:GPT-3主要针对非结构化文本数据进行训练,这意味着它可能难以处理结构化数据(如表格或图形)。
- 高成本:GPT-3需要大量的计算资源来运行,这使得它对于某些应用程序来说成本很高。此外,OpenAI的定价模式可能会使一些用户难以访问GPT-3的全部功能。
- 误传:GPT-3是在来自互联网的大量文本数据集上训练的,这些文本可能包含错误信息。这可能导致模型生成不准确或实际上不正确的文本。
- 偏见延续:GPT-3是在来自互联网的大量文本数据集上训练的。这可能导致模型复制偏见内容在其生成的文本中,从而使现有的偏见和歧视延续存在。
- 隐私问题:GPT-3需要大量数据进行训练,这可能会引起隐私问题。该模型能够生成与人类编写的文本无法区分的文本,这也引起了人们对该模型被用于模拟个人或组织的可能性的担忧。
了解OpenAI API和Playground
什么是API?
API或应用程序编程接口是允许不同软件程序相互通信的一组规则和协议。它定义了软件组件应该如何交互,API充当不同软件系统之间的“中间人”。
API通常用于允许第三方开发人员访问现有应用程序或服务中的某些功能或数据。例如,运营电子商务网站的公司可以通过API提供其库存数据,以便其他公司可以构建其应用程序来显示和销售这些产品。
API还可以连接应用程序或服务的不同部分,从而允许不同组件进行通信和共享数据。它们通常用于连接Web应用程序和数据库,或者连接面向服务架构中的不同微服务。
API可以基于各种协议,例如REST(Representational State Transfer)或SOAP(Simple Object Access Protocol),并且可以使用不同的数据格式,例如JSON或XML。
OpenAI API
OpenAI API允许开发人员通过简单易用的界面访问OpenAI模型的功能,如GPT-3。OpenAI API提供了对广泛功能的访问,包括语言翻译、问题回答和文本生成。开发人员可以使用该API构建自己的应用程序,以理解和生成类似于人类的文本。API使用RESTful接口,可以使用标准HTTP请求访问,并以JSON格式返回数据。
它还提供了一种以安全、可管理和可扩展的方式访问模型的方法;你可以使用它来构建你的应用程序和服务,并且还允许你使用简单、易于使用的界面来访问模型,从而使所有技能水平的开发人员都可以访问。
当开发者发出API请求时,该请求被发送到OpenAI API服务器。然后服务器处理请求并将其发送到指定的模型。然后,模型处理请求并生成响应,响应通过API发送回开发人员。
OpenAI API提供了对各种模型和端点的访问,每个模型和端点都有自己的一组功能。例如,“语言处理”端点提供了对模型的访问,这些模型可以理解并生成类似人类的文本。相反,“问答”端点提供对模型的访问,这些模型可以基于给定的上下文回答问题。
OpenAI API还为Python、Java、JavaScript和Go等多种编程语言提供SDK(软件开发工具包),这使得在代码中发出API请求和处理响应变得更加容易。
要使用API,开发者需要在OpenAI网站上注册API密钥,并将其包含在API请求的头部。OpenAI API还使用基于使用的定价模型,因此开发人员根据他们发出的请求数量和完成这些请求所需的计算时间付费。
OpenAI Playground
OpenAI Playground是一个在线工具,允许用户与OpenAI的模型(如GPT-3)交互并测试其功能,而无需编写任何代码。使用Playground,用户可以输入文本,并查看模型如何真实的生成响应。这对于测试模型的功能和了解其工作方式非常有用。
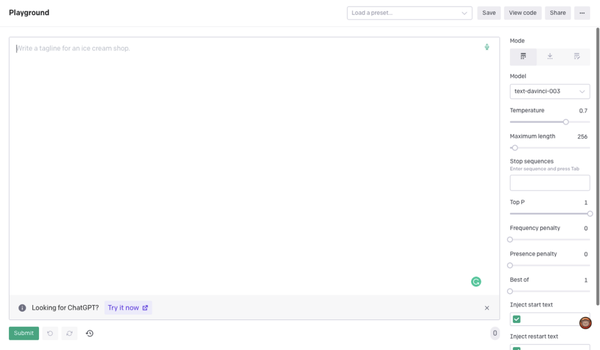

OpenAI Playground允许用户以不同的方式与GPT-3交互,例如:
- 通过给定句子或段落来完成文本Prompt,
- 基于给定主题或几个关键字从头开始生成文本,
- 基于给定上下文回答问题,
- 将文本从一种语言翻译成另一种语言。
- 它还允许用户通过调整Temperature、上下文数量和生成文本的Maximum length来定制模型。
OpenAI Playground是一个基于网络的工具,不需要任何安装,任何人都可以通过互联网连接访问。
Playground上有一些GPT-3预设。转换器驱动的GPT模型的惊人之处在于它能够识别特定的样式、文本字符或结构。如果你从列表开始,GPT-3会继续生成列表。如果你的Prompt有问答结构,它将保持连贯。如果你要一首诗,它就会写一首诗。你可以自己预设,也可以使用现有预设。当构建需要快速工程的产品时,Playground和预设非常重要。

Playground的主要组成部分:
模型:OpenAI提供了四种主要模型,具有不同的功率级别,适合不同的任务。Davinci是最有能力的模型,Ada是最快的。
- Text-davinci-003 :Davinci是最有能力的模型组,可以执行其他模型所能执行的任何任务,需要的指导更少。对于像针对特定受众的摘要和创造性内容生成这样需要大量了解内容的应用程序,Davinci输出的结果最好。这些增强的功能需要更多计算资源,因此Davinci每次API调用的成本更高,速度也不如其他模型。Davinci擅长另一个领域是理解文本意图。Davinci相当擅长解决许多逻辑问题,并解释人物动机。Davinci已经能够解决一些涉及因果关系的最具挑战性的人工智能问题
擅长:复杂的意图,因果关系,为用户总结
- Text-curie-001 :Curie非常强大,而且速度非常快。Davinci在分析复杂文本方面更强,而Curie在情感分类和总结等许多微妙的任务上也相当强。Curie也相当擅长回答问题和执行问答和作为一个一般服务聊天机器人。
擅长:语言翻译、复杂分类、文本情感、总结
- Text-babbage-001 :Babbage可以执行简单的任务,如简单的分类。当涉及到语义搜索排名文档与搜索查询的匹配程度时,也很有强。
擅长:适度分类、语义搜索分类
- Text-ada-001 :Ada是最快的模型,可以执行诸如文本解析、地址更正和某些不需要太多细微差别的分类任务。Ada的性能通常可以通过提供更多的上下文来提高。
擅长:文本解析,简单分类,地址更正,关键词


Temperature :"Temperature"是指控制模型输出的随机性或创造性的参数。较高的Temperature设置将导致更多样和创造性的输出,而较低的Temperature将产生更保守的输出并且类似于训练数据。Temperature设置可用于控制模型预测的置信水平。较低的Temperature会使模型产生更加确定和自信的输出,而较高的Temperature会使模型产生更加多样的输出。
Maximum length :模型将在其输出中生成的最大标记数。标记是模型用来生成其输出的单个单词或文本片段。设置Maximum length有助于限制输出中生成的标记数,并防止模型生成过多的文本。它还可以用于提高模型的性能,因为较长的序列需要更多的计算能力来生成。它还可用于控制模型在生成输出时使用的上下文数量。
Top P :Top P是一个控制计算机文本预测可信度的设置。Top P值越高,输出与训练文本越相似,Top P值越低,输出越有创意和变化。它可用于使输出更适合特定用例。
Frequency penalty :Frequency penalty是用于控制模型生成常见或重复单词和短语的可能性的特征。它是一个可以调节的值,以使模型更有可能或更少地重复它在其训练数据中经常看到的单词或短语。Frequency penalty的正值将使模型不太可能重复常用单词和短语,从而使输出更加多样和富有创造性。Frequency penalty的负值使模型更可能重复常用单词和短语,从而产生与训练数据更相似的输出。此功能可与Temperature和Top P等其他参数结合使用,以微调模型的输出,使其更适合特定用例。
Presence penalty :Presence penalty是一种控制某些单词或短语出现在GPT-3生成的输出中的可能性的方法。它为某些单词或短语赋值,并根据该值是正还是负,使模型或多或少地生成该单词或短语。此功能可用于微调输出,以包括或排除某些单词或短语。
Best of :“Best of”是GPT-3中的一项功能,允许你从多个生成的响应中选择最佳的响应。它可用于通过过滤掉可能不相关或不准确的响应来提高输出的质量。当你有特定的目标或任务(如生成特定类型的文本或回答问题),并且希望选择最合适的响应时,此功能非常有用。
GPT-3创建
根据所需的结果和可用的资源,有多种方法可以使用GPT-3开发产品。一些常见的方法包括:
- 使用OpenAI API:OpenAI API允许开发人员在其应用程序中访问GPT-3的功能。开发人员可以使用API创建广泛的产品,如聊天机器人、自动化写作和内容生成工具以及问答系统。
- 创建OpenAI API的wrapper :开发人员可以围绕OpenAI API创建一个wrapper ,使非开发人员更容易访问和使用GPT-3的功能。
- 使用预构建集成(pre-built integrations):有几个预构建的集成允许用户将GPT-3与其他工具和平台(如Zapier、Integromat和IFTTT)连接起来。这些集成使自动化任务和创建新产品变得容易。
- 创建使用GPT-3作为服务的产品:你可以创建将GPT-3用作服务的产品,方法是提供一个平台或网站,用户可以在其中访问GPT-3的功能,并使用这些功能生成文本、回答问题、翻译语言等。
你还必须了解Prompt Engineering和微调,以便使用任何方法创建产品。
Prompt Engineering
Prompt Engineering是设计和微调GPT-3输入或“Prompt”的过程,目的是控制输出并实现特定结果。它是一种用于控制模型行为并指导模型生成特定类型的文本或回答特定问题的技术。
Prompt Engineering包括仔细地为模型设计输入文本,称为“Prompt”,以引导模型生成所需的输出。这可以包括添加特定关键字或短语、提供上下文或背景信息,甚至包括特定约束或规则。
prompt engineering的目标是最大限度地提高模型在生成与给定任务相关且有用的文本时的性能和准确性。它是使用GPT-3和其他语言生成模型的一个重要部分,因为它允许用户获得特定的结果并微调模型的性能。
Prompt Engineering可以通过试错和实验来完成,测试不同的Prompt并查看哪一个最适合特定任务是很重要的。
同样重要的是要注意,虽然Prompt Engineering可以有效地控制GPT-3的输出,但它不是一个万无一失的方法,因为GPT-3仍然可能生成意外或不需要的文本。
虽然Prompt Engineering是很多关于Playground的实验,有几个原则需要记住。
- 一个Prompt将指导模型生成有用的输出 :当模型接收到Prompt时,它会使用自己丰富的人类语言知识(这些知识是从大量的数据中获得的)来生成与Prompt中描述的上下文和任务一致的文本。该模型可以生成连贯且语法正确的文本,该文本遵循特定的样式,包含特定的信息,或者具有特定的格式,具体取决于Prompt。
- 尝试多种Prompt公式以获得最佳代 :制作好的Prompt的过程通常是反复的,需要进行实验。Prompt的不同表述可能导致不同的输出,并且预测模型将如何响应特定Prompt可能是具有挑战性的。针对用例、受众和领域测试生成的输出也很重要。基于此反馈,可以进一步微调Prompt,以获得最佳的生成。此外,还需要注意的是,Prompt应该足够具体以指导模型,但也应该足够通用以允许模型探索不同的可能性。
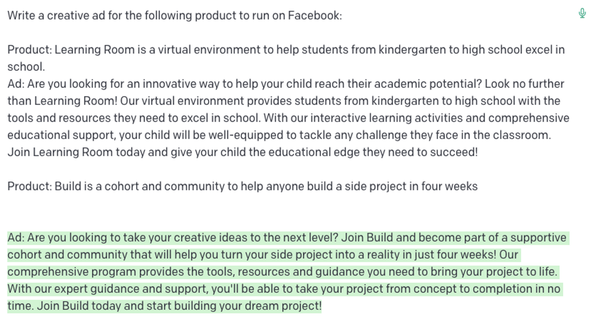
- 详细描述任务和常规设置以获得更好的结果 :背景越清晰,回应越好。参见以下示例(GPT-3响应为绿色)


- 向模型提示你希望看到的内容:在Prompt语中添加例子是实现好一代的关键方法之一。

微调
微调GPT-3指的是使预先训练的GPT-3模型适应特定任务或领域的过程。这是通过在特定于任务或领域的较小数据集上训练模型来实现的,这样它就可以更好地理解上下文并生成更准确和相关的文本。
微调GPT-3的过程包括使用预先训练的模型作为起点,然后在特定于任务或领域的较小数据集上训练它。这可以通过使用OpenAI API来实现,它允许开发人员访问GPT-3模型,并使用它来使用不同的数据集微调模型。
在微调过程中,模型学习调整其权重和偏差,以更好地适应新的数据集,并开始生成与特定任务或领域更相关的文本。该过程可以针对诸如语言翻译、文本摘要、文本完成、文本生成等各种任务来完成。
值得一提的是,微调GPT-3需要大量的计算资源,而且可能非常耗时。然而,它是一种提高模型在特定任务和领域上的性能的强大方法。
微调GPT-3通常包括以下步骤:
- 收集和准备数据集:第一步是收集一个数据集,该数据集特定于你想要微调模型的任务或域。该数据集应该足够大,以便为模型提供对上下文和相关信息的良好理解。
- 创建Prompt:下一步是创建Prompt,这是一个文本输入,用于指导模型生成有用的输出。Prompt应该以特定于任务或域的方式编写,并且它应该为模型提供足够的信息以生成相关文本。
- 微调模型:访问API后,可以使用数据集和Prompt来微调模型。这通常涉及在数据集上训练模型一定数量的步骤,并调整参数以提高性能。
- 评估模型:在对模型进行微调之后,必须在单独的数据集上评估其性能,以确保生成相关且准确的文本。可以使用BLEU、METEOR等度量或其他度量来评估模型的性能。
- 部署模型:在微调之后,模型可以部署在生产环境中,例如网站或移动应用程序,具体取决于用例。
如何思考使用GPT-3
我们中的许多人都很难想出创意,因为我们把这个过程复杂化了。当我们把创意当成一个函数时,创意的产生就变得容易了。
- 识别问题:这可以来自你的生活经历或观察你周围的世界
- 创造力:这是一种以新的方式看待事物并提出原创/新颖解决方案的能力
- 激情:这源于你的兴趣或你喜欢做的活动
我们已经了解了GPT-3的工作原理及其功能;在此基础上,我们可以从以下两个方面来思考:
解决问题
最好的想法是那些解决一个特殊/具体问题的想法,无论大小。发现问题应该是你产生想法的开始。
不要先想一个解决方案,然后试图解决问题
构建面向问题的解决方案非常重要,因为它使你能够专注于解决特定的需求。这可以帮助你创建更有针对性、更有效和更需要的解决方案。它还可以帮助你更好地了解用户的需求以及你的解决方案如何解决这些需求
敏锐的观察你周围:你的问题、你的家人、同事、社区、社会乃至整个世界
- 你是否考虑过无论事情大小都可以高效、更好或更快地解决?特别是想想你希望生活中没有的小问题
- 你组织中的某个职能部门是否经常抱怨/唠叨某事?深入挖掘并找出是否有机会构建简单的解决方案
- 朋友/家人是否经常讨论某个app的功能或特点?你会发现他们会一直一直讨论
- 在努力完成工作时,你面临哪些障碍/问题?观察和评估(例如遛狗、决定买PRADA还是GUCCI等)
阅读和关注有趣的人:KOL谈论一些应该存在的东西,在 Reddit, Twitter或其他地方表达伤感。人们表达伤感是被大多数人忽视的,但如果你每次看到有人表达伤感时都停下来,这可能是一个的机会
- 社交媒体是一个伟大的方式来寻找人们面临的问题。你需要以这样一种方式来管理你的信息来源,即你关注正在分享有价值知识的人
- Twitter上有很多人在谈论针对具体问题的产品。Sharath Kuruganthy做了一个项目来寻找这个叫做RequestforProduct的东西
- 寻找产品评论或论坛,人们在那里分享现有产品的反馈和问题
社群/社区/论坛:提出想法并快速获得反馈。也许就能顿悟并产生创意。
改进当前工作流程
在我们的日常工作流程中,我们需要执行许多重复性的语言任务。GPT-3可以通过自动执行涉及自然语言处理的任务(如编写、摘要和翻译文本)来改进当前的工作流程。它还可以通过提供人性化的响应和见解来协助客户服务和数据分析等任务。此外,GPT-3可用于产生新的想法和内容,这有助于提高创造力和生产力。总的来说,GPT-3有助于简化工作流,节省时间和资源,使专业人员能够专注于更高级别的任务。